\ せっかくなら /
データベーススペシャリストを
クイズ形式で学習しませんか?
クイズを始める→
すぐに利用可能!
データベーススペシャリスト試験 過去問・解説一覧
年度・セッション別のデータベーススペシャリスト試験過去問題集
データベーススペシャリスト試験の過去問演習について
本ページではデータベーススペシャリスト試験の過去問を年度・セッション別に計448問収録しています。データベーススペシャリスト試験は過去問演習が合格への最短ルートです。年度別・セッション別の問題リストから自由に問題を選び、解答・解説を確認できます。
スマートフォンにも最適化されているため、通勤・通学などのスキマ時間学習にも活用してください。データベーススペシャリスト試験の試験概要・出題形式・難易度・合格率の推移は、このページ下部にまとめて掲載しています。
データベーススペシャリスト試験とは(試験概要)
データベーススペシャリスト試験(DB)は、レベル4の高度試験として「データベース全体計画から設計・構築・運用・性能チューニング・監査まで一貫してリードできるプロフェッショナル」を対象に実施される国家試験。最新シラバス Ver.4.1 では、クラウド/NoSQL/生成AI などの動向も踏まえ、全社的データ利活用を支える戦略立案力と実装・運用の実務力の双方が問われる。
| 項目 | 内容 |
|---|---|
| 区分 | DB |
| レベル | レベル4 |
| 実施方式 | CBT方式(令和8年度〜) |
| 実施時期 | 後期(2027年2月頃)※年1回 |
| 試験科目 | 科目A-1 / 科目A-2 / 科目B-1 / 科目B-2(旧:午前Ⅰ/午前Ⅱ/午後Ⅰ/午後Ⅱ) |
| 公式情報 | IPA公式ページ |
| シラバス | シラバス Ver.4.1(2023-12-25 公開) |
特徴・概要
- 組織の情報化戦略を踏まえた中長期的データベース全体計画と標準化を推進し、グローバル最適化を実現する。
- 業務・システムの現状調査から課題分析を行い、データベース要件(データ/容量/性能/セキュリティ/運用・保守/災害対策など)を定義する。
- 概念→論理→物理データモデルを一貫して設計し、正規化/非正規化・ER図・UML などのモデル表現とレビューを主導する。
- RDBMS とその他データマネジメント(NoSQL、分散DB、クラウド DB 等)を比較検討し、最適な製品選定・導入を実施する。
- 物理設計ではトランザクション特性分析、バックアップ/レプリケーション、排他制御、ストレージ/仮想化構成などを踏まえ性能と可用性を最適化する。
- 実装・テストでは定義・ロード・シミュレーション・障害復旧演習を行い、移行・バージョンアップ計画を策定・遂行する。
- 運用・保守計画を策定し、性能監視・キャパシティ管理・災害対策・監査対応・利用者支援・改善提案まで持続的に実践する。
試験の形式・出題構成・採点方式
データベーススペシャリスト試験(DB)は、令和8年度(2026年度)試験からCBT(Computer Based Testing)方式へ移行し、従来の「午前Ⅰ・午前Ⅱ・午後Ⅰ・午後Ⅱ」がそれぞれ「科目A-1・科目A-2・科目B-1・科目B-2」へ名称変更されました。出題形式・出題数・試験時間は従来から変更ありません。
| 試験科目 | 旧名称 | 時間 | 出題形式・構成 |
|---|---|---|---|
| 科目A-1 | 午前Ⅰ | 50分 | 多肢選択式(四肢択一)30問。情報技術の共通知識。一定条件で免除可 |
| 科目A-2 | 午前Ⅱ | 40分 | 多肢選択式(四肢択一)25問。データベース分野の専門知識 |
| 科目B-1 | 午後Ⅰ | 90分 | 記述式。3問出題・2問選択 |
| 科目B-2 | 午後Ⅱ | 120分 | 記述式。2問出題・1問選択 |
採点・合格基準: 各科目とも100点満点で60点以上が基準点。科目A-1→A-2→B-1→B-2の順に採点され、いずれかが基準点未満だと、その時点で不合格(以降は採点されない)。
科目A-1免除制度: 応用情報技術者試験の合格者や、過去2年以内に高度試験・支援士試験の科目A-1(旧午前Ⅰ)で基準点を満たした受験者などは、申請により科目A-1が免除されます。
実施時期・受験機会: 令和8年度は後期(2027年2月頃)の年1回実施予定。CBT化により、受験者が試験期間内で日時・会場を選んで受験します。最新の日程・申込方法はIPA公式で必ず確認してください。
