データベーススペシャリスト 2023年 午後1 問03
農業用機器メーカーによる観測データ分析システムの SQL 設計、性能、運用に関する次の記述を読んで、設問に答えよ。
ハウス栽培農家向けの農業用機器を製造・販売する B社は、農家の DX を支援する目的で、RDBMS を用いたハウス栽培のための観測データ分析システム (以下、分析システムという)を構築することになり、運用部門のCさんが実装を担当した。
〔業務の概要〕
1.顧客、圃場、農事日付
(1) 顧客は、ハウス栽培を行う農家であり、顧客IDで識別する。
(2) 圃場は、農家が農作物を育てる場所の単位で、圃場IDで識別する。 圃場には一つの農業用ハウス (以下、ハウスという) が設置され、トマト、イチゴなどの農作物が1種類栽培される。
(3) 圃場の日出時刻と日没時刻は、圃場の経度、緯度、標高によって日ごとに変わるが、あらかじめ計算で求めることができる。
(4) 日出時刻から翌日の日出時刻の1分前までとする日付を、農事日付という。農家は、農事日付に基づいて作業を行うことがある。
2.制御機器・センサー機器、統合機器、観測データ、積算温度
(1) 圃場のハウスには、ハウスの天窓の開閉、カーテン、暖房、潅水などを制御する制御機器、及び温度 (気温)、湿度、水温、地温、日照時間、炭酸ガス濃度などを計測するセンサー機器が設置される。
(2) 顧客は、圃場の一角に設置した B社の統合環境制御機器 (以下、統合機器という)を用いて、ハウス内の各機器を監視し、操作する。 もし統合機器が何か異常を検知すれば、顧客のスマートフォンにその異常を直ちに通知する。
(3) 統合機器は、各機器の設定値と各センサー機器が毎分計測した値を併せて記録した1件のレコードを、B社の分析システムに送り、蓄積する。 分析システムは、蓄積されたレコードを観測データとして分析しやすい形式に変換し、計測された日付ごと時分ごと圃場ごとに1行を “観測” テーブルに登録する。
