データベーススペシャリスト 2012年 午後1 問03
データウェアハウスの設計・運用に関する次の記述を読んで、設問1〜3に答えよ。
コンビニエンスストアを全国で展開しているE社は、関係データベース管理システムを用いたデータウェアハウスを構築し、売上データを基に販売分析を行っている。データウェアハウスの設計・運用は、情報システム部のFさんが担当している。
〔組織及び販売商品の概要〕
1.組織
(1) 本部を頂点に、10 支部で構成されている。
(2) 加盟店は全国で10,000店舗あり、1支部当たりの平均店舗数は1,000店である。
(3) 各支部の社員のうち、スーパバイザ (以下、SV という) として 100 人が各店舗の経営・運営を支援する。各 SV は、所属する支部内の店舗を平均 10 店担当し、複数の SV が同時に同一店舗を担当することはない。
(4) 支部では、月の途中に支部内又は支部間の人事異動があり、SV の担当店舗を変えることがある。
2.販売商品
(1) 販売する商品は、全店舗共通である。
(2) 商品は、日配食品、加工食品、非食品に区分している。 各商品区分は、次に示すように、更に商品分類として200 種類に分類し、全商品点数は 3,000 点である。
①日配食品:毎日、配送センタから配送される弁当、生菓子など,80 種類
②加工食品:カップ麺、レトルト食品、アルコール飲料など、80種類
③非食品 : 食品以外の雑誌、日用品、医薬品など、40種類
(3) 商品の商品区分は変えないが、商品分類は見直すことがある。
(4) 時期と店舗によって売れ筋商品は異なるが、全商品は毎日、各支部のいずれかの店舗で売れている。 1店舗で、1日当たり平均 2,000点、1か月当たり全商品点数 3,000 点が売れている。
〔テーブルの構造・保守及び販売分析〕
1.テーブル構造
販売分析に使用する主なテーブルの構造を図1に、主な列の意味を表1に示す。
図1のテーブルのうち、“店舗売上” テーブル以外を次元テーブルと呼ぶ。


2.本部における処理
本部の情報システムは、各店舗から売上データファイルを収集し、販売分析に必要な処理を行う。
(1) 各店舗で前日に販売した全商品の店舗売上データファイル(売上日、店舗コード、商品コード、販売数、売上額を記録)を、毎晩0時に収集する。
(2) 販売分析に必要な変換処理と、売上日、店舗番号、商品番号別に集計した行を “店舗売上”テーブルに追加する処理を、6時までに行う。
3.テーブルの保守
(1) 日付、店舗、商品の三つを分析軸として販売分析を行う。これらの分析軸を表現する次元テーブルの各列値を、まれに変更することがある。
(2) 2011年7月1日、SV の青木さんと井上さんに支部間の人事異動があり、担当店舗を入れ替えた。 そのために、当該店舗に新たに店舗番号を付与し、SV コードにそれぞれ新任 SV の社員コードを設定した行を “店舗” テーブルに追加した。
(3) 最近、商品分類である生菓子を生洋菓子と生和菓子に分けた。図2,3 の網掛け部分に示すように、商品コードを変えずに新たに商品分類番号と商品番号を付与した行を、それぞれ “商品分類” テーブルと“商品”テーブルに追加した。

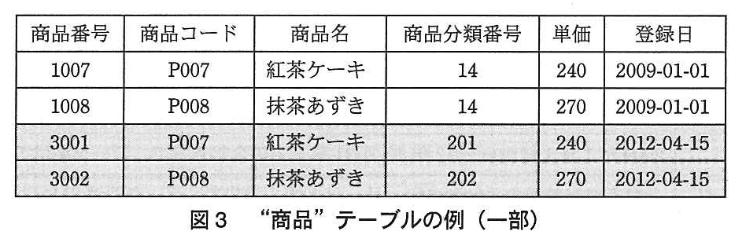
(4) 次元テーブルの変更後、“店舗売上” テーブルには最新の店舗番号及び商品番号を設定した行を追加するが、既に“店舗売上” テーブルに蓄積されている行を過去に遡って変更することはない。
