データベーススペシャリスト 2017年 午後1 問03
テーブル及び SQL の設計に関する次の記述を読んで、設問1,2に答えよ。
A社は、全国の主要都市に家電販売チェーン店を展開している。 A社では,RDBMS の機能を用いて販売分析支援システム (以下、システムという)を運用しており,Fさんがテーブル及びSQL の設計を見直すことになった。
〔業務の概要〕
(1) 店舗は、営業本部の下で全国展開され、店舗コードで識別される。
(2) 店舗で販売を担当する社員は、いずれか一つの店舗に配属され、社員IDで識別される。各店舗には複数の社員が配属される。
(3) 商品は、商品コードで識別される。
〔システムの概要〕
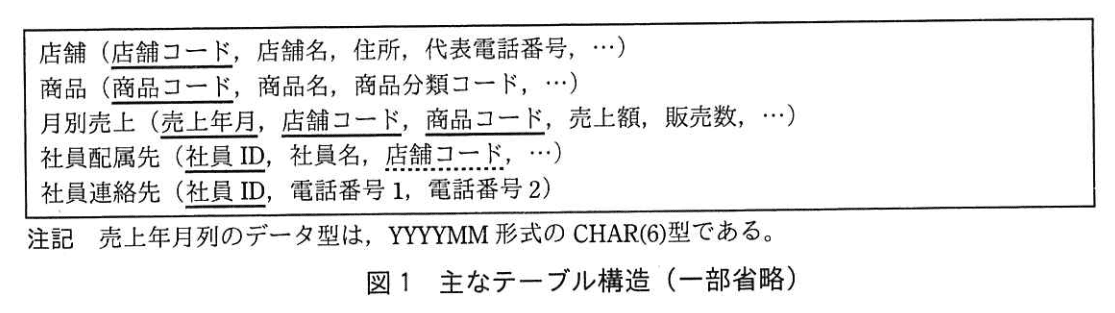
1.主なテーブル構造
主なテーブル構造を、図1に示す。 ここで、テーブルの行は追加された順に並び、同じページに異なるテーブルの行が格納されることはない。 また、索引のキー順に、ページ単位で順次又はランダムに磁気ディスク装置 (以下、ディスクという)からバッファに読み込まれる。
2.システムの運用の概要
(1) 各店舗は、閉店後の夜間に当日の売上明細ファイルを、システムに送信する。
(2) システムは、各店舗から送信された売上明細ファイルのデータを店舗コード別商品コード別に集計し、翌朝までに “月別売上” テーブルに反映させる。
(3) 営業本部の担当者は、システムを用いて販売分析を行う。 また、担当者は店舗の社員に電話をかけて販売状況を問い合わせることがある。
3.営業本部からの要望及び対応の方針
営業本部からの要望のうち、Fさんに対応を任せられた要望と、Fさんによる対応の方針は、次のとおりである。 Fさんがこれらの方針に従って変更した二つのテーブル構造を、図2に示す。
要望1 売上データの分析を行うための照会の応答時間を改善してほしい。
方針1 “月別売上” テーブルを、“月別売上B” テーブルのように変更する。
要望2 社員連絡先の電話番号を3個以上登録できるようにしてほしい。
方針2 “社員連絡先” テーブルに新たな列を追加するのではなく、“社員連絡先B" テーブルのように変更する。

〔“月別売上” テーブルの構造の変更〕
Fさんは、“月別売上” テーブルの構造の変更を、次のように検討した。
1.“月別売上” テーブルには、行が主索引のキー順にロードされている。 その全行をアンロードしたファイルを、"月別売上B” テーブルの構造に従って変換し、“月別売上B" テーブルに主索引のキー順にロードした。
2.RDBMS の機能を用いて、テーブルの統計情報を取得した。 “月別売上” テーブルと “月別売上B” テーブルの統計情報及び索引定義情報を、表1に示す。
3.次の二つの分析処理を選び、照会の応答時間を評価した。 その指標として、各分析処理に必要なディスクからの読込み行数及び読込みページ数を、表1の統計情報を基に比較した。
分析処理1 指定した1店舗について、任意の1年間の売上データを分析する。
分析処理2 指定した1商品について、任意の月の売上データを分析する。