(4) 農家が重視する積算温度は、1日の平均温度をある期間にわたって合計したもので、生育の進展を示す指標として利用される。 例えば、トマトが開花してから完熟するまでに必要な積算温度は、1,000〜1,100℃といわれている。
(5) 分析システムの目標は、対象にする圃場を現状の 100 圃場から段階的に増やし、将来 1,000圃場で最長5年間の観測データを分析できることである。
〔分析システムの主なテーブル〕
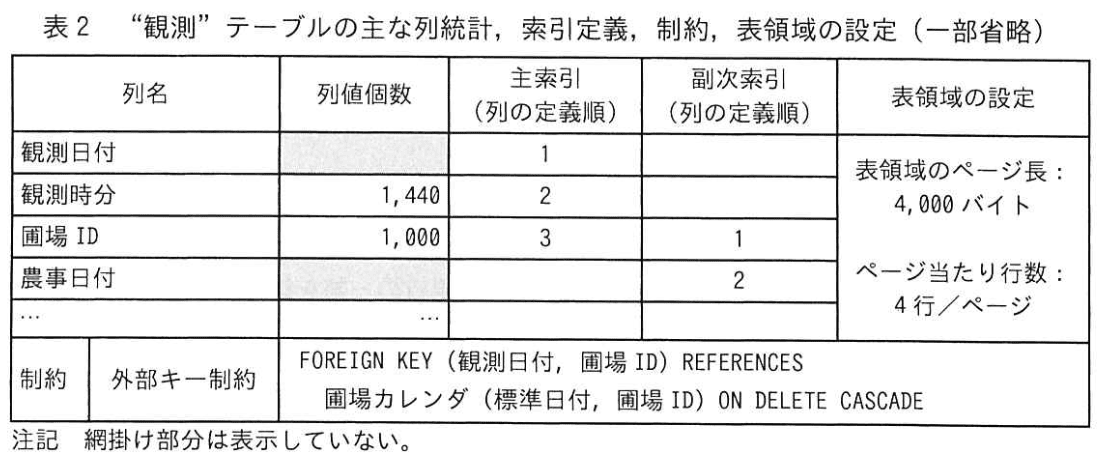
Cさんが設計した主なテーブル構造を図1に、主な列の意味・ 制約を表1に示す。
また、“観測” テーブルの主な列統計、索引定義、制約、表領域の設定を表2に示す。


〔RDBMS の主な仕様〕
1.行の挿入 削除、再編成
(1) 行を挿入するとき、表領域の最後のページに行を格納する。 最後のページに空き領域がなければ、新しいページを表領域の最後に追加し、行を格納する。
(2) 最後のページを除き、行を削除してできた領域は、行の挿入に使われない。
(3) 再編成では、削除されていない全行をファイルにアンロードした後、初期化した表領域にその全行を再ロードし、併せて索引を再作成する。
2.区分化
(1) テーブルごとに一つ又は複数の列を区分キーとし、区分キーの値に基づいて表領域を物理的に分割することを、区分化という。
(2) 区分方法には次の2種類がある。
・レンジ区分 区分キーの値の範囲によって行を区分に分配する。
・ハッシュ区分: 区分キーの値に基づき、RDBMS が生成するハッシュ値によって行を一定数の区分に分配する。 区分数を変更する場合、全行を再分配する。
(3) レンジ区分では、区分キーの値の範囲が既存の区分と重複しなければ区分を追加でき、任意の区分を切り離すこともできる。 区分の追加、切離しのとき、区分内の行のログがログファイルに記録されることはない。
(4) 区分ごとに物理的に分割される索引 (以下、分割索引という)を定義できる。区分を追加したとき、当該区分に分割索引が追加され、また、区分を切り離したとき、当該区分の分割索引も切り離される。
〔観測データの分析〕
1.観測データの分析