2027年度からの新試験制度: IPAが2026年3月31日に公表した試験区分体系の見直しにより、データベーススペシャリスト試験を含む現行の高度試験は2026年度(令和8年度)の試験実施をもって終了する予定です。2027年度夏〜秋頃からは「プロフェッショナルデジタルスキル試験(PDS)」へ大括り化・再編され、データベース領域は主に**データ・AI区分(データ基盤・整備領域)**に関連づけられる見込みです。現行区分での合格を狙う場合は、2026年度後期(2027年2月頃)が最後の受験機会になる見込みです。
対象者像・求められる知識と技能
対象者像
- 高度IT人材として確立した専門分野をもち、データベースに関係する固有技術を活用し、最適な情報システム基盤の企画・要件定義・開発・運用・保守において中心的な役割を果たすとともに、固有技術の専門家として、情報システムの企画・要件定義・開発・運用・保守への技術支援を行う者
求められる主な能力・役割
- 中長期的データベース全体計画とデータ定義標準化を策定・推進するリーダーシップ
- 業務・データ現状分析から問題抽出・課題解決策を創出し、要件定義を合意形成する力
- 概念/論理/物理モデリングを通じた最適なテーブル・インデックス・ビュー設計力
- RDBMS/NoSQL/クラウド DB 等の比較評価・導入・移行を主導する技術選定力
- 性能チューニング(SQL 最適化・索引/パーティション設計・資源見積り)と障害対策の実践力
- 運用・保守・監査・災害対策を含む DB ライフサイクル全体のマネジメント力
求められる知識
- データベース基礎理論(関係モデル、正規化、ER/UML、ドメイン設計、メタデータ管理)
- SQL・トランザクション制御・ロック/多版方式・排他制御理論
- RDBMS/NoSQL(ドキュメント、キーバリュ、列指向、グラフ)/分散 DB/クラウド DB の特徴
- 物理設計(圧縮、パーティショニング、インデックス、ストレージ/仮想化、RAID)と容量・性能見積り
- バックアップ/リカバリ/レプリケーション/HA クラスタ設計、災害対策 DR 設計
- 性能評価・ベンチマーク・ボトルネック分析・キャパシティ管理手法
- 情報セキュリティ(アクセス制御、暗号化、マスキング)と監査/コンプライアンス基準
- クラウドネイティブ設計・IaC、AI/ビッグデータ基盤との連携・データ品質/クレンジング手法
求められる技能
- 全社 DB 計画策定・標準化・リポジトリ運用
- 業務部門ヒアリング・現状調査から課題分析→要件定義書作成・レビュー
- 概念→論理→物理モデル変換、正規化/非正規化判断、インテグリティ制約設計
- RDBMS/NoSQL 製品比較・PoC・導入、クラウド DB 移行設計
- SQL/ユーティリティ/統計処理を用いた性能測定・チューニング
- バックアップ・リカバリ計画/レプリケーション方式設計と検証
- 運用監視・ログ分析・キャパシティ予測・資源増強計画の立案
- 監査資料作成・システム監査対応・災害対策訓練の主導
- 利用者サポート・教育、データ利活用・新ビジネスへの改善提案
シラバス概要
- 1. データベース全体計画・標準化
- 全社 DB 計画(中長期/短期)の策定とグローバル最適化
- データ定義・コード体系・マスタ統合・リポジトリ管理標準化
- 2. 要件定義(現状調査・課題分析~要件書レビュー)
- 業務プロセス・データ調査と課題抽出、作業範囲確定
- データ要件・容量・性能・セキュリティ・運用・災害対策要件定義
- 要件レビュー(利用者/開発者/運用者参加)
- 3. 分析・設計(概念/論理/物理)
- 概念データモデル作成・検証(ER/UML・ビジネスルール整合)
- 論理モデル変換・正規化・インデックス/ビュー設計・検証
- 物理設計:トランザクション分析・容量算出・排他制御・分散/クラウド配置・性能最適化
- 4. 実装・テスト・移行
- RDBMS/NoSQL 選定・導入、DB 定義・ロード・ユーティリティ活用
- 応答シミュレーション/障害復旧演習、データ移行・バージョンアップ計画と実施
- テスト/移行時のマスキング・データ品質・クレンジング・性能測定
- 5. 運用・管理・性能チューニング・利用者サポート
- 運用・保守計画、監視(性能/障害/セキュリティ)とキャパシティ管理
- ボトルネック分析・リソース最適化・SQL/索引/物理配置チューニング
- バックアップ/DR、監査対応、災害対策演習、利用者支援・改善提案
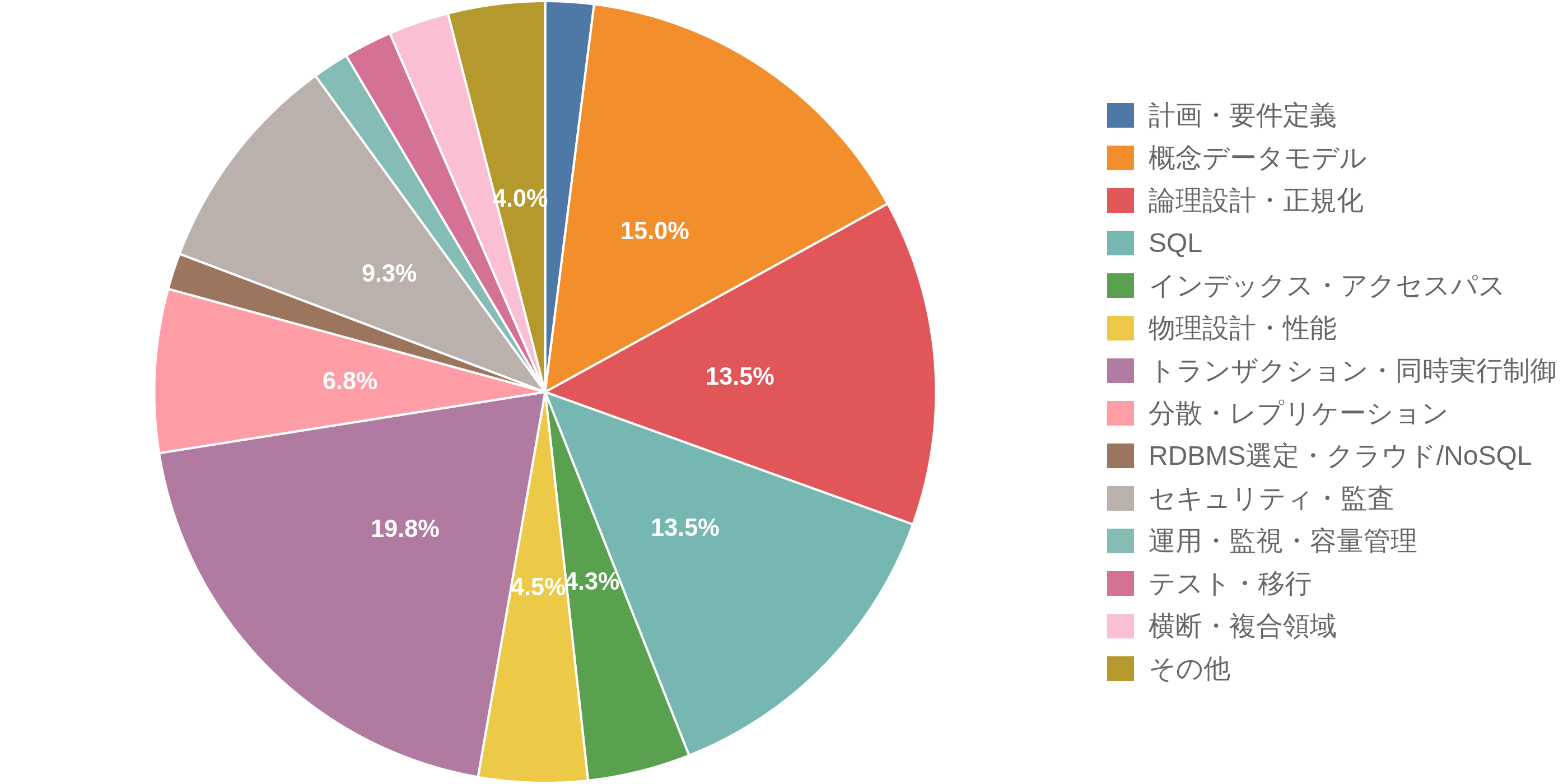
分野別の出題数・出題傾向(学習テーマ別)
