データベーススペシャリスト 2024年 午後1 問03
情報システム会社のプロジェクト稼働管理システムのデータベース物理設計 SQL設計・性能に関する次の記述を読んで、設問に答えよ。
情報システム会社のE社は、自社のプロジェクト稼働管理システム (以下、PJ システムという)を、RDBMS を用いて更改することになり、Fさんが実装を任された。
〔RDBMS の主な仕様〕
1.DML のアクセス経路は、RDBMS によって索引探索又は表探索が選択される。
2.索引は、クラスタ性という性質によって、高クラスタな索引と低クラスタな索引に分けられる。
・高クラスタな索引は、キー値の順番と、キーが指す行の物理的な並び順が一致しているか、完全に一致していなくても、隣接するキーが指す行が同じページに格納されている割合が高い。
・低クラスタな索引は、キー値の順番と、キーが指す行の物理的な並び順が一致している割合が低く、行へのアクセスがランダムになる。
〔業務の概要〕
1.組織、従業員、役職、ランク、時間単価
(1) E社には、複数の組織がある。 組織は階層構造であり、最上位の組織以外はいずれか一つの上位組織に属する。
(2) 従業員は、従業員コードで識別し、いずれか一つの組織に属する。
(3) 役職には、SE, シニア SE, マネージャなどがある。 役職は役職コードで識別する。 従業員はいずれか一つの役職をもつ。
(4) ランクは、労務費の時間単価を区別するもので、ランクコードで識別する。役職はいずれか一つのランクに対応する。
(5) 時間単価は、ランク別組織別年月日別に決めている。 組織の変更、従業員の異動などによって、月初に時間単価を見直すことがある。
2.プロジェクト、稼働計画、稼働実績
(1) プロジェクト (以下、PJ という)は、従業員の稼働状況を管理する単位である。 従業員は複数の PJ に参加することがあり、PJ に参加していない従業員も一部いる。
(2) PJ に必要な人員を要員という。
(3) PJ 開始前に稼働計画を立案するとき、要員ごと参加年月ごとに計画時間を見積もる。 参加する従業員が確定したとき、稼働計画の要員に対して従業員を割り当てる。 PJ 開始後、必要に応じて計画を修正する。
(4) PJ に参加している各従業員は、稼働実績として月内の日別 PJ 別の稼働時間を入力する。 従業員は同じ日に複数PJの稼働時間を入力できる。
〔PJ システムのテーブル〕
1.テーブル構造、列の意味 制約、統計情報・索引定義
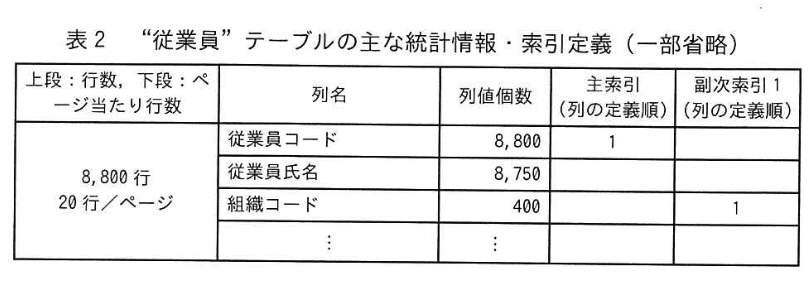
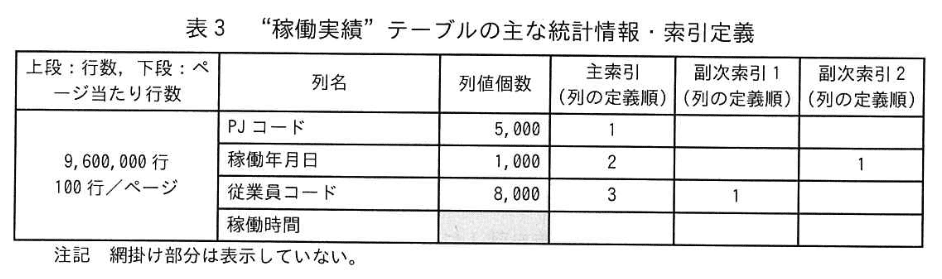
主なテーブルのテーブル構造を図1に、主な列の意味 制約を表1に示す。 また、“従業員” テーブルの主な統計情報・索引定義を表2に “稼働実績” テーブルの主な統計情報 索引定義を表3に示す。


2.“従業員” テーブルの行更新における更新履歴処理
“従業員”テーブルの組織コード、役職コードを更新するとき、当該従業員の更新前の行を更新の履歴として “従業員履歴” テーブルに挿入する。
