応用情報技術者 2024年 秋期 午後 問04
データ処理機能の配置に関する次の記述を読んで、設問に答えよ。
C社は、動画配信サービスを提供する会社であり、サービス内容が充実していることが人気を呼び、動画配信者数や動画視聴者数が増えている。動画配信者は、Webブラウザを用いて、ビデオカメラやスマートフォンで撮影した動画ファイルをC社のWebサイトにアップロードすると、Webサイト上で動画の編集・配信、広報、アクセス分析などの機能が利用できる。
C社の動画配信サービスは、C社配信システム部が企画から運用までを担当している。配信システム部では、サービス内容の向上を目的に、動画編集機能を強化した動画配信者向けの新しいサービスを提供するシステム(以下、新システムという)を構築することにした。新システムの構築は、配信システム部のD君が担当することになった。
〔新システムに必要な機能〕
D君は、現在の動画配信サービスの機能を基に、新システムに必要な動画配信者向け機能の機能要件を定義した。新システムに必要な機能一覧(抜粋)を表1に示す。
 〔新システムのサーバ構成〕
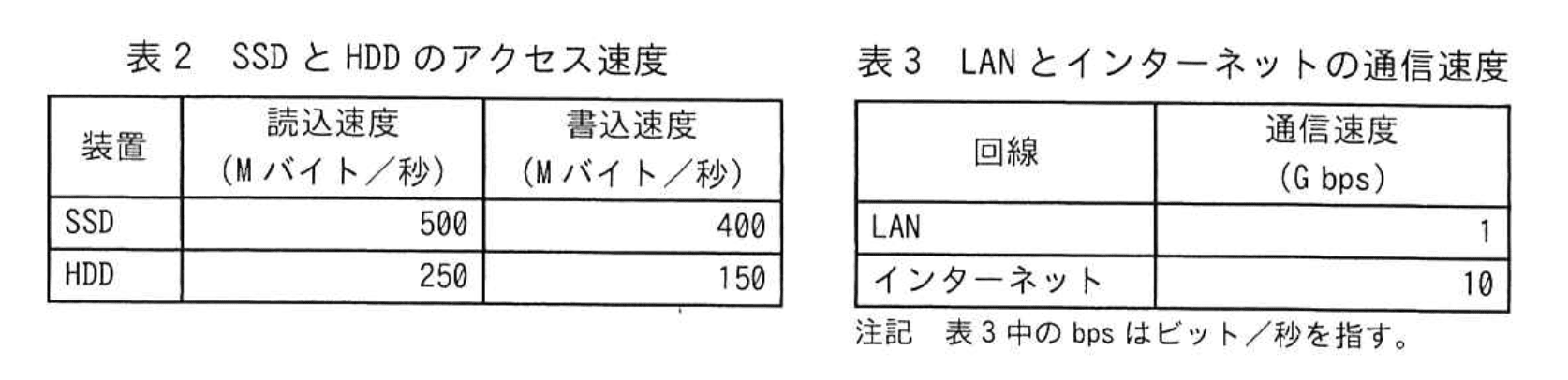
D君は、新システムのサーバ構成を設計した。D君が設計した新システムのサーバ構成(抜粋)を図1に示す。また、SSDとHDDのアクセス速度を表2に、LANとインターネットの通信速度を表3に、各サーバのCPUとGPUの搭載数を表4に示す。なお、新システム内の負荷分散装置、サーバ、NASはLANで接続されている。
〔新システムのサーバ構成〕
D君は、新システムのサーバ構成を設計した。D君が設計した新システムのサーバ構成(抜粋)を図1に示す。また、SSDとHDDのアクセス速度を表2に、LANとインターネットの通信速度を表3に、各サーバのCPUとGPUの搭載数を表4に示す。なお、新システム内の負荷分散装置、サーバ、NASはLANで接続されている。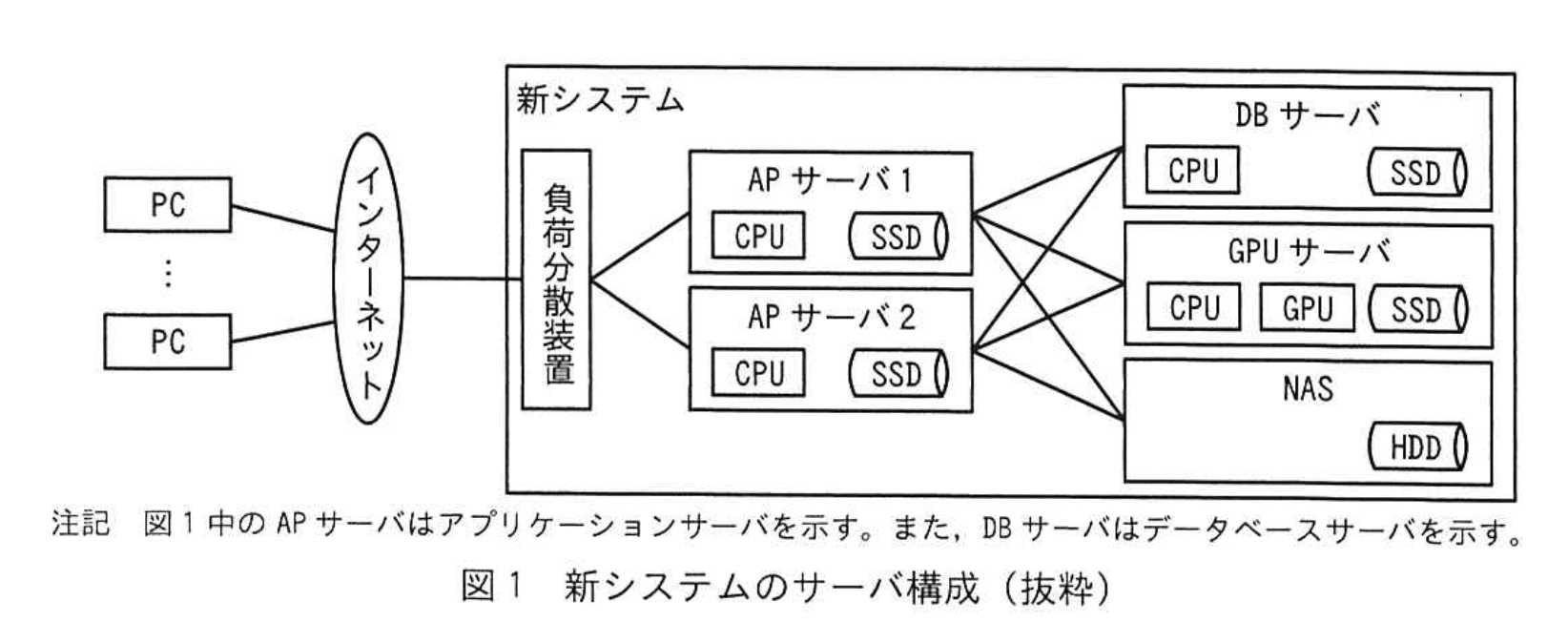
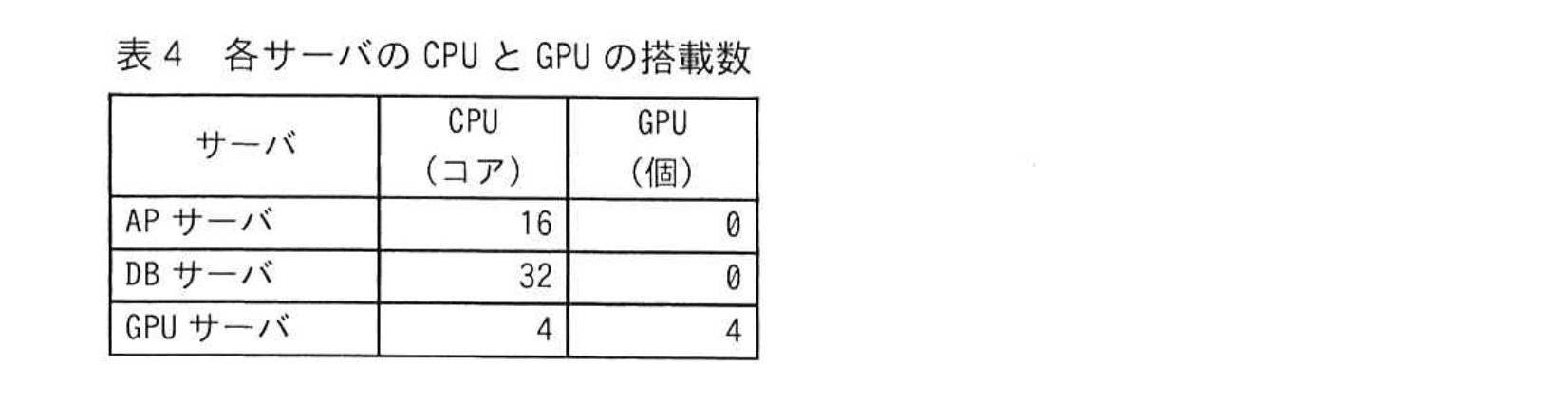