データベーススペシャリスト試験の午前問題の出題範囲を、情報処理推進機構(IPA)が公表する公式シラバス(Ver.4.1)を読み解いたうえで、戦国IT独自の切り口で学習テーマ別に整理し、テーマごとの出題数を集計しました。そのため、IPA公式の分野区分とは、分類のまとめ方や名称が一部異なります(公式の正式な分野構成はIPAのシラバスでご確認ください)。どのテーマが多く問われているかの目安としてご活用ください。
午前問題 全400問を、戦国IT独自の学習テーマ別に分類した出題数の分布です。
| 学習テーマ | 出題数 | 割合 |
|---|---|---|
| 計画・要件定義 | 8問 | 2.0% |
| 概念データモデル | 60問 | 15.0% |
| 論理設計・正規化 | 54問 | 13.5% |
| SQL | 54問 | 13.5% |
| インデックス・アクセスパス | 17問 | 4.2% |
| 物理設計・性能 | 18問 | 4.5% |
| トランザクション・同時実行制御 | 79問 | 19.8% |
| 分散・レプリケーション | 27問 | 6.8% |
| RDBMS選定・クラウド/NoSQL | 6問 | 1.5% |
| セキュリティ・監査 | 37問 | 9.2% |
| 運用・監視・容量管理 | 6問 | 1.5% |
| テスト・移行 | 8問 | 2.0% |
| 横断・複合領域 | 10問 | 2.5% |
| その他 | 16問 | 4.0% |
出題範囲とサンプル問題(学習テーマ別)
ここからは、上の分布で示した学習テーマごとに、何が問われるかの要点と、実際に出題された午前の過去問を1問ずつ紹介します。
本セクションで扱う学習テーマは全13テーマです。
- 計画・要件定義
- 概念データモデル
- 論理設計・正規化
- SQL
- インデックス・アクセスパス
- 物理設計・性能
- トランザクション・同時実行制御
- 分散・レプリケーション
- RDBMS選定・クラウド/NoSQL
- セキュリティ・監査
- 運用・監視・容量管理
- テスト・移行
- 横断・複合領域
計画・要件定義
このテーマで問われること
全社データベース構想を起点に、現状調査で業務・データ・課題を把握し、対象範囲(スコープ)を確定した上で、データベースに求める初期要件を整理する。標準化(命名規約、コード体系、データ型・桁、用語定義、メタデータ管理方針)により、部門横断で一貫したデータ定義と運用を可能にする。試験では、要件の優先度付けや制約条件の明確化、関係者合意の取り方まで含め、計画から要件へ落とす筋道が問われる。
出題の焦点
- 現状調査での業務・データ・課題の整理
- スコープ確定(対象システム/データ/期間)の考え方
- 性能・可用性・拡張性など非機能要件の定義
- データ標準化(命名・コード・型・用語)の目的と効果
- 全社DB化の狙い(統合・重複排除・整合性確保)
- 要件の優先度付けと合意形成
問題 ― 令和2年午前2 問25
ユースケース駆動開発の利点はどれか。
- ア:開発を反復するので、新しい要求やビジネス目標の変化に柔軟に対応しやすい。
- イ:開発を反復するので、リスクが高い部分に対して初期段階で対処しやすく、プロジェクト全体のリスクを減らすことができる。
- ウ:基本となるアーキテクチャをプロジェクトの初期に決定するので、コンポーネントを再利用しやすくなる。
- エ:ひとまとまりの要件を1単位として設計からテストまで実施するので、要件ごとに開発状況が把握できる。
正解と解説
正解:エ
- 結論:ユースケース駆動開発は要件単位で設計からテストまで行い、開発状況を明確に把握できる点が最大の利点です。
- 根拠:ユースケースはシステムの利用シナリオを具体的に表現し、ひとまとまりの機能単位で開発を進めるため管理が容易です。
- 差がつくポイント:反復開発やリスク管理は他の開発手法の特徴であり、ユースケース駆動の本質は要件単位の進捗管理にあります。
概念データモデル
このテーマで問われること
業務の意味を損なわずにデータを表現するため、エンティティ、属性、関連、識別子(主キー候補)を抽出し、ER図などで概念データモデルを作成する分野。検証では、業務ルールの反映漏れ、概念の粒度過不足、関連の多重度・任意性、用語の揺れ、将来拡張を見据えたモデルの安定性を確認する。試験では、業務記述からのモデル化手順、誤った関連設定の指摘、概念レベルでの整合性・網羅性の説明が問われる。
出題の焦点
- エンティティ/属性/関連の抽出手順
- 識別子(キー候補)の設定根拠
- 多重度・任意性(0..1、1..N等)の解釈
- 業務ルールのモデル反映(制約・状態)
- 粒度調整(過度な統合/分割の回避)
- 概念モデルの検証観点(漏れ・重複・矛盾)
問題 ― 令和5年午前2 問3
概念データモデルの説明として、最も適切なものはどれか。
