応用情報技術者 2021年 春期 午後 問06
経営分析システムのためのデータベース設計に関する次の記述を読んで、設問1〜4に答えよ。
P社は、個人向けのカーシェアリングサービスを運営するMaaS(Mobility as a Service)事業者である。シェアリングのニーズが高い大都市の地区を中心に、500駐車場で約2,000台の自動車(以下、車両という)を貸し出している。P社には本社のほかに、各地区でのサービス運営を担当する支社が10社ある。本社はサービス全体を統括しており、新サービスの企画やマーケティングなどを行っている。支社は貸出管理システムを用いて現場で車両の貸出管理業務を行っている。
本社では、サービス運営状況を多角的な観点でタイムリーに把握して、適切な意思決定を行うために、貸出管理システムのデータをソースとする経営分析システムを構築することになった。本社の情報システム部のQさんはデータエンジニアに任命され、データサイエンティストであるRさんとプロジェクトを推進することになった。
〔データソースの調査〕
貸出管理システムには、貸出予約及び貸出実績のデータが過去5年間分蓄積されている。貸出管理システムのデータモデルの抜粋を図1に示す。
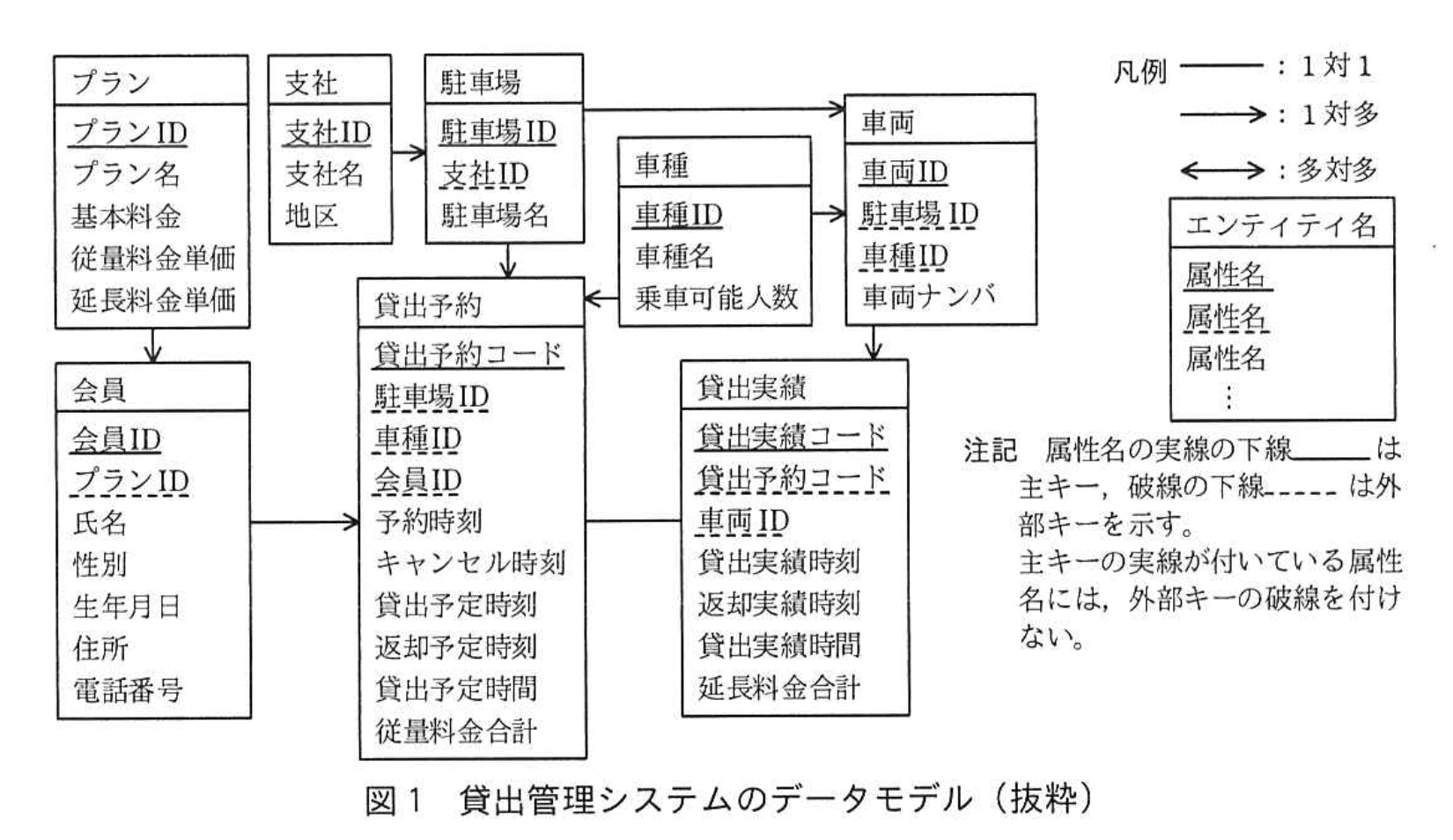
利用希望者はあらかじめ P 社の会員になり、いずれかのプランに加入しておく必要がある。プランごとに基本料金(月額)、従量料金及び延長料金(いずれも 10 分単位)の単価が決まっている。会員が車両を借りたいときは、P 社のホームページで借りたい日時や駐車場、車種などを選択し、貸出を予約する。貸出や返却の実績時刻が予約時の内容と異なる場合であっても、貸出予約の情報は修正しない。従量料金合計は予約時に指定された貸出予定時間を基に算出する。予約時に指定した返却予定時刻より早い時刻に返却しても、従量料金合計は減算しない。予約時に指定した返却予定時刻より遅い時刻に返却した場合は遅延返却として扱う。遅延返却は後の時間帯に予約している別の会員の迷惑となるので、超過した時間については従量料金よりも高い延長料金によって延長料金合計を算出する。これによって、遅延返却の発生件数(以下、遅延返却発生件数という)の低減を図っている。毎月末に当月の基本料金、従量料金合計及び延長料金合計を合算して、翌月に会員に請求する。