各サーバで計算を行うCPUやGPUで実行される演算は、①整数演算と浮動小数点演算の二つに分類される。新システムで利用するCPUは、1コア当たり整数演算が10,000G Operations/秒(以下、OPSという)、浮動小数点演算が500G Floating-point Operations/秒(以下、FLOPSという)で実行できる。また、GPUは1個当たり浮動小数点演算が10,000G FLOPSで実行できる。
この新システムを用いて、APサーバ1がAPサーバ1のSSDに格納された800Mバイトの動画ファイルをメモリに読み込む時間はa秒である。また、DBサーバのDBMSはRDBである。
〔配置の検討〕
D君は、新システムの各機能の中でデータ量や計算量が多い処理を抽出した。デー夕量や計算量が多い処理の一覧を表5に示す。なお、データ量には、各処理を実行するためにCPUやGPUにインプットされるデータ量と、CPUやGPUで計算した後にアウトプットされるデータ量とがある。

レンダリング処理は、APサーバのCPUを4コア用いて処理する場合にはb秒掛かり、GPUサーバのGPUだけを1個用いて処理する場合には[ c 秒掛かる。ただし、GPUサーバを用いて処理する場合には、APサーバからGPUサーバへデータを送信するのにd秒掛かり、APサーバへレンダリング結果を返送するのにe秒掛かる。この検討結果から、APサーバよりもGPUサーバで処理した方がよい。
オンラインユーザ数取得処理について、D君は②DBサーバで処理した結果をAPサーバへ送信する方法が最適と考え、DBサーバで処理することにした。
素材送信処理は、同時に100名の動画配信者向けに素材データを送信しようとすると、LANの通信速度とHDDの読込速度が遅く送信に時間が掛かる。しかし、図1のサーバ構成の変更には大きな費用が掛かることから、サーバ構成を変更せずに対応する方法を検討した。動画配信者のPCへ送信する素材データは特定の素材データに偏っており、各素材データの更新頻度も高くないことから、表5の③素材送信処理の処理方法を変更して対応することにした。
〔動画配信者数増大への対応方針〕
D君は、将来的に動画配信者数が増大することを考慮して、新システムの拡張性について検討した。まず、表5のレンダリング処理は、動画データごとに処理が独立しており、GPUサーバを手動で追加するfの対応を行う方針にした。一方で、オンラインユーザ数取得処理は、時間とともに断続的に追記される動画の視聴ログをリアルタイムに集計する処理であり、DBサーバの数を増やせないことから、DBサーバgをして対応を行う方針にした。また、多次元分析処理は、④そこで扱うデータの特徴から、多次元分析処理専用のDBサーバを追加する方針にした。これによって多次売分析処理の負荷が他の処理へ影響しないようになる。
