応用情報技術者 2016年 秋期 午後 問04
災害復旧対策(ディザスタリカバリ)に関する次の記述を読んで、設問1~4に答えよ。
G社は、全国に営業店をもつ、中堅の専門商社である。現在、東京の本社ビルの一室をサーバルームとして、社内業務システムを運用している。今年度の事業計画に事業継続計画の策定が挙げられていて、その一環として、本社ビルのサーバルームが災害などで使用不能となった際の対策を検討することになった。
〔G社の社内業務システム〕
現在、G社の社内業務システムには、会計、販売管理、人事の三つのシステムがあり、それぞれWebシステムとして実現している。社内業務システムのネットワーク構成を図1に示す。各Webサーバはアプリケーションサーバの機能も有しており、仮想サーバで実現している。データベースサーバ(以下、DBサーバという)は2台のクラスタ構成で、全システムで共用している。営業店から社内業務システムへはIP-VPN経由でアクセスしている。
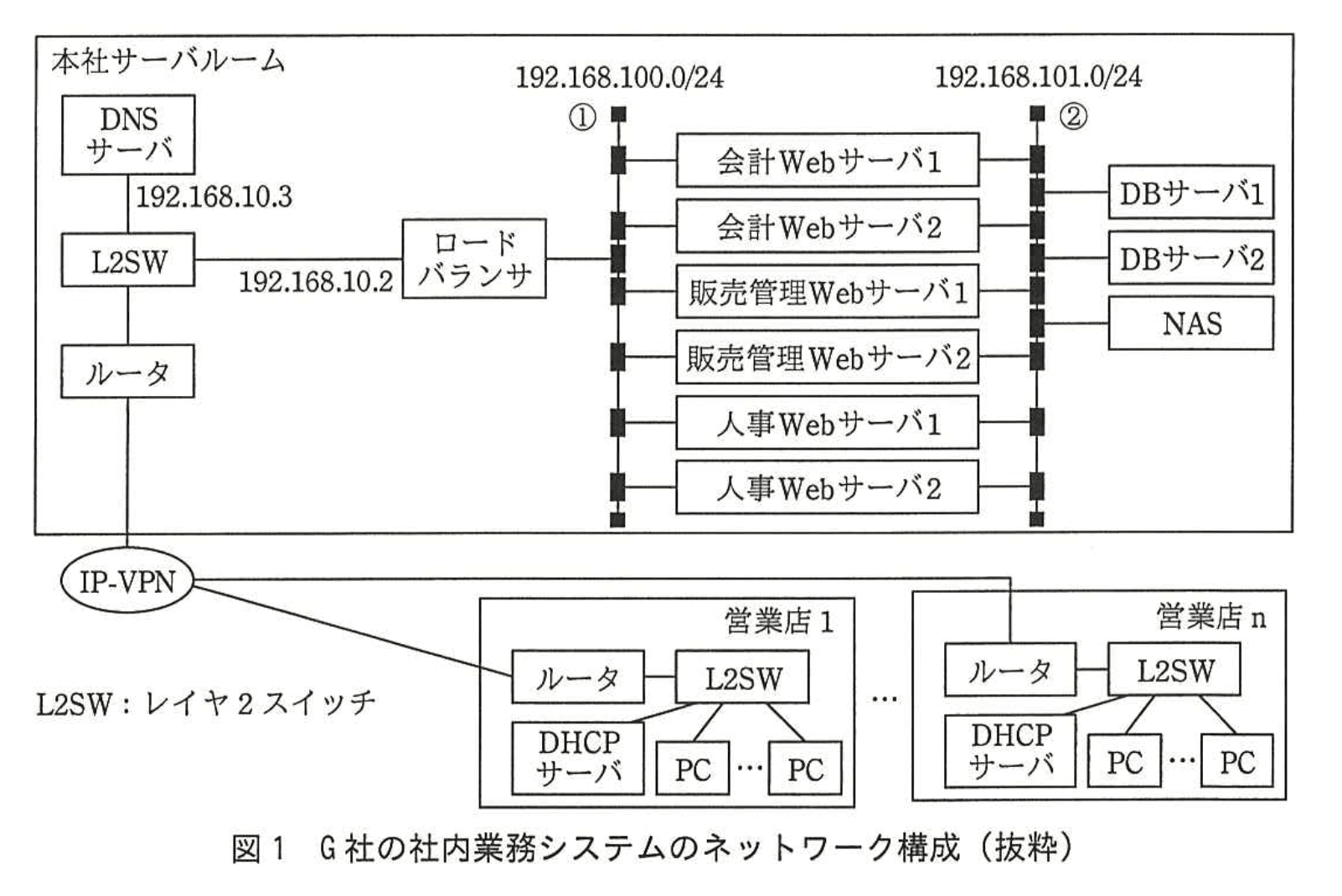
各システムにアクセスする際のURLを表1に示す。ロードバランサでは、URLのパスから対応するシステムのWebサーバにPCからのリクエストを振り分けている。また、複数台あるWebサーバの負荷分散も行っている。
営業店のPCが社内業務システムにアクセスする際は、DNSを利用してwebap.example.co.jpのIPアドレスを取得してアクセスする。DNSサーバのIPアドレスは、PCの起動時に各営業店のDHCPサーバから配布される。現在、プライマリDNSサーバとして、192.168.10.3が登録されており、セカンダリDNSサーバは未登録である。DNSに登録されているリソースレコードの情報を表2に示す。

DBサーバ上のデータベースのバックアップは、フルバックアップと更新ログから成る。毎日深夜1時にフルバックアップを取得し、過去1週間分をNASに保管している。また、1時間ごとに、その1時間の間に発生したトランザクションの更新ログを採取し、1ファイルとしてNASに保管している。フルバックアップの取得は30分以内、更新ログの採取は5分以内に完了する。データベースが壊れた場合は、フルバックアップと、フルバックアップ取得後からデータベースが壊れるまでに採取した更新ログから、データベースを復旧する。