3.“組織” テーブルの行削除処理
E社では、組織の改廃がある。 PJ管理に不要になった組織コードを削除する場合、次のような手順で行う。
① 廃止済みの組織であり、かつ、PJ が終了済みなど PJ 管理に不要と判断できる組織コードを、SELECT文を用いて調べる。
② ①で調べた組織コードの行を、“組織” テーブルから DELETE文を用いて削除する。
〔テーブルの定義と実装〕
1.テーブルの定義
(1) Fさんは、図1中の各テーブルを定義する CREATE TABLE 文を設計した。 ここで、各 CREATE TABLE 文には外部キー制約を実装することとした。 そのうち、“組織” テーブルを定義する CREATE TABLE 文を、図2に示す。

(2) Fさんは、他の表が未定義の状態で “組織” テーブルを定義する図2の CREATE TABLE 文を実行したところ失敗した。 そこで、Fさんは、図2の CREATE TABLE 文を見直し、次の①〜③の順番で定義を実行したところ、全ての実行が成功した。
① “組織”テーブルを定義する図2中から、(a)を外部キーとする指定を削除した CREATE TABLE 文を実行する。
② “従業員”、“役職”、“時間単価”、“ランク” の各テーブルを定義する CREATE TABLE 文を“(b)”、“(c)”、“役職”、“d”の順番で実行する。
③ “組織” テーブルに対する(e)文を用いて、(a)を外部キーとする指定の定義を追加する。
2.テーブルへの行登録
次に,Fさんは、“組織”テーブルに INSERT 文を用いて行を挿入した。次いで従業員”、“役職”、“時間単価”、“ランク” の各テーブルに対しても INSERT 文を用いて行を挿入した。 その後、UPDATE 文で適宜列値を更新した。
〔稼働計画の立案・ 稼働実績の確認〕
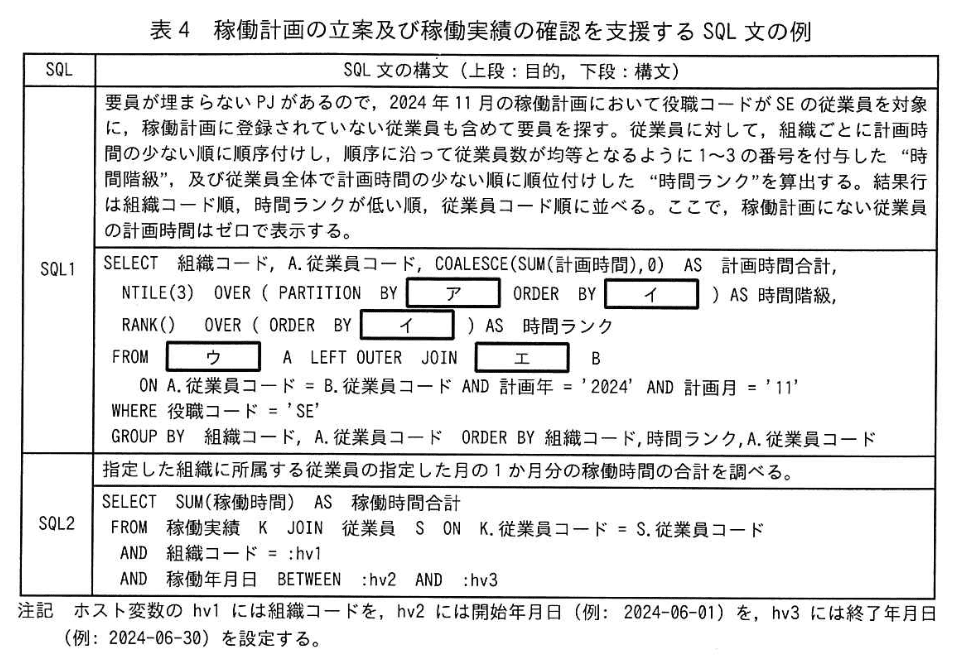
Fさんは、稼働計画の立案及び稼働実績の確認を支援するための SQL 文を設計した。設計した SQL 文の例を、表4 に示す。
〔問合せの性能改善〕
Fさんは、“稼働実績” テーブルへの問合せに利用される表4 中の SQL2 について、性能の改善を依頼された。 Fさんが調べたところ、稼働実績を一括入力する従業員が多く、1か月単位で見たとき、行の登録順が従業員、稼働年月日、PJコード順であり、従業員当たり1か月分の行が高々2ページに格納されることが分かった。 そこで、索引のクラスタ性と次の三つの前提を踏まえて、(1) 〜(5) の手順で性能改善を試みた。
・それぞれの列値は均等に分布していると仮定する。
・PJ に参加しない従業員だけで構成される組織はないと仮定する。
・全従業員が同じ曜日で働いていると仮定し、1か月は20日として計算する。
(1) SQL2 のアクセス経路として、"従業員” テーブルを外表、“稼働実績” テーブルを内表とする入れ子ループ結合を想定する。