その後、D君は新システムの構築を完了させ、C社は新システムによる新しい動画配信者向けサービスの提供を開始した
設問1:〔新システムのサーバ構成〕について答えよ。
(1)本文中の下線①について、整数演算に該当する演算を解答群の中から全て選び、記号で答えよ。
解答群
ア:300 + 200 ― 100
イ:300 × 200 ÷ 100
ウ:3.00 + 2.00 - 0.10
エ:-300 + (-200) - (-100)
オ:300 × 0
力:3.00 × 0
模範解答
ア、イ、エ、オ
解説
解答の論理構成
- 【問題文】では
「各サーバで計算を行うCPUやGPUで実行される演算は、①整数演算と浮動小数点演算の二つに分類される。」
とあり、対象となる演算を “整数演算” か “浮動小数点演算” のいずれかに分ける必要があります。 - 整数演算とは、オペランド(演算対象)がすべて整数型で表現される演算です。
浮動小数点演算は、小数点を含む数値を扱う演算が該当します。 - 解答群を判定します。
• ア: … 全て整数 → 整数演算
• イ: … 全て整数。除算でも結果が整数型で処理される想定 → 整数演算
• ウ: … 小数点を含む → 浮動小数点演算
• エ: … 負の符号を持つが整数 → 整数演算
• オ: … 0も整数 → 整数演算
• カ: … 3.00 が小数 → 浮動小数点演算 - よって、整数演算に該当する記号は
「ア、イ、エ、オ」 となります。
誤りやすいポイント
- 「0」は整数であり、0 を含む演算(オ)は整数演算になる点を見落としやすいです。
- マイナス記号(エ)の有無は型を変えません。負の整数でも浮動小数点とは別扱いです。
- 「÷」を見て浮動小数点と誤解するケースがありますが、オペランドが整数型なら整数演算です。
- 「3.00」のように末尾が 0 でも小数点を含む表記は浮動小数点演算です。
FAQ
Q: 整数演算と浮動小数点演算は CPU・GPU で性能が大きく異なるのですか?
