データベーススペシャリスト 2018年 午後1 問03
物理データベースの設計及び実装に関する次の記述を読んで 設問 1, 2に答えよ。
A社は、都市近郊で複数の日帰り温泉施設(以下、施設という)を運営している。
A社では、リピータを増やすために、全施設で利用できる会員カードを希望する客に発行し、新たにシニア向けの割安な利用料金を設定することにした。 また、この計画に伴いシステムを拡張することが決まり、Fさんが物理データベースの設計及び実装(以下、物理 DB 設計及び実装という)を担当することになった。
〔RDBMS の主な仕様〕
(1) テーブル及び索引のストレージ上の物理的な格納場所を、表領域という。
(2) RDBMSとストレージ間の入出力単位を、ページという。同じページに異なるテーブルの行が格納されることはない。
(3) 索引は、ユニーク索引と非ユニーク索引に分けられる。
(4) 索引は、クラスタ性という性質によって、高クラスタな索引と低クラスタな索引に分けられる。
・高クラスタな索引: キー値の順番と、キーが指す行の物理的な並び順が一致しているか、完全に一致していなくても、隣接するキーが指す行が同じページに格納されている割合が高い。
・低クラスタな索引: キー値の順番と、キーが指す行の物理的な並び順が一致している割合が低く、行へのアクセスがランダムになる。
(5) DML のアクセスパスは、RDBMS によってテーブル及び索引に関する統計情報に基づいて索引探索又は表探索に決められる。 ただし、次の場合は除く。
・WHERE 句の AND だけで結ばれた等値比較の対象列がユニーク索引のキー列に一致している場合 : 統計情報にかかわらず、その索引の索引探索に決められる。
・統計情報からテーブルが空 (0行) と判断した場合: 表探索に決められる。
(6) 主キー制約及び UNIQUE 制約は、制約を定義する列の構成に一致したユニーク索引が RDBMSによって自動的に作成されることで一意性が保証される。
〔施設運営及び会員カードの概要〕
1.施設運営
(1) 営業時間帯は、9:00〜24:00である。
(2) 各施設には、エステ、理容、食事処、売店など、一つ以上の店舗がある。
(3) 受付では、客が一人1枚ずつ入館券を購入し、入館券ごとに腕輪付きロッカ一鍵(以下、鍵という)を一つ受け取り、帰るときに返却する。