分析処理1 指定した1店舗について、任意の1年間の売上データを分析する。
分析処理2 指定した1商品について、任意の月の売上データを分析する。
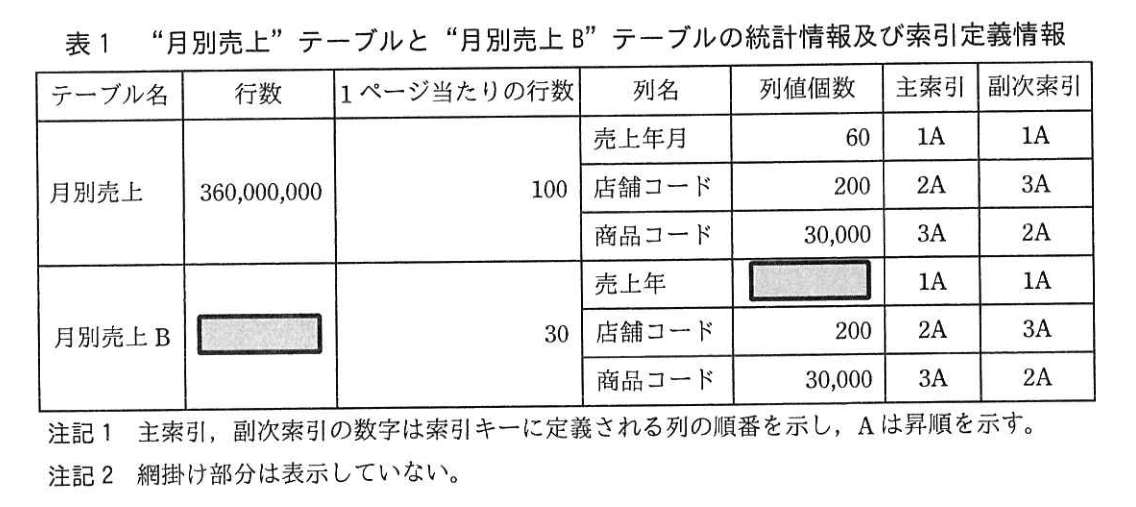
(1) 表1の二つのテーブルでは、複数行を索引のキー順に読み込む場合、アクセス経路が(ア)索引のとき、ページは順次に読み込まれるが、アクセス経路が(イ)索引のとき、1行当たり1ページがランダムに読み込まれる。
(2) 分析処理 1 では、分析に必要な “月別売上” テーブルの店舗当たりの年間(ウ)行である。これらの行を、主索引を用いてディスクから読み込むとき、最小限(エ)ページ読み込む必要がある。
一方、“月別売上 B" テーブルの1 店舗当たりの年間平均行数は、指定した 1年間が年を跨がなければ、(オ)行である。これらの行を、主索引を用いてディスクから読み込むとき、最小限(カ)ページを読み込めばよい。
しかし、その1年間が年をまたがれば、読込みページ数は(ク)ページに増える。
(3) 分析処理 2 では、分析に必要な行数は、二つのテーブルとも 1 商品コード当たり最大(ケ)行である。 これらの行を、副次索引を用いてディスクから読み込むとき、最大(コ)ページ読み込む必要がある。
4.プログラム中の SQLへの影響を調べた。 調べたのは、同じ年の二つの月、例えば,2017年1月と 2017年2月の売上額の差を求める SQL で、その構文を表2中のSQL1 に示す。 テーブル構造を変更した後で、SQL1 と同じ結果行を得るために、実行の都度、比較する年月に対応したSQL の構文を組み立て、動的 SQL で実行することにした。 その構文を表2中のSQL2に示す。

〔“社員連絡先” テーブルの構造の変更〕
Fさんは、“社員連絡先” テーブルの構造の変更を、次のように検討した。
1.“社員連絡先” テーブルの電話番号1列と電話番号2 列の値を調べたところ、プログラムの不備による次のような問題の行があることが分かった。
問題1:電話番号1 列と電話番号2 列は、異なる電話番号であるべきところ、同じ電話番号が設定されている行があった。
問題2:電話番号1 列だけに電話番号を設定すべきところ、電話番号1列にNULL が、電話番号2列に電話番号が設定されている行があった。
問題3:電話番号が設定されている場合だけ行を登録すべきところ、電話番号1列と電話番号2 列の両方に NULL が設定されている行があった。
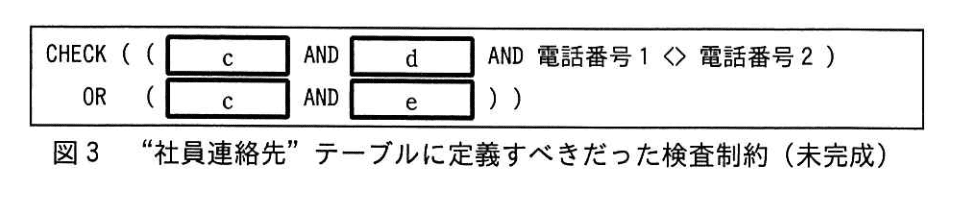
2.問題 1〜3 を防ぐには、“社員連絡先” テーブルに、図3に示す検査制約を定義す
べきであった。 ここで、検査制約は、次の①〜④のいずれかの述語を組み合わせて
指定する。
① 電話番号1 IS NOT NULL
② 電話番号1 IS NULL
③ 電話番号2 IS NOT NULL
④ 電話番号2 IS NULL
3.“社員連絡先B" テーブルの要件を、次のように整理した。
要件1:問題1〜3を解決すること
要件2:社員1人当たりの電話番号を3個以上登録できること
