応用情報技術者 2024年 秋期 午後 問06
トレーディングカードの個人間売買サイトの構築に関する次の記述を読んで、設問に答えよ。
S社は、トレーディングカード販売業のチェーンを営む中堅企業である。トレーディングカードを個人から買い取り、販売する事業を営んでいる。トレーディングカードの個人間の売買が盛んな市場環境を受け、個人間の売買を安心かつ手軽に行える取引プラットフォームをサービスとして提供して、安定的な手数料収入を得る新規事業を立ち上げることにした。S社の情報システム部は新規事業の要となる取引プラットフォームのシステム(以下、本システムという)を新規で構築することになり、Tさんがデータベースの設計及び開発を担当することになった。
〔新規事業の業務要件の確認〕
Tさんは、まず、新規事業において実現する業務要件を確認した。新規事業の業務要件(抜粋)を表1に示す。


〔概念データモデルの設計〕
Tさんは、表1の業務要件に基づいて、E-R図を用いて本システムの概念データモデルを設計した。本システムの概念データモデル(抜粋)を図1に示す。なお、カテゴリの階層構造は、自己参照の関連を用いて表現する。
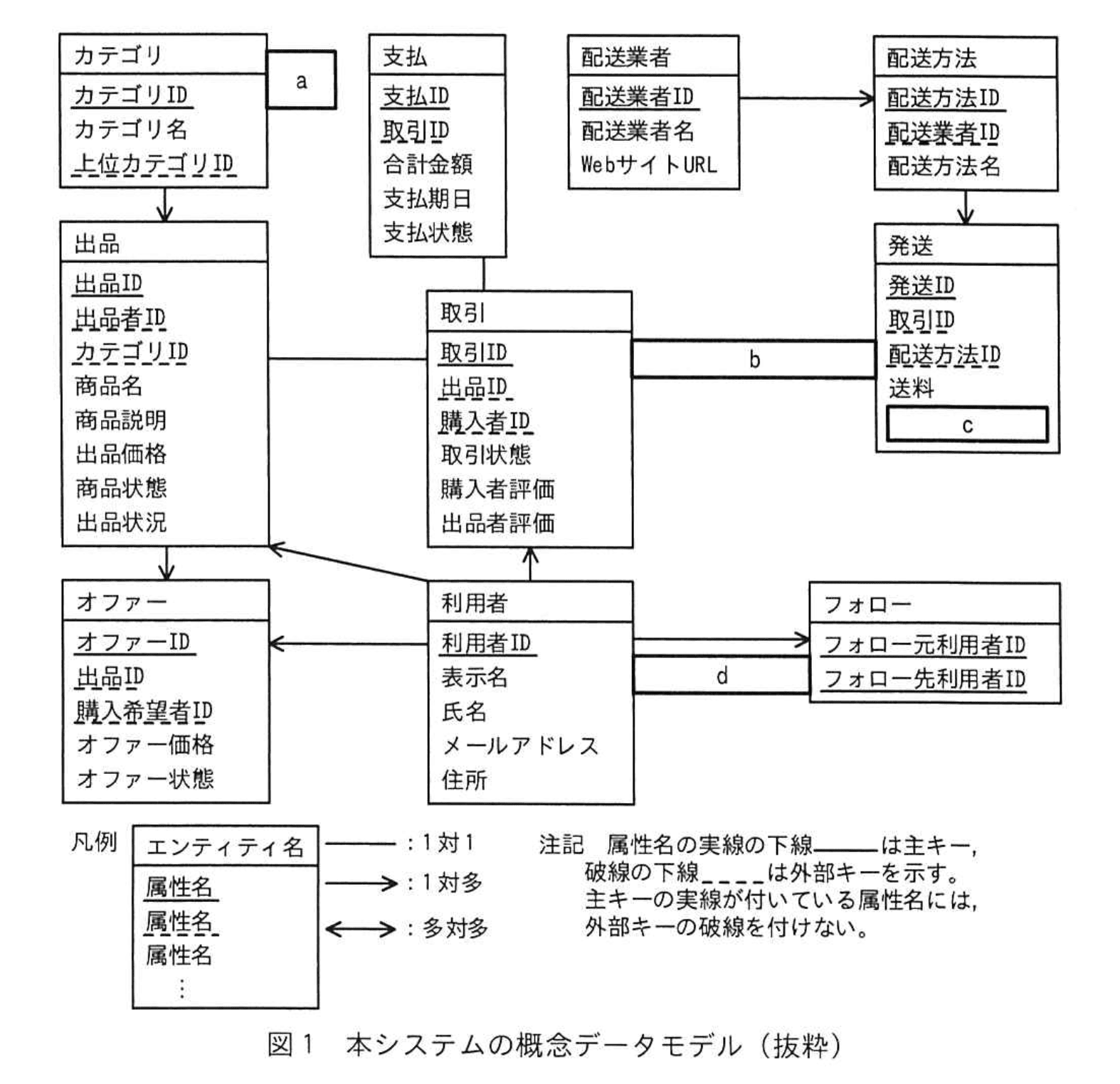
本システムのデータベースでは、E-R図のエンティティ名を表名にし、属性名を列名にして、適切なデータ型で表定義した関係データベースによって、データを管理する。
〔SQLの作成〕
Tさんは、表1の項番2の業務要件を実現するための検索のSQL文を作成した。作成したSQL文を図2に示す。なお、“:カテゴリID”、“:下限価格”、“:上限価格”、“:商品状態”、“:出品状況”、“:キーワード”は、該当の値を格納する埋込み変数である。また、最上位であるカテゴリの上位カテゴリIDにはNULLが設定されている。