(4) 客は、鍵のバーコードに記録されている鍵番号を店舗のレジに読み取らせることで、店舗の有料サービスを含む商品を利用できる。 レジに記録されたデータは、客が精算するまでにシステムのデータベースに送られる。
(5) 未精算の利用額は、退館時に複数台のいずれかの精算機で精算する。
(6) 同じ客が同じ日に、同じ施設を複数回、利用することができる。 この場合、入館券を再度、購入する必要がある。
2.会員カード
(1) 客は、会員カード申込書(以下、申込書という)に必要な情報(氏名、生年月日など)を記入する。 未就学児の入館は無料なので申込対象外である。
(2) 客は、会員IDが刻印された会員カード (申込書に添付) を受け取り、その日から利用することができる。 会員には、鍵を用いた利用の額に応じてポイントを付与する。 ポイントは、次回以降の施設利用に使うことができる。
(3) システムは、翌朝の開館までに申込書に基づいて会員情報を登録し、また、毎日の営業時間外に、会員の生年月日に基づいて年齢及び年齢区分を設定する。
(4) 登録の翌日以降、客は、会員カードを提示して、年齢に応じた入館券を購入する。その際、年齢を示す証明書の提示を求められることはない。
〔物理 DB 設計及び実装〕
1.物理 DB 設計及び実装の前提
(1) テーブル構造は、既に決まっている
(2) テーブルごとの行数は、過去の実績及び伸び率の予想に基づいて見積もる。
(3) 利用実績データは、分析のために1年分を保存する。
(4) システムで用いられるユーザ、ロールは、定義済みである。
(5) プログラム開発者は、DML を設計し、プログラムの開発 単体テストを行う。
(6) 索引は、プログラム開発者が設計した DML に基づいてFさんが設計を行う。
2.主なテーブル構造及び主な列の意味と制約
主なテーブル構造を図1に、主な列の意味・ 制約を表1に示す。 また、“会員”テーブルの年齢区分と年齢の組合せを限定する検査制約を、図2に示す。



3.物理 DB 設計及び実装の作業工程表
Fさんが作成中の物理DB設計及び実装の作業工程表を、表2に示す。
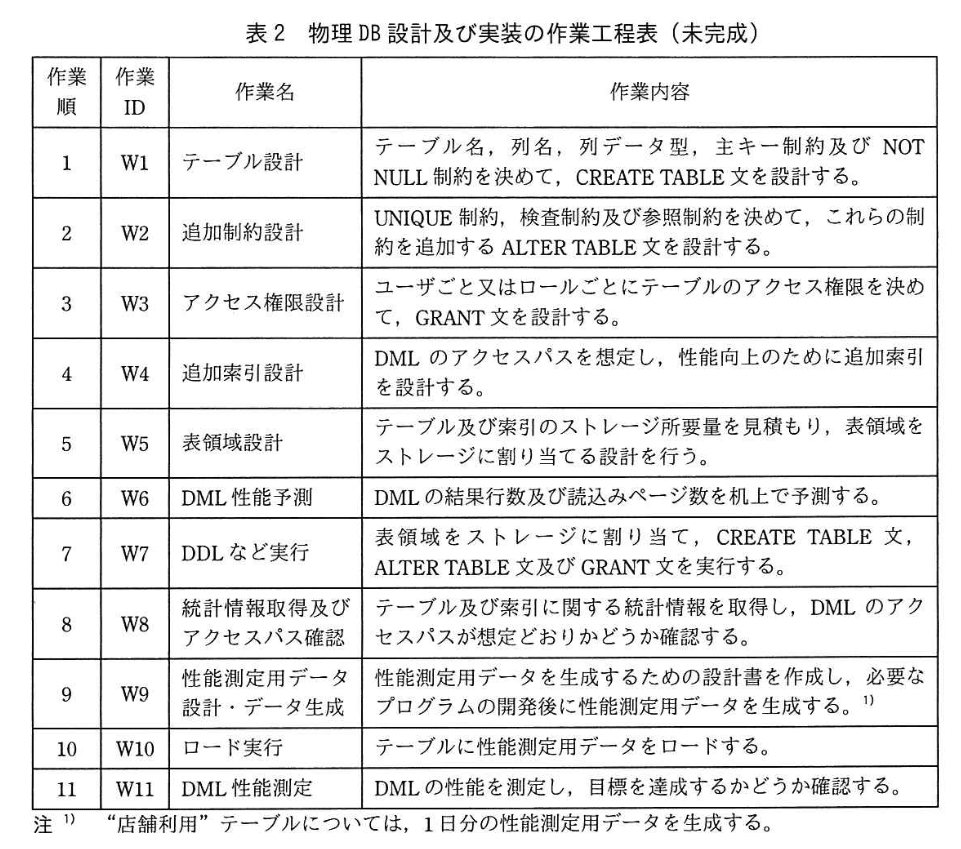
(1) 作業 W4 (追加索引設計)で、利用額の精算時に実行される DML の例を表 3に,Fさんが DML2 及び DML3のために追加した索引を表4に示す。

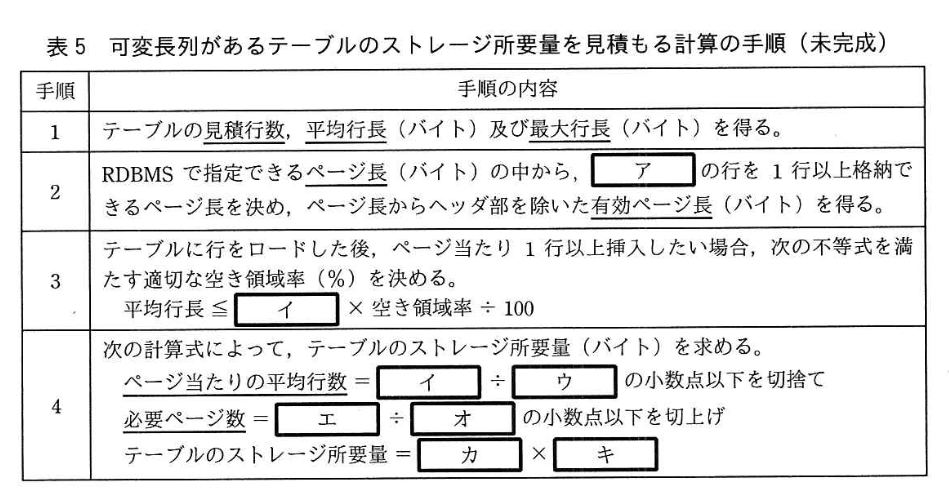
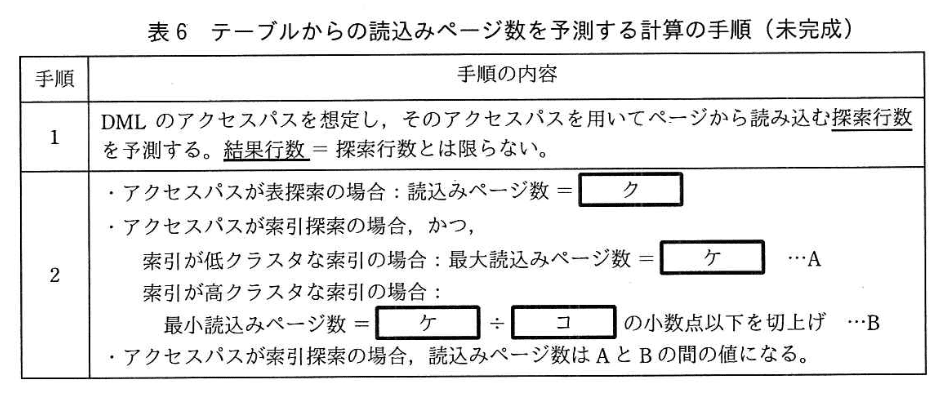