4.販売分析
販売分析の例を表2に、対応する販売分析用 SQL文を表3 に示す。


表2中の分析 A1 を例に、販売分析の手順について説明する。
手順1 表3中の SQLA1 を実行し、その結果行をCSV ファイルに出力する。
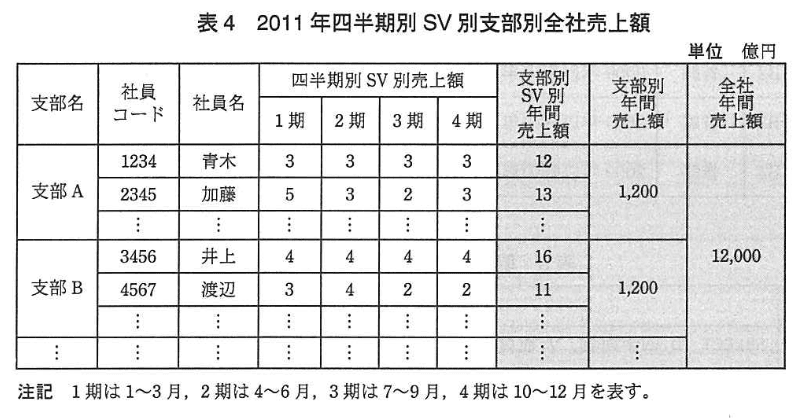
手順2 表計算ソフトに手順1のCSV ファイルを入力し、表4 に示すように支部名、
社員コード、社員名、四半期別 SV 別売上額を並べる。 表4の網掛け部分の支部別 SV 別年間売上額、支部別年間売上額、全社年間売上額は、表計算ソフトの機能を利用して計算する。
5.サマリテーブル
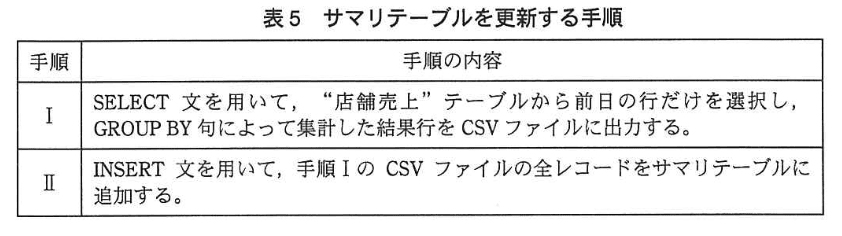
“店舗売上” テーブルへの1日当たりの入力件数は、2,000万件に達する。経営部門及び現場の SV からは、いろいろな切り口で迅速に分析したいという要望が出ている。現状では、“店舗売上”テーブルからその都度、集計していると、時間が掛かってしまう。そこでFさんは、図4に示すサマリテーブルを用意した。 そして 表5 に示す手順でサマリテーブルを毎日更新し、サマリテーブルからその都度、表 2中の分析 B1〜B4の売上額を計算することにした。
なお、サマリテーブルには、売上額がゼロの行は存在しないものとする。

〔問題点の指摘〕
Fさんの上司であるG氏は、次のように問題点を指摘した。
① 青木さんと井上さんの人事異動前後の売上実績が、表4の年間売上額に正しく反映されていない。今後、人事異動の時期にかかわらず、同じような問題が起きないようにすべきである。
② 表5の手順では、次元テーブルの列値の変更の有無にかかわらず、特定日を除き、SQL文で正しく更新できないサマリテーブルがある。
③2012年4月15日に、商品分類である生菓子を生洋菓子と生和菓子に分けたが、表2中の分析 B1〜B4 のうち、“店舗売上” テーブルから再集計をしないと、この最新の商品分類を反映できない分析がある。
設問1:表3の販売分析用 SQL文について、(1)〜(3)に答えよ。
(1)
表3中の(a)〜(c)に入れる適切な字句を答えよ。(b, cは順不同)
模範解答
a:LEFT
b:U1.販売数 IS NOT NULL 又は U1.販売数>0
c:U2.販売数 IS NOT NULL 又は U2.販売数>0
解説
解答の論理構成
- 分析要件を再確認
【問題文】「2011年4月1日に少なくともどちらか一方の店舗で売れた商品」
→ “商品” 列挙が主、店舗側に売上が無い場合も行は欲しい。 - 結合方向の決定
- FROM 句先頭は 商品 P
- ここに店舗別売上 U1、U2 を外部結合
- したがって (a) は LEFT
- 抽出条件の設定
- 外部結合で NULL になる行=その店舗で未販売
- 「少なくともどちらか」は「片方でも NULL でなければ良い」
- つまり (b) は U1.販売数 IS NOT NULL
(c) は U2.販売数 IS NOT NULL - OR 接続で両店舗とも NULL の行を除外し要件を満たす。
-
0 でも可
販売数が 0 行はそもそも “店舗売上” に存在しないという前提で
0 でも同義になる。
誤りやすいポイント
- RIGHT OUTER JOIN や FULL OUTER JOIN を選択してしまい、商品を起点にする設計思想を崩す。