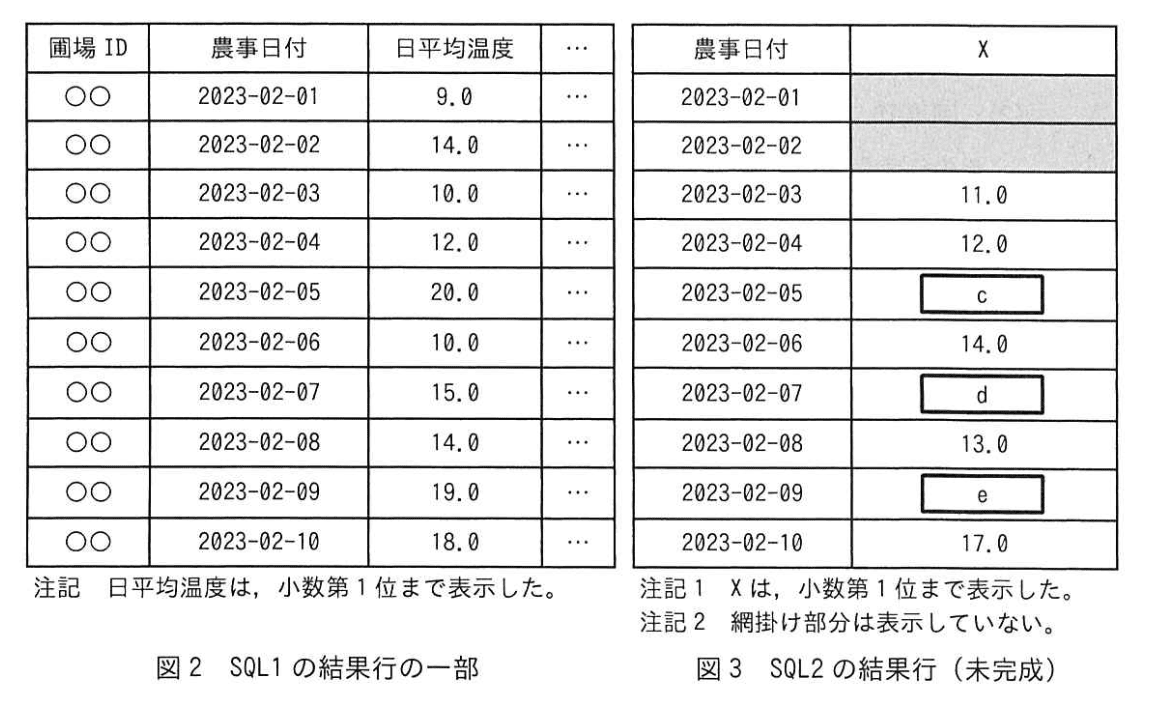
分析システムは、農家の要望に応じて様々な観点から観測データを分析し、その結果を農家のスマートフォンに表示する予定である。 Cさんが設計した観測データを分析する SQL 文の例を表3のSQL1 に、結果行の一部を後述する図2に示す。

2.SQL文の改良
顧客に表3の SQL1 の日平均温度を折れ線グラフにして見せたところ、知りたいのは日々の温度の細かい変動ではなく、変動の傾向であると言われた。 そこでCさんは、折れ線グラフを滑らかにするため、表4のSQL2のように改良した。 SQL2 が利用した表3の SQL1 の結果行の一部を図2に、SQL2の結果行を図3に示す。

3.積算温度を調べる SQL 文
農家は、栽培している農作物の出荷時期を予測するために積算温度を利用する。
Cさんが設計した積算温度を調べる SQL 文を、表5のSQL3 に示す。

〔“観測” テーブルの区分化〕
1.物理設計の変更
Cさんは、大容量になる “観測” テーブルの性能と運用に懸念をもったので、次のようにテーブルの物理設計を変更し、性能見積りと年末処理の見直しを行った。
(1) 表領域のページ長を大きくすることで1ページに格納できる行数を増やす。
(2) 圃場IDごとに農事日付の1月1日から12月31日の値の範囲を年度として、その年度を区分キーとするレンジ区分によって区分化する。
(3) 新たな圃場を追加する都度、当該圃場に対してそのときの年度の区分を1個追加する。
2.性能見積り
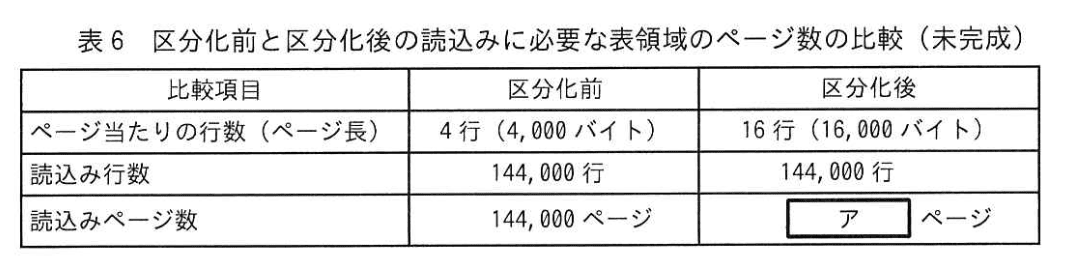
表5のSQL3について 表2に示した副次索引から100日間の観測データ 144,000行を読み込むことを仮定した場合の読込みに必要な表領域のページ数を、区分化前と区分化後のそれぞれに分けて見積もり、表6に整理して比較した。
3.年末処理の見直し
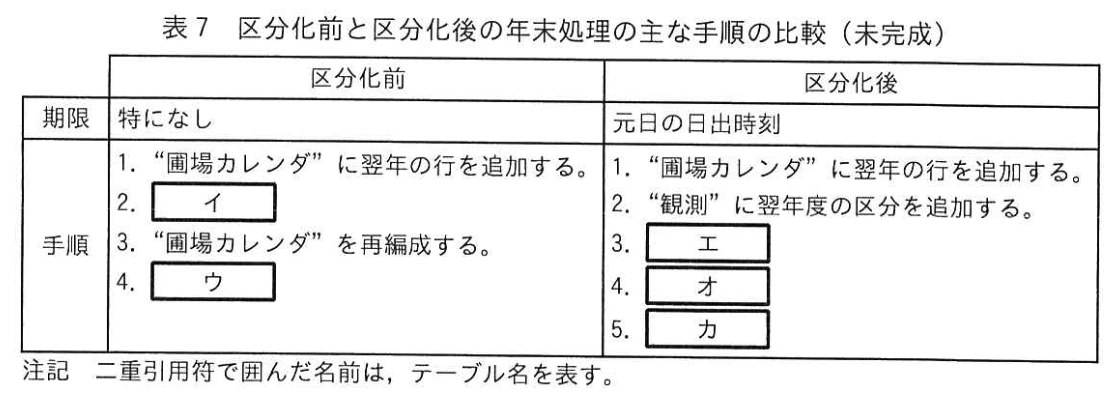