(2) 作業 W5 (表領域設計)、可変長列があるテーブルのストレージ所要量を見積もる計算の手順を、表 5に示す。 また、作業 W6 (DML 性能予測) で DML性能の指標としてDMLのテーブルからの読込みページ数を、表5の見積結果を用いて予測する計算の手順を、表6に示す。
〔G部長の指摘〕
表2の作業工程表について、Fさんは、表に示した作業順で逐次、各作業を行うつもりであったが、G部長から次のような指摘があった。
指摘1:作業を並行して進めることで、作業工程期間を短縮できる。
指摘2:作業 W8 (統計情報取得及びアクセスパス確認) の作業順が8番目では、表3のDML のアクセスパスが適切に決められない。 作業 W8 を、作業(あ)の後に行うべきである。
設問1:表2の作業工程表について、(1)〜(5)に答えよ。
(1)作業 W2(追加制約設計)で “店舗”、“精算” の各テーブルに UNIQUE 制約を設計する場合について、UNIQUE 制約を定義する列の構成(列名又は列名の組合せ)を、それぞれ一つ答えよ。
なお、UNIQUE 制約がない場合、“なし” と答えよ。(b, cは順不同)
模範解答
店舗:施設ID, 内線番号
精算:なし
解説
解答の論理構成
- 一意性が必要な箇所の洗い出し
- “店舗”テーブルの主要列は【図1】で 施設ID、店舗ID、店舗名、内線番号。
- 店舗は施設ごとに複数存在し、内線番号は施設内で電話を識別すると【表1】に記載。
- よって「同一施設内で内線番号が重複してはならない」が要件。
- 列組合せの決定
- 単独の 内線番号 だけでは他施設と衝突する可能性があるため、 施設ID, 内線番号 の複合で一意性を持たせる。
- “精算”テーブルの確認
- 【図1】“精算”の下線付き列 利用年月日、施設ID、券番号 が主キー。
- 【RDBMS の主な仕様】(6):主キー制約で「一意性が保証」され、ユニーク索引も自動生成。
- 追加の UNIQUE 制約は冗長となるため「なし」と判断。
誤りやすいポイント
- 主キー自動索引の存在を忘れ、重複して UNIQUE 制約を定義してしまう。
- “店舗”で 店舗ID を候補に選ぶ誤答:店舗ID は施設横断で一意とは示されていない。
- “精算”で部分列(例:施設ID、券番号)を UNIQUE とする誤答:利用年月日 が抜けると同日再入館ケースで重複が起こり得る。
FAQ
Q: “店舗”に 店舗ID 単独で UNIQUE を付けてはいけませんか?
