応用情報技術者 2009年 秋期 午後 問11
ITサービスにおけるサービスサポートに関する次の記述を読んで、設問1~5に答えよ。
L社は、データセンタを保有し、ITサービスマネジメントを使ってITサービスを提供している。約50台の自社の業務システムサーバをデータセンタ内の専用サーバルーム(以下、社内向けサーバルームという)で運用管理している。
ある平日の昼間、社内向けサーバルームで運用管理している業務システムサーバのうち10台が停止し、業務システムが停止したことを示すアラートがサーバの監視担当によって確認された。サーバの監視担当は、社内向けサーバルームに駆け付け、各サーバに物理的な故障がないことを確かめた。
〔サービスデスク機能〕
サーバの監視担当は、サービスデスクに連絡した。サービスデスク担当は、連絡を受けた情報をaデータベースに記録した。このデータベースは、サービスデスク、インシデント管理、問題管理など、サービスサポートの機能や各プロセスで取り扱う情報を一元管理するデータベースである。サービスデスク担当は、本データベースを検索したが、適切な解決策を得られなかったので、インシデント管理担当へエスカレーションした。
〔インシデント管理プロセス〕
インシデント管理の目標は、bすることである。
本件において、まず実施すべきアクションは、運用手順に従って、cことである。このアクションの後、業務を再開することができた。
〔問題管理プロセス〕
問題管理の目標は、dすることである。
業務システムの稼働再開後、10台のサーバ群が停止した原因を調査した。各サーバの仕様は同一で、サーバ1台当たりの立上げ時の消費電力は20kVA、通常動作時の消費電力は利用度合によって10~20kVAである。今回停止したサーバ群が設置されている電力線は、電源容量が230kVAに制限されており、現在の設備の制約上、増強ができない。同電力線上に、立上げ時の消費電力が大きい装置を1台、数日前に設置し、本日、これを立ち上げた時にサーバ群が停止したことが判明した。この装置の立上げ時の消費電力は50kVA、通常動作時の消費電力は5~10kVAである。この装置は試験用に設置したものであり、通常、試験に使用しないときは電源を落としている。
図は、当該装置設置前の同電力線における週次及び日次(木曜日)の消費電力のグラフである。平日は、曜日によらず同じ推移を示していることが分かる。
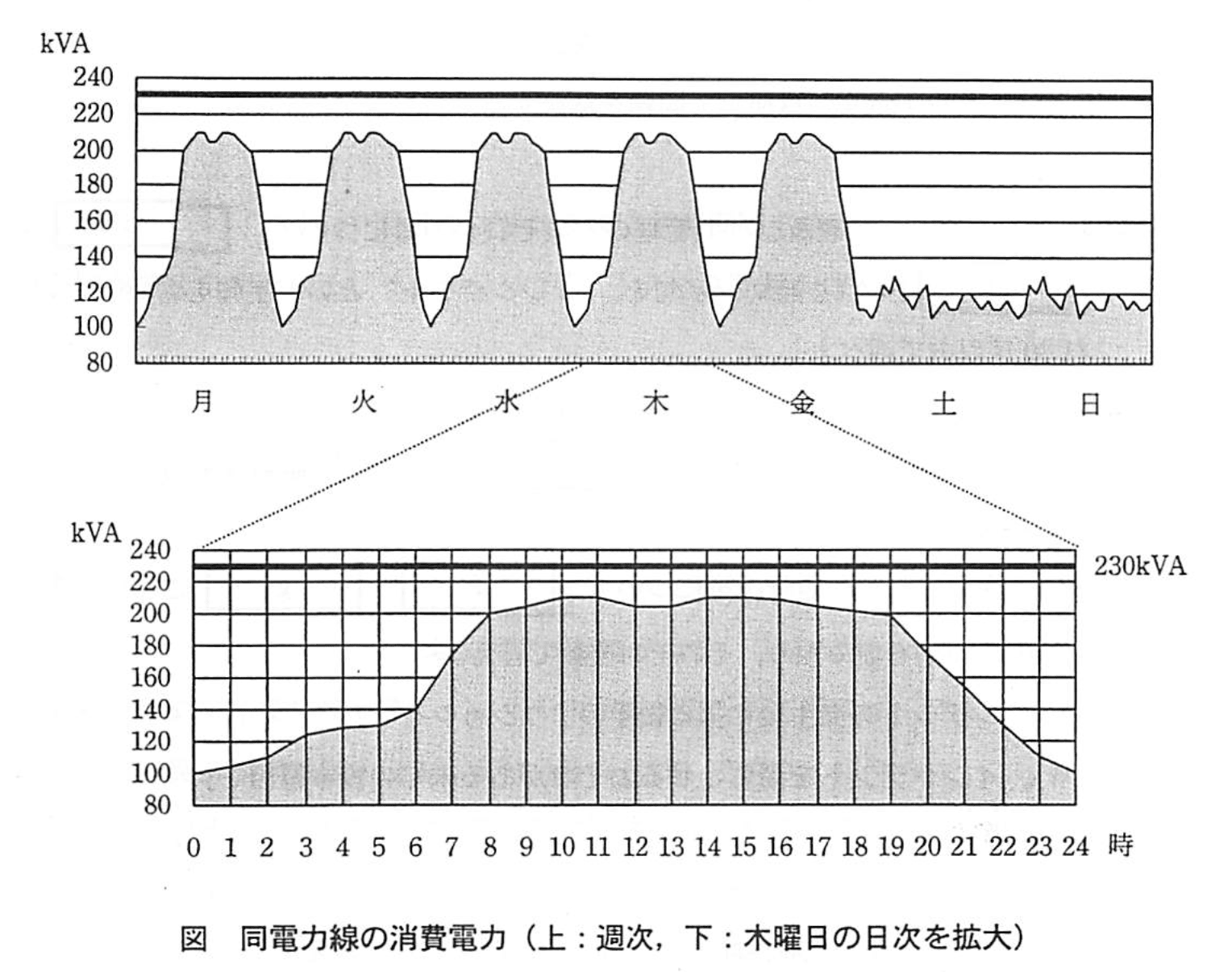