- ア:階層モデル、ネットワークモデル、関係モデルがある。
- イ:業務プロセスを抽象化して表現したものである。
- ウ:集中型DBMSを導入するか、分散型DBMSを導入するかによって内容が変わる。
- エ:対象世界の情報構造を抽象化して表現したものである。
正解と解説
正解:エ
- 結論:概念データモデルは対象世界の情報構造を抽象化して表現するものである。
- 根拠:概念データモデルは現実世界の情報を理解しやすく整理し、システム設計の基盤となる。
- 差がつくポイント:物理的な実装や業務プロセスではなく、情報の本質的な構造に着目する点を押さえること。
論理設計・正規化
このテーマで問われること
概念モデルをリレーショナル構造へ写像し、表(リレーション)、列(属性)、主キー・外部キー、制約(NOT NULL、参照整合性等)を定義して論理データモデルを作成する。正規化により更新時異常(挿入・更新・削除異常)を防ぎつつ、性能や運用を踏まえた非正規化の判断も行う。検証では、関数従属性の誤り、キー設計不備、参照関係の不整合、冗長性と整合性のトレードオフを確認する。試験では、正規形判定や分割案、制約設計の妥当性が問われる。
出題の焦点
- 概念→論理(リレーション)への写像
- 主キー/候補キー/外部キーの設計
- 正規化(第1〜第3正規形、BCNFの基礎)
- 更新時異常の説明と回避策
- 参照整合性と制約設計(NULL可否含む)
- 非正規化の判断(性能・集計・運用要件)
問題 ― 平成29年午前2 問4
関係R(A, B, C, D, E)において、関数従属 {A, B} → C, {B, C} → D, D → {A, E}が成立する。これらから決定できるRの候補キーを全て挙げたものはどれか。
- ア:{A, B, C}
- イ:{A, B}, {B, C}
- ウ:{A, B}, {B, C}, {B, D}
- エ:{B, C}, {C, D}
正解と解説
正解:ウ
- 結論:候補キーは{A, B}、{B, C}、{B, D}の3つが存在します。
- 根拠:与えられた関数従属から属性閉包を計算し、全属性を決定できる最小の属性集合を特定します。
- 差がつくポイント:属性閉包の計算ミスや、決定できる属性の見落としを防ぐことが重要です。
SQL
このテーマで問われること
論理・物理設計を実際のDBMS上に反映するためのSQL活用分野。DDLで表・ビュー・制約・索引などを定義し、DMLで検索・更新・集計を実装する。試験では、要件を満たす問い合わせの組立て(結合、集約、サブクエリ、集合演算)、更新系SQLの副作用(重複更新、参照制約違反)、ビューや制約での業務ルール実装、権限付与(GRANT等)の基礎が問われる。実装時の保守性(可読性、再利用性)も論点になりやすい。
出題の焦点
- DDL(CREATE/ALTER、制約定義)の読み書き
- 結合・集約・サブクエリの設計力
- 更新系SQLと整合性(参照制約・一意性)
- ビューの目的(抽象化・権限・互換性)
- 集合演算やNULLの扱い
- 権限(GRANT/REVOKE)の基本
問題 ― 平成29年午前2 問9
SQLが提供する3値論理において、Aに5, Bに4, CにNULLを代入したとき、次の論理式の評価結果はどれか。
(A>C) or (B>A) or (C=A)- ア:∅(空)
- イ:false (偽)
- ウ:true (真)
- エ:unknown (不定)
正解と解説
正解:エ
- 結論:論理式
(A > C) or (B > A) or (C = A)の評価結果は「unknown (不定)」です。 - 根拠:SQLの3値論理では、NULLを含む比較は「unknown」と評価され、OR演算は「true」があれば真、なければ「unknown」か「false」となるためです。
- 差がつくポイント:NULLの扱いと3値論理のOR演算の評価順序を正確に理解しているかが合否を分けます。
インデックス・アクセスパス
このテーマで問われること
SQLの実行性能を左右する索引設計とアクセスパス理解の分野。B+木やビットマップ等の索引方式、複合索引の列順、選択度、カバリング、レンジ検索と等価検索の違い、ソートや結合方式(ネステッドループ、ハッシュ、ソートマージ)との関係を整理する。実行計画を読み、フルスキャン・インデックススキャンの選択理由を説明できることが重要。試験では、クエリ条件に対する適切な索引提案、不要索引の弊害(更新コスト、容量増)や統計情報の影響が問われる。
出題の焦点
- 索引方式(B+木等)の特徴と使い分け
- 複合索引の列順設計と条件式の関係
- 選択度・カーディナリティと実行計画
- 結合方式とアクセスパスの基本