- 外部結合直後に U1.販売数 IS NOT NULL AND U2.販売数 IS NOT NULL と AND 条件を書き、目的と反対に「両店舗で売れた商品」だけを取得してしまう。
- WHERE U1.店舗コード = 'M001' OR U2.店舗コード = 'M002' など意味の無い列比較を記述し、結合条件と検索条件を混同する。
FAQ
Q: IS NOT NULL と > 0 のどちらを使うべきですか?
A: “販売数が 0 の行は存在しない” という【問題文】前提があるため結果は同じです。NULL 判定の方が「外部結合で NULL になる行を除外」という意図が伝わりやすいです。
A: “販売数が 0 の行は存在しない” という【問題文】前提があるため結果は同じです。NULL 判定の方が「外部結合で NULL になる行を除外」という意図が伝わりやすいです。
Q: FULL OUTER JOIN では駄目ですか?
A: 機能的には結果を得られますが、FULL は余計な NULL 行も生成しパフォーマンスが劣化します。起点が明確な場合は LEFT OUTER JOIN が定石です。
A: 機能的には結果を得られますが、FULL は余計な NULL 行も生成しパフォーマンスが劣化します。起点が明確な場合は LEFT OUTER JOIN が定石です。
Q: なぜ 商品 P を先頭に置くのですか?
A: 「売れた商品の一覧」を作る際、商品マスタを基準にすると店舗ごとの売上列を横持ちしやすく、さらに未販売店舗の列が簡潔に NULL で表現できます。
A: 「売れた商品の一覧」を作る際、商品マスタを基準にすると店舗ごとの売上列を横持ちしやすく、さらに未販売店舗の列が簡潔に NULL で表現できます。
関連キーワード: OUTER JOIN, NULL判定、結合方向、WHERE句、パフォーマンス
設問1:表3の販売分析用 SQL文について、(1)〜(3)に答えよ。
(2)
表3中の SQLA2 において、内結合でなく外結合を使う理由を、本文中の用語を用いて、25字以内で述べよ。
模範解答
・時期と店舗によって売れ筋商品は異なるから
・店舗によって全商品が売れるとは限らないから
解説
解答の論理構成
- 分析要件の確認
「店舗コードM001とM002の店舗において、2011年4月1日に少なくともどちらか一方の店舗で売れた商品の商品名及び販売数一覧」とあります。 - 売上の偏り
商品の売れ方は【問題文】「時期と店舗によって売れ筋商品は異なる」で示され、M001 で売れたが M002 では売れていない(または逆)のケースが存在します。 - 結合方式の比較
- 内部結合(INNER JOIN)…両テーブルで条件を満たす行のみ残る。
- 外部結合(OUTER JOIN)…片方しか一致しない行も NULL を埋めて残す。
- 要件との整合
「少なくともどちらか一方」であるため、片方にしか無い行も結果に含める必要があり、外部結合が必須となります。 - 25字以内の解答例
「売れ筋が店舗ごとに異なり片方未販売商品を残すため」
誤りやすいポイント
- 2店舗ともで売れた商品だけを対象と勘違いして内部結合を選ぶ。
- 「全商品は毎日、各支部のいずれかの店舗で売れている」を根拠に “両店舗で必ず売れる” と早合点する。
- 結合条件に売上日や店舗コードを含め忘れ、期待外の NULL 行を大量に作ってしまう。
FAQ
Q: 内部結合でも UNION すれば同じ結果を得られますか?