貸出管理システムのデータベースでは、データモデルのエンティティ名を表名にし、属性名を列名にして、適切なデータ型で表定義した関係データベースによって、データを管理している。時刻は TIMESTAMP 型、年月日は DATE 型で定義されている。
また、P 社では KPI の一つとして車両稼働率を重視している。車両稼働率とは、各車両における 1 日当たりの貸出実稼働時間の割合である。平均車両稼働率の目標データは、表計算ソフトのデータとして、年月日別・駐車場別・車種別に過去 3 年間分が蓄積されており、それ以前のデータは破棄されている。
〔業務要件の把握〕
P 社の経営企画部では、車両の追加整備計画の立案を検討している。R さんは経営企画部にヒアリングを行い、経営分析システムの業務要件を把握した。業務要件の抜粋を図2に示す。
Qさんは、データソースの調査結果を踏まえて、図2の業務要件の実現可能性を評価した。その結果、①業務要件の一部は経営分析システムの運用開始直後には実現できないことが判明した。対応方針を経営企画部と協議した結果、業務要件は変更せず、運用開始直後の分析は、実現可能な範囲で行うことで合意した。

〔経営分析システムのデータモデル設計〕
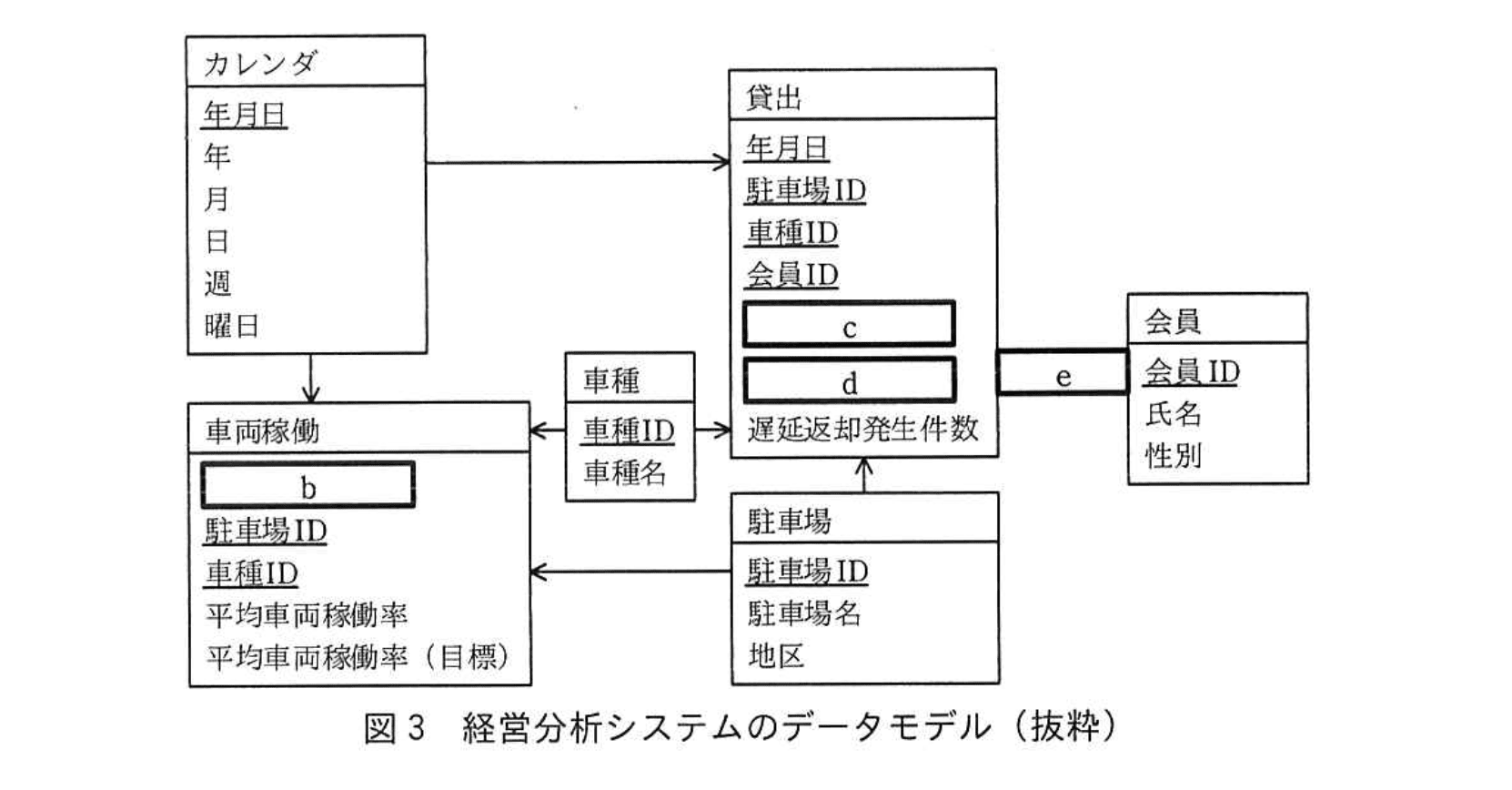
次に、Qさんは図2の業務要件を基に、経営分析システムのデータモデルを多次元データベースとして設計した。多次元データベースの実装とは、データモデルのエンティティ名を表名にし、属性名を列名にして、適切なデータ型で表定義した関係データベースを用いることにした。列指向データベースは用いず、データを行単位で扱う行指向データベースを用いることにした。問合せの処理性能を考慮して、データモデルの構造にはa構造を採用した。経営分析システムのデータモデルの抜粋を図3に示す。
経営分析システムには、最長で過去5年間分のデータを蓄積することにした。
年月日の週と曜日は、事前に定義したSQLのユーザ定義関数を用いて取得できる。
〔データ加工処理の開発〕
貸出管理システムのデータベースから経営分析システムのデータベースへのデータ連携時に、一部のデータを加工する必要がある。Qさんは、データ加工処理用のデータベースを用意し、データ加工を行うバッチ処理プログラムを開発した。図3の貸出表の遅延返却発生件数データを作成するためのものである。ここで、TIMESTAMP_TO_DATE関数は、指定されたTIMESTAMP型の時刻をDATE型の年月日に変換するユーザ定義関数である。