〔性能の検証と改善〕
Tさんがテストデータを用いて図2のSQL文の実行性能を検証したところ、実行を開始してから検索結果が得られるまでの処理時間が長く、実用的ではないことが判明した。
本システムでは出品される商品の数が膨大であり、利用者が図2のSQL文を頻繁に実行することが予想される。そこで、Tさんはキーワードでの検索が必要な商品名及び商品説明の列には全文検索エンジンを用いるとともに、その他の列に対しては適切なインデックスを設定し、性能上の懸念を解消することを検討した。
インデックスの方式には、B-treeインデックスを採用することにした。Tさんは、各表の表定義を確認し、インデックスを設定すべき列を検討した。出品表の表定義を表2に、カテゴリ表の表定義を表3に示す。
表2及び表3のデータ型欄は、データ型、長さ、精度、位取りを示す。PK欄は主キ一制約、UK欄はUNIQUE制約、非NULL欄は非NULL制約の指定をするかどうかを示す。指定する場合にはYを、指定しない場合にはNが記入されている。ここで、主キーに対してはUNIQUE制約は指定せず、非NULL制約は指定するものとする。カーディナリティ欄は列に多数の異なる値をもつ場合には高を、少数の異なる値をもつ場合には低を記入する。そして、高と低の中間の数の異なる値をもつ場合には中を記入する。データ分布欄は列に含まれる値の確率分布の仮定を示す。
Tさんは、①B-treeインデックスの特性を踏まえて、特定の値を指定したときに行数を表全体の5%以下に絞り込める列だけにインデックスを設定することにした。
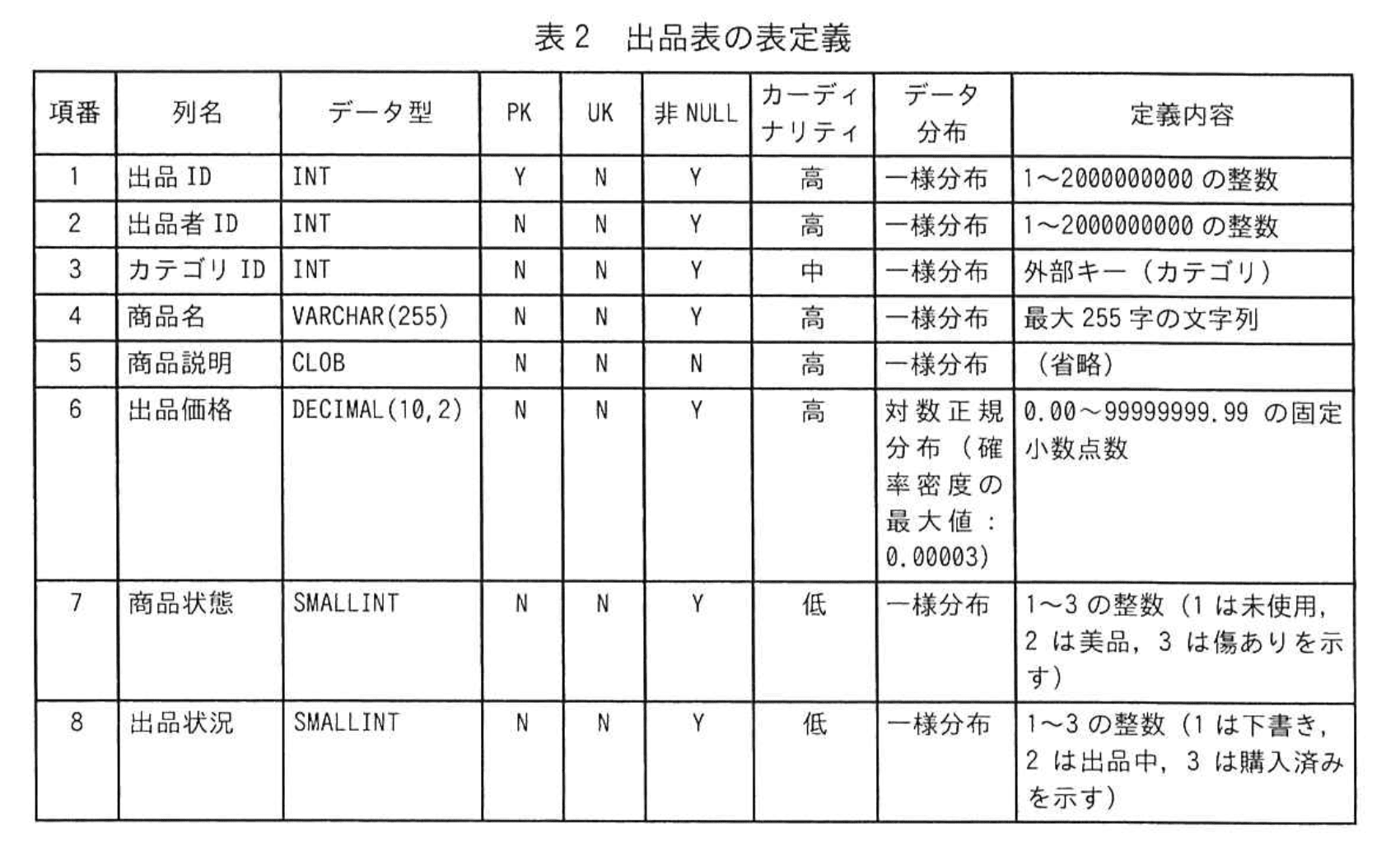