A: 取得後に UNION でまとめる方法でも可能ですが、外部結合1本の方が可読性とパフォーマンスに優れます。
A: 取得後に UNION でまとめる方法でも可能ですが、外部結合1本の方が可読性とパフォーマンスに優れます。
Q: LEFT と RIGHT のどちらを使えば良いですか?
A: 2店舗を同列扱いにしたいので、商品マスタを基点に2回 OUTER JOIN し、左右いずれを使っても論理的には等価になります。
A: 2店舗を同列扱いにしたいので、商品マスタを基点に2回 OUTER JOIN し、左右いずれを使っても論理的には等価になります。
Q: 結果に NULL が出た場合の販売数表示は?
A: 未販売は NULL のままか、COALESCE(販売数,0) で 0 表示に整形すると業務上扱いやすくなります。
A: 未販売は NULL のままか、COALESCE(販売数,0) で 0 表示に整形すると業務上扱いやすくなります。
関連キーワード: 外部結合、内部結合、NULL, 集計クエリ、売上分析
設問1:表3の販売分析用 SQL文について、(1)〜(3)に答えよ。
(3)
表3中の(d)、(e)に入れる適切な字句を答えよ。(d, eは順不同)
模範解答
d:P1.商品コード 又は U.商品コード
e:P2.商品コード
解説
解答の論理構成
-
目的の確認
問題文は SQLA3 を「最新の商品分類に基づいた2012年1月1日以降の日別商品分類名別売上額」と説明しています。最新判定は “商品” テーブルの履歴管理仕様に従います。 -
履歴管理仕様
“商品” テーブルでは「商品の列値を変更したときに、変更履歴を残すために、その商品に新たに商品番号を付与し、変更後の列値を設定した行を “商品” テーブルに追加する」とあります。ここでまとめのキーは “商品コード” です。 -
サブクエリの意味
サブクエリは
sql SELECT MAX(P2.登録日) FROM 商品 P2 WHERE (d) = (e)と書かれています。MAX を取る列が “登録日” であることから、同じグループ内で最新行を選ぶ意図と分かります。 -
比較すべき列
「同じグループ」は同じ “商品コード” であることを 2. が示しています。したがって
・外側 (P1 もしくは U) の“商品コード”
・内側 (P2) の“商品コード”
を比較すればよい。 -
結論
外側は “P1.商品コード” を、内側は “P2.商品コード” を置くことで要件を満たします。外側を “U.商品コード” としても論理的に成立しますが、問題文では P1 を用いる書き方が自然であり、模範解答もそれを許容しています。
誤りやすいポイント
- “商品番号” と “商品コード” の混同
“商品番号” は履歴ごとに変わり、“商品コード” は一意固定です。最新抽出は “商品コード” を基準にします。 - 外側テーブルの選択ミス
P1 か U のどちらを用いても同一値ですが、FROM 句のエイリアスを確認せず “商品” ではなく “店舗売上” 側の列を指定し忘れるケースがあります。 - サブクエリで MAX を取る列の誤解
MAX(登録日) と書かれているため、比較対象列は日付ではなくキー列(商品コード)である点を見落としがちです。
FAQ
Q: “商品番号” を使ってはいけませんか?
A: “商品番号” は履歴追加のたびに新しく振られるため、過去と最新が別値になります。履歴をまとめるには不向きです。
A: “商品番号” は履歴追加のたびに新しく振られるため、過去と最新が別値になります。履歴をまとめるには不向きです。
Q: 外側に “U.商品コード” を書くと実行計画は変わりますか?