バッチ処理プログラムでは、図4のSQL文で作成したデータを貸出表に挿入する際、遅延返却発生件数が0件のレコードに対する処理も別途行うようになっている。

〔分析のレスポンス性能の改善〕
性能検証を実施したところ、分析対象期間を過去複数年間、時間軸を月別として人気車種及び遅延返却発生件数を分析する場合、各々の分析に時間が掛かり過ぎるので改善してほしいという要望が経営企画部から挙がった。経営分析システムのデータベースのインデックスは既に適切に作成している。分析のレスポンス性能を改善するために、Qさんは②データマートとして集計表を追加した。
設問1:
本文中の下線①について、実現できない業務要件を40字以内で具体的に答えよ。
模範解答
システム稼働後2年間は、過去5年間分の平均車両稼働率の目標比を表示できない。
解説
解答の論理構成
- 業務要件には「表計算ソフトのデータを用いて、平均車両稼働率の目標比…を分析できること。」という記述があります。
- しかしデータソースの調査結果には「平均車両稼働率の目標データは…過去 3 年間分が蓄積されており、それ以前のデータは破棄されている。」とあります。
- さらに業務要件では「過去5年間について、分析対象期間を柔軟に変更して…」と求められています。
- 以上より、5 年間分析を行うには 2 年分の目標データが不足しており、運用開始直後は平均車両稼働率の目標比を 5 年スパンで算出できません。
誤りやすいポイント
- 「前年同期比」は算出できても「目標比」は無理という点を混同しやすい
- 「過去 3 年間分」という制約を見落とし、データが揃っていると思い込む
- 将来的にデータが溜まれば可能になることを「永久に不可能」と誤解する
FAQ
Q: 目標比ではなく実績だけなら 5 年間分析できますか?
A: はい。実績データは「貸出管理システム」に「過去5年間分蓄積」されているため、実績ベースの分析は可能です。
A: はい。実績データは「貸出管理システム」に「過去5年間分蓄積」されているため、実績ベースの分析は可能です。
Q: データ欠損を補完すれば目標比分析も可能ですか?
A: 補完方法次第ですが、要件では実際の目標値を使う想定なので、欠損を機械的に補完すると経営指標の信頼性が損なわれます。
A: 補完方法次第ですが、要件では実際の目標値を使う想定なので、欠損を機械的に補完すると経営指標の信頼性が損なわれます。