なお、同じ電話番号が複数の社員で使われることがある。
4.“社員連絡先 B” テーブルの電話番号列に NOT NULL 制約を定義し、テーブルに一意性制約を定義した。
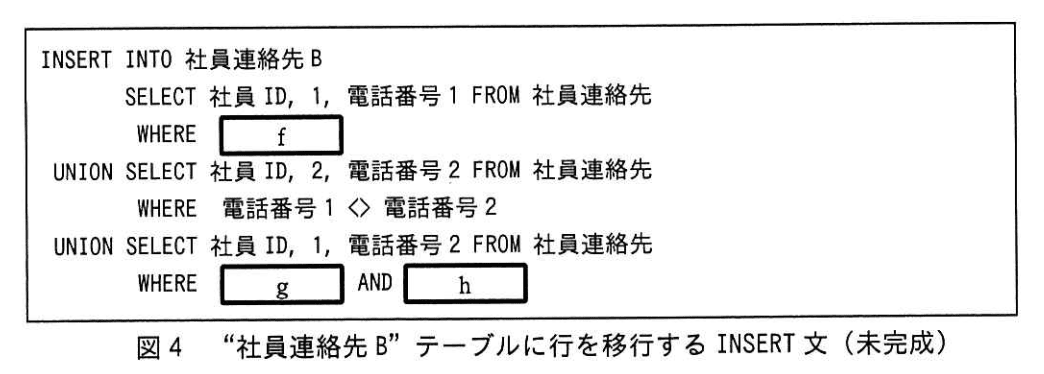
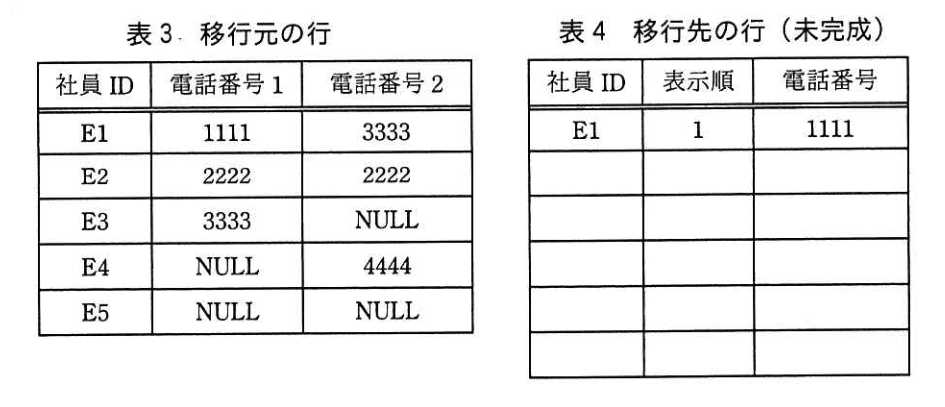
5.要件 1 2 を満たすために、図4に示す INSERT文を用いて、“社員連絡先” テーブルから“社員連絡先 B” テーブルに行を移行することにした。 その移行試験を行ったときの、移行元である “社員連絡先” テーブルの問題 1〜3 を含む行を表3,移行先である“社員連絡先 B" テーブルの行を表4に示す。 ここで、表3及び表 4の見出しは列名を表す。
設問1:〔“月別売上” テーブルの構造の変更〕 について、(1)〜(3)に答えよ。
(1)分析処理に関する記述中の(ア)〜(コ)に入れる適切な字句を答えよ。
なお、索引のバッファヒット率は100%であり、ページ中の行をアクセスするとき、次にアクセスするページはバッファにないものとする。
模範解答
ア:主
イ:副次
ウ:360,000
エ:3,600
オ:30,000
カ:1,000
キ:2
ク:2,000
ケ:200
コ:200
解説
解答の論理構成
-
アクセス経路の種類
(1) に「アクセス経路が(ア)索引のとき、ページは順次に…(イ)索引のとき,1行当たり1ページ…」とあり、主キー経路が順次読み込み、副次索引がランダム読み込みであるため
• (ア)=「主」 • (イ)=「副次」。 -
分析処理1の行数 (ウ)
「指定した1店舗について、任意の1年間」→店舗固定、年固定、月×商品 の組合せ。
月数=12、商品コードの列値個数=【表1】「30,000」。
よって 行 → (ウ)。 -
ページ数 (エ)
“月別売上” の1ページ当たり行数=【表1】「100」。
ページ → (エ)。 -
“月別売上B” の行数 (オ)
1年分12か月が1行になるため行数は 行 → (オ)。 -
ページ数 (カ)・(ク)
1ページ当たり行数=【表1】“月別売上B”「30」。
• 年またぎ無し: → (カ)。
• 年またぎ有り(2年分): → (ク)。 -
分析処理2の行数 (ケ)
「指定した1商品について、任意の月」→商品固定・月固定・店舗のみ可変。
店舗コードの列値個数=【表1】「200」。よって 200 行 → (ケ)。 -
ページ数 (コ)
(1) に「(イ)索引のとき、1行当たり1ページがランダムに読み込まれる」と明記。
(ケ) 行全部が別ページになるため (コ)=200 ページ。
誤りやすいポイント
- “月別売上B” の1ページ当たり行数「30」を見落として 100 で割ってしまう。
- 年をまたぐケースの存在に気付かず (ク) を 1,000 のままにする。
- 副次索引でもページに複数行載ると早合点し (コ) を 2〜4 ページと少なく見積もる。
- 行数算出で「360,000,000」を直接割ろうとして複数店舗・年を混同する。
FAQ
Q: 主索引と副次索引で読込み方式が違うのはなぜですか?