5年以上前の不要な行を効率よく削除し、表領域を有効に利用するための年末処理の主な手順を、区分化前と区分化後のそれぞれについて検討し、表7に整理した。
設問1:〔観測データの分析〕について答えよ。
(1)表3中の(a)、(b)に入れる適切な字句を答えよ。
模範解答
a:圃場ID, 農事日付、AVG(分平均温度)
b:圃場ID, 農事日付
解説
解答の論理構成
- 問題の要求を確認
- 【問題文】「圃場ごと農事日付ごとに1日の平均温度と行数を調べる。」
- 必要な列と集約関数を決定
- 1日の平均温度 → AVG(分平均温度)
- 行数 → COUNT(*)
- SELECT 句の構成
- 答えるべき列は「圃場ID, 農事日付」と平均温度(集約関数)と行数。
- よって (a) = 圃場ID, 農事日付、AVG(分平均温度)
- GROUP BY 句の構成
- 平均と行数を求める単位は「圃場ID, 農事日付」。
- 集約関数以外で SELECT に書いた列を列挙する。
- よって (b) = 圃場ID, 農事日付
誤りやすいポイント
- AVG の対象列を 分平均温度 ではなく 日平均温度 と書いてしまう。
- GROUP BY に AVG(分平均温度) を入れてしまい文法エラーになる。
- 観測日付 をグループ化対象に含めてしまい、日単位集計にならない。
FAQ
Q: COUNT() も SELECT 句に含めるのでは?
A: 含めますが、設問で空欄指定されているのは (a) と (b) だけです。COUNT() は問題文に既に書かれています。
A: 含めますが、設問で空欄指定されているのは (a) と (b) だけです。COUNT() は問題文に既に書かれています。
Q: AVG の結果に別名を付けなくてよいのですか?
A: 実運用では AS 日平均温度 などと別名を付けますが、本設問は構文の穴埋めが目的なので別名は必須ではありません。
A: 実運用では AS 日平均温度 などと別名を付けますが、本設問は構文の穴埋めが目的なので別名は必須ではありません。
Q: WITH 句 R の列順序は答案に影響しますか?