Q: 2 年経過後に自動的に要件を満たせますか?
A: 「平均車両稼働率の目標データ」を継続取得する運用を続ければ、2 年後には 5 年分が揃い、システム改修なしで要件を満たせます。
A: 「平均車両稼働率の目標データ」を継続取得する運用を続ければ、2 年後には 5 年分が揃い、システム改修なしで要件を満たせます。
関連キーワード: KPI, 多次元データベース, 車両稼働率, 目標比, データ欠損
設問2:〔経営分析システムのデータモデル設計〕について、(1)、(2)に答えよ。
(1)本文中のaに入れる適切な字句を解答群の中から選び、記号で答えよ。
解答群
ア:3層スキーマ
イ:オブジェクト指向
ウ:スタースキーマ
エ:スノーフレークスキーマ
オ:第三正規形
カ:非正規系
模範解答
a:ウ
解説
解答の論理構成
-
多次元データベースでの分析性能重視
【問題文】には「問合せの処理性能を考慮して、データモデルの構造にはa構造を採用した」と記載されています。OLAP 分析で高速に集計できる構造として代表的なのはスタースキーマです。 -
図3 の形状が“事実表+次元表”の星型
図3 では「貸出」「車両稼働」という事実表を中心に、「カレンダ」「駐車場」「車種」「会員」が一次結合で放射状に配置されています。中間にさらに正規化された表はなく、典型的な星型配置です。 -
スノーフレークスキーマとの対比
スノーフレークスキーマは次元表をさらに細分化して正規化しますが、図3 にはそのような分割が見られません。また、第三正規形や 3 層スキーマは性能より整合性を優先する設計概念で、本問の「問合せの処理性能を考慮して」という条件と合致しません。
以上より、a に入るのは「ウ:スタースキーマ」と判断できます。
誤りやすいポイント
- 「スノーフレークスキーマ」を選択してしまう
“カレンダ”表がやや階層的に見えるため正規化済みと誤解するケースがありますが、次元表は分割されておらず星型です。 - 「第三正規形」を性能向上と結び付ける誤認
正規形は更新系 DB での整合性確保が目的であり、分析系の集計性能には直結しません。 - “行指向データベースを用いる”=正規形と短絡するミス
行指向か列指向かは物理実装の話で、論理スキーマのスタースキーマ採否とは独立です。
FAQ
Q: スタースキーマを採用すると更新時の冗長性は問題になりませんか?