A: 主索引は表の物理配置順と一致しているため、対象行が近接しておりバッファに順次ロードできます。一方、副次索引は行の物理位置がバラバラなので、索引ツリー経由で目的行を1件ずつ探し、結果として1行=1ページのランダム I/O になりやすいからです。
A: 主索引は表の物理配置順と一致しているため、対象行が近接しておりバッファに順次ロードできます。一方、副次索引は行の物理位置がバラバラなので、索引ツリー経由で目的行を1件ずつ探し、結果として1行=1ページのランダム I/O になりやすいからです。
Q: “月別売上B” では行数が 1/12 になるのにページ当たり行数が減っている理由は?
A: 各行に 12 か月分 × 2 列(売上額・販売数)など多くの列が追加され、行長が約 12 倍になるため 1 ページに収まる行数が「100 → 30」に減少しています。行当たりデータ量とページサイズのバランスを反映した統計値です。
A: 各行に 12 か月分 × 2 列(売上額・販売数)など多くの列が追加され、行長が約 12 倍になるため 1 ページに収まる行数が「100 → 30」に減少しています。行当たりデータ量とページサイズのバランスを反映した統計値です。
Q: 副次索引使用時にフルスキャンを選択するケースはありますか?
A: あります。対象行がテーブル全体の大半を占める場合、索引経由でランダムアクセスするより表をフルスキャンした方がディスク I/O が少なくなるとオプティマイザが判断することがあります。本問では対象行が「200/360,000,000」と極端に少ないため、副次索引利用が有利とされています。
A: あります。対象行がテーブル全体の大半を占める場合、索引経由でランダムアクセスするより表をフルスキャンした方がディスク I/O が少なくなるとオプティマイザが判断することがあります。本問では対象行が「200/360,000,000」と極端に少ないため、副次索引利用が有利とされています。
関連キーワード: 主索引、副次索引、ページング、統計情報、ランダムアクセス
設問1:〔“月別売上” テーブルの構造の変更〕 について、(1)〜(3)に答えよ。
(2)表2中の(a)、(b)に入れる適切な字句を答えよ。
模範解答
a:売上額2月 - 売上額1月
b:売上年 = '2017' 又は 売上年 = ?
解説
解答の論理構成
-
問題設定の確認
- 【問題文】「同じ年の二つの月、例えば,2017年1月と 2017年2月の売上額の差を求める SQL」とある。
- さらに「ホスト変数の hv1 及び hv2 には、それぞれ ‘201701’ 及び ‘201702’ が設定」と記載。
-
比較対象の月を列で表現
-
“月別売上B” では「売上額1月」「売上額2月」… と 1 行に 12 か月分を保持する縦持ち→横持ち(ワイドテーブル)設計に変更済み。
-
双方の月を同一行内で参照できるため、SELECT 句は売上額2月 - 売上額1月で目的の差分が得られる。従来の自己結合は不要。
-
-
WHERE 句の絞り込み
-
列として「売上年」が存在し、比較月は列名で確定しているため、条件は年のみ。
-
hv1・hv2 の先頭 4 桁が “2017” とわかるので売上年 = '2017'が適切。
-
-
以上より
- (a) = 「売上額2月 - 売上額1月」
- (b) = 「売上年 = '2017'」
誤りやすいポイント
- 縦持ちの “月別売上” と横持ちの “月別売上B” を混同し、自己結合を書いてしまう。
- WHERE 句で月も絞り込みたくなり 売上月 IN (1,2) などと余計な条件を付け、結果列に NULL が混在して誤差分が NULL になる。
- 年をハードコードせず SUBSTR(:hv1,1,4) と書きたくなるが、試験では具体例をそのまま記述させる設問である点を見落とす。
FAQ
Q: 列名に全角数字が含まれていますが、そのまま記述して良いですか?
A: はい。【問題文】中で列名として提示されている「売上額1月」「売上額2月」などはそのまま引用する必要があります。
A: はい。【問題文】中で列名として提示されている「売上額1月」「売上額2月」などはそのまま引用する必要があります。
Q: hv1 と hv2 が異なる年になる場合はどうしますか?
A: 設問は「同じ年の二つの月」を前提にしているので、今回の回答では年が一致しているケースだけを考えます。異年比較を行う場合は WHERE 句を 売上年 = SUBSTR(:hv1,1,4) など動的に組み替え、列名も年を跨いだロジックに変更する必要があります。
A: 設問は「同じ年の二つの月」を前提にしているので、今回の回答では年が一致しているケースだけを考えます。異年比較を行う場合は WHERE 句を 売上年 = SUBSTR(:hv1,1,4) など動的に組み替え、列名も年を跨いだロジックに変更する必要があります。
Q: 売上額列に NULL があった場合、差分計算はどうなるのでしょう?