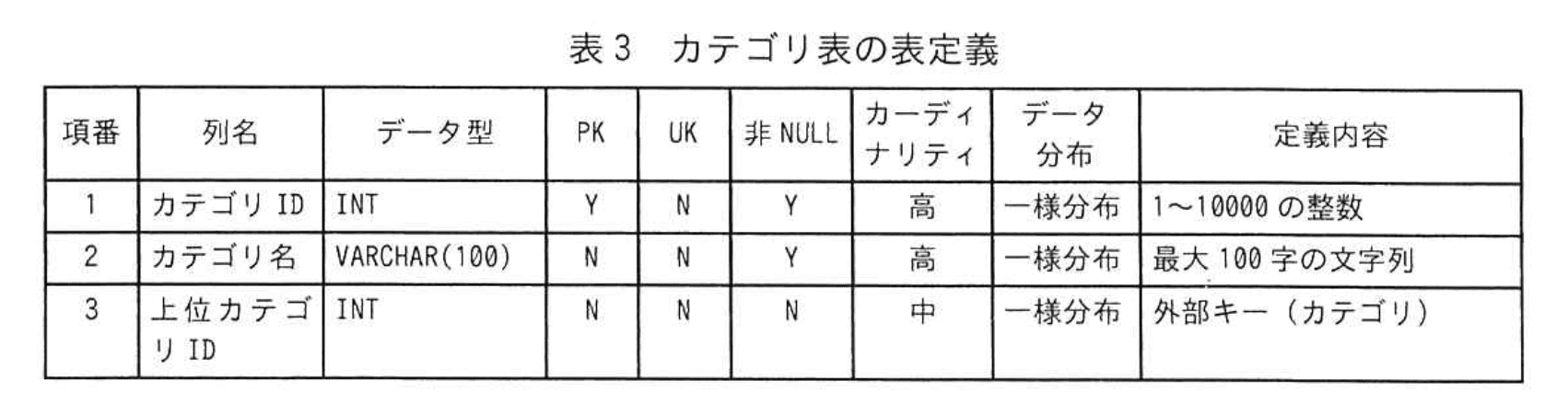
Tさんは、必要なインデックスを設定後にテストデータを用いて図2のSQL文の実行性能を検証し、実用的な性能であることを確認した。ただし、表2及び表3のデー夕分布は新規事業立上げ前の時点における仮定でしかない。今後実際に運用する際にはデータ分布が仮定とは異なる場合があるので、定期的にインデックスを見直すことを申し送り事項の一つとして、本システムのデータベースの設計及び開発を完了した。
設問1:
図1中のa〜dに入れる適切なエンティティ間の関連及び属性名を答え、概念データモデルを完成させよ。なお、エンティティ間の関連及び属性名の表記は、図1の凡例に倣うこと。
模範解答
a:↩︎
b:ー
c:追跡番号
d:→
解説
解答の論理構成
-
自己参照を示す a
【問題文】には「カテゴリの階層構造は、自己参照の関連を用いて表現する。」とあります。自己参照はエンティティ内部に折り返す矢印で示すのが一般的です。図1のカテゴリエンティティ末尾にある a はこの自己参照を表すため、曲がった矢印 「↩︎」 を補います。 -
取引と発送の関連 b
リレーションシップ一覧に「取引 — 発送(1対多)」とあり、矢印ではなく実線のみで 1 対多を表現しています。図1の取引エンティティ末尾の b はこの実線を示すため、凡例の 1 対 1 用ではなく水平線 「ー」 を記入します。 -
発送エンティティの不足属性 c
業務要件(項番5)に「S社は発送した商品の追跡番号を管理し、配送業者のWebサイトと連携することで、出品者や購入者が商品の配送状況を確認できるようにする。」と記載されています。従って発送表には追跡番号を保持する列が必要です。よって c には 「追跡番号」 を入れます。 -