〔災害復旧対策〕
災害復旧対策において目標とする復旧のレベルの指標として、目標復旧時間(RTO:Recovery Time Objective)及び目標復旧時点(RPO:Recovery Point Objective)を用いる。RTOは、システムが使用不能になった時(以下、災害時刻という)から、業務が再開されるまでに掛かる時間の目標を表す。RPOは、災害時刻にどれだけ近い時刻の状態にデータを復旧できるかの目標を、災害時刻との時間差で表す。RTOとRPOを検討した結果、RTOは24時間、RPOは1時間とした。
別の拠点に、本社ビルと同等のサーバルームを用意するのはコストが掛かり過ぎ、実現が難しい。そこで、低コストで災害復旧対策を実現する方法を調査したところ、クラウドサービスを利用する方法があることが分かった。調査したクラウドサービスでは、コストは、サーバが稼働している時間、使用しているストレージの容量、及び下りデータの通信量に応じて掛かるので、サーバを停止していれば安価になると考えた。
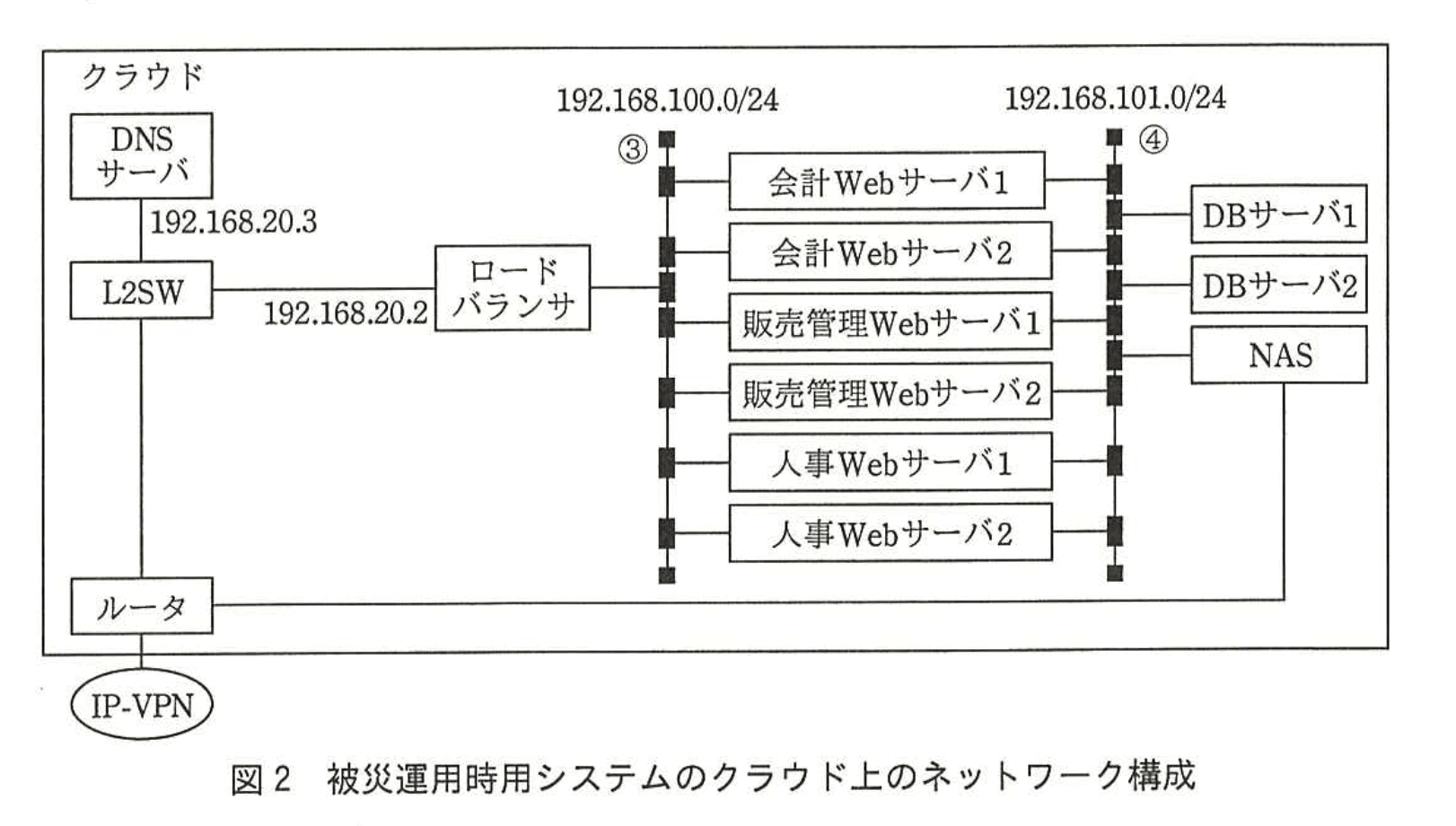
各システムのWebサーバのイメージファイルから、クラウド上にWebサーバを作成し、DBサーバには本社と同じデータベースを作成しておく。DNSサーバは本社と同じ設定でセカンダリDNSサーバとして使えるように稼働しておく。通常時は、ロードバランサ、Webサーバ、DBサーバは停止しておく。本社でデータベースのバックアップを作成次第、クラウドのNASにアップロードする。被災運用が発動された際は、ロードバランサ、DBサーバを起動して、データベースを復旧し、Webサーバを起動して動作確認をした後、DNSの登録内容を変更して被災運用を開始する。被災運用時用システムのクラウド上のネットワーク構成を図2に示す。
〔被災運用の発動手順〕
実際に被災運用が発動された際の手順を表3のとおり定めた。また、各作業に必要な時間を表4に示す。全システムの動作確認が完了する前に、営業店から被災運用時用システムにアクセスすることがないよう、DNSの変更は手順の最後にした。
動作確認の際は、DNSを利用せす被災用時用のロードバランサのIPアドレスを用いる。

設問1:
G社では、10月10日の10時30分に本社ビルのサーバルームが被災して使用できなくなってしまった場合、社内業務システムは、いつまでに、いつ時点のデータで被災運用が開始されることを目標としているかを答えよ。