A: いいえ。WITH R (圃場ID, 農事日付、日平均温度、行数) と列名が示されているため、(a) で選ぶ列の並びが正しければ列順は自動的に合致します。
A: いいえ。WITH R (圃場ID, 農事日付、日平均温度、行数) と列名が示されているため、(a) で選ぶ列の並びが正しければ列順は自動的に合致します。
関連キーワード: GROUP BY, 集約関数、ウィンドウ関数、WITH句、SQL構文
設問1:〔観測データの分析〕について答えよ。
(2)SQL1 の結果について、1日の行数は、1,440 行とは限らない。 その理由を30字以内で答えよ。 ただし、何らかの不具合によって分析システムにレコードが送られない事象は考慮しなくてよい。
模範解答
・日時刻が日々異なり1日の分数が同じとは限らないから
・農事日付の1日は1,440分とは限らないから
解説
解答の論理構成
- センサーは「毎分」計測し、分析システムはその 1 分単位データを “観測” テーブルに登録します。
- SQL1 は GROUP BY で (a) (圃場ID, 農事日付) をまとめ、COUNT(*) で 1 日分のレコード数を算出します。
- 【問題文】には
「農事日付…1日の区切りを、圃場の日出時刻から翌日の日出時刻の1分前までとする」とあります。 - 日出時刻は同じ圃場でも経度・緯度・季節で変わる(【業務の概要】1.(3))ため、農事日付 1 日の長さ(分数)は
- 夏:24 時間より長い
- 冬:24 時間より短い
- よって、1 日当たりの計測回数(行数)は 1,440 分を基準に増減するため、「1,440 行とは限らない」が正答となります。
誤りやすいポイント
- 標準日付=24 時間と早合点し、農事日付の可変性を見落とす。
- 行数の不足を通信障害などの「不具合」で説明してしまう(問題文で除外条件と明記)。
- 日出時刻が固定だと思い込み、季節変動の影響を忘れる。
FAQ
Q: 標準日付と農事日付はどちらを使うべきですか?
A: 「農事日付で作業することがある」と明記されているため、農業分析では農事日付が重要です。標準日付は一般的な 0 時区切りの集計に使います。
A: 「農事日付で作業することがある」と明記されているため、農業分析では農事日付が重要です。標準日付は一般的な 0 時区切りの集計に使います。
Q: 日出時刻の計算はリアルタイムで行うのですか?
A: 圃場ごとに経度・緯度・標高が登録されているので、事前計算し “圃場カレンダ” に格納し参照します。
A: 圃場ごとに経度・緯度・標高が登録されているので、事前計算し “圃場カレンダ” に格納し参照します。
Q: 1 日行数が変動しても SQL1 の平均値は正しいですか?
A: SQL1 は AVG(分平均温度) を使うため分数の多少にかかわらず平均値自体は正しく求められますが、行数を確認するときは変動を考慮する必要があります。
A: SQL1 は AVG(分平均温度) を使うため分数の多少にかかわらず平均値自体は正しく求められますが、行数を確認するときは変動を考慮する必要があります。
関連キーワード: 日出時刻、可変長データ、時系列データ、集計関数、分単位計測
設問1:〔観測データの分析〕について答えよ。
(3)図3中の(c)〜(e)に入れる適切な字句を答えよ。
模範解答
c:14.0
d:15.0
e:16.0
解説
解答の論理構成
- SQL2 の計算仕様を確認
【問題文】「AVG(日平均気温度) OVER ( ORDER BY 農事日付 ROWS BETWEEN 2 PRECEDING AND CURRENT ROW )」
→ 直前2行と現在行、合計3行の算術平均を算出。 - 元データを列挙
図2より
2023-02-01: 9.0 / 02: 14.0 / 03: 10.0 / 04: 12.0 / 05: 20.0 / 06: 10.0 / 07: 15.0 / 08: 14.0 / 09: 19.0 / 10: 18.0 - 各行の移動平均
- 2023-02-03 → (9.0+14.0+10.0)/3 = 11.0(図3に提示済み)
- 2023-02-04 → (14.0+10.0+12.0)/3 = 12.0(提示済み)
- 2023-02-05 → (10.0+12.0+20.0)/3 = 14.0 ⇒ (c)
- 2023-02-06 → (12.0+20.0+10.0)/3 = 14.0(提示済み)
- 2023-02-07 → (20.0+10.0+15.0)/3 = 15.0 ⇒ (d)
- 2023-02-08 → (10.0+15.0+14.0)/3 = 13.0(提示済み)
- 2023-02-09 → (15.0+14.0+19.0)/3 = 16.0 ⇒ (e)
- よって (c) 14.0、(d) 15.0、(e) 16.0 が確定。
誤りやすいポイント
- PRECEDING を「日前」ではなく「行数」基準と誤読する。
- 3日平均なのに“列数が2+1=3”であることを忘れ、2日平均で計算してしまう。
- 先頭行・2行目も3行平均に含めてしまい図3との対応が取れなくなる。
FAQ
Q: ROWS BETWEEN 2 PRECEDING と RANGE BETWEEN 2 PRECEDING の違いは?