- カバリング/クラスタリングの効果
- 索引の副作用(更新負荷・容量増・ロック)
問題 ― 平成25年午前2 問15
$B^+$木インデックスとビットマップインデックスを比較した説明のうち、適切なものはどれか。
- ア:ANDやOR操作だけで行える検索は$B^+$木インデックスの方が有効である。
- イ:BETWEENを用いた範囲指定検索はビットマップインデックスの方が有効である。
- ウ:NOTを用いた否定検索は$B^+$木インデックスの方が有効である。
- エ:少数の異なる値をもつ列への検索はビットマップインデックスの方が有効である。
正解と解説
正解:エ
- 結論:少数の異なる値を持つ列にはビットマップインデックスが有効である。
- 根拠:ビットマップインデックスは値ごとにビット列を持ち、少ない異なる値で効率的に検索できるため。
- 差がつくポイント:範囲検索や論理演算の適用範囲を理解し、適切なインデックス選択が重要である。
物理設計・性能
このテーマで問われること
データの格納方式や配置を設計し、要求性能を満たすための物理設計・チューニング分野。表領域・ファイル配置、パーティション、圧縮、I/O分散、メモリ/キャッシュ、ログ設計などを踏まえ、処理特性(OLTP/バッチ/分析)に合わせて設計する。性能チューニングでは、ボトルネック(CPU、I/O、ロック、ネットワーク)を切り分け、実行計画・統計・パラメタ・SQL・索引・物理配置の観点で対策を立てる。試験では、設計判断の根拠と効果見積りが問われる。
出題の焦点
- 表領域・ファイル配置とI/O特性
- パーティショニング設計(範囲/ハッシュ等)
- ログ/一時領域/バッファの設計観点
- 性能問題の切り分け(CPU/I/O/ロック)
- 統計情報・パラメタ調整の影響
- OLTPと分析系での設計差
問題 ― 令和6年午前2 問2
クライアントサーバシステムにおけるストアドプロシージャに関する記述のうち、適切でないものはどれか。
- ア:機密性が高いデータに対する処理を特定のプロシージャ呼出しに限定することによって、セキュリティを向上させることができる。
- イ:システム全体に共通な処理をプロシージャとして格納しておくことによって、処理の標準化を行うことができる。
- ウ:データベースへのアクセスを細かい単位でプロシージャ化することによって、処理性能(スループット)を向上させることができる。
- エ:複数のSQL文から成る手続を1回のプロシージャ呼出しで実行することによって、クライアントとサーバの間の通信回数を減らすことができる。
正解と解説
正解:ウ
- 結論:ストアドプロシージャは処理の標準化やセキュリティ向上、通信回数削減に効果的だが、細かい単位でのプロシージャ化が必ずしも性能向上につながるわけではない。
- 根拠:ストアドプロシージャは複数SQL文をまとめて実行し通信負荷を減らすが、細分化しすぎるとオーバーヘッドが増え性能低下の原因になる。
- 差がつくポイント:性能向上を狙う際は、処理の粒度を適切に設定し、通信回数削減や処理の集約を意識することが重要である。
トランザクション・同時実行制御
このテーマで問われること
複数利用者環境で整合性を保つためのトランザクション管理と同時実行制御の分野。ACID特性、コミット/ロールバック、隔離性レベル、ロック(共有/排他、意向ロック)、MVCC、デッドロック、更新競合、ファントムリードなどを理解し、業務要件に応じて整合性と性能のバランスを取る。試験では、現象(不整合や待ち)の原因特定、隔離レベルやロック設計の選択、再試行・タイムアウトなどアプリ側対策も含めた説明が問われる。
出題の焦点
- ACIDとトランザクション境界の設計
- 隔離レベルと発生し得る現象(幻影等)
- ロック方式(S/X、ロック粒度、階層)
- MVCCの考え方と利点・注意点
- デッドロックの検出・回避・対処
- 整合性とスループットのトレードオフ
問題 ― 令和2年午前2 問4
DBMSが取得するログに関する記述として適切なものはどれか。
- ア:トランザクションの取消しに備えて、データベースの更新されたページに対する更新後情報を取得する。
- イ:媒体障害からの復旧に備えて、データベースの更新されたページに対する更新前情報を取得する。
- ウ:ロールバック後のトランザクション再実行に備えて、データベースの更新されたページに対する更新後情報を取得する。
- エ:ロールフォワードに備えて、データベースの更新されたページに対する更新後情報を取得する。
正解と解説
正解:エ
- 結論:DBMSはロールフォワード復旧のために更新後情報をログに取得します。