A: 【問題文】にあるとおり CPU は「整数演算が10,000G Operations/秒」「浮動小数点演算が500G FLOPS」と性能差が大きく、GPU は浮動小数点演算が得意です。処理負荷を見積もる際に重要な指標になります。
A: 【問題文】にあるとおり CPU は「整数演算が10,000G Operations/秒」「浮動小数点演算が500G FLOPS」と性能差が大きく、GPU は浮動小数点演算が得意です。処理負荷を見積もる際に重要な指標になります。
Q: 「÷」を含む式は常に浮動小数点演算と考えた方が安全でしょうか?
A: オペランドが全て整数なら整数型除算として扱われます。型(データの表現形式)で判断してください。
A: オペランドが全て整数なら整数型除算として扱われます。型(データの表現形式)で判断してください。
Q: 小数点以下が 0 の値(例:3.0)は整数演算に含まれますか?
A: 含まれません。表記に小数点がある時点で浮動小数点型と見なされます。
A: 含まれません。表記に小数点がある時点で浮動小数点型と見なされます。
関連キーワード: 整数演算、浮動小数点、データ型、演算性能、CPU
設問1:〔新システムのサーバ構成〕について答えよ。
(2)本文中のaに入れる適切な数値を答えよ。ここで、本文に記載の読込速度、書込速度を実効速度とし、他のオーバヘッドは無視できるものとする。なお、計算結果に小数が発生する場合、答えは小数第2位を四捨五入して小数第1位まで求めよ。
模範解答
a:1.6
解説
解答の論理構成
-
必要な数値の抽出
- データ量は本文の「APサーバ1がAPサーバ1のSSDに格納された800Mバイトの動画ファイル」と明示されているので、サイズは 「800Mバイト」 です。
- 読込速度について、表2には
「SSD 読込速度(Mバイト/秒) 500」
とあります。 - 本文には「他のオーバヘッドは無視できる」とあり、単純に転送時間=データ量÷速度で求めてよいことが分かります。
-
計算=\frac{800}{500}=1.6\;\text{秒} $$
データ転送時間 は -
桁処理
問題文の指示は「小数第2位を四捨五入して小数第1位まで求めよ」ですが、1.6 秒はすでに小数第2位が存在しないためそのまま採用します。 -
結論
a に入る値は 1.6 となります。
誤りやすいポイント
- Mバイトと Mbps(bit 単位)を混同し、LAN やインターネット回線の「1」「10」を使ってしまう。今回はあくまでも SSD の 500Mバイト/秒 を用いる問題です。
- 「800Mバイト」を 800Mビットと読み違えて 8 倍してしまう。単位確認が必須です。
- 四捨五入の指示を読み落とし、「1.60」や「1.599…」などと書いて減点される。
FAQ
Q: LAN やインターネットの速度は考慮しなくてよいのですか?
A: 今回のシナリオは「APサーバ1 の SSD ⇒ 同サーバのメモリ」という内部転送であり、ネットワーク帯域は関係ありません。
A: 今回のシナリオは「APサーバ1 の SSD ⇒ 同サーバのメモリ」という内部転送であり、ネットワーク帯域は関係ありません。
Q: SSD の書込速度「400」は使わなくて良いのでしょうか?
A: 問題が求めているのは読込時間です。したがって 「読込速度 500」 のみを使用します。
A: 問題が求めているのは読込時間です。したがって 「読込速度 500」 のみを使用します。
Q: 1.6 秒を「2 秒」と丸めても良いですか?