模範解答
いつまでに:10月11日10時30分
いつ時点の:10月10日9時30分
解説
解答の論理構成
-
被災時刻の確認
問題が想定する災害時刻は【問題文】「10月10日の10時30分」です。 -
目標復旧時間(RTO)の適用
【問題文】には「RTOは24時間」とあります。
RTOは「災害時刻から、業務が再開されるまでに掛かる時間の目標」を示します。
したがって
災害時刻 10月10日10時30分
+ RTO 24時間
= 10月11日10時30分
よって “いつまでに” は「10月11日10時30分」となります。 -
目標復旧時点(RPO)の適用
同じく【問題文】で「RPOは1時間」と示されています。
RPOは「災害時刻にどれだけ近い時刻の状態にデータを復旧できるか」の目標です。
つまりデータは災害時刻の1時間前まで戻れば良いということです。
10月10日10時30分 − 1時間 = 10月10日9時30分
よって “いつ時点のデータで” は「10月10日9時30分」となります。 -
まとめ
・いつまでに:10月11日10時30分
・いつ時点の:10月10日9時30分
誤りやすいポイント
- RTO と RPO の役割を逆に解釈する
「RTO=データ時点」「RPO=再開時刻」と勘違いしやすいので注意です。 - 災害時刻からの計算基点を誤る
例:10月10日“0時”を起点にしてしまうと 24 時間後がずれます。 - 「1時間」の数え方
“丸 1 時間前”を求めるため、分単位(10時30分 → 9時30分)まで正確に差し引きます。
FAQ
Q: RTO 24時間なら、被災当日中に再開を目指す必要はないのですか?
A: はい。「24時間以内」に再開できれば目標を満たすため、翌日の同時刻までに業務再開できれば合格となります。
A: はい。「24時間以内」に再開できれば目標を満たすため、翌日の同時刻までに業務再開できれば合格となります。
Q: RPO 1時間のとき、更新ログ取得間隔が1時間で足りますか?
A: 更新ログは「1時間ごと」に採取しているため、最悪でも直前のログまで適用すれば災害時刻の1時間前へ復旧でき、RPO を満たせます。
A: 更新ログは「1時間ごと」に採取しているため、最悪でも直前のログまで適用すれば災害時刻の1時間前へ復旧でき、RPO を満たせます。