- 根拠:更新後情報は障害発生後の再適用(ロールフォワード)に必要であり、復旧処理の基本です。
- 差がつくポイント:更新前情報はロールバック用、更新後情報はロールフォワード用と区別する理解が重要です。
分散・レプリケーション
このテーマで問われること
複数拠点・複数ノードにまたがるデータ管理を扱う分野。レプリケーション(同期/非同期)、シャーディング、分散トランザクション、二相コミット、整合性モデル(強整合/結果整合)、障害時のフェイルオーバ/フェイルバック、遅延や競合解決などを理解する。試験では、可用性・性能・運用負荷の観点から構成を選び、障害シナリオでのデータ不整合や復旧手順を説明できることが重要。ネットワーク分断や遅延を前提にした設計判断も問われる。
出題の焦点
- 同期/非同期レプリケーションの違いと用途
- 分散トランザクション(二相コミット)の要点
- シャーディング設計(キー選定、再配置)
- 整合性モデル(強整合/結果整合)の理解
- フェイルオーバ時の復旧と整合性確保
- 競合解決(マルチマスタ等)の基本
問題 ― 令和1年午前2 問17
分散型データベースで結合演算を行うとき、通信負荷を最も小さくすることができる手法はどれか。ここで、データベースは異なるコンピュータ上に格納されかつ結合演算を行う表の行数が、双方で大きく異ならないものとする。
- ア:入れ子ループ法
- イ:インデックスジョイン法
- ウ:セミジョイン法
- エ:マージジョイン法
正解と解説
正解:ウ
- 結論:分散型データベースの結合演算で通信負荷を最小化するにはセミジョイン法が最適です。
- 根拠:セミジョイン法は必要な結合キーのみを相手ノードに送信し、不要なデータ転送を削減します。
- 差がつくポイント:結合対象の表の行数が大きく異ならず、通信コストがボトルネックになる場合にセミジョイン法の効果が顕著です。
RDBMS選定・クラウド/NoSQL
このテーマで問われること
業務要件に適したDB基盤を選定し、導入・移行までの意思決定を行う分野。RDBMS製品の機能差(可用性、バックアップ、暗号化、パーティション、監視)、ライセンスやサポート、運用体制、性能検証の進め方を踏まえ、オンプレ/クラウド(マネージドDB)/NoSQLの適用可否を比較する。試験では、要求(RPO/RTO、ピーク負荷、拡張、コスト、運用責任分界)に対し、選定理由を論理的に説明する力が問われる。
出題の焦点
- 要件(RPO/RTO、性能、拡張性)と製品機能の対応付け
- クラウドの責任分界と運用設計への影響
- コスト評価(初期/運用、ライセンス)の観点
- PoC/ベンチマークの設計と評価指標
- RDBMSとNoSQLの適材適所(整合性/検索要件)
- 導入時のリスク(互換性、ロックイン、移行性)
問題 ― 令和3年午前2 問17
W3Cで勧告されているIndexed Database APIに関する記述として適切なものはどれか。
- ア:Javaのアプリケーションプログラムからデータベースにアクセスするための標準的なAPIが定義されている。
- イ:SQL文をホストプログラムに埋め込むためのAPIが定義されている。
- ウ:Webブラウザ用のストレージの機能としてトランザクション処理のAPIが定義されている。
- エ:データベースに対する一連の手続きをDBMSに格納し呼び出すAPIが定義されている。
正解と解説
正解:ウ
- 結論:Indexed Database APIはWebブラウザ上でトランザクション処理を可能にするストレージAPIである。
- 根拠:W3Cが勧告している仕様で、クライアントサイドの大容量データ管理と整合性確保を目的としている。
- 差がつくポイント:JavaやSQLのAPIではなく、ブラウザ内での非リレーショナルデータ管理に特化している点を理解すること。
セキュリティ・監査
このテーマで問われること
データベースを保護し、証跡を残して統制を効かせる分野。認証・認可(最小権限、ロール設計)、権限分離、機密データの暗号化(保存/通信)、マスキング、SQLインジェクション等の脅威、監査ログの取得と保全、改ざん検知、特権ID管理を体系的に扱う。試験では、求められるセキュリティレベルに応じて対策を選び、監査可能性(誰がいつ何をしたか)を満たす設計・運用を説明できることが問われる。
出題の焦点
- 最小権限とロール/権限設計
- 暗号化(保存・通信)と鍵管理の基本
- 監査ログ(取得・保全・検索)の要点
- 特権IDの統制(分離、申請承認、証跡)
- 代表的脅威(SQLi等)と防御策
- 個人情報等の保護(マスキング、アクセス制御)
問題 ― 令和4年午前2 問19
NISTが制定した、AESにおける鍵長の条件はどれか。