A: 【問題文】には“施設内の各店舗”という説明のみで、施設を跨いだ一意性は示されていません。安全策として 施設ID, 内線番号 の複合を選ぶのが正解です。
A: 【問題文】には“施設内の各店舗”という説明のみで、施設を跨いだ一意性は示されていません。安全策として 施設ID, 内線番号 の複合を選ぶのが正解です。
Q: 主キー列以外にも UNIQUE 制約を設けるメリットは?
A: 他にも候補キーが存在し、アプリケーションで重複を禁止したい場合や、索引を高クラスタに保ちたい場合に付けます。本設問の“精算”テーブルには該当しません。
A: 他にも候補キーが存在し、アプリケーションで重複を禁止したい場合や、索引を高クラスタに保ちたい場合に付けます。本設問の“精算”テーブルには該当しません。
関連キーワード: UNIQUE制約、主キー自動索引、候補キー、データ完全性
設問1:表2の作業工程表について、(1)〜(5)に答えよ。
(2)作業 W2(追加制約設計)について、図2中の(a)〜(d)に入れる適切な述語を一つずつ答えよ。(b, cは順不同)
模範解答
a:年齢 < 12
b:年齢区分 = '2'
c:年齢 BETWEEN 12 AND 59
d:年齢 >= 60
解説
解答の論理構成
- 年齢区分の仕様確認
- 【問題文】より引用
子供(12 歳未満):'1'、大人(12 歳以上 60 歳未満):'2'、シニア(60 歳以上):'3'
- 【問題文】より引用
- 検査制約の骨格確認
- 図2の書式
CHECK( ( 年齢区分 = ’1’ AND (a) ) OR ( (b) AND (c) ) OR ( 年齢区分 = ’3’ AND (d) ) )
- 図2の書式
- 3つの OR ブロックに区分を割当
- 1番目:年齢区分 = '1'(子供) ⇒ 年齢は 12 未満 → (a)=年齢 < 12
- 2番目:年齢区分が空欄 (b) と年齢範囲 (c) が空欄
- 区分=大人なので (b)=年齢区分 = '2'
- 大人の年齢は 12 以上 60 未満 ⇒ (c)=年齢 BETWEEN 12 AND 59
- 3番目:年齢区分 = '3'(シニア) ⇒ 年齢は 60 以上 → (d)=年齢 >= 60
- 以上より回答を確定。
誤りやすいポイント
- 12 歳未満 を <= 12 と誤記する。
- 大人の上限を 60 としてしまい、60 歳が両区分に重複。
- OR ブロック2で区分条件 (b) を入れ忘れ、年齢 BETWEEN 12 AND 59 だけにする。
- BETWEEN を使う際に BETWEEN 12 AND 60 と境界値をずらす。
FAQ
Q: BETWEEN ではなく不等号を2つ置く形でも良いですか?
A: 機能面の違いはありませんが、BETWEEN 12 AND 59 の方が境界値を1度だけ書けばよいので保守性が高まります。
A: 機能面の違いはありませんが、BETWEEN 12 AND 59 の方が境界値を1度だけ書けばよいので保守性が高まります。
Q: シニア区分で上限を設ける必要はありませんか?
A: 【問題文】の定義に 60 歳以上 とあるため、上限は不要です。検査制約 (d) は 年齢 >= 60 で十分です。
A: 【問題文】の定義に 60 歳以上 とあるため、上限は不要です。検査制約 (d) は 年齢 >= 60 で十分です。
Q: 年齢区分列だけに制約を掛ければ良い気がしますが?