A: ROWS は物理行数、RANGE は値の範囲です。本問では日付の連続性が保証されておらず、値の範囲指定は不適切なため ROWS を使用しています。
A: ROWS は物理行数、RANGE は値の範囲です。本問では日付の連続性が保証されておらず、値の範囲指定は不適切なため ROWS を使用しています。
Q: 先頭2行がない場合でも AVG は動作しますか?
A: 行が不足する場合は存在する行のみで平均を取り、行数で割るため数値が歪むことはありません。本問ではその部分を網掛けで非表示にしています。
A: 行が不足する場合は存在する行のみで平均を取り、行数で割るため数値が歪むことはありません。本問ではその部分を網掛けで非表示にしています。
Q: 行を追加しても SQL を変えずに移動平均幅を変えたいのですが?
A: 幅をパラメータ化したビューやストアドプロシージャを用意し、2 PRECEDING の数値を変数化すると保守が容易になります。
A: 幅をパラメータ化したビューやストアドプロシージャを用意し、2 PRECEDING の数値を変数化すると保守が容易になります。
関連キーワード: 窓関数、移動平均、OVER句、行分析、データ平滑化
設問1:〔観測データの分析〕について答えよ。
(4)図5中の(f)〜(h)に入れる適切な字句を答えよ。
模範解答
f:日平均温度
g:圃場ID
h:・農事日付
・圃場ID, 農事日付
解説
解答の論理構成
- 目的確認
【問題文】「指定した農事日付の期間について、圃場ごと農事日付ごとの積算温度を調べる。」
⇒ “圃場ごと”=PARTITION BY、“農事日付ごとに累積”=ORDER BY 農事日付 が必要。 - 加算対象(f)
積算温度は【業務の概要】「1日の平均温度をある期間にわたって合計したもの」。
SQL1 の CTE R が生成する列は 日平均温度 なので、(f)=日平均温度。 - 区分列(g)
“圃場ごと” の累積を別々に計算させるには PARTITION BY に 圃場ID を指定。 - 並べ替え列(h)
日付順に累積するため ORDER BY 農事日付。
厳密にソート安定性を考え ORDER BY 圃場ID, 農事日付 も正しく、設問が両方を解と認めている。 - 以上より
f:日平均温度
g:圃場ID
h:農事日付(又は 圃場ID, 農事日付)
誤りやすいポイント
- 日平均気温 と 日平均温度 の表記ゆれをそのまま書いて減点。原文では SQL1 列名が 日平均温度。
- PARTITION BY 農事日付 としてしまい、圃場をまたいで累積してしまう。
- 累積窓の範囲句を確認せず ROWS BETWEEN 2 PRECEDING … と混同する。積算は “UNBOUNDED PRECEDING” が必須。
FAQ
Q: なぜ 日平均温度 でなければいけないのですか?
A: 積算温度の定義が「日平均温度の合計」だからです。【業務の概要】で明示されています。
A: 積算温度の定義が「日平均温度の合計」だからです。【業務の概要】で明示されています。
Q: ORDER BY 圃場ID, 農事日付 と書くと重複キーになりませんか?
A: PARTITION BY 圃場ID で圃場ごとに分かれるので、各パーティション内では 農事日付 が一意となり問題ありません。ソートキーを冗長に書いても正しく動作します。
A: PARTITION BY 圃場ID で圃場ごとに分かれるので、各パーティション内では 農事日付 が一意となり問題ありません。ソートキーを冗長に書いても正しく動作します。
Q: PARTITION BY を省略しても答えは出ますか?