A: 分析用のデータマートは参照中心で更新頻度が低いため、冗長性よりも集計クエリのシンプルさと高速性が優先されます。
A: 分析用のデータマートは参照中心で更新頻度が低いため、冗長性よりも集計クエリのシンプルさと高速性が優先されます。
Q: スノーフレークスキーマに正規化すると性能は必ず落ちますか?
A: 一般に結合回数が増えるためクエリ性能は低下しやすいですが、データ量が極端に大きい場合やキャッシュ戦略によっては差が小さいこともあります。
A: 一般に結合回数が増えるためクエリ性能は低下しやすいですが、データ量が極端に大きい場合やキャッシュ戦略によっては差が小さいこともあります。
Q: 行指向データベースしか使えない場合でもスタースキーマは有効ですか?
A: はい。有効です。列指向ほどではないものの、スタースキーマにより結合が単純化されフィルタリングも効率化されるため、行指向でも一定の性能向上が得られます。
A: はい。有効です。列指向ほどではないものの、スタースキーマにより結合が単純化されフィルタリングも効率化されるため、行指向でも一定の性能向上が得られます。
関連キーワード: スタースキーマ, OLAP, 事実表, 次元表, 正規化
設問2:〔経営分析システムのデータモデル設計〕について、(1)、(2)に答えよ。
(2)図3中のb〜eに入れる適切なエンティティ間の関連及び属性名を答えよ。なお、エンティティ間の関連及び属性名の表記は図1の凡例及び注記に倣うこと(cとdは順不同)。
模範解答
b:年月日
c:年代
d:貸出実績件数
e:←
解説
解答の論理構成
-
[b] の判断
- 図3の「車両稼働」表は日時軸で分析するファクト表です。
- 同表の b(FK → カレンダ.年月日) という注記から、カレンダ 表の主キーと同じ属性を外部キーとして持つことが分かります。
- 図3の「カレンダ」表の主キーは【問題文】に示されているとおり「年月日」です。
- よって b = 年月日。
-
[c]・[d] の判断(順不同)
- 業務要件には「会員の性別・年代別の人気車種」を分析したいとあります。年代は年齢を10歳刻みなどでグルーピングしたディメンションで、集計の切り口になるため貸出ファクトに保持します。
- 同じく業務要件には「貸出実績件数は貸出予定の日付で集計すること」と明記されています。人気車種判定は貸出実績件数の多寡に依存するので、件数そのものを格納するメジャーが必要です。
- 以上より、追加すべき列は「年代」「貸出実績件数」の2つです。
- 順不同ですので c=年代, d=貸出実績件数(逆でも正解)。
-
[e] の判断(エンティティ間の関連)
-
図1の凡例では「1対多」を矢印(→)で表し、矢印の先が “多” 側です。
-
図3のリレーション記載順は「多」側→「1」側で書かれている行もあり、該当箇所は車両稼働 e カレンダとなっています。
-
「車両稼働」は多(ファクト)、「カレンダ」は1(ディメンション)の関係なので、矢印の先が左側=車両稼働 ← カレンダ となります。
-
よって e = ←。
-
誤りやすいポイント
- 年代を会員ディメンションに置き忘れる
年代は会員そのものの属性と考えがちですが、分析を高速化するために貸出ファクトに冗長保持している点に注意が必要です。 - 件数系メジャーを計算式で済ませようとする
「貸出実績件数」を動的 COUNT で済ませると期間指定が広いときレスポンスが悪化します。ファクト表に格納する設計意図を読み取れないと失点します。 - 矢印方向の読み違い
図1の凡例を忘れて「1」側と「多」側を逆に書くと [e] を誤ります。列挙順と矢印向きの関係に要注意です。
FAQ
Q: 年代はどう求めているのですか?