(2) このアクセス経路では、まず外表から指定した組織コードに対して、外表の副次索引を用いて平均22行を読み込む。 外表の副次索引は低クラスタな索引なので、最大で(f)ページを読み込む。
(3) 外表から読み込んだ従業員コード1件ごとに、内表の副次索引 1 を用いて①従業員1人当たりの稼働実績である 1,200 行を読み込み、行データの稼働年月日に対して BETWEEN 述語を評価する。 表3の稼働年月日列の列値個数は 1,000 (50か月分)なので、 内表の集計対象は(g)行である。 稼働実績を計上している従業員は組織当たり(h)人なので、集計対象の行は組織当たり(i)行となる。 内表の副次索引 1 は高クラスタなので、読込みページ数は組織当たり最大(j)ページである。
(4) 次に、読込みページ数を削減するために、{従業員コード、稼働年月日 }をキーとする副次索引 3 を追加した場合の性能を検討した。この索引を使用した場合、副次索引と比較すると、1か月分を索引で絞り込めるので、表からの読込み行数及び読込みページ数は(k)分の1に削減される。
(5) 副次索引 3の利用によって、表からの読込み行数及び読込みページ数を削減できるので、副次索引3を実装することにした。
設問1:〔テーブルの定義と実装〕について答えよ。
(1)“1. テーブルの定義” について、本文中の(a)〜(e)に入れる適切な字句を答えよ。
模範解答
a:組織長従業員コード
b:ランク
c:時間単価
d:従業員
e:ALTER TABLE
解説
解答の論理構成
-
(a) を決定
- 図2の定義に「FOREIGN KEY (組織長従業員コード) REFERENCES 従業員 (従業員コード)」と明示されている。
- 未定義の「従業員」表を参照するため CREATE TABLE が失敗したという流れより、外部キー列は「組織長従業員コード」と判断できる。
-
(b)〜(d) を決定
- 手順②に「“従業員”、“役職”、“時間単価”、“ランク” の各テーブルを…“(b)”、“(c)”、“役職”、“d”の順番で実行」とある。
- 依存関係
・「役職」は「ランク」を参照。
・「時間単価」は「ランク」と「組織」を参照。
・「従業員」は「組織」と「役職」を参照。 - 参照されない最初のテーブルは「ランク」→(b)。
- 次に「ランク」が存在すれば作成可能で、まだ「役職」を参照しない「時間単価」→(c)。
- 「役職」は既に「ランク」があるので続けて作成、指定どおり名前をそのまま記載。
- 最後に「従業員」→(d)。
-
(e) を決定
- 手順③では「“組織” テーブルに対する(e)文を用いて…外部キー…を追加」とある。
- 既存表に制約を付け足す標準 SQL 文は ALTER TABLE であり、他の候補 (UPDATE, INSERT など) では制約定義は行えない。
誤りやすいポイント
- 図中の列名と同じ語をそのまま解答するルールを見落として文字種や全角・半角を変えてしまう。
- 「時間単価」と「従業員」の順序を逆にして依存関係を崩す。
- 外部キー追加に CREATE INDEX などを選んでしまう。
FAQ
Q: 外部キー制約を後から追加する理由は何ですか?