A: 指定は「小数第1位まで」です。従って 「1.6」 と書く必要があります。
A: 指定は「小数第1位まで」です。従って 「1.6」 と書く必要があります。
関連キーワード: SSD, データ転送時間、読込速度、単位換算
設問2:〔配置の検討〕について答えよ。
(1)本文中のb〜dに入れる適切な数値を、整数で答えよ。
模範解答
b:50
c:10
d:4
解説
解答の論理構成
-
演算量と CPU・GPU 性能の把握
【問題文】には
・CPU は「1コア当たり浮動小数点演算が 500G FLOPS」
・GPU は「1個当たり浮動小数点演算が 10,000G FLOPS」
と記載されています。
また、レンダリング処理の浮動小数点演算量は表5で「100,000GFLO」と示されています。 -
AP サーバ(CPU 4コア)で実行したときの所要時間
実効性能=500GFLOPS × 4コア=2,000GFLOPS
処理時間= 秒
よって b=50。 -
GPU サーバ(GPU 1個)で実行したときの所要時間
実効性能=10,000GFLOPS
処理時間= 秒
よって c=10。 -
AP サーバ→GPU サーバへのデータ転送時間
転送量は表5のインプット「500Mバイト」。
回線速度は表3で LAN が「1Gbps」。
500Mバイト=4,000Mビット
1Gbps=1,000Mビット/秒
転送時間= 秒
よって d=4。
誤りやすいポイント
- “G” を 1,024 で換算してしまう
本試験では 1,000 倍として扱う前提が多く、ここでも 1Gbps=1,000Mビット/秒で計算するのが正解になります。 - 100,000GFLO を 10^3 倍の誤読
表5の「100,000」を「100,000G」→「100,000×10^9」と二重に解釈すると桁を誤ります。 - 入力 500Mバイトと出力 100Mバイトを合算して転送量を 600Mバイトと考える
問われているのは「APサーバからGPUサーバへ送信する」入力データのみです。
FAQ
Q: GPU でレンダリングする場合、出力 100Mバイトを返送する時間 e は計算しなくてよいのですか?
A: 今回の小問は b〜d のみを求めるので、返送時間 e の算出は不要です。
A: 今回の小問は b〜d のみを求めるので、返送時間 e の算出は不要です。
Q: CPU 性能に整数演算 10,000G OPS があるのに使わないのはなぜ?
A: レンダリング処理は表5で整数演算 0GO、浮動小数点演算 100,000GFLO と示されており、整数演算は事実上関与しません。
A: レンダリング処理は表5で整数演算 0GO、浮動小数点演算 100,000GFLO と示されており、整数演算は事実上関与しません。
Q: 1Gbps を 1,000Mビット/秒にした根拠は?
A: 【問題文】の「通信速度 (Gbps)」は SI 接頭辞に従うのが一般的であり、試験問題でも 10Gbps=10,000Mビット/秒という扱いをしています。
A: 【問題文】の「通信速度 (Gbps)」は SI 接頭辞に従うのが一般的であり、試験問題でも 10Gbps=10,000Mビット/秒という扱いをしています。
関連キーワード: FLOPS, 帯域幅、並列処理、データ転送、GPU
設問2:〔配置の検討〕について答えよ。
(2)本文中のeに入れる適切な数値を答えよ。なお、計算結果に小数が発生する場合、答えは小数第2位を四捨五入して小数第1位まで求めよ。
模範解答
e:0.8
解説
解答の論理構成
-
転送対象データの特定
レンダリング処理のアウトプットは表5の
「アウトプット (Mバイト)」が“100”である。したがって APサーバに戻すデータ量は“100Mバイト”である。 -
伝送路の確認
本文には「新システム内の負荷分散装置、サーバ、NASはLANで接続されている」とあり、GPUサーバとAPサーバ間もLAN接続である。
表3には「LAN 1 Gbps」とあるので、使用帯域は1Gbpsとなる。 -
単位換算
100Mバイト = 100 × 8 = 800Mビット -
時間算出※1Gbps=1,000Mbps として計算。
-
四捨五入処理
小数第2位は発生しないためそのまま0.8秒。
以上より、e に入る値は 0.8 である。
誤りやすいポイント
- インターネット側の“10 Gbps”を誤って用いる。GPUサーバとAPサーバは社内LAN接続であり対象外。
- “Mバイト”と“Mビット”を混同し 8 倍換算を忘れる。
- 1Gbpsを1,024Mbpsとみなすなど、問題文以外の値を当てはめる。
FAQ
Q: バイト→ビット換算は必ず必要ですか?