A: 区分と実年齢の矛盾を防ぐために、両列を同時に評価する複合 CHECK が必要です。これによりデータ整合性が担保されます。
A: 区分と実年齢の矛盾を防ぐために、両列を同時に評価する複合 CHECK が必要です。これによりデータ整合性が担保されます。
関連キーワード: 検査制約、CHECK句、年齢区分、不等号、BETWEEN
設問1:表2の作業工程表について、(1)〜(5)に答えよ。
(3)作業 W4(追加索引設計)に関する表4の索引について、①、②に答えよ。
① 索引1は、ユニーク索引又は非ユニーク索引のどちらに該当するか答えよ。
② 索引2は、高クラスタな索引である。 その理由を35字以内で述べよ。
模範解答
①:非ユニーク索引
②:同じ券番号の行が精算時にまとめて追加されるから
解説
解答の論理構成
- ユニーク/非ユニーク判定
- 【問題文】「(3) 索引は、ユニーク索引と非ユニーク索引に分けられる。」
- 店舗利用表に対し表4「施設 ID, 鍵番号、未精算フラグ」でユニーク制約は設定されていない。ゆえに①は「非ユニーク索引」となる。
- 高クラスタ判定
- 【問題文】「高クラスタな索引: キー値の順番と、キーが指す行の物理的な並び順が一致…隣接するキーが指す行が同じページに格納されている割合が高い。」
- DML2 挿入時、キー列「利用年月日、施設 ID, 券番号」はホスト変数で与えられ同一値で連続挿入される。
- 同一キーが物理的にも隣接するためクラスタ率が高く、索引2は高クラスタ。
誤りやすいポイント
- 「施設 ID, 鍵番号」が鍵だからユニークと思い込む。実際には同一客が複数商品を購入するため重複が起きる。
- クラスタ性を“索引が主キーかどうか”で判断してしまう。実際はデータ配置パターンが重要。
- INSERT 文にSELECT を使った一括挿入時の物理配置への影響を見落とす。
FAQ
Q: ユニーク索引にすれば検索は必ず速くなりますか?
A: 一意性確認が省略できるなどの利点はありますが、高クラスタでない場合はランダムアクセスが増え性能低下もあり得ます。目的に合わせて選択します。
A: 一意性確認が省略できるなどの利点はありますが、高クラスタでない場合はランダムアクセスが増え性能低下もあり得ます。目的に合わせて選択します。
Q: 高クラスタか低クラスタかは統計情報更新後に変わることがありますか?
A: あります。更新・削除・再編成で行が分散すればクラスタ率が下がり、統計情報取得後に「低クラスタ」と評価される場合があります。
A: あります。更新・削除・再編成で行が分散すればクラスタ率が下がり、統計情報取得後に「低クラスタ」と評価される場合があります。
関連キーワード: 索引設計、クラスタ率、ユニーク制約、アクセスパス、INSERT連続挿入
設問1:表2の作業工程表について、(1)〜(5)に答えよ。
(4)作業 W5(表領域設計)について、表5中の(ア)〜(キ)に入れる適切な字句を、表5中の下線部分の用語を用いて答えよ。(カ、キは順不同)
模範解答
ア:最大行長
イ:有効ページ長
ウ:平均行長
エ:見積行数
オ:ページ当たりの平均行数
カ:ページ長
キ:必要ページ数
解説
解答の論理構成
- 手順2
表5には「ページ頭部を除いた有効ページ長(バイト)」とあり、空欄(ア)は “どの行” を格納できるかを判定する基準です。ページに収まるかどうかは行の最大サイズで決めるので(ア)は「最大行長」。 - 手順3
不等式の右辺は “1 ページに確保できる空き領域” を表すので、「有効ページ長 × 空き領域率 ÷ 100」。よって(イ)は「有効ページ長」。 - 手順4
・「ページ当たりの平均行数」は “有効ページ長 ÷ 行長” なので分母(ウ)は「平均行長」。
・「必要ページ数」は “行数 ÷ ページ当たりの平均行数” なので分子(エ)は「見積行数」、分母(オ)は「ページ当たりの平均行数」。
・「テーブルのストレージ所要量」は “ページ長 × ページ数” なので(カ)は「ページ長」、(キ)は「必要ページ数」。 - 以上より、空欄すべての語が確定します(結論参照)。
誤りやすいポイント
- 「平均行長」と「最大行長」を逆に入れる
手順2は “収まるかどうか” の判定なので最大値で評価します。 - 「ページ長」と「有効ページ長」を混同する
有効ページ長はヘッダ領域を除いた値で、計算に使うのはこちらです。 - 「必要ページ数」と「ページ当たりの平均行数」を同じと勘違いする
前者は総量、後者は密度。式の分子・分母を意識することで区別できます。
FAQ
Q: 有効ページ長はどのように求めますか?
A: 表5手順2にあるとおり、RDBMS が選択可能なページ長から “最大行長の行を 1 行以上格納できるもの” を選び、そのページ長からページ頭部(ヘッダ)を差し引いた値が有効ページ長です。
A: 表5手順2にあるとおり、RDBMS が選択可能なページ長から “最大行長の行を 1 行以上格納できるもの” を選び、そのページ長からページ頭部(ヘッダ)を差し引いた値が有効ページ長です。
Q: 空き領域率は必ず設定しなければなりませんか?