利用者とフォローの関連 d
業務要件(項番8)は「利用者はお気に入りの利用者をフォローできる。」と述べています。リレーションシップ一覧には「利用者 → フォロー(1対多)」があり、1人の利用者が多数のフォロー行を持つ方向を矢印で示しています。したがって d には 1 対多の矢印 「→」 を入れます。
以上より解答は
a:↩︎
b:ー
c:追跡番号
d:→
a:↩︎
b:ー
c:追跡番号
d:→
誤りやすいポイント
- 自己参照を通常の「→」で描いてしまう
曲がった矢印で自己参照を示すと気付きにくい受験生が多いです。 - 「取引 — 発送」をどちら向きの矢印にするか迷う
問題文は方向を特定していないため実線「ー」が正解です。 - 業務要件にだけ登場する「追跡番号」を見落とす
列名は本文で明示されているので、そのまま「追跡番号」と書く必要があります。 - フォローのリレーション向きを逆にする
フォロー元が 1、フォロー行が多側であることを業務要件から確認しましょう。
FAQ
Q: 自己参照の矢印「↩︎」は必ず使わなければいけませんか?
A: 問題文の凡例に従う必要があります。自己参照を示す専用記号が用意されている場合は、それを選択してください。
A: 問題文の凡例に従う必要があります。自己参照を示す専用記号が用意されている場合は、それを選択してください。
Q: 「取引 — 発送」を矢印で描くと減点になりますか?
A: 凡例では 1 対多を「→」と定義していますが、問題文が「—」を使用しているため、そのまま実線を用いるのが正解です。
A: 凡例では 1 対多を「→」と定義していますが、問題文が「—」を使用しているため、そのまま実線を用いるのが正解です。
Q: 「追跡番号」を英語で書いても良いですか?