A: 意味は同じで最適化も同等になることが多いですが、可読性を考えるとサブクエリと同じ“商品”テーブルのエイリアス (P1) を使う方が誤解を防ぎます。
A: 意味は同じで最適化も同等になることが多いですが、可読性を考えるとサブクエリと同じ“商品”テーブルのエイリアス (P1) を使う方が誤解を防ぎます。
関連キーワード: 履歴管理、サブクエリ、集計関数、外部結合、データウェアハウス
設問2:〔問題点の指摘〕 の① への対応について、(1)、(2)に答えよ。
(1)
表4中の支部別 SV 別年間売上額、支部別年間売上額、全社年間売上額のうち、正しくないものを全て答えよ。また、人事異動前後の売上実績がそれらの年間売上額に正しく反映されなかった理由を、30字以内で述べよ。
模範解答
正しくないもの:支部別 SV別年間売上額、支部別年間売上額
理由:・社員が人事異動前に所属していた支部の情報を失うから
・SVの売上額が分析実施時点の所属支部に集計されるから
解説
解答の論理構成
- 問題文の事実確認
- “1.(4) 支部では、月の途中に…人事異動…”
- “3.(2) …店舗番号を付与し、SV コードに…新任 SV の社員コードを設定した行を ‘店舗’ テーブルに追加”
以上より、同一店舗でも売上日によって担当 SV・支部が変わる。
- SQLA1 の挙動
- FROM 店舗売上 U, 店舗 M, SV 社員 V, 日付 D
- U.店舗番号 = M.店舗番号 AND M.SVコード = V.社員コード
ここで “M” は履歴管理された店舗テーブルの「最新行」のみが結合対象になるため、過去売上も異動後の M.SVコード に付け替わる。
- 表計算での集計
異動前の売上が異動後支部に集計されるので、 ・支部別 SV 別年間売上額
・支部別年間売上額
が過大/過少となり不正確。全社年間売上額は影響を受けないため正しい。 - したがって解答は指定 2 箇所、理由は 30 字以内で上記のとおりとなる。
誤りやすいポイント
- 「店舗番号を付与し直す」ことで履歴が保持されると誤認し、M.SVコード が過去売上に影響しないと思い込む。
- 全社年間売上額まで誤っていると早合点しがちだが、売上総額は変わらない。
- 理由を 30 字以内で書く設問要件を見落とす。
FAQ
Q: どうすれば異動前後を正しく集計できますか?
A: 店舗 テーブルに着任期間列を追加し、U.売上日 BETWEEN 開始日 AND 終了日 で期間一致させる、いわゆるスローチェンジングディメンション(タイプ2)を実装します。
A: 店舗 テーブルに着任期間列を追加し、U.売上日 BETWEEN 開始日 AND 終了日 で期間一致させる、いわゆるスローチェンジングディメンション(タイプ2)を実装します。
Q: 店舗番号を付け替えるだけでは不十分なのですか?
A: 不十分です。M.SVコード しか履歴がないため、売上日と担当期間の整合が取れず、結合時に過去売上が最新担当者へ紐付いてしまいます。
A: 不十分です。M.SVコード しか履歴がないため、売上日と担当期間の整合が取れず、結合時に過去売上が最新担当者へ紐付いてしまいます。
Q: SQLA1 を修正する場合のポイントは?
A: AND U.売上日 BETWEEN M.登録日 AND COALESCE(M.登録終了日、'9999-12-31') など期間条件を追加し、売上発生時点の担当情報に絞り込みます。
A: AND U.売上日 BETWEEN M.登録日 AND COALESCE(M.登録終了日、'9999-12-31') など期間条件を追加し、売上発生時点の担当情報に絞り込みます。
関連キーワード: スローチェンジングディメンション、外部結合、履歴管理、集計関数、ディメンションテーブル
設問2:〔問題点の指摘〕 の① への対応について、(1)、(2)に答えよ。
(2)
〔問題点の指摘〕 の① への対応として、F さんは、変更履歴を残すために、“SV 社員” テーブルと “店舗” テーブルの構造を次のように変更し、併せてSQLA1 を見直した。 この対応後に支部間の人事異動によって SV の担当店舗が変わった場合、その変更を “SV 社員” テーブルに対してどのように反映すべきかを、30字以内で述べよ。
SV社員(SV番号、社員コード、社員名、支部コード、支部名、着任日)
店舗(店舗番号、店舗コード、店舗名,SV 番号、登録日)
模範解答
・当該社員に新しい SV番号を付与した行を追加する。
・当該社員に異動後の支部コードを設定した行を追加する。
解説
解答の論理構成
- 変更要求の背景