A: はい。通信速度はビット/秒で与えられているため、バイトで示されたデータ量を 8 倍してビットに直す必要があります。
A: はい。通信速度はビット/秒で与えられているため、バイトで示されたデータ量を 8 倍してビットに直す必要があります。
Q: LANが1Gbpsと10Gbpsで記載が逆では?
A: 問題文の表3に「LAN 1 Gbps」「インターネット 10 Gbps」と明示されているため、設問ではその値をそのまま使用します。
A: 問題文の表3に「LAN 1 Gbps」「インターネット 10 Gbps」と明示されているため、設問ではその値をそのまま使用します。
Q: 1024倍の換算を使うと答えは変わりますか?
A: 本問題は10進法で記載されているため、1Mbps=1,000,000bps として計算します。2進法換算を用いる指示はありません。
A: 本問題は10進法で記載されているため、1Mbps=1,000,000bps として計算します。2進法換算を用いる指示はありません。
関連キーワード: LAN, 帯域幅、データ転送時間、バイト換算、浮動小数点演算
設問2:〔配置の検討〕について答えよ。
(3)本文中の下線②について、DBサーバで処理した結果をAPサーバへ送信する方法が最適と考えたのはなぜか。データ量の観点から35字以内で答えよ。
模範解答
アウトプットデータと比較してインプットデータの量が多いから
解説
解答の論理構成
-
入出力データ量の把握
表5の「オンラインユーザ数取得」行には、 ・「インプット (Mバイト) 100」
・「アウトプット (Mバイト) 0.1」
とあります。インプットはアウトプットの1,000倍です。 -
データ転送量を最小化する方針
下線②では「DBサーバで処理した結果をAPサーバへ送信する方法が最適」と述べています。DBサーバ内で集計を完了させれば、APサーバへ送るのは「0.1Mバイト」だけで済みます。逆にAPサーバで処理する場合、100MバイトをLAN経由で転送しなければなりません。 -
結論
よって「アウトプットデータと比較してインプットデータの量が多い」ため、DBサーバ側で処理して小さな結果だけを送る方が効率的であり、ネットワーク負荷を大幅に削減できます。
誤りやすいポイント
- 「0.1Mバイト」を 0.1Gバイトと誤読し、差を小さく見積もる。
- 計算量(GO)の差ばかりに注目し、データ転送量の影響を軽視する。
- DBサーバとAPサーバ間の通信速度(1Gbps)を見落とし、転送時間を過小評価する。
FAQ
Q: DBサーバで処理するとCPU負荷が心配ですが問題ありませんか?
A: 「整数演算数 (GO) 50」と小さく、DBサーバの「CPU(コア) 32」で十分処理可能です。
A: 「整数演算数 (GO) 50」と小さく、DBサーバの「CPU(コア) 32」で十分処理可能です。
Q: LANとインターネットの速度は関係ありますか?
A: 本設問ではDBサーバとAPサーバ間のLAN(1Gbps)のみが関係します。インターネット速度(10Gbps)は影響しません。
A: 本設問ではDBサーバとAPサーバ間のLAN(1Gbps)のみが関係します。インターネット速度(10Gbps)は影響しません。
Q: アウトプットが0.1Mバイトでも高頻度で送れば負荷は増えませんか?