今回のサーバ停止の直接原因は、同電力線におけるeであった。図から、立上げ時の消費電力が50kVAの当該装置を立ち上げる場合、少なくとも平日のf~g時の間を避けなければならないことが読み取れる。これを基に、当該装置の立上げ日時の調整を問題解決策として採用することにした。
設問1:
本文中のaに入れる適切なITIL(Information Technology Infrastructure Library)の用語を答えよ。
模範解答
a:構成管理
解説
解答の論理構成
- 問題文は「サービスデスク担当は、連絡を受けた情報をaデータベースに記録した。このデータベースは、サービスデスク、インシデント管理、問題管理など、サービスサポートの機能や各プロセスで取り扱う情報を一元管理するデータベースである。」と記載しています。
- ITIL のサービスサポートで、複数プロセスが共通で利用し、構成アイテム(CI)やインシデント、変更履歴などを集中管理するデータベースは「構成管理データベース(Configuration Management DataBase、CMDB)」です。
- 「サービスデスク」「インシデント管理」「問題管理」など多岐にわたる情報を“一元管理”する点が CMDB の典型的な役割であるため、a に入る語は「構成管理」と判断できます。
- よって解答は「構成管理」です。
誤りやすいポイント
- 「インシデント管理データベース」や「ナレッジベース」と混同する。CMDB はサービスサポート全体の基盤であり、個別プロセス専用のデータベースとは目的が異なります。
- 「構成データベース」と短縮してしまう。ITIL 用語では必ず「構成管理データベース」と呼び、a 部分には「構成管理」が入ります。
- CMDB を「障害対応の履歴管理用」と限定的に捉える。実際には変更管理・リリース管理など幅広いプロセスで利用されます。
FAQ
Q: CMDB にはインシデント情報も格納されるのですか?
A: はい。構成アイテムとインシデントを関連付けることで、影響範囲分析や問題管理との連携が容易になります。
A: はい。構成アイテムとインシデントを関連付けることで、影響範囲分析や問題管理との連携が容易になります。
Q: ITIL v3 では CMDB と CMS(Configuration Management System)の用語の違いは?
A: CMDB は構成情報を格納する単一または複数のデータベースを指し、CMS は CMDB を含む構成管理に必要なツール群全体を指します。
A: CMDB は構成情報を格納する単一または複数のデータベースを指し、CMS は CMDB を含む構成管理に必要なツール群全体を指します。
Q: 運用開始後に CMDB を更新しないとどうなりますか?