- ア:128ビット、192ビット、256ビットから選択する。
- イ:256ビット未満で任意に指定する。
- ウ:暗号化処理単位のブロック長よりも32ビット長くする。
- エ:暗号化処理単位のブロック長よりも32ビット短くする。
正解と解説
正解:ア
- 結論:AESの鍵長は128ビット、192ビット、256ビットの3種類から選択することがNISTで定められています。
- 根拠:NISTのFIPS 197標準でAESの仕様が規定されており、鍵長はこの3種類に限定されています。
- 差がつくポイント:鍵長の選択肢が固定されている点と、ブロック長(128ビット)とは別に定義されていることを理解することが重要です。
運用・監視・容量管理
このテーマで問われること
安定稼働を継続するための運用設計と日常管理を扱う分野。バックアップ/リストア、障害対応、監視(死活・性能・ログ・ストレージ)、容量計画、ユーザ・権限・構成管理、変更管理、定期メンテナンス(統計更新、再編成)などを一連の運用プロセスとして整理する。利用者サポートでは、問い合わせ対応や性能相談、データ取扱いルール周知などを通じて運用品質を高める。試験では、手順の妥当性、優先度判断、運用上のリスク低減策が問われる。
出題の焦点
- バックアップ方式とリストア手順(RPO/RTO)
- 監視設計(指標、しきい値、アラート)
- 容量見積りと拡張計画(データ/ログ/索引)
- 変更・構成管理(手順化、権限、承認)
- 定期メンテナンス(統計、再編成)の目的
- 利用者サポート(問い合わせ/教育/ルール整備)
問題 ― 令和1年午前2 問23
Webシステムの負荷分散技術の一つである、ロードバランサ方式の特徴として、最も適切なものはどれか。
- ア:Webブラウザのキャッシュ機能によって負荷が均等に分散しない場合がある。
- イ:接続されたサーバの死活状態をロードバランサは考慮せずに選択する。
- ウ:複数のサーバそれぞれにグローバルIPアドレスの固定割当てが必要になる。
- エ:ヘルスチェックに失敗しているサーバをロードバランサは選択しない。
正解と解説
正解:エ
- 結論:ロードバランサはヘルスチェックに失敗したサーバを選択しないことで、システムの安定性を確保します。
- 根拠:ヘルスチェック機能によりサーバの死活状態を監視し、障害サーバを除外する仕組みが一般的です。
- 差がつくポイント:死活監視の有無やIPアドレスの割当て方法など、ロードバランサの基本機能を正確に理解することが重要です。
テスト・移行
このテーマで問われること
新規構築や更改で品質と継続性を担保するためのテスト・移行分野。移行方式(リフト、段階移行、並行稼働、切替)を選び、移行対象データの抽出・変換・ロード、整合性確認、リハーサル、切戻し計画を立てる。テストでは、機能・結合に加え、性能・負荷・可用性・回復(バックアップ復元)まで検証し、受入条件を明確化する。試験では、移行リスク(欠損・重複・停止時間)への対策と、確認観点の漏れの指摘が問われる。
出題の焦点
- 移行方式の選択(段階/一括/並行稼働)
- ETL(抽出・変換・ロード)設計と検証
- データ整合性確認(件数、参照整合、突合)
- 移行リハーサルと切替手順・切戻し
- 性能/負荷/回復テストの観点
- 受入基準と判定指標の設定
問題 ― 令和6年午前2 問25
エクストリームプログラミング(XP:ExtremeProgramming)における“テスト駆動開発”の特徴はどれか。
- ア:最初のテストで、なるべく多くのバグを摘出する。
- イ:テストケースの改善を繰り返す。
- ウ:テストでのカバレージを高めることを目的とする。
- エ:プログラムコードを書く前にテストコードを書く。
正解と解説
正解:エ
- 結論:テスト駆動開発(TDD)は「プログラムコードを書く前にテストコードを書く」ことが特徴です。
- 根拠:XPの基本プラクティスであり、コードの品質向上と設計の明確化に寄与します。
- 差がつくポイント:テストを後から追加するのではなく、先にテストを書く点が他のテスト手法と異なります。
横断・複合領域
このテーマで問われること
単一テーマに閉じず、設計・実装・運用をまたいで最適解を導く分野。たとえば、要件(性能・可用性・セキュリティ)を概念/論理/物理へ一貫して落とし込み、SQL・索引・パーティション・運用手順を組み合わせて達成する力が求められる。障害や性能劣化の事象から原因を仮説立てし、ログ・実行計画・監視指標を横断的に用いて切り分けることも重要。試験では、制約条件下のトレードオフ説明と、実務的な判断根拠の提示が問われる。
出題の焦点
- 要件→設計(概念/論理/物理)への一貫性