問題文では「支部では、月の途中に…SV の担当店舗を変えることがある」とし、その結果「青木さんと井上さんの人事異動前後の売上実績が…正しく反映されていない」①と指摘しています。 - 新スキーマの目的
F さんは「SV社員(SV番号、社員コード、…、支部コード、…)」に変更し、SV番号 を主キーにして履歴を残す方針を採用しました。これは Slowly Changing Dimension Type-2 と同じ考え方です。 - 履歴を正しく残す方法
Type-2 では属性値(ここでは 支部コード)が変わった時点で「新しいサロゲートキー(SV番号)を振ったレコードを追加」し、旧レコードは残して過去分析を可能にします。 - したがって解答
・当該社員に新しい SV番号 を付与した行を追加する。
・当該社員に異動後の 支部コード を設定した行を追加する。
誤りやすいポイント
- 既存行の 支部コード を UPDATE で書き換えてしまう
→ 過去の担当支部が失われ、前年同期比較などができなくなる。 - SV番号 を社員番号のように「一人一つ」と思い込む
→ 異動のたびに増える一対多関係である点を取り違えやすい。 - 「店舗」テーブルだけ更新すれば良いと考え、SV社員 テーブルを放置
→ 新旧 SV番号 が店舗側に存在しない不整合が起きる。
FAQ
Q: なぜ 社員コード をキーにしないのですか?
A: 社員コード をキーにすると UPDATE が発生し、過去分析が破壊されます。履歴保持のために不変の業務キー(社員コード)とは別に再利用しないサロゲートキー SV番号 を設けます。
A: 社員コード をキーにすると UPDATE が発生し、過去分析が破壊されます。履歴保持のために不変の業務キー(社員コード)とは別に再利用しないサロゲートキー SV番号 を設けます。
Q: 店舗 テーブルの更新はどうなりますか?
A: 異動日以降に対象店舗へ新しい 店舗番号 を付与し、SV番号 に前項で追加した新レコードの SV番号 を設定します。
A: 異動日以降に対象店舗へ新しい 店舗番号 を付与し、SV番号 に前項で追加した新レコードの SV番号 を設定します。
Q: サマリテーブルに影響はありますか?
A: 対応後は SV番号 を介して支部や社員が正しく紐づくため、再集計なしでも正しい担当別集計が可能になります。
A: 対応後は SV番号 を介して支部や社員が正しく紐づくため、再集計なしでも正しい担当別集計が可能になります。
関連キーワード: サロゲートキー、変更履歴管理、Slowly Changing Dimension, 集計ロジック、データウェアハウス
設問3:〔問題点の指摘〕 の ① への対応が済んでいることを前提に、〔問題点の指摘〕の② ③への対応について、(1)〜(3)に答えよ。
(1)
サマリテーブル S1〜S4 のうち、〔問題点の指摘〕 の②に該当するものを一つ選び、特定日の例を一つ答えよ。 また、その特定日を除き、SQL 文で正しく更新できない理由を、20字以内で述べよ。
模範解答
サマリテーブル名:S2 又は S4
特定日の例:
サマリテーブル名を S2と解答した場合
・四半期の初日
サマリテーブル名を S4と解答した場合
・各月の初日
理由:・主キーが重複するから
・挿入すべき行が既に存在するから
解説
解答の論理構成
- 手順 I は【表5】で「前日の行だけを選択」し、手順 II でその結果を INSERT しています。
- S2 の列構成は【図4】「S2(年、四半期名、店舗コード、店舗名、商品コード、商品名、売上額)」です。
- 同一四半期内では「年、四半期名、店舗コード、店舗名、商品コード、商品名」が同一のまま日々売上額が増えるため、2 日目以降に INSERT すると「主キーが重複するから」(20 字以内の理由)SQL が失敗します。
- ただし四半期が替わる最初の日、例として 2011-04-01(第 2 四半期初日)だけはテーブルにまだ行が存在しないため、正しく挿入されます。
- S4 も月次サマリなので同様の問題を抱えますが、問われたのは「一つ選び」なので S2 を採用しました。
誤りやすいポイント
- 「S1 も ‘日’ を持つから安全だ」と理解できずに S1 を選んでしまう。
- 「INSERT 後に UPDATE すれば良い」と手順外の操作を想定してしまう。
- 特定日を「四半期末」と誤答する(実際は四半期開始日で初回 INSERT)。
- 主キーではなく「売上額が 0 行は無い」条件を問題の原因と取り違える。
FAQ
Q: S4 が該当すると答えても減点になりますか?