A: 送信頻度が上がっても1回あたりのデータ量が小さいため、総通信量はインプット100Mバイトを直接送る場合より依然として少なく抑えられます。
A: 送信頻度が上がっても1回あたりのデータ量が小さいため、総通信量はインプット100Mバイトを直接送る場合より依然として少なく抑えられます。
関連キーワード: データ転送最適化、ネットワーク帯域、入出力バランス、サーバ配置、集計処理
設問2:〔配置の検討〕について答えよ。
(4)本文中の下線③について、素材送信処理の処理方法をどのように変更したか。変更点を30字以内で答えよ。
模範解答
素材データをAPサーバのSSDにキャッシュする。
解説
解答の論理構成
-
ボトルネックの特定
【問題文】で「LANの通信速度とHDDの読込速度が遅く送信に時間が掛かる」と指摘されています。
─ 素材送信処理は NAS(HDD)→APサーバ→インターネットの順に流れ、①HDD 読込 ②LAN 1 Gbps の二重制約を受けます。 -
サーバ構成は固定条件
同じ段落で「サーバ構成の変更には大きな費用が掛かる」と明言され、NAS 交換や LAN 増速といったハード強化策は採れません。 -
データの性質
さらに「素材データは特定の素材データに偏っており、各素材データの更新頻度も高くない」とあります。
─ 頻繁にアクセスされるがほとんど更新されない=キャッシュに最適なパターンです。 -
代替案の導出
NAS を経由せず、事前に AP サーバの高速ストレージ(SSD)へ素材をコピーし、そこから配信すれば
・HDD→SSD で読込速度が「150 Mバイト/秒」→「500 Mバイト/秒」に向上
・LAN トラフィックは素材初回転送時だけになり、同時 100 名送信時の帯域圧迫を回避
となります。 -
結論
以上より、下線③「素材送信処理の処理方法を変更して対応」の具体策は
「素材データをAPサーバのSSDにキャッシュする」
となります。
誤りやすいポイント
- NAS の HDD を SSD に換装すると読み替える
→ 費用制約で「サーバ構成の変更」不可。 - LAN を 10 Gbps 化すると考える
→ 同じくハード変更に該当し不可。 - 「キャッシュ」を DB サーバ側に置くと誤解する
→ 素材送信は AP サーバ経由で配信者 PC に送る処理であり、DB は関与しません。
FAQ
Q: キャッシュ用領域が足りなくなった場合はどうしますか?
A: 人気素材のみを LRU などで保持し、低頻度素材は従来どおり NAS から転送するハイブリッド方式にします。
A: 人気素材のみを LRU などで保持し、低頻度素材は従来どおり NAS から転送するハイブリッド方式にします。
Q: なぜ CDN を使わないのですか?
A: 本設問では「サーバ構成を変更せずに対応」が条件で、外部サービス追加は想定外だからです。
A: 本設問では「サーバ構成を変更せずに対応」が条件で、外部サービス追加は想定外だからです。
Q: 素材更新時の整合性は?
A: 更新頻度が低い前提ですが、変更が発生した際に NAS 更新トリガーで AP サーバ側キャッシュをリフレッシュする運用を行います。
A: 更新頻度が低い前提ですが、変更が発生した際に NAS 更新トリガーで AP サーバ側キャッシュをリフレッシュする運用を行います。
関連キーワード: キャッシュ、SSD, ネットワーク帯域、ボトルネック、データ分散
設問3:〔動画配信者数増大への対応方針〕について答えよ。
(1)本文中のf、gに入れる適切な字句を解答群の中から選び、記号で答えよ。
解答群
ア:スケールアウト
イ:スケールアップ
ウ:スケールイン
エ:スケールダウン
模範解答
f:ア
g:イ
解説
解答の論理構成
-
“GPUサーバを手動で追加するfの対応”
- ここでは「サーバを追加」することで全体の処理能力を高めようとしています。
- 複数台を並列配置して性能を上げる方法は水平スケーリング、すなわち “スケールアウト” です。
- 解答群で該当する語は “ア:スケールアウト”。
-
“DBサーバの数を増やせないことから、DBサーバgをして対応”
- 台数を増やせない=水平方向は不可。既存サーバのCPU・メモリ・ストレージを強化して縦に拡張します。
- これは垂直スケーリング、すなわち “スケールアップ” に該当します。
- 解答群で該当する語は “イ:スケールアップ”。
-
以上より
- f には “ア:スケールアウト”
- g には “イ:スケールアップ”
が妥当となります。
誤りやすいポイント
- “サーバを追加する” と “サーバの性能を上げる” を混同しやすい
水平か垂直かを落ち着いて判定しましょう。 - “数を増やせない” という表現を読み飛ばし、g にもスケールアウトを選択してしまうケース。
- “スケールイン/スケールダウン” は性能を下げる方向なので、本設問とは無関係です。
FAQ
Q: スケールアウトとロードバランシングは同義ですか?
A: 目的は同じ「並列分散による性能向上」ですが、ロードバランサはその実装手段の一部です。スケールアウトは台数を増やす設計方針、ロードバランシングはトラフィックを各台へ振り分ける技術です。
A: 目的は同じ「並列分散による性能向上」ですが、ロードバランサはその実装手段の一部です。スケールアウトは台数を増やす設計方針、ロードバランシングはトラフィックを各台へ振り分ける技術です。
Q: スケールアップの限界はどこで判断しますか?
