データベーススペシャリスト 2013年 午後1 問03
SQL の設計及び性能に関する次の記述を読んで、設問1〜3に答えよ。
全国の法人及び個人に事務用品をインターネット販売しているE社は、RDBMS を用いた注文システムを運用している。 注文システムの運用は、情報システム部のFさんが担当している。
〔RDBMS のアクセス経路に関する主な仕様〕
1.SQL 文の実行ごとに、アクセス経路が決められる。
2.各テーブルの定義情報、及び統計更新処理が収集する統計情報、例えば、各テーブルの行数及び列値の個数は、システムカタログに記録される。
3.各テーブルの列値の個数は、統計更新処理時点の各列に存在する異なる値の個数である。
4.アクセス経路は、各テーブルの統計情報及び索引定義情報に基づき、RDBMS のオプティマイザによって表探索又は索引探索のいずれかに決められる。
5.表探索は、索引を使わずに先頭のデータページから全行を探索する。索引探索は,WHERE 句中の述語に適した索引によって行を絞り込んでから、データページ中の行を探索する。 SQL文の実行によって取得される行を、結果行と呼ぶ。
6.索引探索に使われる索引は、1テーブル当たり1個である。 索引探索に使える列は索引キーを構成する先頭の列として定義され、かつ、述語の比較演算子は=、<、>、<=、>= のいずれかでなければならない。
7.オプティマイザは、アクセス経路を決めるとき、次のように仮定している。
(1) 統計情報は、テーブルの最新状態を反映したものである。
(2) 列値当たりの行数は均等である。
(3) 行数がゼロの場合、表探索が最適である。
〔販売商品の概要〕
販売する商品は、主にオフィス又は家庭で使用される事務用品である。 販売する商品は、2階層のカテゴリによって分類される。 カテゴリの例を次に示す。
(1) カテゴリ1は、筆記具、用紙などの大分類(100 種類)を表す。
(2) カテゴリ1が筆記具の場合、カテゴリ2は鉛筆、ボールペンなどである。
〔テーブルの構造〕
注文処理に使用する主なテーブルの構造を図1に、主な列の意味を表1に示す。


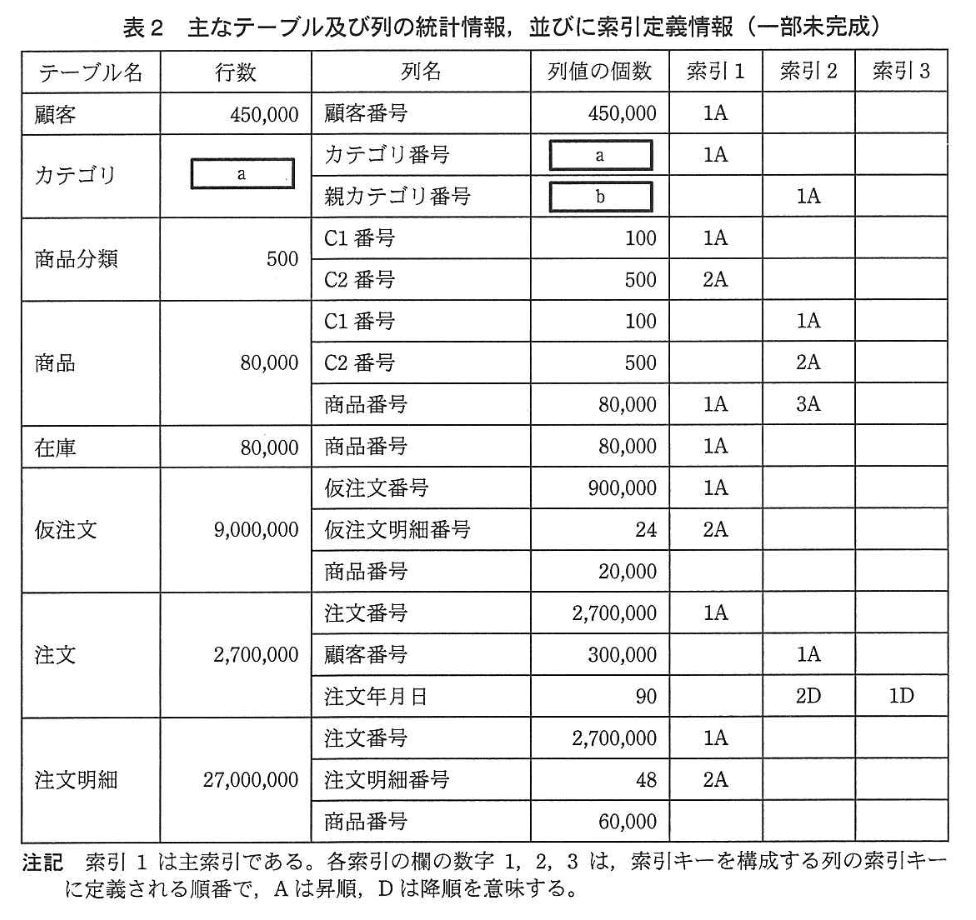
現在、“仮注文” テーブルのデータ保存期間を1か月間、また“注文” テーブル及び“注文明細”テーブルのデータ保存期間を 3 か月間として、毎月の末日に統計更新処理を行い、その後に不要な行を削除する削除処理を行っている。 2013年3月末日に統計更新処理を行ったときにシステムカタログに記録された主なテーブル及び列の統計情報、並びに索引定義情報を、表2に示す。
〔注文処理の概要〕
1.注文システムによる処理
注文システムは、24時間オンライン稼働している。 注文システムによる処理の概要は、次のとおりである。