A: 問題文の模範解答に「S2 又は S4」とあるため、どちらでも正解です。ただし特定日の例を「各月の初日」としないと整合しません。
A: 問題文の模範解答に「S2 又は S4」とあるため、どちらでも正解です。ただし特定日の例を「各月の初日」としないと整合しません。
Q: UPDATE 付きの MERGE を使えば問題②は解決しますか?
A: はい。四半期(または月)サマリでは MERGE/UPSERT で既存行に加算更新し、存在しなければ挿入する方式が一般的です。
A: はい。四半期(または月)サマリでは MERGE/UPSERT で既存行に加算更新し、存在しなければ挿入する方式が一般的です。
Q: サマリテーブルはなぜ“売上額がゼロの行は存在しない”前提なのですか?
A: 不要な行を省くことで行数を削減し、サマリテーブルの検索・保守性能を高めるためです。ゼロ売上は分析上も意味が薄く、省略しても問題になりにくいケースが多いです。
A: 不要な行を省くことで行数を削減し、サマリテーブルの検索・保守性能を高めるためです。ゼロ売上は分析上も意味が薄く、省略しても問題になりにくいケースが多いです。
関連キーワード: サマリ更新、主キー重複、増分集計、UPSERT, データマート
設問3:〔問題点の指摘〕 の ① への対応が済んでいることを前提に、〔問題点の指摘〕の② ③への対応について、(1)〜(3)に答えよ。
(2)
(1)の問題が解決していることを前提に、表 2 中の分析 B1, B2 の売上額を集計できるサマリテーブルの名称を、それぞれ GROUP BY句による年間の集計対象行数が少ない順に、全て答えよ。
なお、一つのサマリテーブルから売上額を集計するものとし、必要に応じて次元テーブルを参照するものとする。
模範解答
B1:S1
B2:S3, S4, S2
解説
解答の論理構成
- 【問題文】の分析要件
- B1: 「2009年以降の年別月別店舗名別商品区分名別売上額」
- B2: 「2009年以降の年別商品名別売上額」
- “図4” のサマリテーブル粒度
- S1(年、月、日、店舗コード、商品分類番号、…)
- S2(年、四半期名、店舗コード、商品コード、…)
- S3(年、月、日、支部コード、商品コード、…)
- S4(年、月、商品コード、社員コード、…)
- 行数見積もり(主な列だけで概算)
- 1日当たりの “店舗売上” 件数は “2,000万件”。
- 店舗数 “10,000”、商品点数 “3,000”、SV “100×10”。
- S1: 日別×店舗×商品分類(200) → 行数 ≒ 365×10,000×200
- S3: 日別×支部(10)×商品 → 365×10×3,000
- S4: 月別×商品×SV(1,000) → 12×3,000×1,000
- S2: 四半期別×店舗×商品 → 4×10,000×3,000
- 求めたい粒度との比較
- B1 は「商品区分名」。S1 はすでに「商品分類番号」までまとまっており、商品区分名は商品分類テーブルと結合するだけ。よって追加集計行数が最少。
- B2 は「年×商品名」。列の余分が最も少ないのは S3(支部単位)→次に S4(月・SV 単位)→最後に S2(店舗・四半期単位)。
- 以上より
- B1:S1
- B2:S3, S4, S2(少ない順)
誤りやすいポイント
- 「商品区分名が S1 に無いから使えない」と早合点する
→ 商品分類番号から商品区分名は次元テーブル参照で取得可能。 - 行数比較で「列の数」だけを見てしまう
→ 必ず【値のバリエーション】を掛け合わせて概算する。 - B2 で S4 を最小と判断してしまう
→ SV 列が “1,000” 値を生むため S3 より行数が多い。
FAQ
Q: 日付列を持つ S1 と S3 では、年集計時に日付列の存在は行数に影響しないのでは?