A: 指示に「数字・固有名詞は必ず原文を正確に引用」とあるため、日本語の「追跡番号」を用いる必要があります。
A: 指示に「数字・固有名詞は必ず原文を正確に引用」とあるため、日本語の「追跡番号」を用いる必要があります。
関連キーワード: 自己参照、1対多、外部キー、エンティティ、データモデル
設問2:
図2中のe〜hに入れる適切な字句又は式を答えよ。
模範解答
e:WITH RECURSIVE
f:UNION ALL
g:出品.カテゴリID = 指定カテゴリ.カテゴリID
h:LIKE '%' || :キーワード || '%'
解説
解答の論理構成
- 検索画面で、利用者が「カテゴリを指定する場合、指定されたカテゴリ及びその下位にある全てのカテゴリの出品が検索の対象となる」ことが業務要件の「表1 項番2」に明記されています。
したがって SQL では再帰的に「カテゴリ」の階層をたどる必要があります。ANSI SQL では再帰問い合わせを記述する定型句が WITH RECURSIVE なので、e に入る語句はこれになります。 - 再帰共通テーブル式(CTE)は
①アンカー部 ― 最初に選択された 1 行(または複数行)
②再帰部 ― 直前に取得した行と「上位カテゴリID」で結合して子階層を取得
を UNION ALL で連結するのが典型形です。よって f は UNION ALL となります。 - 取得した「指定カテゴリ」CTE と「出品」表を結合して対象レコードを絞り込む必要があります。結合キーは「出品.カテゴリID」と「指定カテゴリ.カテゴリID」の等価条件なので、g には 出品.カテゴリID = 指定カテゴリ.カテゴリID が入ります。
- キーワード検索について、「キーワードは、商品名及び商品説明を部分一致で検索したい場合に指定する」(表1 項番2)とあるので、LIKE 述語とワイルドカード % を使ったパターンマッチになります。埋込み変数 :キーワード の前後に % を連結する書式が LIKE '%' || :キーワード || '%' であり、商品名・商品説明の両方で同じ式を使うため、h も同じ式になります。
誤りやすいポイント
- 再帰CTEを WITH だけで書き始め、RECURSIVE を付け忘れる。RECURSIVE を入れないと自己参照の再帰が許されません。
- 再帰部の結合で UNION を選択してしまう。重複排除付き UNION は余計な DISTINCT 処理を伴い性能低下を招きます。本問では階層を重複なく辿る前提が立っており、UNION ALL が正解です。
- 出品とカテゴリの結合条件を「上位カテゴリID」で書いてしまうミス。出品レコードが持つのは直接の「カテゴリID」です。
- LIKE :キーワード とだけ書き、ワイルドカード % を忘れる/前後のどちらか一方しか付けない誤答が多いです。
FAQ
Q: 「指定カテゴリ」CTE にエイリアスを付けていませんが大丈夫ですか?
A: 本問のスクリプトは CTE 名そのものがテーブル名のように扱われるため、別途エイリアスは不要です。もちろん SELECT 句側で必要に応じて付けることも可能です。
A: 本問のスクリプトは CTE 名そのものがテーブル名のように扱われるため、別途エイリアスは不要です。もちろん SELECT 句側で必要に応じて付けることも可能です。
Q: LIKE ではなく全文検索エンジンを使う話が後段にありますが、SQL は LIKE でよいのですか?
A: 問1 の段階では全文検索導入前のベース SQL を問うています。業務要件の「部分一致検索」を関数や索引で高速化するかどうかは別途チューニングの話になります。
A: 問1 の段階では全文検索導入前のベース SQL を問うています。業務要件の「部分一致検索」を関数や索引で高速化するかどうかは別途チューニングの話になります。
Q: UNION ALL による自己再帰は階層が深い場合にスタックオーバーフローを起こしませんか?