A: 通常の SQL 演算では NULL を含む計算結果は NULL になります。データをクリーニングするか COALESCE(売上額n月,0) で NULL を 0 に置換してから差分を取るなどの対処が必要です。
A: 通常の SQL 演算では NULL を含む計算結果は NULL になります。データをクリーニングするか COALESCE(売上額n月,0) で NULL を 0 に置換してから差分を取るなどの対処が必要です。
関連キーワード: 正規化、ワイドテーブル、動的SQL, 集約列、縦持ち横持ち
設問1:〔“月別売上” テーブルの構造の変更〕 について、(1)〜(3)に答えよ。
(3)Fさんは、なぜ表2中の SQL2 を動的 SQL で実行することにしたのか。 その理由を 40字以内で述べよ。
模範解答
比較する売上年月ごとに選択リストの列名を変更しなければならないから
解説
解答の論理構成
- テーブル変更の影響
“月別売上B” は「売上年、店舗コード、商品コード」に続き「売上額1月」「売上額2月」…の列を持つワイドテーブル。 - 既存 SQL1 の構造
SQL1 では WHERE X.売上年月 = :hv1 AND Y.売上年月 = :hv2 によって行を選び、同じ列 売上額 を減算して月間差を算出していた。 - 列名が可変になる問題
ワイドテーブルでは比較する月ごとに引き当てる列が変わる。たとえば1月と2月なら 売上額1月 と 売上額2月、3月と5月なら 売上額3月 と 売上額5月 になる。 - 静的 SQL では対応不能
プレースホルダ(バインド変数)はリテラル値や演算対象に使えても、列名を置き換える機能はない。 - 動的 SQL が唯一の解決策
したがって【問題文】にある通り「実行の都度、比較する年月に対応したSQL の構文を組み立て」る必要が生じ、動的 SQL を選択した。
誤りやすいポイント
- バインド変数で列名まで可変にできると誤解する。
- 「WHERE 句だけが問題」と考え、SELECT 句の列名置換を見落とす。
- 年月を跨ぐ場合のページ読み込み増など別テーマの記述と混同し、本設問の焦点を外す。
FAQ
Q: 静的 SQL で CASE 式を使えば列名の切替えを回避できますか?
A: CASE 式で列名自体は切替えられません。各列値を CASE の条件分岐で選択する方法はありますが、12 か月分すべてを式に含むため可読性と保守性が低下し、本システムの方針に合いません。
A: CASE 式で列名自体は切替えられません。各列値を CASE の条件分岐で選択する方法はありますが、12 か月分すべてを式に含むため可読性と保守性が低下し、本システムの方針に合いません。
Q: ビューを月ごとに作っておけば動的 SQL を避けられますか?
A: ビューを月ペアごとに無数に作成する必要が生じ、管理コストが高騰します。柔軟性と実行時の自由度を確保するには動的 SQL が合理的です。
A: ビューを月ペアごとに無数に作成する必要が生じ、管理コストが高騰します。柔軟性と実行時の自由度を確保するには動的 SQL が合理的です。
Q: 動的 SQL によるパフォーマンス低下は問題になりませんか?
A: 解析準備時間が再発生しますが、月間差分取得は分析処理の一部であり、I/O 削減効果のほうが大きいと判断されています。必要に応じてプリペアドキャッシュや変数バインドで実行計画の再利用を図ります。
A: 解析準備時間が再発生しますが、月間差分取得は分析処理の一部であり、I/O 削減効果のほうが大きいと判断されています。必要に応じてプリペアドキャッシュや変数バインドで実行計画の再利用を図ります。
関連キーワード: 動的SQL, ワイドテーブル設計、列名可変、バインド変数、可読性向上
設問2:〔“社員連絡先” テーブルの構造の変更〕 について、(1)〜(5)に答えよ。
(1)“社員連絡先B” テーブルの電話番号列に NOT NULL 制約を定義した理由を、本文中の字句を用いて25字以内で述べよ。
模範解答
電話番号が設定されている行だけを登録したいから
解説
解答の論理構成
- 【問題文】には電話番号列の欠陥として
「問題3:電話番号が設定されている場合だけ行を登録すべきところ…NULL が設定されている行があった。」
と記述されている。 - そこでFさんは「“社員連絡先 B” テーブルの電話番号列に NOT NULL 制約を定義」したと述べている。
- NOT NULL 制約を付ければ NULL 値(=電話番号未設定)を持つ行そのものが登録不可能になる。
- したがって「電話番号が設定されている行だけを登録したい」という意図と完全に一致する。
誤りやすいポイント
- 「一意性制約」も定義されているが、NOT NULL とは目的が異なる(重複防止ではなく空値防止)。
- 問題1・問題2の対策と混同し、NULL 制約の役割をあいまいに答えてしまう。
- “行を更新するとき”ではなく“登録(INSERT)時”のチェックであることを忘れがち。
FAQ
Q: なぜ CHECK ではなく NOT NULL としたのですか?