なお、文中の(SQL1)、(SQL6)、(SQL7)は、表3のSQL1, SQL6, SQL7 がそれぞれ実行されることを示す。
(1) 商品照会
① 顧客は、インターネットから注文処理を呼び出し、メニューを表示させる。
② 顧客は、メニューから商品照会を選んで、商品のカテゴリ1 のカテゴリ名の一覧を表示させ、そのうちの一つを検索条件として選択する。
③ 注文システムは、検索条件に合致する商品の情報 (商品名、定価、販売価格、割引率、商品画像など)を“商品” テーブルから取得し (SQL1)、商品一覧画面に最大 10 商品を表示する。
④ 顧客が次画面ボタンをクリックすると、次の10商品が表示される。
(2) 仮注文入力
① 顧客は、商品一覧画面の1個又は複数個の商品に注文数を入力する。
② 注文システムは、“在庫” テーブルを調べ、引当可能な商品ならば、“仮注文”テーブルに1行を追加する。 注文システムは、1 画面の処理ごとにCOMMIT文を発行する。
③ 顧客は、仮注文入力を終えると、発送・支払に必要な顧客名、発送先住所などの情報を入力し、注文内容を注文確認画面で確認してから注文確定ボタンをクリックする。
④ 仮注文入力が注文確定とならなかった場合、注文システムは注文処理を終了させて、“仮注文” テーブルから該当行を削除し、COMMIT文を発行する。
(3) 注文確定
① 仮注文入力が注文確定となったとき、注文システムは、“注文” テーブルに 1行を追加する。 “仮注文” テーブルから主キー順に1行ずつ取得しながら(SQL6)、注文確定の列に‘Y'を設定し、かつ、商品ごとに“在庫” テーブルの引当可能数の列を更新し (SQL7)、“注文明細” テーブルに1行を追加する。これを商品数だけ繰り返し、最後に COMMIT 文を発行する (在庫引当ができなかった場合の処理については、省略)。
②その後、注文の支払が完了したとき、該当する “注文” テーブルの行の支払済の列に‘Y'を設定する。
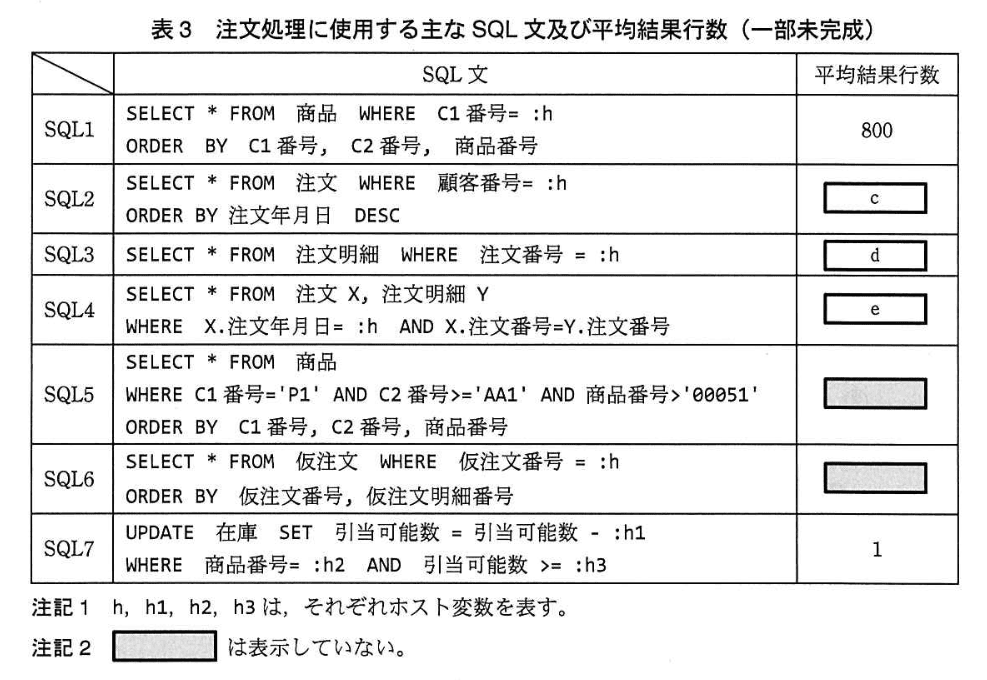
2.注文処理に使用する主な SQL 文
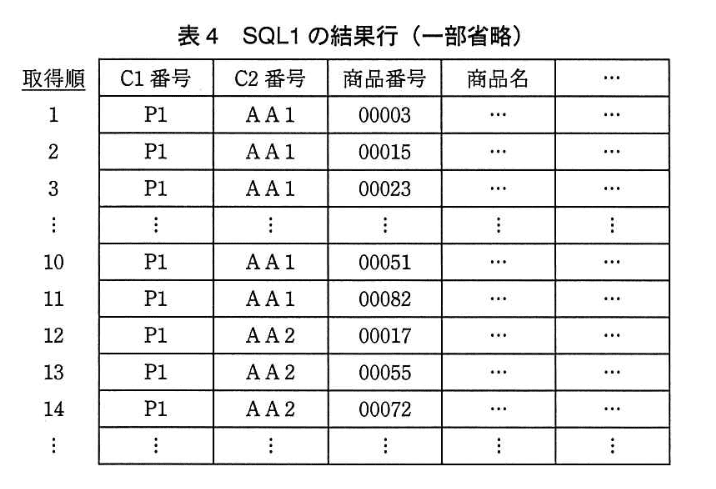
注文処理に使用する主な SQL文を、表3に示す。 表3の平均結果行数は、表2の統計情報とオプティマイザの仮定に基づいて計算される推定行数である。また、表3 の SQL1 のホスト変数に ‘P1' を指定した場合の SQL1 の結果行を、表4 に示す。
〔テーブルの保守の見直し〕
Fさんは、毎月の末日に行っていたテーブルの保守を、次のように日次処理として見直すことにした。
なお、行の削除には DELETE文を用いる 。