A: 会員の生年月日から当該「年月日」時点の年齢を算出し、10歳刻みなどの区分に変換してバッチで書き込んでいます。動的計算ではありません。
A: 会員の生年月日から当該「年月日」時点の年齢を算出し、10歳刻みなどの区分に変換してバッチで書き込んでいます。動的計算ではありません。
Q: なぜ件数をファクト表に持つのですか?
A: 業務要件に「過去5年間」「時間軸を柔軟に変更」とあり、大量データを都度集計するとレスポンスが悪化するためです。事前集計で「貸出実績件数」列を用意し高速化しています。
A: 業務要件に「過去5年間」「時間軸を柔軟に変更」とあり、大量データを都度集計するとレスポンスが悪化するためです。事前集計で「貸出実績件数」列を用意し高速化しています。
Q: [e] が「←」になる理由をもう一度教えてください。
A: 図1の凡例で矢印の先が“多”側と定義されています。車両稼働が多、カレンダが1なので「車両稼働 ← カレンダ」になります。
A: 図1の凡例で矢印の先が“多”側と定義されています。車両稼働が多、カレンダが1なので「車両稼働 ← カレンダ」になります。
関連キーワード: スタースキーマ, ファクトテーブル, ディメンション, 外部キー, 集計メジャー
設問3:〔データ加工処理の開発〕について、(1)、(2)に答えよ。
(1)図4中のf、gに入れる適切な字句を答えよ。なお、表の列名には必ずその表の相関名を付けて答えよ。
模範解答
f:INNER JOIN 貸出実績 J ON R.貸出予約コード =
g:GROUP BY R.貸出予定年月日, R.駐車場ID, R.車種ID, R.会員ID
解説
解答の論理構成
-
遅延返却を求める条件
【問題文】の図04では
sql WHERE R.返却予定時刻 < J.返却実績時刻と示されています。よって R(貸出予約)と J(貸出実績)を結合しなければ比較はできません。 -
結合すべきキー
貸出予約と貸出実績のリレーションは【問題文】図01に
「貸出予約 → 貸出実績(1対1)」
と示されています。両エンティティを唯一結び付ける列は「貸出予約コード」です。 -
結合方法
遅延返却が発生した予約だけを集計したいので、貸出実績が存在しない行は不要です。従って INNER JOIN を採用します。INNER JOIN 貸出実績 J ON R.貸出予約コード = J.貸出予約コード -
GROUP BY 句
SELECT 句に列挙されている
「R.貸出予定年月日, R.駐車場ID, R.車種ID, R.会員ID」
は集計キーです。COUNT(*) で件数を求めるため、これら4列を GROUP BY に記述します。
以上より、f と g に入る字句は次のとおりです。
[f] INNER JOIN 貸出実績 J ON R.貸出予約コード = J.貸出予約コード
[g] GROUP BY R.貸出予定年月日, R.駐車場ID, R.車種ID, R.会員ID
[f] INNER JOIN 貸出実績 J ON R.貸出予約コード = J.貸出予約コード
[g] GROUP BY R.貸出予定年月日, R.駐車場ID, R.車種ID, R.会員ID
誤りやすいポイント
- 結合条件を WHERE 句に書いてしまい、f を単に INNER JOIN 貸出実績 J として不正解になる。
- 遅延返却がない予約も残すつもりで LEFT JOIN を選択してしまう。
- GROUP BY に COUNT(*) 以外の列(例えば J.返却実績時刻)を含めてしまい、意図しない粒度で集計してしまう。
- 貸出予定年月日を「貸出実績年月日」と誤記するなど、別列をキーにしてしまう。
FAQ
Q: 結合を LEFT JOIN にして WHERE でフィルタする方法ではダメですか?