A: 電話番号列を NULL 禁止にすれば「電話番号未設定の行」を物理的に登録できなくなるため、CHECK より簡潔で確実です。
A: 電話番号列を NULL 禁止にすれば「電話番号未設定の行」を物理的に登録できなくなるため、CHECK より簡潔で確実です。
Q: 電話番号が複数登録される場合はどう区別しますか?
A: 「表示順」列で 1,2,3… を付与し、複数レコードで 1 人当たり 3 件以上を保持できます(同じ電話番号が他の社員と重複しても一意性制約の列組み合わせで許容)。
A: 「表示順」列で 1,2,3… を付与し、複数レコードで 1 人当たり 3 件以上を保持できます(同じ電話番号が他の社員と重複しても一意性制約の列組み合わせで許容)。
関連キーワード: NOT NULL 制約、NULL 値、検査制約、一意性制約
設問2:〔“社員連絡先” テーブルの構造の変更〕 について、(1)〜(5)に答えよ。
(2)“社員連絡先B” テーブルの一意性制約に定義すべき列名又は列名の組合せを答えよ。 ここで、主キー制約を除くこと。
模範解答
社員ID、電話番号 又は 電話番号、社員ID
解説
解答の論理構成
- 【問題文】「要件1:問題1〜3を解決すること」より、
- 問題1:同一社員行内で電話番号が重複してはいけない
- 【問題文】「なお、同じ電話番号が複数の社員で使われることがある。」より、
- 電話番号は社員をまたいで重複してもよい
- 【問題文】「4.“社員連絡先 B” テーブルの電話番号列に NOT NULL 制約を定義し、テーブルに一意性制約を定義した。」より、
- NULL は排除済みなので一意性検証は値比較だけで済む
- 主キー (社員ID, 表示順) では “同じ社員が 1 と 2 の両行に 1111” のような重複を防げない
- 電話番号のみでは異なる社員 E1 と E3 が 3333 を共有できなくなる
- よって「社員ID と 電話番号」の組に一意性制約を設けることで
・同一社員内の重複を排除(問題1解決)
・異なる社員間の番号共有を許容(要件2を阻害しない) - 以上より答えは「社員ID、電話番号」です。列順に意味はないため「電話番号、社員ID」でも同義となります。
誤りやすいポイント
- 電話番号列だけに一意性を掛けてしまい、複数社員で同じ番号を持てなくなる
- 主キーと同じ「社員ID、表示順」を再度一意にしてしまい、問題1が未解決
- 「表示順、電話番号」とすると同一番号を異なる表示順で登録できる点を見落とす
FAQ
Q: 「社員ID、電話番号」を主キーにしてはいけないのですか?
A: 表示順で並び替える要求があるため主キーは「社員ID、表示順」が適切です。一意性は別途「社員ID、電話番号」で与えるのが自然です。
A: 表示順で並び替える要求があるため主キーは「社員ID、表示順」が適切です。一意性は別途「社員ID、電話番号」で与えるのが自然です。
Q: 電話番号列に NOT NULL 制約があるのに一意性制約は必要ですか?
A: NOT NULL は欠損値を防ぐだけで重複を許します。重複禁止には一意性制約が必須です。
A: NOT NULL は欠損値を防ぐだけで重複を許します。重複禁止には一意性制約が必須です。
Q: 列順は制約に影響しますか?
A: 一意性制約では列の組合せ全体がキーになりますので、「社員ID、電話番号」と「電話番号、社員ID」は機能的に同一です。
A: 一意性制約では列の組合せ全体がキーになりますので、「社員ID、電話番号」と「電話番号、社員ID」は機能的に同一です。
関連キーワード: 一意性制約、複合キー、NULL制約、主キー設計、データ品質
設問2:〔“社員連絡先” テーブルの構造の変更〕 について、(1)〜(5)に答えよ。
(3)図3中の(c)〜(e)に入れる適切な述語を、①〜④の中からそれぞれ重複なく一つずつ選んで答えよ。
模範解答
c:①
d:③
e:④
解説
解答の論理構成
- 【問題文】では検査制約を
CHECK ( ((c) AND (d) AND 電話番号1 <> 電話番号2) OR ((c) AND (e)) )
と提示しています。 - 目的は【問題文】の “問題1〜3を防ぐ” こと。具体的には
- 問題1:同じ番号を重複登録
- 問題2:電話番号1 が NULL、電話番号2 のみ有値
- 問題3:両方 NULL
- まず両パターンとも (c) が 共通 で使われているため、(c) は必ず満たすべき条件です。問題2・3を防ぐには 電話番号1 の非 NULL を必須にする必要があるので (c)=① 電話番号1 IS NOT NULL と決定します。
- 第1グループは「両列に値があり、かつ異なる」条件です。ここで (d) は 電話番号2 の非 NULL、つまり ③ 電話番号2 IS NOT NULL が入ります。
- 第2グループは「電話番号2 が無い」パターンを許可するため (e)=④ 電話番号2 IS NULL。
- 以上より
- c:① 電話番号1 IS NOT NULL
- d:③ 電話番号2 IS NOT NULL
- e:④ 電話番号2 IS NULL
が正答となります。
誤りやすいポイント
- (c) と (d) を “電話番号1・2それぞれ NULL/NOT NULL を入れ替えても同じ” と早合点する。実際には (c) が両グループで共通なので入れ替え不可です。
- 問題1の「値が同じ」を <> 条件で排除できることを忘れ、(d) に 電話番号2 IS NULL を入れてしまう。
- 問題2を “電話番号2 だけ有値も許可” と誤読し、(c) に ② 電話番号1 IS NULL を選んでしまう。
FAQ
Q: 電話番号2 だけが登録されるケースも業務上ありそうですが、なぜ許さないのですか?