(1) 注文の少ない毎朝4時から4時30分までの間、仕掛り中の注文処理を終わらせ、仕掛り中の注文処理がないことを確認した後、注文処理を一時的に停止する。
(2) “仮注文”テーブルの不要な行(注文確定の列が ‘Y' の行) を削除する。
(3) “注文”テーブルの不要な行(保存期間を超過し、かつ、支払済の列が‘Y'の行)、及び“注文明細” テーブルの不要な行を削除する。
(4) (2) 、(3) の処理を行った後、テーブルを再編成し、次に統計更新処理を行う。
(5) 注文処理を再開する。
〔問題点の指摘〕
Fさんの上司である G氏は、注文処理とテーブルの保守の見直しについて、次の問題点を指摘した。
① 商品一覧画面の表示では、SQL1 を実行したときの平均結果行数が多い。 全結果行を取得してから表示するのではなく、1 画面(10行) 分を取得して、表示した方がよい。 ただし、次の1 画面分を取得するとき、最初から取得し直さないようにすべきである。
② Fさんによる〔テーブルの保守の見直し〕では、アクセス経路が索引探索から表探索に変わる SQL がある。 その結果、注文確定の際に、その SQL を実行するたびに処理時間が長くなることが懸念される。
設問1:表2及び表3について、(1)〜(3)に答えよ。
(1)
表 2 の“商品分類” テーブルの統計情報を基に、表 2 中の(a)、(b)に入れる適切な数値を答えよ。
模範解答
a:600
b:100
解説
解答の論理構成
- 表示された統計情報を確認
表2より
• “商品分類” の行数は 500
• “C1番号” の列値の個数は 100
• “C2番号” の列値の個数は 500 - カテゴリ数の読み替え
〔販売商品の概要〕には「カテゴリ1は … (100 種類)」と明示され、表2の “C1番号 100” と一致する。
よって
• カテゴリ1 = 100種類
• カテゴリ2 = 500種類 - “カテゴリ” テーブルの構造
問題文より “カテゴリ” テーブルにはカテゴリ1とカテゴリ2の両方が格納される(カテゴリ1行では親カテゴリ番号がNULL)。したがって
行数(=カテゴリ番号の列値の個数)=カテゴリ1+カテゴリ2
→ (a) = 600 - 親カテゴリ番号の列値個数
親カテゴリ番号が入るのはカテゴリ2行のみ。親はカテゴリ1の番号なので distinct 値はカテゴリ1の種類数と同じ
→ (b) = 100
誤りやすいポイント
- “商品分類” の行数 500 をそのまま (a) と誤記する
- 親カテゴリ番号に NULL が含まれるかどうかを見落とし、(b) を 101 などにしてしまう
- “C2番号 500” を (b) に入れてしまう(親と子を取り違え)
FAQ
Q: なぜ “商品分類” の行数がカテゴリ2の種類数と決めつけられるのですか?