A: WHERE 句で R.返却予定時刻 < J.返却実績時刻 と書くと、J が NULL の行は除外されるため結果は同じですが、目的が「一致するレコードのみ取得」なので INNER JOIN の方が明示的で読みやすく、最適化もしやすいです。
A: WHERE 句で R.返却予定時刻 < J.返却実績時刻 と書くと、J が NULL の行は除外されるため結果は同じですが、目的が「一致するレコードのみ取得」なので INNER JOIN の方が明示的で読みやすく、最適化もしやすいです。
Q: GROUP BY は SELECT 句に列挙した4列と COUNT() だけで十分ですか?
A: はい。COUNT() は集計関数なので GROUP BY に含める必要はありません。指定すべきは集計キーの4列のみです。
A: はい。COUNT() は集計関数なので GROUP BY に含める必要はありません。指定すべきは集計キーの4列のみです。
Q: 遅延返却発生件数が0件のレコードをどう扱いますか?
A: 本 SQL は遅延返却が発生した予約のみ抽出します。0件のレコードは、「バッチ処理プログラムでは…別途行うようになっている」(【問題文】)とあるとおり、別処理で INSERT します。
A: 本 SQL は遅延返却が発生した予約のみ抽出します。0件のレコードは、「バッチ処理プログラムでは…別途行うようになっている」(【問題文】)とあるとおり、別処理で INSERT します。
関連キーワード: INNER JOIN, 集約関数, GROUP BY, エイリアス, 時間比較
設問3:〔データ加工処理の開発〕について、(1)、(2)に答えよ。
(2)図4のSQL文を実行するべき頻度を2字以内で答えよ。
模範解答
日次
解説
解答の論理構成
-
業務要件の確認
【問題文】の図2には、
「毎週月曜日の朝に最新のデータを確認できること。ただし、遅延返却発生件数については前日までの実績を翌営業日の朝に確認できること。」
と明記されています。
ここで対象となるのは図4のSQLで生成する「遅延返却発生件数」です。 -
必要なデータ鮮度の整理
・“最新のデータ”は週次であればよいが、
・“遅延返却発生件数”だけは「前日までの実績」を「翌営業日の朝」に提供する、つまり1日遅れのデータで十分だが、少なくとも毎営業日には更新されていなければなりません。 -
バッチ処理の位置付け
図4のSQLは「遅延返却発生件数データを作成するSQL文」であり、バッチ処理プログラムがこれを実行して貸出表へ挿入すると【問題文】に説明があります。
よって、このバッチは「前日=貸出予定日」の遅延返却分を取り込み、翌営業日の朝までに完了している必要があります。 -
更新頻度の決定
前日分を翌朝までに集計するには、毎営業日に1回の実行が不可欠です。業務システムでは営業日ごとのバッチを「日次」と呼ぶため、SQL実行頻度の最適解は「日次」となります。
誤りやすいポイント
- 「毎週月曜日の朝」という文言だけに着目し、週次更新と早合点する。遅延返却発生件数だけは別途“前日まで”が要求されていることを見落としがちです。
- 「翌営業日の朝」を“翌週の月曜”と取り違える。営業日は通常平日を指し、週末や祝日を跨いでも最初の営業日に処理が必要です。
- 図4のSQLが生成するのは遅延返却データだけであり、他のKPIと混同して一律の週次処理と考えるミス。
FAQ
Q: 休日が連続する場合でも毎日実行するのですか?
A: 「翌営業日の朝に確認できること」とあるため、連休中は処理をスキップし、最初の営業日前夜にまとめて実行するなど運用で調整します。ただしバッチ自体の実行単位は日次です。
A: 「翌営業日の朝に確認できること」とあるため、連休中は処理をスキップし、最初の営業日前夜にまとめて実行するなど運用で調整します。ただしバッチ自体の実行単位は日次です。
Q: “日次”と“毎日”は同義ですか?
A: 実務ではほぼ同義ですが、本設問は“頻度を2字以内”で答える指定があるため「日次」と表記します。
A: 実務ではほぼ同義ですが、本設問は“頻度を2字以内”で答える指定があるため「日次」と表記します。
Q: 週次バッチで前日分を集計する後処理を付ければ要件を満たせませんか?