A: 多くの RDBMS は再帰CTEに対して最大再帰回数やメモリ制限を持っています。実システムではカテゴリ階層の深さが把握できているため、設計時点で適切にチューニングできます。
A: 多くの RDBMS は再帰CTEに対して最大再帰回数やメモリ制限を持っています。実システムではカテゴリ階層の深さが把握できているため、設計時点で適切にチューニングできます。
関連キーワード: 再帰CTE, B-treeインデックス、部分一致検索、等価結合、ワイルドカード
設問3:〔性能の検証と改善〕について答えよ。
(1)本文中の下線①について、B-treeインデックスの特性として適切なものを解答群の中から三つ選び、記号で答えよ。
解答群
ア:インデックスを設定した各列に対する条件をAND演算子で組み合わせた検索は高速化できるが、NOT演算子を用いた条件による検索は高速化できない。
イ:インデックスを設定した列に対して演算や型変換を行った上で検索条件に指定した場合、検索を高速化できる。
ウ:インデックスを設定した列に含まれる値の分布に偏りがない場合、検索性能が安定する。
エ:カーディナリティが低い列にインデックスを設定すると、検索を高速化できる。
オ:行数nの表において、特定の行を検索するときの計算量はO(Logn)である。
カ:行数nの表において、特定の行を挿入するときの計算量はO(n)である。
キ:等号演算子を用いた条件による検索は高速化できるが、値の範囲を指定した条件による検索は高速化できない。
模範解答
a:ア、ウ、オ
解説
解答の論理構成
-
問題文は、インデックス設定方針について「①B-treeインデックスの特性を踏まえて、特定の値を指定したときに行数を表全体の5%以下に絞り込める列だけにインデックスを設定する」と述べています。
これは B-tree が
・検索対象行を“少数”に絞れる列ほど効果が高い
・探索コストが木の高さに比例し になる
という一般的な特性を示しています。 -
解答群を B-tree の事実と照合します。
ア:NOT 条件はインデックスを使いづらい。AND 条件の組合せは選択率が下がり利用されやすい。○
イ:列に関数・型変換を掛けると索引キーが一致せずフルスキャンになることが多い。×
ウ:値の分布に偏りが無い(=高い選択性が保たれる)と、どの値を検索しても行数が平均的になり性能が安定。○
エ:カーディナリティが低い列は選択率が悪く、インデックスを使っても行取得コストが下がらない。×
オ:B-tree は高さ (m は分岐数)なので検索計算量は 。○
カ:挿入も分割が起きても高さに比例し が一般的。×
キ:B-tree は範囲走査にも強い。× -
よって、正しい三つは
ア・ウ・オ。
誤りやすいポイント
- 「カーディナリティが低い列でもインデックス=高速化」と思い込み、解答群「エ」を選択しやすい。
- B-tree が範囲検索に弱いと誤解し「キ」を選ぶケース。実際は木構造が連続キーを順次たどれるため範囲走査にも適する。
- 挿入計算量を線形 と誤認し「カ」を選択するミス。ページ分割は発生しても高々木の高さ分で済む。
FAQ
Q: NOT 条件でもインデックスが絶対に使われないのですか?
A: 一部の DBMS は“NOT NULL” や “!= 定数” で索引を利用できる最適化を持ちますが、選択率が悪い・行判定に追加 I/O が必要などの理由でフルスキャンに切り替わることが多いため、一般論として「高速化しにくい」と覚えるのが無難です。
A: 一部の DBMS は“NOT NULL” や “!= 定数” で索引を利用できる最適化を持ちますが、選択率が悪い・行判定に追加 I/O が必要などの理由でフルスキャンに切り替わることが多いため、一般論として「高速化しにくい」と覚えるのが無難です。
Q: 値の分布が偏ると何が起こるのですか?
A: 例えば特定値に行が集中すると、その値検索時は選択率が下がりインデックス経由でも大量ページを読むことになります。偏りが小さい(=一様分布に近い)ほどどの値でも平均的に少ない行数を返し、キャッシュ効率も高くなります。
A: 例えば特定値に行が集中すると、その値検索時は選択率が下がりインデックス経由でも大量ページを読むことになります。偏りが小さい(=一様分布に近い)ほどどの値でも平均的に少ない行数を返し、キャッシュ効率も高くなります。
Q: 範囲検索を高速化したい場合は B-tree 以外を使うべき?