A: 可変長列があるテーブルで「挿入時にページ分割を極力避けたい」場合に設定します。固定長だけのテーブルや更新頻度が低いテーブルでは 0%にすることもあります。
A: 可変長列があるテーブルで「挿入時にページ分割を極力避けたい」場合に設定します。固定長だけのテーブルや更新頻度が低いテーブルでは 0%にすることもあります。
Q: 計算式の切捨て・切上げを誤るとどんな影響がありますか?
A: 実際の必要容量より小さい値を見積もってしまい、運用中に領域不足でオンライン再編成が必要になるなど、ダウンタイムや性能低下の要因になります。
A: 実際の必要容量より小さい値を見積もってしまい、運用中に領域不足でオンライン再編成が必要になるなど、ダウンタイムや性能低下の要因になります。
関連キーワード: ページ長、最大行長、有効ページ長、空き領域率、ストレージ見積り
設問1:表2の作業工程表について、(1)〜(5)に答えよ。
(5)作業 W6(DML 性能予測)について、表6中の(ク)〜(コ)に入れる適切な字句を、表5, 6中の下線部分の用語を用いて答えよ。
模範解答
ク:必要ページ数
ケ:探索行数
コ:ページ当たりの平均行数
解説
解答の論理構成
-
表探索の場合
表6 手順2には
・アクセスパスが表探索の場合: 読込みページ数 = (ク)
とあります。表探索はテーブル全ページを読むので、同じ問題文にある表5 手順4
「必要ページ数 = (エ) ÷ (オ)」
で算出する“テーブルを構成するページ総数”をそのまま使うのが自然です。よって
(ク)=「必要ページ数」。 -
索引探索の場合
表6 手順2では
・索引が低クラスタ … 最大読込みページ数 = (ケ)
・索引が高クラスタ … 最小読込みページ数 = (ケ) ÷ (コ)
が示されています。
手順1に
「ページから読み込む探索行数を予測する。結果行数=探索行数とは限らない。」
とあり、ここで出てくる行数がページ数計算に使われる行数(ケ)です。したがって
(ケ)=「探索行数」。
また、行数をページ数に換算するには1ページに何行入るかが必要で、表5 手順4の
「ページ当たりの平均行数 = (イ) ÷ (ウ)」
が該当します。よって
(コ)=「ページ当たりの平均行数」。
誤りやすいポイント
- 「必要ページ数」と「ページ当たりの平均行数」を混同して式が成り立たなくなる。
- (ケ)を「結果行数」と誤答する。問題文に「結果行数=探索行数とは限らない」と強調されている点を見落としやすい。
- 表探索でも索引ページを読むと誤解して読込みページ数を過大評価してしまう。
FAQ
Q: 索引探索時に「探索行数」を使うのはなぜですか?
A: 索引が指す行を抽出するまでに、条件に合わない行を含むページも読み込む可能性があるため物理 I/O の観点では「結果行数」より「探索行数」が妥当だからです。
A: 索引が指す行を抽出するまでに、条件に合わない行を含むページも読み込む可能性があるため物理 I/O の観点では「結果行数」より「探索行数」が妥当だからです。
Q: クラスタ性が高いとページ数が少なく見積もられる仕組みは?