A: 【問題文】で “電話番号1 列だけに電話番号を設定すべきところ” と規定されており、電話番号1 が必須だからです。設計上「主番号は必ず電話番号1」と定めています。
A: 【問題文】で “電話番号1 列だけに電話番号を設定すべきところ” と規定されており、電話番号1 が必須だからです。設計上「主番号は必ず電話番号1」と定めています。
Q: 電話番号1 <> 電話番号2 だけで重複を防げませんか?
A: NULL が混在すると比較結果が不定になるため、NULL 制御を IS NULL/IS NOT NULL で明示的に行う必要があります。
A: NULL が混在すると比較結果が不定になるため、NULL 制御を IS NULL/IS NOT NULL で明示的に行う必要があります。
Q: “社員連絡先B” へ移行した後も同じ制約は必要ですか?
A: “社員連絡先B” は 1 行 1 電話番号の構造で、一意性制約と NOT NULL ですべての問題を根本的に解消できるため、同じ複合 CHECK 制約は不要です。
A: “社員連絡先B” は 1 行 1 電話番号の構造で、一意性制約と NOT NULL ですべての問題を根本的に解消できるため、同じ複合 CHECK 制約は不要です。
関連キーワード: CHECK制約、NULL判定、論理演算、データ整合性、非正規形
設問2:〔“社員連絡先” テーブルの構造の変更〕 について、(1)〜(5)に答えよ。
(4)図4中の(f)〜(h)に入れる適切な述語を、(3)に倣って①〜④の中からそれぞれ重複なく一つずつ選んで答えよ。(g, hは順不同)
模範解答
f:①
g:②
h:③
解説
解答の論理構成
-
【問題文】図4(INSERT 文)の構造SELECT 社員ID、1, 電話番号1 … WHERE □(f) UNION SELECT 社員ID、2, 電話番号2 … WHERE 電話番号1 <> 電話番号2 UNION SELECT 社員ID、1, 電話番号2 … WHERE □(g) AND □(h)
-
選択肢は 【問題文】「① 電話番号1 IS NOT NULL ② 電話番号1 IS NULL ③ 電話番号2 IS NOT NULL ④ 電話番号2 IS NULL」。
-
第1SELECT(表示順=1, 電話番号1)
- 目的:有効な “電話番号1” をそのままコピー。
- 必要条件:電話番号1 が NULL でないこと → “①”。
- 重複なしの要件とも矛盾しない。
⇒ (f)=①。
-
第2SELECT(表示順=2, 電話番号2)
- WHERE 句に既に 電話番号1 <> 電話番号2 がある。
- “電話番号1 = 電話番号2” 行(【問題文】“問題1”)を除外して二件目として登録する意図。
- 追加の述語は不要なので (g)(h) ではない。
-
第3SELECT(表示順=1, 電話番号2)
- 目的:電話番号1 が未入力で 電話番号2 だけ登録されている行(【問題文】“問題2”)を救済。
- 条件① 電話番号1 IS NULL → “②”。
- 条件② 電話番号2 IS NOT NULL → “③”。
- 両条件は AND で連結、順序は問われていない。
⇒ (g)=②、(h)=③(順不同)。
誤りやすいポイント
- 第2SELECTに既に 電話番号1 <> 電話番号2 があるため、「③」を重ねて書かないこと。
- 第3SELECTの表示順は “1” なので「2」にしてしまうミスに注意。
- NULL 判定に = を使う誤記(電話番号1 = NULL など)は SQL 文法エラーとなる。
FAQ
Q: 第1SELECTに 電話番号1 <> 電話番号2 を追加しても良いですか?
A: 不要です。電話番号1 が NULL でなければ要件1(重複電話番号の排除)は第2SELECTでカバーでき、余計な述語は性能低下を招きます。
A: 不要です。電話番号1 が NULL でなければ要件1(重複電話番号の排除)は第2SELECTでカバーでき、余計な述語は性能低下を招きます。
Q: 第3SELECTで 電話番号2 IS NOT NULL だけを書けば十分では?
A: 電話番号1 が NULL である保証がなければ、電話番号1 も値を持つ行を重複登録する恐れがあります。必ず “② 電話番号1 IS NULL” と組合せます。
A: 電話番号1 が NULL である保証がなければ、電話番号1 も値を持つ行を重複登録する恐れがあります。必ず “② 電話番号1 IS NULL” と組合せます。
Q: UNION ALL ではなく UNION を使っている理由は?