A: 日付列を保持している以上、テーブル内には日ごとの行が存在します。GROUP BY で日を切り捨てる前は行数がそのまま残るため影響します。
A: 日付列を保持している以上、テーブル内には日ごとの行が存在します。GROUP BY で日を切り捨てる前は行数がそのまま残るため影響します。
Q: 商品区分名を得るための結合がコスト高では?
A: 行数が少なければ結合コストも小さいため、サマリ選択の第一基準は「行数の少なさ」です。結合自体はインデックスを用いれば軽微です。
A: 行数が少なければ結合コストも小さいため、サマリ選択の第一基準は「行数の少なさ」です。結合自体はインデックスを用いれば軽微です。
Q: S2 の “四半期名” 列は B2 の集計に不要だが悪影響は?
A: 列が増えるだけなら問題ありませんが、値のバリエーションが増える(四半期は4種類)ため行数が4倍になります。これが S2 が最後になる理由です。
A: 列が増えるだけなら問題ありませんが、値のバリエーションが増える(四半期は4種類)ため行数が4倍になります。これが S2 が最後になる理由です。
関連キーワード: 集約関数、粒度設計、サマリーテーブル、行数見積り、多次元分析
設問3:〔問題点の指摘〕 の ① への対応が済んでいることを前提に、〔問題点の指摘〕の② ③への対応について、(1)〜(3)に答えよ。
(3)
分析 B1〜B4 のうち、〔問題点の指摘〕の③に該当するものを、全て答えよ。
模範解答
B3
解説
解答の論理構成
- 変更内容の確認
【問題文】「2012年4月15日」に商品分類「生菓子」を「生洋菓子」「生和菓子」に分割し、新しい行を “商品分類”・“商品” テーブルへ追加した。 - サマリテーブル側の問題
【問題文】図4 S1 は「商品分類番号、商品分類名」を列として保持し、表5手順 I・II により“前日の行だけ”を積み上げている。したがって 2012年4月14日以前の行は旧分類名「生菓子」のまま固定され、分割後に自動的には更新されない。 - 各分析で利用されるサマリテーブル
• B1:次元は「商品区分名」。商品区分は「日配食品」などで変わっていないため影響なし。
• B2:次元は「商品名」。分類変更に関係しない。
• B3:次元は「店舗名」と 「商品分類名」。S1 の固定値をそのまま使うため、旧データが更新されず影響を受ける。
• B4:売上軸に 支部名 と 商品分類名 が入るが、S1 には支部列がないため、実際の集計では商品コード主体の S3 を JOIN して最新の分類を参照する設計となる。JOIN 時点で“商品分類”テーブルから最新分類名を取得できるので再集計は不要。 - よって、該当するのは B3 のみとなる。
誤りやすいポイント
- 「商品区分名も分割された」と誤解して B1 まで選んでしまう。
- 「支部名を含むから B4 も S1 だろう」と早合点し、JOIN で最新値を取得できる事実を見逃す。
- サマリテーブルに「商品分類番号」があれば最新名を引けると思い込み、「商品分類名」も物理的に保持している点を見落とす。
FAQ
Q: なぜ B4 は再集計不要なのですか?
A: B4 で直接保持しているのは S3 の「商品コード」。商品分類名はクエリ実行時に “商品”→“商品分類” テーブルを JOIN して取得できるため、分類変更を自動的に反映できます。
A: B4 で直接保持しているのは S3 の「商品コード」。商品分類名はクエリ実行時に “商品”→“商品分類” テーブルを JOIN して取得できるため、分類変更を自動的に反映できます。
Q: 今後も商品分類が頻繁に変わる場合の対策は?
A: サマリテーブルに名称を保持せず「番号キーのみ」を格納し、レポート時にマスタを JOIN する設計に改めると再集計を回避できます。
A: サマリテーブルに名称を保持せず「番号キーのみ」を格納し、レポート時にマスタを JOIN する設計に改めると再集計を回避できます。
関連キーワード: ディメンション更新、スローチェンジングディメンション、集計テーブル、正規化、JOIN