A: 表2で “C2番号” の列値個数が行数と同じ 500 であり、1行に1つのカテゴリ2が対応していることが分かるためです。
A: 表2で “C2番号” の列値個数が行数と同じ 500 であり、1行に1つのカテゴリ2が対応していることが分かるためです。
Q: 親カテゴリ番号が NULL の行は distinct 個数にカウントされますか?
A: NULL は「値が不明」扱いで distinct 個数には含まれません。したがってカテゴリ1分の 100 だけが distinct になります。
A: NULL は「値が不明」扱いで distinct 個数には含まれません。したがってカテゴリ1分の 100 だけが distinct になります。
Q: 行数と列値個数が同じでも索引があるとは限らないのですか?
A: はい。表2では索引欄に “1A” がある場合のみ主キー索引が明示されており、行数=列値個数は一意性を示す統計情報です。
A: はい。表2では索引欄に “1A” がある場合のみ主キー索引が明示されており、行数=列値個数は一意性を示す統計情報です。
関連キーワード: 正規化、統計情報、オプティマイザ、親子関係
設問1:表2及び表3について、(1)〜(3)に答えよ。
(2)
表2の統計情報を基に、表3中の(c)〜(e)に入れる適切な数値を答えよ。
模範解答
c:9
d:10
e:300,000
解説
解答の論理構成
- オプティマイザの仮定
問題文に「(2)列値当たりの行数は均等である。」とあるため、平均値は
総行数 ÷ 列値個数 で求められる。 - (c) の算出
SQL2 は 「SELECT * FROM 注文 WHERE 顧客番号 = :h」。
注文テーブル行数は 2,700,000、顧客番号の列値個数は 300,000。
よって 2,700,000 ÷ 300,000 = 9。 - (d) の算出
SQL3 は 「SELECT * FROM 注文明細 WHERE 注文番号 = :h」。
注文明細テーブル行数は 27,000,000、注文番号の列値個数は 2,700,000。
よって 27,000,000 ÷ 2,700,000 = 10。 - (e) の算出
SQL4 は 「SELECT * FROM 注文 X, 注文明細 Y WHERE X.注文年月日 = :h AND X.注文番号 = Y.注文番号」。
① 注文テーブルにおける 注文年月日 列値個数は 90。
2,700,000 ÷ 90 = 30,000 … 指定日付の注文行数
② 1件の注文に対する注文明細は平均 10 行(上記 (d))。
③ 結合後の行数は 30,000 × 10 = 300,000。
誤りやすいポイント
- 注文年月日の列値個数 90 の読み落としにより、(e) を 30,000 と誤答しがちです。
- (d) の分母を列値個数ではなくテーブル行数で割って 0.1 としてしまう計算ミス。
- オプティマイザの仮定「均等分布」を忘れ、実際の偏りを想像して平均でない数字を書くケース。
FAQ
Q: 実システムでは行分布が偏ることが多いですが、試験ではなぜ均等分布で計算するのですか?
A: 問題文に「列値当たりの行数は均等である」とオプティマイザの仮定が明示されており、それに基づいて平均結果行数を算出する設計になっているためです。
A: 問題文に「列値当たりの行数は均等である」とオプティマイザの仮定が明示されており、それに基づいて平均結果行数を算出する設計になっているためです。
Q: SQL4 の結果行数は結合順序や索引有無で変わりますか?
A: アクセス経路が変わっても、平均結果行数は論理的に導かれる行数に依存します。計算はテーブル統計と均等分布の仮定だけで決まるため、索引の有無は影響しません。
A: アクセス経路が変わっても、平均結果行数は論理的に導かれる行数に依存します。計算はテーブル統計と均等分布の仮定だけで決まるため、索引の有無は影響しません。
Q: 他の列でフィルタする場合も同じ計算方法ですか?
A: はい。列の値個数が分かれば「対象列の値個数で割る → 行数を求める」を基本にして平均結果行数を算出できます。
A: はい。列の値個数が分かれば「対象列の値個数で割る → 行数を求める」を基本にして平均結果行数を算出できます。
関連キーワード: 統計情報、均等分布仮定、オプティマイザ、平均結果行数、結合行数
設問1:表2及び表3について、(1)〜(3)に答えよ。
(3)
表2の統計情報を基に、“注文明細” テーブルについて、一つの注文で発生した最大明細行数を答えよ。
模範解答
最大 48行
解説
解答の論理構成
- 表2から事実を抜き出す。
- “注文明細”–“注文明細番号” の「列値の個数」は “48” である。
- 表1で列の性質を確認する。
- “注文明細番号” は「一つの注文の中で、商品ごとの注文を一意に識別する番号。1から付与する。」
- 以上より “注文明細番号” は 1 注文につき 1〜N の連番を取り、「列値の個数」48 はその連番の取り得る最大値=1 注文当たりの最大行数を示す。
- 従って求める最大明細行数は 48 行 となる。
誤りやすいポイント
- 「列値の個数」がテーブル全体の distinct 値だと早合点し、注文単位の上限と結び付けられない。
- 行数 27,000,000 と混同し、平均や最大を誤って算出する。
- “注文明細番号” ではなく “注文番号” の列値個数 2,700,000 を見てしまう。
FAQ
Q: 「列値の個数」は常にテーブル全体の distinct 値ですか?