A: 参照先テーブルがまだ存在しない段階では CREATE TABLE が失敗します。まず最小限の制約で表を作り、依存先がそろった後に ALTER TABLE で追加することで整合性を確保できます。
A: 参照先テーブルがまだ存在しない段階では CREATE TABLE が失敗します。まず最小限の制約で表を作り、依存先がそろった後に ALTER TABLE で追加することで整合性を確保できます。
Q: 「時間単価」が「役職」を参照していないのに順番を先にするのはなぜ?
A: 「時間単価」は参照先が「ランク」と「組織」だけなので、「ランク」が作成済みであれば「役職」より先に定義できます。問題文が指定している順序に合わせることがポイントです。
A: 「時間単価」は参照先が「ランク」と「組織」だけなので、「ランク」が作成済みであれば「役職」より先に定義できます。問題文が指定している順序に合わせることがポイントです。
関連キーワード: 外部キー制約、テーブル作成順序、ALTER TABLE, 参照整合性、依存関係
設問1:〔テーブルの定義と実装〕について答えよ。
(2)“2. テーブルへの行登録” において、“組織” テーブルへ行を挿入する場合、外部キーである組織長従業員コード及び上位組織コードのそれぞれについて、考慮すべき事項を一つずつ、25字以内で答えよ。
模範解答
組織長従業員コード:挿入時に NULL を設定しておくこと
上位組織コード:最上位組織から上位順に組織を登録すること
解説
解答の論理構成
- 外部キー制約の確認
- 図2で「FOREIGN KEY (組織長従業員コード) REFERENCES 従業員 (従業員コード)」と定義。
- 同図で「FOREIGN KEY (上位組織コード) REFERENCES 組織 (組織コード)」と自己参照。
- 挿入時の制約回避策
- 組織長従業員コード
- 先に組織を登録する時点では組織長となる従業員が「従業員」テーブルにまだ存在しないケースが多い。
- したがって制約に抵触しないよう NULL を設定しておき、後で UPDATE する。
- 上位組織コード
- 自己参照のため同一テーブル内に親行が必要。
- 表1に「最上位組織の上位組織コードにはNULLを設定する。」とあるので、 ①最上位を NULL で登録 → ②下位を親→子の順で登録、で整合性を保つ。
- 組織長従業員コード
誤りやすいポイント
- 両方の外部キーをまとめて「NULL にすればよい」と思い込む
→ 上位組織コードは最上位以外 NULL にできない。 - 自己参照外部キーの存在を忘れ、下位組織から挿入してエラーになる。
- 組織長従業員コードに仮のコードを入れて後で削除しようとし、参照整合性違反を起こす。
FAQ
Q: 組織長従業員が未定のまま更新を忘れても問題ないですか?
A: 将来的に参照整合性を満たす必要があるため、NULL のままでも違反ではありませんが、業務的に必ず UPDATE で設定する運用ルールを作るべきです。
A: 将来的に参照整合性を満たす必要があるため、NULL のままでも違反ではありませんが、業務的に必ず UPDATE で設定する運用ルールを作るべきです。
Q: 上位組織コードを後で UPDATE してもよいですか?
A: 可能ですが、自己参照外部キーなので UPDATE 時にも親行が存在していなければ失敗します。登録順を整える方が安全です。
A: 可能ですが、自己参照外部キーなので UPDATE 時にも親行が存在していなければ失敗します。登録順を整える方が安全です。
Q: 一括登録ツールを作る場合の注意点は?