Q: RPO をさらに短くするには何を変更すればよいですか?
A: 更新ログの採取間隔を短縮し、差分バックアップやリアルタイムレプリケーションを導入する方法が代表的です。
A: 更新ログの採取間隔を短縮し、差分バックアップやリアルタイムレプリケーションを導入する方法が代表的です。
関連キーワード: RTO, RPO, バックアップ、更新ログ、ディザスタリカバリ
設問2:
図1中の①と図2中の③のネットワークアドレス、及び図1中の②と図2中の④のネットワークアドレスが同じである理由を35字以内で述べよ。
模範解答
Webサーバのイメージファイルをそのまま使用するから
解説
解答の論理構成
- 本社とクラウドの Web サーバはまったく同じ OS・ミドルウェア設定を含むイメージで展開すると明記されています。
――【問題文】「各システムのWebサーバのイメージファイルから、クラウド上にWebサーバを作成し」
既存イメージには本社側で使用している IP アドレス帯の設定が残っています。 - もしクラウド側のネットワークを別アドレスにすると、イメージを展開後に全サーバの TCP/IP 設定やアプリケーション設定を書き換える追加作業が必要になります。これは RTO「24時間」に悪影響です。
- そこで、図1中の「①192.168.100.0/24」「②192.168.101.0/24」と、図2中の「③」「④」を同じネットワークアドレスにしておけば、イメージを“そのまま”起動するだけで稼働できます。
- 以上より、解答は「Webサーバのイメージファイルをそのまま使用するから」となります。
誤りやすいポイント
- 「DNS を同じ設定にするため」と考えがちですが、DNS 変更は被災運用の最後(表3 手順10)で実施されるため理由になりません。
- 「IP‐VPN の閉域網だから同一アドレスでも衝突しない」という説明は不十分です。ネットワーク衝突を回避するだけなら他アドレスでも構い、設問は“なぜ同じにするのか”を問います。
- RPO(データ復旧点)と混同し、「1時間以内に復旧するため」と書くミス。アドレス設計は復旧点ではなく復旧作業時間短縮(RTO)に寄与します。
FAQ
Q: クラウド側で DHCP を使って自動でアドレスを振り直す方法では駄目ですか?