A: 表2の定義は「統計更新処理時点の各列に存在する異なる値の個数」です。ただし業務ルールで列の取り得る値域が限定される場合、その値が意味的に上限を示すことがあります。本設問はその代表例です。
A: 表2の定義は「統計更新処理時点の各列に存在する異なる値の個数」です。ただし業務ルールで列の取り得る値域が限定される場合、その値が意味的に上限を示すことがあります。本設問はその代表例です。
Q: 実運用で 48 行を超える場合はないのですか?
A: 表1の説明どおり「1 から付与する」連番であり、再利用しない制約は注文明細番号には記載されていませんが、列値の個数 48 が統計情報として得られているため、少なくとも統計更新時点では 48 が上限です。業務変更で列値が増えれば統計情報も更新されます。
A: 表1の説明どおり「1 から付与する」連番であり、再利用しない制約は注文明細番号には記載されていませんが、列値の個数 48 が統計情報として得られているため、少なくとも統計更新時点では 48 が上限です。業務変更で列値が増えれば統計情報も更新されます。
Q: 行数 27,000,000 と最大 48 行はどのように関連しますか?
A: 27,000,000 はテーブル全体の行数、48 は 1 注文(“注文番号”)に属する最大行数です。総行数 ÷ 最大行数 ≒ 最大注文件数を粗く見積もる指標にもなります。
A: 27,000,000 はテーブル全体の行数、48 は 1 注文(“注文番号”)に属する最大行数です。総行数 ÷ 最大行数 ≒ 最大注文件数を粗く見積もる指標にもなります。
関連キーワード: 統計情報、列値個数、連番、主キー、データ設計
設問2:〔問題点の指摘〕 の ①への対応について(1)、(2)に答えよ。
(1)
Fさんが表4の取得順で示した 11行目以降を取得するために表3のSQL5を実行したところ、最初の3行の取得順は次のようになった。この取得順で示し、2,3行目の(ア)、(イ)に入れる適切な字句を答えよ。
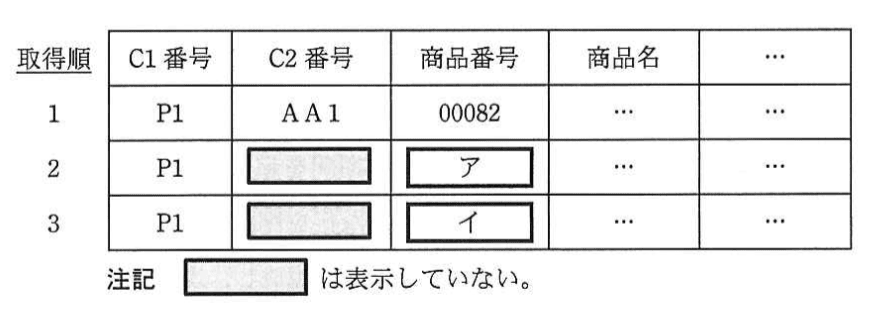
模範解答
ア:00055
イ:00072
解説
解答の論理構成
-
「表4」の10行目は P1, AA1, 00051 である。
-
「表3 SQL5」は
sql WHERE C1番号 > 'P1' AND C2番号 > 'AA1' AND 商品番号 > '00051' ORDER BY C1番号、C2番号、商品番号を実行するため、F さんが取得した結果も同じ並び順(C1→C2→商品番号の昇順)で返る。 -
10行目より後の並びを「表4」から列挙すると
- 11行目 P1, AA1, 00082
- 12行目 P1, AA2, 00017
- 13行目 P1, AA2, 00055
- 14行目 P1, AA2, 00072
-
このうち最初の3件が設問の図に示された取得順
- 1行目 P1, AA1, 00082(すでに図に記載)
- 2行目 P1, AA2, 00055
- 3行目 P1, AA2, 00072
-
よって (ア)=00055、(イ)=00072 となる。
誤りやすいポイント
- ORDER BY の先頭列が同じときは2列目、さらに同じなら3列目で比較されることを見落とす。
- 「前ページの最後のキー3列よりすべて大きい」という条件を AND で書くと、実際には1列目が同値の行が除外されるため正しくページングできない。
- 文字列比較で 'P1' > 'P1' は偽になる点を忘れ、結果が合わないと混乱する。
FAQ
Q: なぜ3列とも > を使うとページングが失敗するのですか?
A: 3列すべてが前行より“大きい”行だけを選ぶと、1列目が同じ (C1番号 = 'P1') 行が除外されます。本設問のように11行目以降も P1 が続くケースでは取り漏れが起きます。
A: 3列すべてが前行より“大きい”行だけを選ぶと、1列目が同じ (C1番号 = 'P1') 行が除外されます。本設問のように11行目以降も P1 が続くケースでは取り漏れが起きます。
Q: 正しく次ページを取得する書き方はありますか?