A: UNION は重複行を自動的に排除するため、一意性制約を意識した手間の少ない書き方になります。
A: UNION は重複行を自動的に排除するため、一意性制約を意識した手間の少ない書き方になります。
関連キーワード: NULL判定、一意性制約、検査制約、UNION, INSERT…SELECT
設問2:〔“社員連絡先” テーブルの構造の変更〕 について、(1)〜(5)に答えよ。
(5)表4に記入されている 1行目の例に倣って、全ての結果行を埋めよ。 ここで、行の並び順は問わない。 また、表4の全ての行が埋まるとは限らない。
模範解答
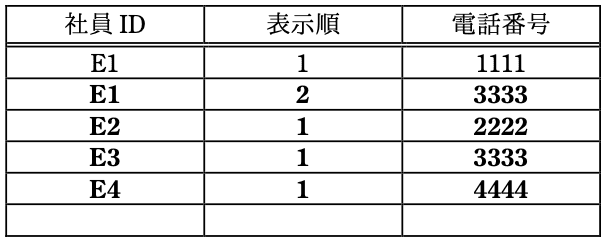
解説
解答の論理構成
-
前提整理
- 移行元行は【問題文】「表3」に5件。
- 移行先は【問題文】「“社員連絡先B” テーブルの電話番号列に NOT NULL 制約を定義」なので NULL は登録不可。
-
INSERT 文の3つの SELECT
- 【問題文】「SELECT 社員ID、1, 電話番号1 … WHERE □(f)」
• 要件:電話番号1が存在する行だけを採用 → (f) は “電話番号1 IS NOT NULL”。
• 取得行:E1/E2/E3。 - 【問題文】「SELECT 社員ID、2, 電話番号2 … WHERE 電話番号1 <> 電話番号2」
• <> は両列が非 NULL かつ値が異なる場合にのみ真。
• 取得行:E1(1111≠3333)だけ。E2 は同値、E4 は NULL 比較で偽。 - 【問題文】「SELECT 社員ID、1, 電話番号2 … WHERE □(g) AND □(h)」
• 要件2の「電話番号1が無いが電話番号2はある」パターンを救済。
(g) は “電話番号1 IS NULL”、(h) は “電話番号2 IS NOT NULL”。
• 取得行:E4 のみ。
- 【問題文】「SELECT 社員ID、1, 電話番号1 … WHERE □(f)」
-
UNION の結果
- ①+②+③ = {E1-1111, E2-2222, E3-3333, E1-3333, E4-4444}
- 表示順は SELECT 固定値で決定。
- E5 は両列 NULL なのでどの SELECT にも該当しない。
-
一意性制約との整合
- 【問題文】「テーブルに一意性制約を定義した。」により
(社員ID, 表示順) または (社員ID, 電話番号) の重複は登録不可。
取得結果には重複がないため制約違反は発生しない。
- 【問題文】「テーブルに一意性制約を定義した。」により
-
最終結果行社員ID 表示順 電話番号 E1 1 1111 E1 2 3333 E2 1 2222 E3 1 3333 E4 1 4444
誤りやすいポイント
- NULL と値の比較結果は UNKNOWN。WHERE 電話番号1 <> 電話番号2 では「片方が NULL」を拾えない。
- 「同じ電話番号が複数の社員で使われることがある」を読み落とし、一意性制約のキーを (電話番号) だけにしてしまう。
- 問題2を修正する SELECT ③の表示順を「2」にしてしまい、社員 E4 の表示順が 2 になり制約違反となる。
- E5 のように両方 NULL の行を誤って INSERT してしまい、NOT NULL 制約違反となる。
FAQ
Q: WHERE 電話番号1 <> 電話番号2 で NULL を含む行が無視される理由は?
A: SQL の3値論理では NULL との比較は真でも偽でもなく UNKNOWN になり、WHERE 句では採用されません。
A: SQL の3値論理では NULL との比較は真でも偽でもなく UNKNOWN になり、WHERE 句では採用されません。
Q: 電話番号列に NOT NULL を付けただけで問題1~3は防げますか?
A: 防げません。問題1(重複番号)は一意性制約、問題2・3(NULL 関連)は CHECK 制約または移行時のロジックで排除する必要があります。
A: 防げません。問題1(重複番号)は一意性制約、問題2・3(NULL 関連)は CHECK 制約または移行時のロジックで排除する必要があります。
Q: 表示順を 1 と 2 に固定してしまうと、要件2「3個以上登録」へ拡張できませんか?
A: 移行時は最大 2 件しか存在しないため固定値で良く、追加登録時はアプリまたはシーケンスで 3 以上の表示順を設定すれば拡張可能です。
A: 移行時は最大 2 件しか存在しないため固定値で良く、追加登録時はアプリまたはシーケンスで 3 以上の表示順を設定すれば拡張可能です。
関連キーワード: NULL比較、CHECK制約、一意性制約、UNION, 移行スクリプト