A: 実環境と CMDB が乖離し、影響分析や変更計画の精度が落ち、サービス停止リスクが高まります。
A: 実環境と CMDB が乖離し、影響分析や変更計画の精度が落ち、サービス停止リスクが高まります。
関連キーワード: ITIL, 構成管理データベース、サービスデスク、インシデント管理、問題管理
設問2:
インシデント管理プロセスにおいて、cに入れる適切な字句を解答群の中から選び、記号で答えよ。
解答群
ア:業務システムを再起動して早急に復旧させる
イ:業務を手作業に切り換えて業務を継続する
ウ:サーバの保守担当者を呼んで原因を調査させる
エ:サーバを1台ずつ点検して問題を解決する
模範解答
c:ア
解説
解答の論理構成
-
インシデント管理プロセスの目的
問題文では、インシデント管理の目標を「bすることである。」と述べています。一般に ITIL などでは “サービスをできるだけ早く復旧し、業務への影響を最小化する” ことが目標です。 -
初動で実施すべきアクションを探る手掛かり
直後に「本件において、まず実施すべきアクションは、運用手順に従って、cことである。このアクションの後、業務を再開することができた。」と続きます。
➔ “このアクションの後、業務を再開することができた” という一文が決定的で、「業務を止めない/早期に復旧させる」タイプの対応であることが分かります。 -
解答群との照合
ア:業務システムを再起動して早急に復旧させる
イ:業務を手作業に切り換えて業務を継続する
ウ:サーバの保守担当者を呼んで原因を調査させる
エ:サーバを1台ずつ点検して問題を解決する• 「業務を再開することができた」という結果は、システムを“再起動”しサービスを復旧した場合に最も自然です。
• イは恒常的な“代替プロセス”であり、業務再開はできますが IT システム自体は復旧していません。
• ウ・エは調査/点検フェーズであり、即時復旧のニュアンスが不足しています。 -
したがって c に入る適切な字句は「業務システムを再起動して早急に復旧させる」、すなわち解答群「ア」です。
誤りやすいポイント
- 「業務を再開できた」という表現を“手作業切替”と早合点し、イを選んでしまう。
- 根本原因追及=正解という思考でウやエを選ぶが、インシデント管理の第一目的は“早期復旧”であり、原因究明は問題管理の領域。
- “運用手順に従って”という文言からルーチン作業を連想し、点検(エ)を選択してしまう。
FAQ
Q: インシデント管理と問題管理の違いは何ですか?
A: インシデント管理は「できるだけ早くサービスを復旧し影響を最小化する」ことが目的、問題管理は「インシデントの根本原因を究明し再発防止策を講じる」ことが目的です。復旧後に原因分析を行う点が最大の違いです。
A: インシデント管理は「できるだけ早くサービスを復旧し影響を最小化する」ことが目的、問題管理は「インシデントの根本原因を究明し再発防止策を講じる」ことが目的です。復旧後に原因分析を行う点が最大の違いです。
Q: 手作業への切替(イ)はインシデント管理ではダメなのですか?
A: 手作業は“ビジネス継続”の視点では有効ですが、本問は IT サービスを運転再開できた事実が明示されているため、手作業では要件を満たしません。
A: 手作業は“ビジネス継続”の視点では有効ですが、本問は IT サービスを運転再開できた事実が明示されているため、手作業では要件を満たしません。
Q: 調査や点検はいつ行うべきですか?