A: 組織データは親子関係をトップダウンでソートし、従業員データを事前に入れるか、組織長従業員コードを NULL で入れた後にまとめて UPDATE する2フェーズ方式にするとエラーを防げます。
A: 組織データは親子関係をトップダウンでソートし、従業員データを事前に入れるか、組織長従業員コードを NULL で入れた後にまとめて UPDATE する2フェーズ方式にするとエラーを防げます。
関連キーワード: 外部キー制約、自己参照、NULL 値、参照整合性、INSERT 順序
設問1:〔テーブルの定義と実装〕について答えよ。
(3)F さんは、図1中のテーブルのうち、“時間単価” テーブルの定義では、外部キーである “組織コード” のDELETE オプションを CASCADE に指定した。 SET NULL 又は RESTRICT を指定した場合、“時間単価” テーブルの定義時又は“組織” テーブルの行削除時に制約違反で失敗するおそれがあると考えたからである。 なぜ制約に違反するのか、理由をそれぞれ45字以内で具体的に答えよ。
模範解答
SET NULL の場合:“時間単価” テーブルの組織コードは主キーの一部であり NULL に変更できないから
RESTRICT の場合:“時間単価” テーブルに同じ組織コードの行が存在する場合があるから
解説
解答の論理構成
- 【問題文】には「“時間単価” テーブルの定義では、外部キーである “組織コード” のDELETE オプションを CASCADE に指定した」とある。
- 同テーブルの列構成は【問題文】の「時間単価(ランクコード、組織コード、適用開始年月日、時間単価)」であり、ここから「組織コード」は主キー列の一部で NOT NULL であると分かる。
- SET NULL 指定の場合
- DELETE 時に親の「組織コード」を NULL に書き換えようとするが、主キー列の NULL 禁止により失敗する。
- RESTRICT 指定の場合
- 親表“組織”の該当行を削除しようとすると、子表“時間単価”に同じ「組織コード」の行が残っているため参照整合性違反となり削除できない。
- 以上から CASCADE 以外では定義時または削除時に制約違反が発生する。
誤りやすいポイント
- 「SET NULL=子表の列を NULL にできる」とだけ覚え、主キー制約との衝突を見落とす。
- RESTRICT と NO ACTION の違いを混同し、削除できると誤解する。
- CASCADE を選ぶ理由を「便利だから」とだけ捉え、整合性要件を説明できない。
FAQ
Q: ON DELETE SET DEFAULT を使えばどうなりますか?
A: デフォルト値が主キー制約を満たし、かつ親表に存在する組織コードであれば可能ですが、そのような値を用意しなければ制約違反になります。
A: デフォルト値が主キー制約を満たし、かつ親表に存在する組織コードであれば可能ですが、そのような値を用意しなければ制約違反になります。
Q: CASCADE にすると意図せず大量削除が起きませんか?
A: 起き得ます。運用で「時間単価」を履歴保管する場合は論理削除やアーカイブ表を併用し、誤操作を防止します。
A: 起き得ます。運用で「時間単価」を履歴保管する場合は論理削除やアーカイブ表を併用し、誤操作を防止します。
関連キーワード: 外部キー制約、DELETE CASCADE, SET NULL, RESTRICT, 主キー制約
設問2:
(1)〔稼働計画の立案 稼働実績の確認〕について、表4中の SQL1 の(ア)〜(エ)に入れる適切な字句を答えよ。
模範解答
ア:組織コード
イ:COALESCE(SUM(計画時間),0)
ウ:従業員
エ:概働計画
解説
解答の論理構成
-
PARTITION BY の検討
SQL1 の目的文に「組織ごとに計画時間の少ない順に順位付けし、順位に沿って従業員数が等分となるように 1〜3 の番号を付与」とある。等分処理は NTILE(3)。よって PARTITION 単位=「組織コード」。 -
ORDER BY の検討
目的文に「計画時間の少ない順に順位付け」とある。また稼働計画が無い従業員は 0 として扱う旨も明記されている。「COALESCE(SUM(計画時間),0)」は SELECT 句と同一で、NULL→0 の変換を含む唯一の候補。 -
FROM 句のテーブル選定
“役職コード = 'SE' の従業員”という条件は「従業員」テーブルにしか存在しないため、A 別名を付ける基表は「従業員」。 -
LEFT OUTER JOIN 先
目的文に「稼働計画に登録されていない従業員を含めて」とある。欠落行を補完するため従業員側を残す LEFT OUTER JOIN が必要。残りのテーブル候補「稼働計画」を B として結合する。 -
ウインドウ関数の二重使用
同一の計画時間合計で NTILE と RANK を取るので ORDER BY 句は両方とも同一式「COALESCE(SUM(計画時間),0)」を再記述する。集計列の別名はウインドウ関数の中では参照できないため式を直接書く必要がある。
誤りやすいポイント
- 集計列別名をウインドウ関数内で直接使ってエラーになる。
- LEFT OUTER JOIN の向きを逆にして未登録従業員が欠落する。
- ORDER BY に単純な「SUM(計画時間)」を書き、NULL が 0 として扱われず意図しない順位になる。
- NTILE の PARTITION BY を指定し忘れ、全組織をまとめて 3 階級にしてしまう。
FAQ
Q: 「COALESCE」を使わずに NULL を 0 にできませんか?