A: CPUソケット数・メモリスロット数・電源容量などハードウェア上限、ライセンスコスト、ダウンタイム許容度を総合的に評価します。上限が近い場合は早期にスケールアウト戦略へ切替えるのが一般的です。
A: CPUソケット数・メモリスロット数・電源容量などハードウェア上限、ライセンスコスト、ダウンタイム許容度を総合的に評価します。上限が近い場合は早期にスケールアウト戦略へ切替えるのが一般的です。
Q: スケールダウンを採用する場面はありますか?
A: 一時的に負荷が減少し、コスト削減を優先したいときにクラウド環境でリソースを縮小するケースがあります。本問はオンプレ構成かつ負荷増を想定しているため対象外です。
A: 一時的に負荷が減少し、コスト削減を優先したいときにクラウド環境でリソースを縮小するケースがあります。本問はオンプレ構成かつ負荷増を想定しているため対象外です。
関連キーワード: スケールアウト、スケールアップ、水平スケーリング、垂直スケーリング、パフォーマンス拡張
設問3:〔動画配信者数増大への対応方針〕について答えよ。
(2)本文中の下線④について、オンラインユーザ数取得処理と対比して、多次元分析処理で扱うデータの特徴を20字以内で答えよ。
模範解答
追加・更新のない過去のデータ
解説
解答の論理構成
-
オンラインユーザ数取得処理の特徴を把握
【問題文】には「オンラインユーザ数取得処理は、時間とともに断続的に追記される動画の視聴ログをリアルタイムに集計する処理」とあります。
➜ データが“絶えず追記・更新される”ことが強調されています。 -
対比対象である多次元分析処理の前提を確認
同じ段落で「多次元分析処理は、そこ で扱うデータの特徴から、多次元分析処理専用のDBサーバを追加する方針」と記述されています。さらに表5では「多次元分析」のインプットは「50,000 Mバイト」で、処理内容は「前日までの動画の視聴ログを複数の分析軸から分析する」と明言されています。 -
「前日まで」の意味を読み解く
「前日まで」とは当日更新が終わった後の確定データを示すため、分析時点では追記も更新も行われません。オンラインユーザ数取得処理で強調された“リアルタイム更新”とは対照的に、“過去データを読み込むだけ”になります。 -
したがって多次元分析処理で扱うデータの本質は、 追加・更新を前提としない「静的な過去データ」。これを20字以内にまとめると追加・更新のない過去のデータ
誤りやすいポイント
- 「50,000 Mバイト」という大容量に気を取られ、データが頻繁に変わると勘違いする。実際には量ではなく更新頻度が鍵です。
- 多次元分析=BIツールのイメージから「随時更新されるダッシュボード」と連想するケース。問題文は「前日まで」と限定しています。
- “専用DBサーバを追加”をスケールアウトと解釈し「高頻度更新に対応」と誤読する。目的は更新ではなく他処理への影響分離です。
FAQ
Q: なぜ「前日まで」と書かれているだけで更新がないと言い切れるのですか?
A: 視聴ログは日次で締めた後に分析対象になります。リアルタイムに追記されるのはオンラインユーザ数取得処理のログであり、多次元分析処理は確定済みログを扱うため更新が発生しません。
A: 視聴ログは日次で締めた後に分析対象になります。リアルタイムに追記されるのはオンラインユーザ数取得処理のログであり、多次元分析処理は確定済みログを扱うため更新が発生しません。
Q: 大容量でも更新がなければ専用DBに切り出すメリットは?
A: 読み出し専用クエリが集中しても、他システムのトランザクション性能に影響を与えない構成にできるためです。
A: 読み出し専用クエリが集中しても、他システムのトランザクション性能に影響を与えない構成にできるためです。
Q: 「過去データ」を強調する理由は?
A: 更新がない=ロック競合やトランザクション管理が不要で、列指向DBやパーティショニングなど分析向け最適化を行いやすいからです。
A: 更新がない=ロック競合やトランザクション管理が不要で、列指向DBやパーティショニングなど分析向け最適化を行いやすいからです。
関連キーワード: データウェアハウス、ETL, バッチ処理、列指向ストレージ