- 性能・可用性・セキュリティのトレードオフ
- 障害/性能問題の横断的切り分け手順
- 設計変更の影響範囲(SQL/索引/運用)の把握
- 運用制約を踏まえた実装・設計判断
- 複数施策の組合せによる最適化
問題 ― 令和3年午前2 問25
マッシュアップの説明はどれか。
- ア:既存のプログラムからそのプログラムの仕様を導き出す。
- イ:既存のプログラムを部品化しそれらの部品を組み合わせて新規プログラムを開発する。
- ウ:クラスライブラリを利用して新規プログラムを開発する。
- エ:公開されている複数のサービスを利用して新たなサービスを提供する。
正解と解説
正解:エ
- 結論:マッシュアップとは複数の公開サービスを組み合わせて新たなサービスを作る手法です。
- 根拠:Web APIなどの公開サービスを活用し、異なる機能やデータを融合させる点が特徴です。
- 差がつくポイント:単なるプログラムの部品化やクラスライブラリ利用ではなく、異なるサービスの連携に注目しましょう。
攻略ポイント・学習アドバイス
- シラバス大項目をマッピングした学習計画を立て、過去問と照合しながら弱点を可視化する。
- 午後Ⅰは「正規化・インデックス設計・障害復旧・性能改善」など頻出テーマで答案テンプレを作り、設問パターンごとに時間配分を訓練。
- 午後Ⅱ(科目B-2)は論述式ではなく、長大な事例文を読み解く記述式。概念データモデル作成・物理設計・性能改善など出題テーマごとに解法手順を整理し、120分で設問要求に沿って解き切る演習を繰り返す。
- クラウド DB/分散 DB/NoSQL の比較評価や生成 AI の活用等、Ver.4.1 追加トピックを整理し、最新動向を事例で説明できるようにする。
- ベンチマーク結果の読み取り・資源見積り・チューニング手順は実機やクラウド・ラボ環境で体験し、数値根拠を示せるよう準備する。
関連リンク
データベーススペシャリスト試験の難易度・合格率の推移
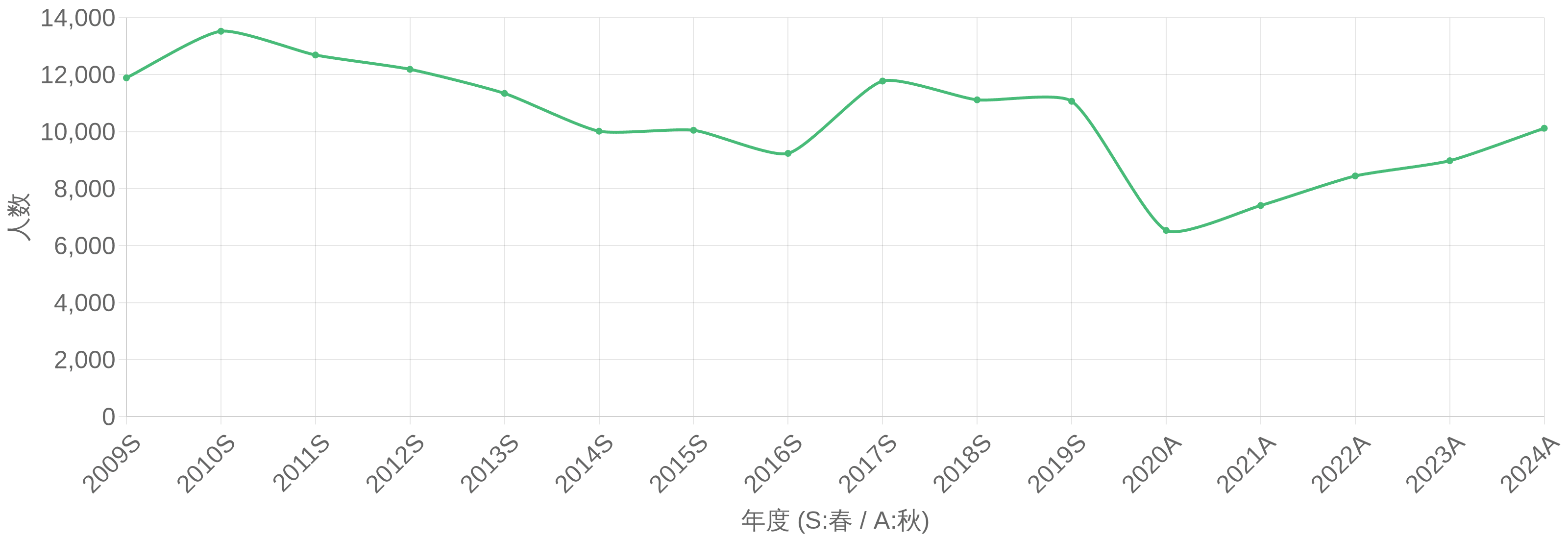
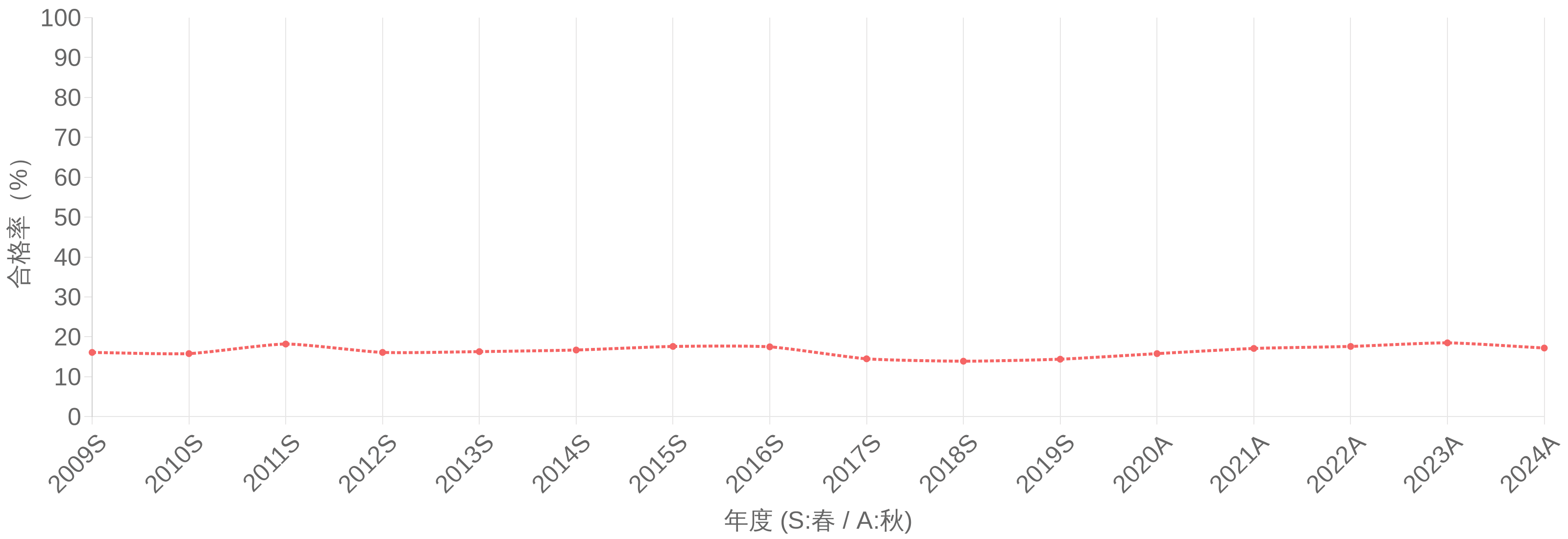
以下は年度ごとの受験者数・合格者数・合格率・合格者平均年齢の推移データです。合格率の傾向を把握し、学習計画の目安にしてください。
年度別 統計データ(表形式)
各年度ごとの合格率・平均年齢・合格者数などの推移です。
※ 表は横にスクロールできます
| 年度 | 受験申込者数(人) | 受験者数(人) | 合格者数(人) | 合格率(%) | 合格者平均年齢(才) |
|---|---|---|---|---|---|
| 2009 春期 | 18538 | 11887 | 1912 | 16.1 | 30.6 |
| 2010 春期 | 20529 | 13523 | 2142 | 15.8 | 31.8 |
| 2011 春期 | 20207 | 12689 | 2304 | 18.2 | 31.4 |
| 2012 春期 | 18799 | 12187 | 1963 | 16.1 | 31.8 |
| 2013 春期 | 17489 | 11342 | 1845 | 16.3 | 31.8 |
| 2014 春期 | 15807 | 10016 | 1671 | 16.7 | 32.4 |
| 2015 春期 | 15355 | 10049 | 1767 | 17.6 | 31.9 |
| 2016 春期 | 13980 | 9238 | 1620 | 17.5 | 32.4 |
| 2017 春期 | 17706 | 11775 | 1709 | 14.5 | 31.5 |
| 2018 春期 | 17165 | 11116 | 1548 | 13.9 | 31.9 |
| 2019 春期 | 16831 | 11066 | 1591 | 14.4 | 31.3 |
| 2020 秋期 | 9468 | 6536 | 1031 | 15.8 | 30.9 |
| 2021 秋期 | 10648 | 7409 | 1269 | 17.1 | 30.4 |
| 2022 秋期 | 12399 | 8445 | 1486 | 17.6 | 31.0 |
| 2023 秋期 | 13121 | 8980 | 1664 | 18.5 | 30.8 |
| 2024 秋期 | 14549 | 10120 | 1744 | 17.2 | 30.9 |
年度別 統計推移グラフ
各年度ごとの合格者数・受験者数・合格率・平均年齢の推移
合格者数
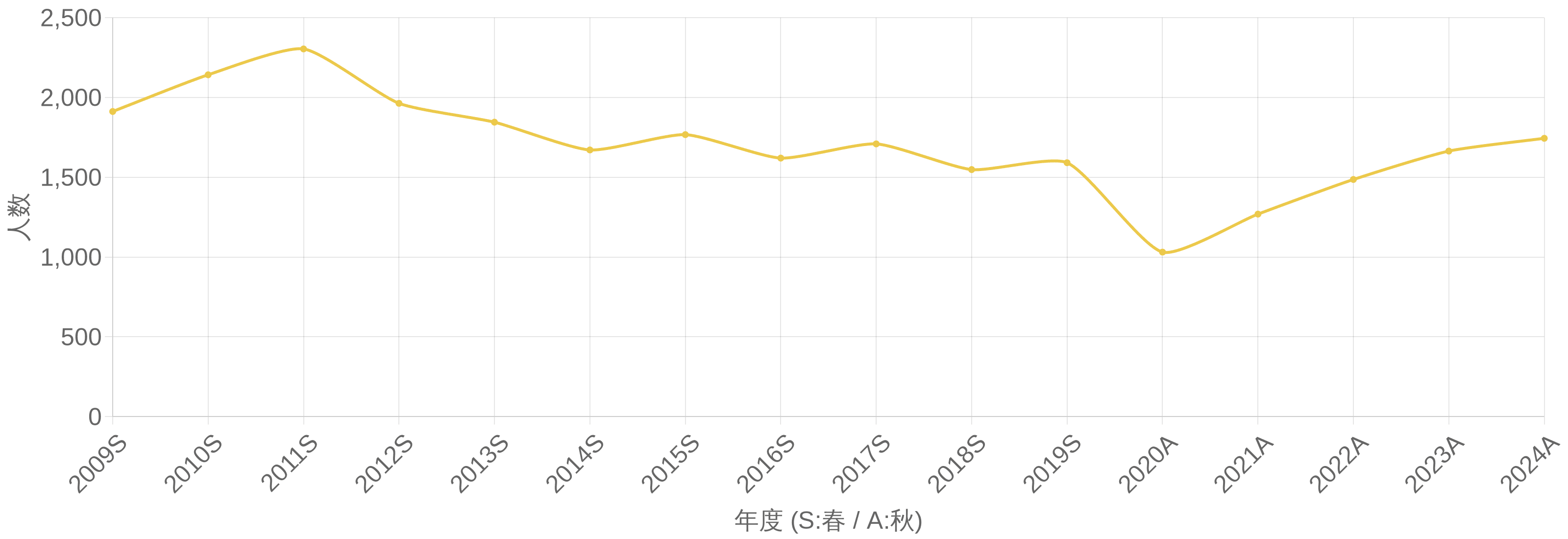
受験者数
合格率(%)
合格者平均年齢