A: 典型例は組合せ比較—WHERE (C1番号、C2番号、商品番号) > ('P1'、'AA1'、'00051')—または C1番号 > 'P1' OR (C1番号 = 'P1' AND (C2番号 > 'AA1' OR (C2番号 = 'AA1' AND 商品番号 > '00051'))) のように OR と括弧で条件を分解します。
A: 典型例は組合せ比較—WHERE (C1番号、C2番号、商品番号) > ('P1'、'AA1'、'00051')—または C1番号 > 'P1' OR (C1番号 = 'P1' AND (C2番号 > 'AA1' OR (C2番号 = 'AA1' AND 商品番号 > '00051'))) のように OR と括弧で条件を分解します。
Q: インデックスが (C1番号、C2番号、商品番号) であれば、この並び順は高速に取得できますか?
A: はい。先頭列から順に比較していく索引木を1回の範囲検索で済ませられるため、高速にページングできます。
A: はい。先頭列から順に比較していく索引木を1回の範囲検索で済ませられるため、高速にページングできます。
関連キーワード: ページング、複合索引、比較演算子、ソート順列、範囲検索
設問2:〔問題点の指摘〕 の ①への対応について(1)、(2)に答えよ。
(2)
(1)の結果は F さんの目的とは異なるので,SQL5 を 1 画面目の情報を使って、次のように修正した。(ウ)~(オ)に入れる適切な字句を答えよ。
なお、(ウ)~(オ)に入れる述語はそれぞれ一つとする。(ウ、エは順不同)
SELECT * FROM 商品 WHERE C1番号='P1' AND
( ( (ウ) AND (エ) ) OR (オ) )
ORDER BY C1番号、C2番号、商品番号
模範解答
ウ:C2番号 = 'AA1'
エ:商品番号 > '00051'
オ:C2番号 > 'AA1'
解説
解答の論理構成
- 【問題文】表4の 10 行目は
C1番号 P1 / C2番号 AA1 / 商品番号 00051。 - ORDER BY は【問題文】「ORDER BY C1番号、C2番号、商品番号」である。したがって辞書順で
(P1, AA1, 00051) より後ろの行を次画面とする。 - 辞書順で後ろになるケースは3つ。
① C1番号 が同じで C2番号 も同じ、かつ 商品番号 が大きい。
② C1番号 が同じで C2番号 が大きい(商品番号は任意)。
③ C1番号 が大きい(以下の列は任意)。今回は WHERE 句の先頭で C1番号='P1' と固定したので③は不要。 - ①を SQL にすると (C2番号='AA1' AND 商品番号>'00051')。
②を SQL にすると C2番号>'AA1'。 - よって ((C2番号='AA1' AND 商品番号>'00051') OR C2番号>'AA1') が必要条件であり、 (ウ) C2番号='AA1'、(エ) 商品番号>'00051'、(オ) C2番号>'AA1' となる。
- (ウ) と (エ) の順序は AND で結合されるため入れ替えても意味は変わらない。
- 以上より修正後 SQL は
sql SELECT * FROM 商品 WHERE C1番号='P1' AND ((C2番号='AA1' AND 商品番号>'00051') OR C2番号>'AA1') ORDER BY C1番号、C2番号、商品番号;
誤りやすいポイント
- C1番号>'P1' を使うと C1番号='P1' の商品が全て除外され、正しくページングできない。
- (C2番号='AA1' OR C2番号>'AA1') と書くと 1 画面目の重複行(商品番号='00051' 以下)が再取得される。
- ORDER BY の列順と WHERE 句の条件順を混同し、末尾列の範囲指定だけで済むと誤解しやすい。
FAQ
Q: 3列まとめて「>」を使う書き方はできますか?
A: 標準 SQL では複合列を直接比較する構文はありません。列ごとに条件を分解し、OR で組み合わせる必要があります。
A: 標準 SQL では複合列を直接比較する構文はありません。列ごとに条件を分解し、OR で組み合わせる必要があります。
Q: C1番号 も文字列ですが、辞書順は保証されますか?
A: 文字列型でも ORDER BY と > 比較演算子は同一の照合順序を使います。表4の並びがそのまま比較結果と一致します。
A: 文字列型でも ORDER BY と > 比較演算子は同一の照合順序を使います。表4の並びがそのまま比較結果と一致します。
Q: (ウ) と (エ) の順序で実行計画は変わりますか?