A: 根本原因の調査・恒久対応は、サービスを暫定復旧させた後に問題管理プロセスとして実施します。
A: 根本原因の調査・恒久対応は、サービスを暫定復旧させた後に問題管理プロセスとして実施します。
関連キーワード: インシデント管理、ワークアラウンド、サービス復旧、根本原因分析
設問3:
インシデント管理及び問題管理のそれぞれの目標について、b及びdに入れる適切な字句を、“インシデント”という字句を含めてそれぞ30字以内で述べよ。
模範解答
b:インシデントの発生時に通常のサービス運用を迅速に回復
d:インシデントの根本原因を突き止めてその解決策を提供
解説
解答の論理構成
- 問題文の確認
- インシデント管理については、本文に「インシデント管理の目標は、bすることである。」とあります。
- 問題管理については、本文に「問題管理の目標は、dすることである。」とあります。
- ITサービスマネジメント(ITIL)における公式定義
- ITIL ではインシデント管理の目的を「インシデントによるサービス中断の影響を最小化し、可能な限り早く通常のサービス運用を回復すること」と定義しています。
- 問題管理の目的は「インシデントの根本原因を特定し、再発防止や恒久的な解決策を提供すること」です。
- 解答への当てはめ
- b は “インシデント” を含み、かつ「通常のサービス運用を迅速に回復」する内容が必要。したがって「インシデントの発生時に通常のサービス運用を迅速に回復」が妥当です。
- d は “インシデント” を含み、根本原因の追究と解決策提供を示す必要があります。よって「インシデントの根本原因を突き止めてその解決策を提供」となります。
誤りやすいポイント
- インシデント管理と問題管理の目的を混同し、「回復」と「根本原因分析」を逆に書いてしまう。
- “インシデント” という語を含める指示を見落とし、単に「サービスを早期復旧させる」などと書いて減点される。
- 問題管理の目的を「再発防止」とだけ書き、解決策提示まで言及しないために不完全と判断される。
FAQ
Q: インシデント管理は恒久対策まで実施するのですか?
A: いいえ。インシデント管理は「通常のサービス運用を迅速に回復」することが中心で、恒久対策は問題管理が担います。
A: いいえ。インシデント管理は「通常のサービス運用を迅速に回復」することが中心で、恒久対策は問題管理が担います。
Q: 問題管理の「根本原因」は必ず物理的故障ですか?
A: 物理的故障に限りません。設定ミス、設計上の欠陥、人為的要因など、インシデントを発生させる根本要因すべてが対象です。
A: 物理的故障に限りません。設定ミス、設計上の欠陥、人為的要因など、インシデントを発生させる根本要因すべてが対象です。
Q: サービスデスクが検索したデータベースは何と呼ばれますか?
A: 問題文にあるとおり「aデータベース」、すなわちサービスサポート情報を一元管理するデータベース(一般にはナレッジベース)です。
A: 問題文にあるとおり「aデータベース」、すなわちサービスサポート情報を一元管理するデータベース(一般にはナレッジベース)です。
関連キーワード: ITIL, インシデント管理、問題管理、サービスデスク、根本原因分析
設問4:問題管理プロセスについて(1)、(2)に答えよ。
(1)本事例の問題の原因について、eに入れる適切な字句を10字以内で答えよ。
模範解答
e:電源容量の不足
解説
解答の論理構成
- 直接原因を示す文の確認
問題文には、 「今回のサーバ停止の直接原因は、同電力線におけるeであった。」
と明記されています。 - 同電力線の状況を整理
・「電源容量が230kVAに制限されており、現在の設備の制約上、増強ができない。」
・停止したサーバ群(10台)の立上げ時消費電力は「20kVA」×10=「200kVA」。
・新たに設置した装置の立上げ時消費電力は「50kVA」。
合計すると「250kVA」で、許容値「230kVA」を超えています。 - 原因を導出
上記の数値関係から、電力線が供給できる「230kVA」を上回ったためにサーバが停止しています。これは電力線側の供給余力が足りない、すなわち「電源容量の不足」が原因と判断できます。 - 結論
よって e に入る字句は
「電源容量の不足」 となります。
誤りやすいポイント
- 「過負荷」「瞬間的なピーク電流」など、技術的には近しい表現を選んでしまう。問題文は「容量が230kVAに制限」と具体的に示しているため、「電源容量の不足」と書くのが適切です。
- サーバ10台だけの合計「200kVA」で閾値を下回るため問題ないと早合点する。新装置の「50kVA」を加算し、ピーク時の総消費電力を計算する必要があります。
- 図を詳しく読まずに“休日なら大丈夫”と条件づけてしまう。平日ピーク帯の数値と装置の立上げ電力を足し合わせ、閾値との比較を行うことが大切です。
FAQ
Q: 「電源容量の不足」と「電源障害」は何が違いますか?