A: 可能ですが、イメージ内のアプリケーション設定やスクリプトに固定 IP が埋め込まれている恐れがあります。同一アドレスにする方が安全かつ迅速です。
A: 可能ですが、イメージ内のアプリケーション設定やスクリプトに固定 IP が埋め込まれている恐れがあります。同一アドレスにする方が安全かつ迅速です。
Q: 本社とクラウドで同じアドレスを使うと、VPN 越しに重複しませんか?
A: 災害時は本社のルータ・サーバが停止している前提なので重複は発生しません。平常時はクラウドの対象サーバを停止させているため問題ありません。
A: 災害時は本社のルータ・サーバが停止している前提なので重複は発生しません。平常時はクラウドの対象サーバを停止させているため問題ありません。
Q: なぜ Web サーバだけでなく DB サーバ側ネットワークも同じにしているのですか?
A: Web サーバ内の DB 接続設定(接続先サブネットや IP)がイメージに含まれているため、バックエンド側も同一アドレスにすることで設定変更を不要にしています。
A: Web サーバ内の DB 接続設定(接続先サブネットや IP)がイメージに含まれているため、バックエンド側も同一アドレスにすることで設定変更を不要にしています。
関連キーワード: イメージファイル、RTO, 固定IP, ネットワーク設計、災害復旧
設問3:DHCPサーバとDNSサーバは、あらかじめ現在の設定を変更しておかないと、災害が発生した場合に〔被災運用の発動手順〕に従って作業を進めても、営業店のPCから被災運用時用システムにアクセスすることができない。被災運用に対する準備について、(1)、(2)に答えよ。
(1)DHCPサーバの設定で、あらかじめ変更しておくべき内容を40字以内で述べよ。
模範解答
セカンダリDNSサーバとして、192.168.20.3を登録する。
解説
解答の論理構成
- 依存関係の把握
- 営業店 PC は「DNSサーバのIPアドレスは、PCの起動時に各営業店のDHCPサーバから配布される。」ため、名前解決ができないと業務システムへ接続できません。
- 現状の問題点
- DHCP では「現在、プライマリDNSサーバとして、192.168.10.3 が登録されており、セカンダリDNSサーバは未登録である。」とあり、本社が被災すると 唯一の DNS サーバが停止 してしまいます。
- 対策方針
- クラウド側では「DNSサーバは本社と同じ設定でセカンダリDNSサーバとして使えるように稼働しておく。」と計画されています。
- したがって、営業店 PC がこのクラウド DNS にフォールバックできるよう、あらかじめ DHCP でセカンダリ DNS を配布しておく必要があります。
- 具体的設定値
- クラウド DNS の IP は 192.168.20.3。
- DHCP の “セカンダリ DNS サーバ” 欄に同 IP を登録することで、被災時も PC はクラウド DNS へ自動的に問い合わせ、被災運用時用システムへ到達できます。
以上より、模範解答「セカンダリDNSサーバとして、192.168.20.3 を登録する。」となります。
誤りやすいポイント
- プライマリ DNS の書き換えと勘違いし、192.168.10.3 を置き換えてしまう
→ 平常時の通信が本社を経由しなくなり、テスト環境で思わぬ影響が出るおそれがあります。 - DHCP ではなく DNS レコード側 (A レコードや TTL) の変更で対応できると思い込む
→ 名前解決先が得られない根本原因は “問い合わせ先サーバ” なので、レコードをいくら整備しても PC から届きません。 - セカンダリ DNS を「被災時に手動登録すればよい」と考える
→ 災害発生後に各営業店で DHCP 設定を変更するのは非現実的で、RTO24時間を守れません。
FAQ
Q: プライマリ DNS もクラウド側にしてはだめですか?