A: 週次バッチに追加処理を付けるとデータが6日分遅延します。要件は「前日までの実績」を翌営業日に確認することなので、週次では間に合いません。
A: 週次バッチに追加処理を付けるとデータが6日分遅延します。要件は「前日までの実績」を翌営業日に確認することなので、週次では間に合いません。
関連キーワード: ETL, バッチ処理, 時系列集計, KPI, 遅延ペナルティ
設問4:
本文中の下線②について、追加した集計表の主キーを答えよ。
模範解答
年月, 駐車場ID, 車種ID, 会員ID
解説
解答の論理構成
- 処理性能問題の把握
問題文には「分析対象期間を過去複数年間、時間軸を月別として人気車種及び遅延返却発生件数を分析する場合、各々の分析に時間が掛かり過ぎる」とあります。高速化のために「②データマートとして集計表を追加した」と明記されています。 - 元ファクトの粒度を確認
図3の「貸出」表は
・「年月日」「駐車場ID」「車種ID」「会員ID」に対し
・「貸出実績件数」「貸出実績時間」「遅延返却発生件数」
を保持する日次ファクトです。これは「貸出実績件数及び遅延返却発生件数は貸出予定の日付で集計すること」という業務要件と一致しています。 - 集計表(データマート)の目的
ボトルネックは“日次×5年”の大量レコード走査です。時間軸を「月別」に限定する分析のため、日付を月単位にロールアップした集計表を用意すれば、走査行数を1/約30に削減できます。 - 集計表の最小粒度(キー)の決定
集計後も分析で必要な切り口は保つ必要があります。人気車種分析では「車種ID」、遅延返却分析では「駐車場ID」「車種ID」「会員ID」を用います。従って、月次レベルで一意になる列は
「年月」+「駐車場ID」+「車種ID」+「会員ID」
です。これらを合わせた複合主キーなら、同一組合せの重複登録を防ぎ、インデックスも主キーだけで済みます。 - 結論
以上より、追加した集計表の主キーは
「年月, 駐車場ID, 車種ID, 会員ID」
となります。
誤りやすいポイント
- 「地区」や「性別」もキーに入れると考えてしまう
→ どちらも分析の切り口ですが、地区は「駐車場ID」から、性別は「会員ID」から導出可能なので冗長です。 - 「年月日」をそのまま残す
→ 性能改善の目的は日次→月次へのロールアップです。日付粒度を残せば行数が減らず効果が出ません。 - 「車種ID」を外す
→ 人気車種分析では必須。月次集計でも車種軸が残らなければ目的を達成できません。
FAQ
Q: 「週別」「曜日別」の分析もあるが、月次集計表で良いのか?
A: 週別や曜日別は日次ファクトを直接参照します。月次で重いクエリだけをデータマート化するのがポイントです。
A: 週別や曜日別は日次ファクトを直接参照します。月次で重いクエリだけをデータマート化するのがポイントです。
Q: 集計表にサロゲートキー(連番)を付けた方が高速では?
A: 本設問は“主キー”を問うています。実務でサロゲートキーを採用しても、論理的な一意性は「年月, 駐車場ID, 車種ID, 会員ID」に置くのが正解です。
A: 本設問は“主キー”を問うています。実務でサロゲートキーを採用しても、論理的な一意性は「年月, 駐車場ID, 車種ID, 会員ID」に置くのが正解です。
Q: 年月はDATE型の月初で保持しますか、それともVARCHARで“202104”のように?
A: 実装自由ですが、集計・比較や範囲検索を考えるとDATE型(月初に丸める)またはNUMERIC型“YYYYMM”が一般的です。問題の主旨は列内容より粒度の同定です。
A: 実装自由ですが、集計・比較や範囲検索を考えるとDATE型(月初に丸める)またはNUMERIC型“YYYYMM”が一般的です。問題の主旨は列内容より粒度の同定です。
関連キーワード: データマート, 月次集計, ファクトテーブル, ロールアップ, 複合主キー