A: 「電源容量の不足」は設計上用意している供給能力が需要を下回る状態を指します。一方「電源障害」は停電や配線トラブルなど電源そのものが故障・停止する事象を指します。今回のケースは前者です。
A: 「電源容量の不足」は設計上用意している供給能力が需要を下回る状態を指します。一方「電源障害」は停電や配線トラブルなど電源そのものが故障・停止する事象を指します。今回のケースは前者です。
Q: インシデント管理と問題管理の役割分担は?
A: インシデント管理は「サービスを早期復旧すること」が目的で、暫定対処や迂回策を優先します。問題管理は「根本原因の究明と再発防止」が目的で、恒久対策を立案・実施する役割です。
A: インシデント管理は「サービスを早期復旧すること」が目的で、暫定対処や迂回策を優先します。問題管理は「根本原因の究明と再発防止」が目的で、恒久対策を立案・実施する役割です。
Q: 電力線の容量制限を超えた場合、他にどのような影響がありますか?
A: ブレーカが動作して全機器が同時停止する、あるいは電圧降下で機器が誤動作するなど、広範囲に影響が及ぶ可能性があります。そのため容量計画とピーク管理は非常に重要です。
A: ブレーカが動作して全機器が同時停止する、あるいは電圧降下で機器が誤動作するなど、広範囲に影響が及ぶ可能性があります。そのため容量計画とピーク管理は非常に重要です。
関連キーワード: 容量計画、電力負荷、インシデント管理、問題管理
設問4:問題管理プロセスについて(1)、(2)に答えよ。
(2)採用された問題解決策について、f、gに入れる適切な数字を図から読み取り、それぞれ整数で答えよ。
模範解答
f:7
g:20
解説
解答の論理構成
- まず【問題文】で、今回のサーバ停止の直接原因は「同電力線におけるe」であると明示されています。また「立上げ時の消費電力が50kVAの当該装置を立ち上げる場合、少なくとも平日のf~g時の間を避けなければならない」と述べられています。
- 図(平日木曜日の詳細グラフ)を読むと、電力線の使用量は
• 早朝~午前 時頃に急上昇し、 • 夕方 時頃まで kVA 付近で高止まり、 • その前後は大きく低下していることが分かります。
これは、電源容量「230kVA」に対し「10台×20kVA=200kVA」+「既存システム」≒上限近くまで張り付いている時間帯を示しています。 - したがって、ピーク帯の開始が 時、ピーク帯の終了が 時と読み取れます。ピーク帯で 50kVA を追加すると「230kVA」を超過し、再びeが発生する恐れがあるため、この時間帯を避ける必要があります。
- よって、f には「7」、g には「20」が入ります。
誤りやすいポイント
- 230kVA の容量と 200kVA 付近の消費電力を「十分余裕がある」と誤解し、ピーク帯を短く見積もってしまう。
- グラフの「時」目盛を読み違え、ピーク開始を 8 時、終了を 19 時とずらしてしまう。
- 「立上げ時の消費電力は50kVA、通常動作時は5~10kVA」という記述を読み落とし、通常動作時の値で判定してしまう。
FAQ
Q: グラフは木曜日だけ詳細ですが、他の平日にも当てはめて良いのでしょうか?
A: 【問題文】に「平日は、曜日によらず同じ推移を示していることが分かる」とあるため、木曜日の推移を平日全体に適用して問題ありません。
A: 【問題文】に「平日は、曜日によらず同じ推移を示していることが分かる」とあるため、木曜日の推移を平日全体に適用して問題ありません。
Q: ピーク帯の終了時刻は 19 時でなく 20 時では?
A: 詳細グラフでは 19~20 時にかけてまだ約 kVA を維持しています。50kVA を加えると 230kVA を超えるため、20 時まで避ける必要があります。
A: 詳細グラフでは 19~20 時にかけてまだ約 kVA を維持しています。50kVA を加えると 230kVA を超えるため、20 時まで避ける必要があります。
Q: 立ち上げさえピークを外せば、その後はいつ電源を落としても良いのですか?