A: 平常時トラフィックを本社外へ出さない方がネットワーク遅延・コスト面で有利なため、本社をプライマリ、クラウドをセカンダリとする構成が妥当です。
A: 平常時トラフィックを本社外へ出さない方がネットワーク遅延・コスト面で有利なため、本社をプライマリ、クラウドをセカンダリとする構成が妥当です。
Q: DHCP リース期間が長い場合、被災直後に PC がセカンダリへ切り替わらないのでは?
A: リース期間中でもプライマリに到達できなければ OS は自動的にセカンダリへ問い合わせます。手動更新は不要です。
A: リース期間中でもプライマリに到達できなければ OS は自動的にセカンダリへ問い合わせます。手動更新は不要です。
Q: TTL を短く設定しておけば DNS サーバが 1 台でも問題ないですか?
A: TTL はキャッシュ保持時間であり、問い合わせ先サーバが停止した場合の可用性には直接寄与しません。複数 DNS サーバが必須です。
A: TTL はキャッシュ保持時間であり、問い合わせ先サーバが停止した場合の可用性には直接寄与しません。複数 DNS サーバが必須です。
関連キーワード: DHCP, DNSフェイルオーバー、セカンダリサーバ、可用性設計、事業継続
設問3:DHCPサーバとDNSサーバは、あらかじめ現在の設定を変更しておかないと、災害が発生した場合に〔被災運用の発動手順〕に従って作業を進めても、営業店のPCから被災運用時用システムにアクセスすることができない。被災運用に対する準備について、(1)、(2)に答えよ。
(2)表2のDNSサーバの設定で、あらかじめ変更しておくべき内容を解答群の中から選び、記号で答えよ。
解答群
ア:RDATAを192.168.20.2に変更
イ:TTLを600に変更
ウ:TTLを172800に変更
エ:TYPEをAAAAに変更
模範解答
イ
解説
解答の論理構成
-
現行設定の確認
表2には次のように記載されています。
・「TTL (Time to Live)」=「86400」
これは を意味し、PC やキャッシュ DNS が 24 時間は古い情報を保持することになります。 -
災害時の運用フローとの整合
〔被災運用の発動手順〕の「10 DNSの登録内容を変更する。」で IP アドレスを書き換えても、TTL が「86400」のままでは営業店側のキャッシュが切れず、新しい IP へ誘導できません。RTO が「24時間」なので最悪ギリギリ達成できますが、実際には DNS 変更後すぐに切り替わらないと復旧作業が長引きます。 -
事前変更の指針
TTL を短く設定しておけば、キャッシュが速やかに失効し、手順10実行後およそその TTL で全端末が新 IP を引き当てられるようになります。運用現場では 10 分 ~ 数十分が一般的な目安で、本問の解答群には「TTLを600に変更」が用意されています。
「600」は であり、切替え遅延を許容範囲に抑えられます。 -
他選択肢との比較
ア: 事前に「RDATAを192.168.20.2」にしてしまうと、平常時からクラウド側へトラフィックが流れ想定外。
ウ: 「TTLを172800」にすると 48 時間もキャッシュが残り逆効果。
エ: IPv6 用の「TYPEをAAAA」に変更しても問題の根本(キャッシュ時間)は解決しません。
よって、あらかじめ変更すべき項目は「イ:TTLを600に変更」です。
誤りやすいポイント
- 「RTO が24時間だから TTL=86400 でも大丈夫」と考えてしまう
→ DNS 変更後 24 時間待つと他作業との合計で RTO を超過する可能性があります。 - 事前に RDATA をクラウド IP に変えておく誤り
→ 平常時のアクセスがクラウドへ流れコスト増大、性能・セキュリティの面でも想定外です。 - AAAA レコード追加で万全と誤解
→ IPv6 対応は別問題。キャッシュ時間短縮には何の影響もありません。
FAQ
Q: TTL を短くし過ぎると問題はありますか?
A: DNS への問い合わせ回数が増加し、DNS サーバ負荷やネットワークトラフィックが増えます。通常運用と被災運用のバランスを考慮し、10 分〜1 時間程度がよく使われます。
A: DNS への問い合わせ回数が増加し、DNS サーバ負荷やネットワークトラフィックが増えます。通常運用と被災運用のバランスを考慮し、10 分〜1 時間程度がよく使われます。
Q: 手順10を前倒しして DNS を早く変更してはいけないのでしょうか?