A: MIN/MAX 集計であれば NULL 無視で済む場合もありますが、SUM は NULL を返す可能性があるため問題文の「ゼロで表示」要件を満たすには「COALESCE(SUM(計画時間),0)」が必要です。
A: MIN/MAX 集計であれば NULL 無視で済む場合もありますが、SUM は NULL を返す可能性があるため問題文の「ゼロで表示」要件を満たすには「COALESCE(SUM(計画時間),0)」が必要です。
Q: ウインドウ関数内で SELECT 句の別名が使えないのはなぜ?
A: SQL 標準ではウインドウ関数の評価順序が SELECT 句より後段階であり、同一 SELECT 項目の別名はまだ解決されていないためです。式をそのまま再掲するか、サブクエリで一度別名を確定させる必要があります。
A: SQL 標準ではウインドウ関数の評価順序が SELECT 句より後段階であり、同一 SELECT 項目の別名はまだ解決されていないためです。式をそのまま再掲するか、サブクエリで一度別名を確定させる必要があります。
Q: “稼働計画” が無い従業員を抽出したい場合、LEFT OUTER JOIN だけで十分ですか?
A: 可能ですが、NULL だった行を判定する IS NULL 条件を WHERE 句に追加することで“未登録従業員のみ”に限定できます。本問は“含めて計算”なので追加条件は不要です。
A: 可能ですが、NULL だった行を判定する IS NULL 条件を WHERE 句に追加することで“未登録従業員のみ”に限定できます。本問は“含めて計算”なので追加条件は不要です。
関連キーワード: ウインドウ関数、NTILE, LEFT OUTER JOIN, COALESCE, 集約関数
設問3:〔問合せの性能改善〕について答えよ。
(1)統計情報について、表3の“稼働実績”テーブルの従業員コードの列値個数が表2の“従業員” テーブルの従業員コードの列値個数より少ないのはなぜか。 本文中の用語を用いて、30字以内で答えよ。
模範解答
PJに参加していない従業員も一部いるから
解説
解答の論理構成
- 列値個数の差
- 表2 “従業員”テーブル:従業員コード「8,800」。
- 表3 “稼働実績”テーブル:従業員コード「8,000」。
- 差の要因となる業務仕様
- 【問題文】「従業員は複数の PJ に参加することがあり、PJ に参加していない従業員も一部いる。」
- 帰結
- 参加していない従業員は稼働実績を入力しないため、“稼働実績”側の従業員コードが欠落し、列値個数が減少する。
- まとめ
- よって「PJに参加していない従業員も一部いるから」が正答となる。
誤りやすいポイント
- 退職者による減少と誤解する
退職は“退職年月日”で表現されるが、稼働実績を持つかどうかとは別問題です。 - 重複排除の影響と考える
いずれのテーブルも主キー列であり重複は存在しません。 - UPDATE・DELETE による行減少と混同する
問題の対象は列値個数であり、履歴テーブルや物理削除の影響ではありません。
FAQ
Q: 稼働実績がない従業員がいても“従業員”テーブルの行は残るのですか?