A: AND で結ばれた条件は論理的には交換法則が成り立つため結果は同じです。RDBMS のオプティマイザが内部で並べ替えるので性能差も通常は生じません。
A: AND で結ばれた条件は論理的には交換法則が成り立つため結果は同じです。RDBMS のオプティマイザが内部で並べ替えるので性能差も通常は生じません。
関連キーワード: ページング、範囲検索、複合索引、辞書順比較、OR条件
設問3:〔問題点の指摘〕の②への対応について、(1)〜(3)に答えよ。
(1)
アクセス経路が索引探索から表探索に変わる SQL を、表 3 の SQL1〜SQL7の中から一つ答え、アクセス経路が変わる理由を、40字以内で述べよ。
模範解答
SQL:SQL6
理由:
・ “仮注文”テーブルの全行が削除された直後に統計更新処理を行ったから
・ “仮注文”テーブルの統計情報の行数がゼロになるから
解説
解答の論理構成
- 削除対象とタイミング
- 〔テーブルの保守の見直し〕(2)
「“仮注文”テーブルの不要な行(注文確定の列が ‘Y' の行) を削除する。」 - 同(1) で「仕掛り中の注文処理がないことを確認」してから実施しているため、仮注文の残存行は実質 0 行。
- 〔テーブルの保守の見直し〕(2)
- 統計情報の更新
- 同(4)
「…テーブルを再編成し、次に統計更新処理を行う。」 - 仕様 1,2 により統計更新処理の結果がシステムカタログへ登録される。
- 同(4)
- オプティマイザの判断基準
- 仕様 7-(3)
「行数がゼロの場合、表探索が最適である。」
- 仕様 7-(3)
- 対象 SQL の特定
-
SQL6
sql SELECT * FROM 仮注文 WHERE 仮注文番号 = :h ORDER BY 仮注文番号、仮注文明細番号 -
インデックスは表2で “仮注文” の「仮注文番号」に 1A が定義されているが、行数 0 となった時点で表探索に切り替わる。
-
- 以上より、「SQL6 が索引探索から表探索へ変わり、理由は統計更新後に行数 0 となるため」と結論付けられる。
誤りやすいポイント
- インデックスが残っているから索引探索と早合点し、統計情報を無視してしまう。
- 仕様 7-(3) の「行数がゼロの場合…」を見逃し、行数が極端に少ない場合の経路決定を誤解する。
- SQL1 など他の検索系 SQL に目を奪われ、更新系 SQL6 が対象であることに気付かない。
FAQ
Q: 「全行削除されない日もあるのでは?」
A: 仕掛り中の処理がないことを確認してから削除するため、日次バッチ開始時点では “仮注文” に残る行は基本的にありません。残る場合でも行数は極小であり、同じく表探索が選択されやすくなります。
A: 仕掛り中の処理がないことを確認してから削除するため、日次バッチ開始時点では “仮注文” に残る行は基本的にありません。残る場合でも行数は極小であり、同じく表探索が選択されやすくなります。
Q: 統計更新を行わずに削除だけ実施した場合は?
A: システムカタログに旧行数が残るため、オプティマイザは依然として索引探索を選択します。したがって「統計更新を行うこと」が経路変更の直接要因です。
A: システムカタログに旧行数が残るため、オプティマイザは依然として索引探索を選択します。したがって「統計更新を行うこと」が経路変更の直接要因です。
Q: 表探索に変わると何が問題ですか?
A: 注文確定処理は商品数分 SQL6 をループ実行します。表探索になると毎回全ページを読み、I/O が急増してレスポンスが低下します。
A: 注文確定処理は商品数分 SQL6 をループ実行します。表探索になると毎回全ページを読み、I/O が急増してレスポンスが低下します。
関連キーワード: オプティマイザ、統計情報、インデックス、表探索、行数推定
設問3:〔問題点の指摘〕の②への対応について、(1)〜(3)に答えよ。
(2)
(1)で答えた SQL のアクセス経路が表探索に変わった場合、その SQL を実行するたびに処理時間が長くなる理由を、40 字以内で述べよ。
模範解答
・SQL6を実行するたびに表探索によって読み込む行数が増えるから
・ “仮注文”テーブルは蓄積されるので表探索によって読み込む行数が増えるから
解説
解答の論理構成
- 表探索の動作
「表探索は、索引を使わずに先頭のデータページから全行を探索する。」
この仕様により、条件に合致しない行も含めテーブル全体を走査します。 - “仮注文”テーブルの規模
表2より「仮注文 行数 9,000,000」「仮注文番号 列値の個数 900,000」
1 つの「仮注文番号」で平均 10 行しか該当しません。 - SQL6 の検索条件
「SELECT * FROM 仮注文 WHERE 仮注文番号 = :h」
一致比較なので索引探索なら10行程度で済みますが、表探索では 9,000,000 行を読むことになります。 - 行数が増えるにつれ処理時間も増大
保守後も未確定データは追加され続けるためテーブルは再び肥大化し、表探索による I/O 量も比例して増加します。
誤りやすいポイント
- 「表探索でも行数が少なければ速い」と思い込み、行数増加による I/O 量を軽視する。
- 「索引探索は常に最速」と誤認し、オプティマイザが表探索を選択するケース(統計情報の変化など)を想定しない。
- SQL6 の条件列と索引の先頭列が一致する点を見落とし、アクセス経路変更の影響を過小評価する。
FAQ
Q: なぜ統計更新後にオプティマイザが表探索を選ぶことがあるのですか?