A: 表3にあるとおり、動作確認「全システムの動作確認が完了する前に、営業店から被災運用時用システムにアクセスすることがないよう、DNSの変更は手順の最後にした。」ため、前倒しはリスクがあります。
A: 表3にあるとおり、動作確認「全システムの動作確認が完了する前に、営業店から被災運用時用システムにアクセスすることがないよう、DNSの変更は手順の最後にした。」ため、前倒しはリスクがあります。
Q: DHCP 側では何を準備するのですか?
A: 各営業店 DHCP にセカンダリ DNS(クラウドの「192.168.20.3」)を追加しておくことで、本社 DNS が停止しても名前解決が行えます。
A: 各営業店 DHCP にセカンダリ DNS(クラウドの「192.168.20.3」)を追加しておくことで、本社 DNS が停止しても名前解決が行えます。
関連キーワード: DNSキャッシュ、TTL設定、DRサイト切替、RTO/RPO, ネームサーバ冗長化
設問4:〔被災運用の発動手順〕について(1)、(2)に答えよ。
(1)10月10日の10時30分に本社ビルのサーバルームが被災して使用できなくなってしまい、11時に被災運用を発動した場合、社内業務システムは、いつから被災運用が開始できるかを答えよ。
模範解答
10月10日17時00分
解説
解答の論理構成
-
災害発生と被災運用発動の基点
- 本社サーバルームは「10月10日の10時30分」に被災。
- 「11時に被災運用を発動」すると問題文にある。
したがって 11 時を 0 時間目として復旧作業を積み上げる。
-
実施する作業手順と所要時間
表3・表4より引用すると、被災運用発動時の作業は次の順序と時間で行う。 -
更新ログの本数を確定
- 最新フルバックアップは「毎日深夜1時」に取得済み。
- 更新ログは「1時間ごと」に採取。
- 災害時刻は 10 時 30 分なので、取得済みの更新ログは
1:00–2:00 から 9:00–10:00 までの 9 本。 - 反映時間は 9 本 × 「10分」= 90 分。
-
全作業時間の合計
20 分(手順1)
+ 30 分(手順2)
+ 90 分(手順3)
+ 10 分 × 3(手順4・6・8)= 30 分
+ 60 分 × 3(手順5・7・9)= 180 分
+ 10 分(手順10)
= 360 分 = 6 時間 -
被災運用開始時刻
発動時刻 11:00 + 6 時間 = 17:00
よって社内業務システムは「10月10日17時00分」から被災運用を開始できる。
誤りやすいポイント
- 更新ログの本数を 10 本と勘違いし「10:00–11:00」分まで加算してしまう。
災害時点が 10:30 であり、そのファイルはまだ採取されていない。 - Web サーバが各システム 2 台ある図と混同し「起動 6 回」と数えてしまう。
手順では 1 システム=1 回の起動で計 3 回。 - 「TTL 86400」を考慮して DNS 反映まで 24 時間かかると思い込む。
設問は“運用開始”時刻を問うため、登録変更完了時をもって良い。
FAQ
Q: RPO が「1時間」ですが、30 分のデータ損失が発生しても問題ないのですか?
A: はい。RPO は“最大許容損失時間”を示します。10 時 30 分時点で最新の更新ログは 9:00–10:00 分までなので、損失は 30 分以内に収まり要件を満たします。
A: はい。RPO は“最大許容損失時間”を示します。10 時 30 分時点で最新の更新ログは 9:00–10:00 分までなので、損失は 30 分以内に収まり要件を満たします。
Q: DNS 変更に伴うキャッシュが残っているとアクセスできないのでは?
A: 被災運用開始時刻は“システム側の準備完了”を示します。利用拠点への周知やキャッシュ対策は別途運用手順でフォローします。
A: 被災運用開始時刻は“システム側の準備完了”を示します。利用拠点への周知やキャッシュ対策は別途運用手順でフォローします。
Q: 動作確認を並列に行えばもっと短縮できますか?