A: 隣接するキーの行が同じページに集まっているため、同じ行数でも必要なページが減ります。式では「探索行数 ÷ ページ当たりの平均行数」で最小値を計算しており、これが高クラスタな索引の効果を表しています。
A: 隣接するキーの行が同じページに集まっているため、同じ行数でも必要なページが減ります。式では「探索行数 ÷ ページ当たりの平均行数」で最小値を計算しており、これが高クラスタな索引の効果を表しています。
関連キーワード: 表探索、索引探索、クラスタ性、ページ当たり行数、I/O見積もり
設問2:〔G部長の指摘〕表2の作業工程表について、(1)〜(3)に答えよ。
(1)指摘1について,Fさんは、他の三つ以上の作業と並行して進められる作業として W3 と W9 の二つを選んだ。 作業順を変えた後の、直前の作業及び直後の作業の作業ID を、それぞれ答えよ。
模範解答
W3:
直前の作業ID:W1
直後の作業ID:W7
W9:
直前の作業ID:W1
直後の作業ID:W10
解説
解答の論理構成
- テーブル確定後に始められる作業を抽出
- 表2より **“W1”**は“CREATE TABLE 文を設計”でテーブル構造を確定する作業。
- 依存関係が“テーブル構造の確定のみ”で済む作業を探すと、
- “W3”“GRANT 文を設計する”
- “W9”“性能測定用データを生成するための設計書を作成”
が該当する。
- それぞれの完了〆切を確認
- **“W3”**の成果物(GRANT 文)は “W7”“DDL など実行”で実行される。
よって “W3” → “W7” の順序が必須。 - **“W9”**の成果物(データ生成プログラム・データ)は **“W10”**でロードされる。
よって “W9” → “W10” の順序が必須。
- **“W3”**の成果物(GRANT 文)は “W7”“DDL など実行”で実行される。
- 直前作業は何か
- どちらも開始条件は“テーブル構造確定”= **“W1”**終了。
- したがって直前は共に “W1”。
- 直後作業は何か
- 先述の〆切より、
- **“W3”**の直後は “W7”
- **“W9”**の直後は “W10”
- 先述の〆切より、
誤りやすいポイント
- “設計”の完了と“実行”の完了を混同し、**“W3 は W7 より後”**と誤解する。
- **“W9”**を“性能測定用データ生成”と読み違えて **“W10”**後に置いてしまう。
- **“W2/W4/W5/W6”**と **“W3/W9”**の並行可否を、作業番号順で思い込む。
FAQ
Q: 「W3」は“追加制約設計(W2)”より後でなくて本当に大丈夫?
A: はい。【問題文】表2で「W3」は“ユーザごと又はロールごとにテーブルのアクセス権限を決める”作業です。制約(UNIQUE、検査など)はアクセス権限に影響しないため、テーブル定義が固まる “W1” 完了後なら問題ありません。
A: はい。【問題文】表2で「W3」は“ユーザごと又はロールごとにテーブルのアクセス権限を決める”作業です。制約(UNIQUE、検査など)はアクセス権限に影響しないため、テーブル定義が固まる “W1” 完了後なら問題ありません。
Q: 「W9」は索引や表領域設計が終わっていなくても開始できますか?
A: できます。性能測定用データの“設計書”と“生成プログラム”を作る段階ではテーブル構造さえ決まっていれば十分で、索引や表領域配置は影響しません。実際にロードする “W10” までにデータが準備できていれば良いのです。
A: できます。性能測定用データの“設計書”と“生成プログラム”を作る段階ではテーブル構造さえ決まっていれば十分で、索引や表領域配置は影響しません。実際にロードする “W10” までにデータが準備できていれば良いのです。
Q: 並行実施で影響し合わないか心配です。
A: 「W3」と「W9」は“設計”フェーズのドキュメント・プログラム作成が主目的なので、他作業の DDL 実行やロード処理とは重ならず、コンフリクトは起きません。レビュー・承認フローを調整すればスムーズに並行できます。
A: 「W3」と「W9」は“設計”フェーズのドキュメント・プログラム作成が主目的なので、他作業の DDL 実行やロード処理とは重ならず、コンフリクトは起きません。レビュー・承認フローを調整すればスムーズに並行できます。
関連キーワード: 依存関係分析、並列工程、DDL, アクセス権限設計、性能測定データ
設問2:〔G部長の指摘〕表2の作業工程表について、(1)〜(3)に答えよ。
(2)指摘2について、アクセスパスが索引探索でなく表探索に決められる DML を、表3から全て答え、表探索に決められる理由を、W8 の作業順の観点から40字以内で述べよ。
模範解答
DML:DML2, DML3
理由:作業W7直後のテーブルは空だと判断されて表探索に決められるから
解説
解答の論理構成
- 作業順の確認
表2より W7「DDL など実行」でテーブルだけが作成され、データ投入は W9・W10。
よって W8「統計情報取得及びアクセスパス確認」はデータ未投入時点で実施される。 - RDBMS の仕様
原文(5)より
「統計情報からテーブルが空 (0行) と判断した場合: 表探索に決められる。」 - DML の判定
• DML2, DML3 は空表対象でありユニーク索引による例外条件に該当しない。
• DML1 は「施設ID, 鍵番号」を等値で指定し、これはテーブル“鍵”の主キーであるため仕様(5)のユニーク索引例外により索引探索。 - したがって、表探索になるのは DML2 と DML3。
理由(40字以内例):
「作業W7直後のテーブルは空と判断され表探索に決まるため」
誤りやすいポイント
- 「空表なら表探索」というルールを見落とし、索引を設計しただけで安心してしまう。
- 主キー列等値検索は統計情報に左右されない点を忘れ、DML1を誤って選択。
- 作業順の前後関係(W8 が W9・W10 より先)を読み違える。
FAQ
Q: 索引を作成していても統計情報が空なら常に表探索ですか?