A: 行数が統計上“少ない”と判断されると、索引アクセスより全件走査の方が安いと見積もられるためです。
A: 行数が統計上“少ない”と判断されると、索引アクセスより全件走査の方が安いと見積もられるためです。
Q: 索引探索に戻す方法はありますか?
A: 統計情報を正確に保ちつつ、列のカーディナリティやクラスタ化度合いを考慮した索引設計(例えば複合索引)を行い、ヒント句でオプティマイザに索引使用を促す方法もあります。
A: 統計情報を正確に保ちつつ、列のカーディナリティやクラスタ化度合いを考慮した索引設計(例えば複合索引)を行い、ヒント句でオプティマイザに索引使用を促す方法もあります。
Q: どの程度行数が増えると表探索がボトルネックになりますか?
A: ストレージ構成やバッファサイズによりますが、行数×行長分のフルスキャン I/O が発生するため、数百万行規模では顕著な遅延が発生します。
A: ストレージ構成やバッファサイズによりますが、行数×行長分のフルスキャン I/O が発生するため、数百万行規模では顕著な遅延が発生します。
関連キーワード: 表探索、索引探索、オプティマイザ、統計情報、I/Oコスト
設問3:〔問題点の指摘〕の②への対応について、(1)〜(3)に答えよ。
(3)
答えた SQL がアクセスするテーブルについて、②の問題点を改善するために表 2 に示した統計情報がシステムカタログに存在するという前提で、毎朝4時に行う次のA〜Cの処理を正しい順番に並べよ。なお、不要な処理は省いてよい。
A:不要な行の削除 B:再編成 C:統計更新処理
模範解答
C、A、B 又は A、B
解説
解答の論理構成
- 性能低下の原因
- G氏の指摘②「アクセス経路が索引探索から表探索に変わる SQL がある」
- 表探索に変わるのは、統計情報に行数が「ゼロ又は極端に少ない」と記録されるため。仕様「7.(3) 行数がゼロの場合、表探索が最適である。」が適用される。
- 現行フローの問題
- 【問題文】〔テーブルの保守の見直し〕では「(4) …再編成し、次に統計更新処理を行う。」
- つまり A→B→C の順。削除・再編成後に C を走らせるため行数が激減し、SQL6(仮注文番号検索)などが表探索化する。
- 改善方針
- 統計を「削除前」に採取するか、そもそも採取しない。
- 処理順の決定
- 方式① C→A→B
統計を先に取得(行数多い状態)→削除→再編成。統計は古いままだが行数推定は大きく、索引探索を維持。 - 方式② A→B
統計更新を行わず、前日の統計(行数多い状態)を維持。 - いずれも問題点②を解決するため、模範解答「C、A、B 又は A、B」に一致します。
- 方式① C→A→B
誤りやすいポイント
- 再編成(B)を行えばアクセス経路が自動的に元へ戻ると誤解し、C を最後に置く。
- 統計情報は常に最新であることが正しいと考え、性能への影響を軽視する。
- A→C→B を選び、再編成後のページ構造変化で統計が不整合になる点に気付かない。
FAQ
Q: 統計が実際より多い行数を示しても問題になりませんか?
A: 問題文「7.(2) 列値当たりの行数は均等である。」という仮定の範囲であれば、多少の過大評価は索引探索選択に大きく影響しません。今回の目的は「表探索化を防ぐ」ことであり、多少の誤差より索引利用の方が重要です。
A: 問題文「7.(2) 列値当たりの行数は均等である。」という仮定の範囲であれば、多少の過大評価は索引探索選択に大きく影響しません。今回の目的は「表探索化を防ぐ」ことであり、多少の誤差より索引利用の方が重要です。
Q: 定期的に統計更新をまったく行わないとどうなりますか?
A: データ量や分布が大きく変化したときに誤ったアクセス経路が選択される恐れがあります。今回は日次削除直後だけ避け、月次や閑散時に別途統計更新を実施する運用が現実的です。
A: データ量や分布が大きく変化したときに誤ったアクセス経路が選択される恐れがあります。今回は日次削除直後だけ避け、月次や閑散時に別途統計更新を実施する運用が現実的です。
Q: 再編成(B)は必須ですか?
A: 再編成でページの空き領域を詰めると I/O を減らせますが、索引探索の可否には直接影響しません。性能要件に応じて省略する選択肢もあります。
A: 再編成でページの空き領域を詰めると I/O を減らせますが、索引探索の可否には直接影響しません。性能要件に応じて省略する選択肢もあります。
関連キーワード: 統計情報、オプティマイザ、アクセス経路、索引探索、表探索