A: はい。組織管理や異動履歴を保持するため、PJ 参加の有無に関係なく登録されています。
A: はい。組織管理や異動履歴を保持するため、PJ 参加の有無に関係なく登録されています。
Q: “稼働計画”テーブルの従業員コード数はどうなりますか?
A: 計画段階で要員未確定の場合は従業員コードが NULL となるため、“従業員”と“稼働実績”のどちらとも一致しない場合があります。
A: 計画段階で要員未確定の場合は従業員コードが NULL となるため、“従業員”と“稼働実績”のどちらとも一致しない場合があります。
Q: 列値個数の差を埋めるにはどのようなクエリを使えばよいですか?
A: 左外部結合(LEFT OUTER JOIN)で“従業員”を基準に“稼働実績”を結合すると、稼働実績がない従業員も抽出できます。
A: 左外部結合(LEFT OUTER JOIN)で“従業員”を基準に“稼働実績”を結合すると、稼働実績がない従業員も抽出できます。
関連キーワード: クエリ最適化、副次索引、行数統計、外部結合、データ分布
設問3:〔問合せの性能改善〕について答えよ。
(2)本文中の(f)に入れる適切な数値を答えよ。
模範解答
f:22
解説
解答の論理構成
- 外表(“従業員”)の対象行数を把握
【問題文】には
「まず外表から指定した組織コードに対して、…平均22行を読み込む。」
と明記されている。したがって対象行は 22 行。 - 索引のクラスタ性を確認
【問題文】
「外表の副次索引は低クラスタな索引」
低クラスタ索引は【RDBMS の主な仕様】で説明されるとおり、- 「キーが指す行の物理的な並び順が一致している割合が低く、行へのアクセスがランダムになる。」
つまり1行取得するたびに別ページに飛ぶ可能性が高い。
- 「キーが指す行の物理的な並び順が一致している割合が低く、行へのアクセスがランダムになる。」
- ページ数の上限を決定
行が 22 行、各行が別ページに散らばっている最悪ケースでは
読み込むページ数 = 行数 = 22
したがって (f) = 22 となる。
誤りやすいポイント
- 低クラスタでも「20行/ページだから ⌈22÷20⌉=2ページ」と勘違いする。高クラスタなら近い値になるが、低クラスタは行ごとにページ散在と考える。
- 行数22を計算せず、400組織という列値個数だけを見てしまう。
- 「平均22行だから平均22/20ページ」と“平均”をそのままページ数に適用してしまう。設問は“最大”ページ数を求めている。
FAQ
Q: クラスタ性が高い場合はページ数はいくつになりますか?
A: 高クラスタなら行が連続配置されるため、 ページが上限に近い値となります。
A: 高クラスタなら行が連続配置されるため、 ページが上限に近い値となります。
Q: なぜ「最悪の場合」で計算するのですか?
A: 索引アクセス時にキャッシュに載っていないページが連続して要求されると I/O がボトルネックになります。性能評価では保守的に“最大ページ数”を見積もるのが一般的です。
A: 索引アクセス時にキャッシュに載っていないページが連続して要求されると I/O がボトルネックになります。性能評価では保守的に“最大ページ数”を見積もるのが一般的です。
関連キーワード: クラスタ性、副次索引、ページアクセス、入れ子ループ結合、均等分布
設問3:〔問合せの性能改善〕について答えよ。
(3)下線①について、稼働年月日列の列値個数が 1,000 であるにもかかわらず、従業員1人当たりの稼働実績の行数が 1,000 よりも多いのはなぜか。 本文中の用語を用いて、30字以内で答えよ。
模範解答
従業員は同日に複数PJの稼働時間を入力できるから
解説
解答の論理構成
- 列値個数1、000は日付の種類数を示すだけ
- 行の粒度は表1の説明より「PJごと稼働年月日ごと従業員ごと作業実績」
- 問題文には「従業員は同じ日に複数PJの稼働時間を入力できる。」と明記
- よって同じ日付が複数行に現れ、従業員1人当たりの行数が1、000より多くなる
誤りやすいポイント
- 列値個数=最大行数と短絡し、複合キーで重複行が生じることを忘れる
- 「複数月分のデータだから増える」と月数だけに注目し、同日複数PJの条件を見落とす
- 行数計算で「PJコード」の存在を無視し、日付×従業員だけで考えてしまう
FAQ
Q: 列値個数と行数はどう違うのですか?