A: ユニーク索引で主キーと完全一致する等値検索だけは例外で索引探索になります。
A: ユニーク索引で主キーと完全一致する等値検索だけは例外で索引探索になります。
Q: W8 の位置を後ろにずらすとどうなる?
A: データ投入後に統計情報を取得するため、索引活用可否が実際の行数を反映し、想定どおりのアクセスパスを確認できます。
A: データ投入後に統計情報を取得するため、索引活用可否が実際の行数を反映し、想定どおりのアクセスパスを確認できます。
Q: 表探索と索引探索、性能差が最も大きいのはどんなとき?
A: 取得行が全体のごく一部で、かつ索引が高クラスタである場合に読込みページ数の差が顕著になります。
A: 取得行が全体のごく一部で、かつ索引が高クラスタである場合に読込みページ数の差が顕著になります。
関連キーワード: 統計情報、表探索、索引探索、空テーブル、アクセスパス
設問2:〔G部長の指摘〕表2の作業工程表について、(1)〜(3)に答えよ。
(3)(あ)に入れる適切な作業ID を、一つ答えよ。
模範解答
あ:W10
解説
解答の論理構成
- W8 の目的を確認
- 【問題文】“作業 W8 (統計情報取得及びアクセスパス確認) … DML のアクセスパスが想定どおりか確認する。”
- 統計情報が必要とする前提
- 統計情報は行数・分布などの“実データ”を解析して計算される。空テーブルでは誤ったアクセスパスが選択される。
- データが格納される工程を特定
- W10 の説明は【問題文】“ロード実行 – テーブルに性能測定用データをロードする。”
- これによりテーブルが本番想定量で満たされる。
- したがって
- 統計情報を取る W8 は“ロード完了”後、すなわち W10 の後に置くのが最適。
誤りやすいポイント
- 「設計完了直後に統計情報を取得できる」と思い込み、W7 後や W9 後を選んでしまう。
- W9“性能測定用データ設計・データ生成”で“データ生成”という語に引きずられ、ロード前であることを見落とす。
- 索引の作成(W7 内)だけでアクセスパスが確定すると誤解し、統計情報の重要性を軽視する。
FAQ
Q: なぜ W9 ではなく W10 の後なのですか?
A: W9 は“性能測定用データを生成するための設計書作成およびプログラム開発”フェーズであり、まだテーブルにデータは入っていません。実データを投入するのは W10“ロード実行”なので、その後に統計情報を収集します。
A: W9 は“性能測定用データを生成するための設計書作成およびプログラム開発”フェーズであり、まだテーブルにデータは入っていません。実データを投入するのは W10“ロード実行”なので、その後に統計情報を収集します。
Q: 空テーブルで統計情報を取った場合に何が問題になりますか?
A: 【問題文】“統計情報からテーブルが空 (0行) と判断した場合: 表探索に決められる。”とあるように、行が無いとアクセスパスが常に表探索になり、実運用時の性能を正しく予測できません。
A: 【問題文】“統計情報からテーブルが空 (0行) と判断した場合: 表探索に決められる。”とあるように、行が無いとアクセスパスが常に表探索になり、実運用時の性能を正しく予測できません。
Q: 索引を追加した直後に統計情報を取り直すべきですか?
A: はい。索引の有無や列値分布が変わると統計情報は陳腐化します。ロードや大量更新・索引作成後には ANALYZE などで再取得するのがベストプラクティスです。
A: はい。索引の有無や列値分布が変わると統計情報は陳腐化します。ロードや大量更新・索引作成後には ANALYZE などで再取得するのがベストプラクティスです。
関連キーワード: 統計情報、アクセスパス、データロード、物理設計、インデックス