A: 装置が「通常動作時は5~10kVA」なので、起動後はピーク帯へ戻っても容量を圧迫しません。ただし運用手順で装置停止・再起動の時間帯も統制すべきです。
A: 装置が「通常動作時は5~10kVA」なので、起動後はピーク帯へ戻っても容量を圧迫しません。ただし運用手順で装置停止・再起動の時間帯も統制すべきです。
関連キーワード: サービスデスク、インシデント管理、問題管理、電源容量、キャパシティ管理
設問5:
インシデントの発生後に採る後手のアクションをリアクティブなアクションといい、インシデントを発生させるおそれがある未知の根本原因を突き止めて解決策を提供する先手のアクションをプロアクティブなアクションという。サーバ停止というインシデントを発生させないためにL社が採るべきであったプロアクティブなアクションを解答群の中から二つ選び、記号で答えよ。
解答群
ア:業務システムが実施している業務を手作業で実施するための訓練をする。
イ:業務システムの再起動時間を短縮するために、運用手順を見直す。
ウ:サーバや装置を設置する前に、消費電力の最大値の合計を確認する。
エ:サーバを直ちに修理できるよう、サーバの監視担当を定期的に教育する。
オ:電力線の消費電力の記録を定期的に確認し、増減の傾向を把握する。
模範解答
ウ、オ
解説
解答の論理構成
-
インシデント発生の根本原因を把握
- 問題文には「今回のサーバ停止の直接原因は、同電力線におけるeであった」とあります。
- 同じ電力線に「立上げ時の消費電力は50kVA」の装置を追加した結果、電源容量「230kVA」を超えたことが停止の引き金でした。
-
プロアクティブなアクションとは
- 小問説明で「インシデントを発生させるおそれがある未知の根本原因を突き止めて解決策を提供する先手のアクション」と定義されています。
- したがって “電源容量オーバー” を未然に防ぐ施策が選定基準になります。
-
各選択肢を評価
- ア:手作業訓練 → 障害後の対応であり後手(リアクティブ)。
- イ:再起動時間短縮 → 既に障害が起きた後の復旧速度向上でリアクティブ。
- ウ:「サーバや装置を設置する前に、消費電力の最大値の合計を確認する。」
• 追加装置による「50kVA」増分が電源容量「230kVA」を超えるかどうか事前に確認する行為で、原因を未然に排除できます。 - エ:監視担当の教育 → 障害発生後に即修理できる体制づくりでリアクティブ。
- オ:「電力線の消費電力の記録を定期的に確認し、増減の傾向を把握する。」
• 問題文にある週次・日次グラフのように消費電力を定点観測することで、ひっ迫を事前に察知できます。
-
結論
- 未然防止(プロアクティブ)に該当するのは「ウ」と「オ」です。
誤りやすいポイント
- 「再起動時間短縮」や「監視担当の教育」は一見“備え”に見えるため選びやすいですが、どちらも障害が起きた後の対処策です。
- 電力関連の数値(「20kVA」「50kVA」「230kVA」など)が多数登場するため、混同して容量超過の深刻さを見落としがちです。
- 問題文中の「週次及び日次」のグラフを“運用後の分析”と誤解し、記録を取る行為(オ)をリアクティブと誤判断するケースがあります。
FAQ
Q: 「ウ」と「オ」の両方を選ぶ必要がありますか?
A: はい。装置導入前の確認(ウ)と導入後の継続監視(オ)の両輪で初めてプロアクティブな電力管理が成立します。
A: はい。装置導入前の確認(ウ)と導入後の継続監視(オ)の両輪で初めてプロアクティブな電力管理が成立します。
Q: 電力線の容量を増強するという選択肢がないのはなぜですか?
A: 問題文に「現在の設備の制約上、増強ができない」と明記されているため、現実的な対策は設置前確認と継続監視になります。
A: 問題文に「現在の設備の制約上、増強ができない」と明記されているため、現実的な対策は設置前確認と継続監視になります。
Q: “装置ごとのピーク電力”ではなく“平均電力”を見れば十分では?
A: ピーク時に「立上げ時の消費電力は50kVA」と跳ね上がる装置があるため、平均値だけでは容量超過を見逃すおそれがあります。最大値での検証が必須です。
A: ピーク時に「立上げ時の消費電力は50kVA」と跳ね上がる装置があるため、平均値だけでは容量超過を見逃すおそれがあります。最大値での検証が必須です。
関連キーワード: インシデント管理、問題管理、キャパシティ計画、電源容量、プロアクティブ保守