A: B-tree で十分高速なケースが多いです。範囲が広くフルスキャン近くになる場合や、時間系列で追加のみのデータならばパーティショニングや LSM ツリーなど別方式を検討します。
A: B-tree で十分高速なケースが多いです。範囲が広くフルスキャン近くになる場合や、時間系列で追加のみのデータならばパーティショニングや LSM ツリーなど別方式を検討します。
関連キーワード: B-tree, カーディナリティ、選択率、範囲検索、計算量
設問3:〔性能の検証と改善〕について答えよ。
(2)出品表及びカテゴリ表のそれぞれについて、表2及び表3を基に、B-treeインデックスを設定することで図2のSQL文の実行性能の高速化に寄与する列名を全て答えよ。なお、本システムで使用する関係データベースでは、主キーに対して自動的にインデックスが設定される。
模範解答
出品表:カテゴリID, 出品価格
カテゴリ表:上位カテゴリID
解説
解答の論理構成
-
インデックス設定の方針確認
問題文より- “①B-treeインデックスの特性を踏まえて、特定の値を指定したときに行数を表全体の5%以下に絞り込める列だけにインデックスを設定する”
つまり
(a) 検索条件や結合条件に現れる列
(b) カーディナリティが中〜高(≒選択度が高い)
が対象になる。
- “①B-treeインデックスの特性を踏まえて、特定の値を指定したときに行数を表全体の5%以下に絞り込める列だけにインデックスを設定する”
-
図2のSQL文で検索・結合に使われる列
- 出品表:
“出品.出品価格 BETWEEN :下限価格 AND :上限価格”
“出品.商品状態 = :商品状態”
“出品.出品状況 = :出品状況”
“ON … 出品.カテゴリID …” - カテゴリ表:
“WHERE B.上位カテゴリID = C.カテゴリID”
(“カテゴリID”は主キーなのでインデックス済)
- 出品表:
-
各列のカーディナリティと適否判定
【表2 出品表】- “出品価格” … カーディナリティ “高” → 5%以下に絞り込める可能性大 → ○
- “カテゴリID” … カーディナリティ “中” → 結合列で絞込効果も期待 → ○
- “商品状態”“出品状況” … カーディナリティ “低” → 5%以下になりにくい → ×
【表3 カテゴリ表】- “上位カテゴリID” … カーディナリティ “中” かつ再帰CTE内の検索キー → ○
- “カテゴリID” は主キーで既にインデックス自動付与 → 対象外(追加不要)
-
以上より高速化に寄与する列
出品表:カテゴリID, 出品価格
カテゴリ表:上位カテゴリID
誤りやすいポイント
- 「主キーは自動でインデックス化される」記述を見落とし、カテゴリIDに重複してインデックスを定義してしまう。
- “カーディナリティ 低” でも WHERE 句に出てくるからと安易にインデックスを貼る(B-tree では逆効果になり得る)。
- “全文検索エンジンを用いる”と明示された“商品名”“商品説明”に B-tree インデックスを重ねてしまう。
- BETWEEN 句に対して範囲検索だから B-tree は不要だと誤解する(実際は範囲条件でも有効)。
FAQ
Q: “中” と “高” のどちらでも 5%以下に絞れると判断して良いのですか?
A: 問題設定では“低・中・高”の区分のうち“中”以上を高選択度とみなし、Tさんは“行数を表全体の5%以下に絞り込める列だけ”という基準に合致すると判断しています。
A: 問題設定では“低・中・高”の区分のうち“中”以上を高選択度とみなし、Tさんは“行数を表全体の5%以下に絞り込める列だけ”という基準に合致すると判断しています。
Q: “出品.カテゴリID” は結合相手がサブクエリ生成の小さな表ですが、それでもインデックスは必要ですか?
A: はい。ルックアップ側(出品表)が大規模であれば、結合キーのインデックスは絞込効果が高く、NLJ/HASH JOIN いずれのプランでも有利に働く可能性があります。
A: はい。ルックアップ側(出品表)が大規模であれば、結合キーのインデックスは絞込効果が高く、NLJ/HASH JOIN いずれのプランでも有利に働く可能性があります。
Q: SMALLINT など省メモリ型の列でもインデックスを貼るべきでは?
A: カーディナリティが“低”で 5%以下に絞れないと想定されるため、I/O オーバーヘッドを増やすだけになり得ます。本問の方針では貼りません。
A: カーディナリティが“低”で 5%以下に絞れないと想定されるため、I/O オーバーヘッドを増やすだけになり得ます。本問の方針では貼りません。
関連キーワード: B-tree, カーディナリティ、選択度、インデックス設計、結合条件