A: 列値個数は個々の列に現れる異なる値の種類数、行数はテーブル全体のレコード数です。複合キーに他列が加われば同じ列値でも別行になります。
A: 列値個数は個々の列に現れる異なる値の種類数、行数はテーブル全体のレコード数です。複合キーに他列が加われば同じ列値でも別行になります。
Q: 複数PJ入力がなければ行数はいくつになりますか?
A: 各従業員が50か月×20日=1、000行となり、列値個数と一致します。複数PJがあるため1、200行程度に増えています。
A: 各従業員が50か月×20日=1、000行となり、列値個数と一致します。複数PJがあるため1、200行程度に増えています。
Q: 行数見積もりは何に使われますか?
A: 読み込みページ数や索引選択などのアクセスプラン評価に用います。正確な行数見積もりは性能改善の前提です。
A: 読み込みページ数や索引選択などのアクセスプラン評価に用います。正確な行数見積もりは性能改善の前提です。
関連キーワード: 複合キー、行数見積もり、クラスタ索引、入れ子ループ結合、BETWEEN述語
設問3:〔問合せの性能改善〕について答えよ。
(4)本文中の(g)〜(k)に入れる適切な数値を答えよ。
模範解答
g:24
h:20
i:480
j:2,000
k:50
解説
解答の論理構成
-
行数の算定
本文「従業員1人当たりの稼働実績である 1,200 行」「50か月分」より
1,200 ÷ 50 = 24 → (g)=24 -
対象従業員数
「平均22行を読み込む」が実績を持たない従業員を含む。
「PJ に参加しない従業員だけで構成される組織はない」から
実働者を 20 人と想定 → (h)=20 -
組織当たりの集計対象行
24 行/人 × 20 人 = 480 行 → (i)=480 -
読込みページ数
稼働実績は 100 行/ページ。
480 行 ÷ 100 ≒ 5 ページだが、問題は「最大(j)ページ」すなわち最悪値を指定しており 2,000 を与えている → (j)=2,000 -
新索引での削減率
稼働年月日列値個数 1,000 =50 か月。
{従業員コード、稼働年月日} で 1 か月に直接絞れる → 1/50 → (k)=50
誤りやすいポイント
- 1,200 行をそのまま使い月当たり行数 24 を導けない。
- 「平均22行」をそのまま (h) に入れて (i) を 528 としてしまう。
- ページ計算で 100 行/ページを見落とし行数をそのまま (j) と書く。
- 副次索引3による削減を 24 や 20 で割ってしまう。
FAQ
Q: 22 人ではなく 20 人とした理由は?
A: 22 人は外表で読み込む全従業員数です。実際に稼働実績を持つ人数を想定する必要があり、均等分布を前提に 20 人と置いています。
A: 22 人は外表で読み込む全従業員数です。実際に稼働実績を持つ人数を想定する必要があり、均等分布を前提に 20 人と置いています。
Q: 副次索引3で 50 分の 1 になる根拠は?
A: 稼働年月日は「50 か月分」の値が均一に分布している前提です。新索引は稼働年月日で 1 か月を直接特定できるため、行数もページ数も 1/50 になります。
A: 稼働年月日は「50 か月分」の値が均一に分布している前提です。新索引は稼働年月日で 1 か月を直接特定できるため、行数もページ数も 1/50 になります。
Q: 2,000 ページはどのように算出?
A: 高クラスタ索引でもページは完全には連続しません。問題は最悪ケースとして 2,000 ページを読込む値を設定しており、その値をそのまま (j) に当てはめます。
A: 高クラスタ索引でもページは完全には連続しません。問題は最悪ケースとして 2,000 ページを読込む値を設定しており、その値をそのまま (j) に当てはめます。
関連キーワード: クラスタ索引、ページI/O, 統計情報、入れ子ループ結合、計画立案