A: クラウド内リソースの同時使用料金と作業者の人数を考慮し順次確認する方式を採用しています。手順を変更する際はコストと体制の両面から再検討が必要です。
A: クラウド内リソースの同時使用料金と作業者の人数を考慮し順次確認する方式を採用しています。手順を変更する際はコストと体制の両面から再検討が必要です。
関連キーワード: RTO, RPO, バックアップ、更新ログ、DNS
設問4:〔被災運用の発動手順〕について(1)、(2)に答えよ。
(2)表3中の下線⑤で変更する登録内容について、表2の項目と変更後の値を答えよ。
模範解答
項目:RDATA
変更後の値:192.168.20.2
解説
解答の論理構成
-
DNS が解決するホスト名
問題文には「営業店のPCが社内業務システムにアクセスする際は、DNSを利用して webap.example.co.jp のIPアドレスを取得してアクセスする。」とあります。したがって被災時も同一ホスト名でアクセスさせる必要があります。 -
現行レコードの確認
表2 に示されたリソースレコードは
・NAME: webap.example.co.jp
・TYPE: A
・CLASS: IN
・TTL (Time to Live): 86400
・RDATA: 192.168.10.2
です。切り替え対象となるのは IP アドレスを示す「RDATA」欄のみです。 -
被災運用時に参照させる IP アドレス
クラウド側ロードバランサの IP アドレスは図2に「192.168.20.2」と明示されています。このロードバランサが各 Web サーバ群へ振り分けるため、被災後は営業店 PC が必ずこの IP へ到達しなければなりません。 -
手順 10 の作業内容
表3 の作業順「10」に「⑤DNSの登録内容を変更する。」とあります。変更する対象は 2. で述べたとおり RDATA 欄、変更後の値は 3. のとおり「192.168.20.2」となります。 -
以上より
項目:RDATA
変更後の値:192.168.20.2
誤りやすいポイント
- 「TTL を短くするのでは?」と考えがちですが、TTL は問い合わせ側キャッシュ保持時間の設定であり、被災直前に変更しておくべき項目です。設問は“被災時に実際に行う登録変更”を問うており、求められるのは IP アドレスだけです。
- 「NAME を別ホスト名に変える」案は、ユーザ側 URL 変更・ブックマーク更新が必要になるため災害時対応では採用されません。
- TYPE を AAAA(IPv6)と誤記するミスも散見されます。問題文中すべて IPv4 で構成されています。
FAQ
Q: アドレスを 192.168.20.2 に変えるだけで RPO「1時間」を満たせるのですか?
A: はい。データベースは毎時の更新ログで 1 時間以内の差分を吸収できるため、DNS 切替は可用性確保の手順であり RPO には影響しません。
A: はい。データベースは毎時の更新ログで 1 時間以内の差分を吸収できるため、DNS 切替は可用性確保の手順であり RPO には影響しません。
Q: TTL を短くしておいた方が早く切り替わるのでは?
A: 平時に TTL を短縮しておけばキャッシュ保持時間が短くなり切替伝播が速まります。しかし設問は「実際に被災が発生し手順を実行する場面」を想定しており、TTL 変更は問われていません。
A: 平時に TTL を短縮しておけばキャッシュ保持時間が短くなり切替伝播が速まります。しかし設問は「実際に被災が発生し手順を実行する場面」を想定しており、TTL 変更は問われていません。
Q: セカンダリ DNS サーバでの変更作業は別途必要ですか?
A: 問題文に「DNSサーバは本社と同じ設定でセカンダリDNSサーバとして使えるように稼働しておく。」とあるため、プライマリ側が停止してもクラウド側セカンダリに同内容を反映すれば切替は成り立ちます。設問ではレコード内容のみを回答すれば十分です。
A: 問題文に「DNSサーバは本社と同じ設定でセカンダリDNSサーバとして使えるように稼働しておく。」とあるため、プライマリ側が停止してもクラウド側セカンダリに同内容を反映すれば切替は成り立ちます。設問ではレコード内容のみを回答すれば十分です。
関連キーワード: RDATA, Aレコード、ロードバランサ、RTO, クラウドバックアップ