A: いいえ。全圃場の行が一つのパーティションになり、圃場を跨いだ累積値が計算されるため誤結果となります。
A: いいえ。全圃場の行が一つのパーティションになり、圃場を跨いだ累積値が計算されるため誤結果となります。
関連キーワード: 窓関数、PARTITION BY, ORDER BY, 累積集計、列名の厳密性
設問2:〔“観測” テーブルの区分化〕について答えよ。
(1)C さんは、区分方法としてハッシュ区分を採用しなかった。 その理由を 35字以内で答えよ。
模範解答
・区分を追加する都度、全体の行の再分配が必要になるから
・同じ圃場に異なる圃場の観測データが混在する可能性があるから
・レンジ区分でも区分の行数をほぼ同じにする利点が得られるから
解説
解答の論理構成
- 本文の仕様確認
- ハッシュ区分は「区分キーの値に基づき、RDBMS が生成するハッシュ値によって行を一定数の区分に分配する。 区分数を変更する場合、全行を再分配する。」
- レンジ区分は「区分キーの値の範囲が既存の区分と重複しなければ区分を追加でき、任意の区分を切り離すこともできる。」
- 運用要件
- 「新たな圃場を追加する都度、当該圃場に対してそのときの年度の区分を1個追加する。」
- 年度が進むたびに5年以上前の区分を削除(切離し)する。
- 問題点の導出
①区分を毎年・毎圃場追加→ハッシュ区分ではそのたびに「全行を再分配」⇒実運用で長時間停止。
②削除時にも同様の再分配が必要でストレージ/CPU負荷が高い。
③圃場単位のデータが区分内で混在し、物理削除しにくい。 - よって「ハッシュ区分は採用しない」→35字以内の理由文につながる。
誤りやすいポイント
- 「全行再分配」は区分追加・削除の両方で起こることを忘れる。
- レンジ区分でも行が均等にばらけると誤解し、メリットを過小評価する。
- 圃場単位の管理しやすさ(混在しない)よりもアクセス性能のみで判断する。
FAQ
Q: レンジ区分でも行移動が全くないのですか?
A: 本文にある通り「区分を追加したとき、区分内の行のログがログファイルに記録されることはない」。つまり既存行は移動せず、新区分に今後挿入される行だけが入ります。
A: 本文にある通り「区分を追加したとき、区分内の行のログがログファイルに記録されることはない」。つまり既存行は移動せず、新区分に今後挿入される行だけが入ります。
Q: ハッシュ区分を選んでも副次索引で速く読めるのでは?
A: 参照性能は得られても、頻繁な区分追加・切離し時に「全行を再分配する」ためダウンタイムと I/O が大きく、トータルで非効率です。
A: 参照性能は得られても、頻繁な区分追加・切離し時に「全行を再分配する」ためダウンタイムと I/O が大きく、トータルで非効率です。
Q: 区分数を固定すればハッシュ区分でも良い?
A: 本システムでは圃場や年度が増えるたびに区分が増えるため固定は非現実的です。
A: 本システムでは圃場や年度が増えるたびに区分が増えるため固定は非現実的です。
関連キーワード: レンジ区分、ハッシュ区分、全行再分配、区分追加、パーティション管理
設問2:〔“観測” テーブルの区分化〕について答えよ。
(2)表6中の(ア)に入れる適切な数値を答えよ。
模範解答
ア:9,000
解説
解答の論理構成
- 区分化後の表領域条件を確認
- 【問題文 表6】ページ当たりの行数(ページ長)「16行(16,000バイト)」
- 同じ表で読込み行数「144,000行」
- 必要ページ数を計算
- 式:必要ページ数 = 読込み行数 ÷ 1ページ当たり行数
- 代入:144,000 ÷ 16 = 9,000
- 端数チェック
- 144,000は16の倍数のため端数なし。
- 結果として(ア)に入る値は 9,000ページ
誤りやすいポイント
- 区分化前の数値(4行/ページ)と混同する。
- 端数が出た場合の切上げ有無を考えずにそのまま整数部分だけを書く。
- ページ当たり行数ではなくページ長の「16,000バイト」で計算を始めてしまう。
FAQ
Q: 144,000行を副次索引で取得することとページ数計算は関係ありますか?
A: 取得方法にかかわらず、表領域から読み込む物理ページ数は行数とページ当たり行数の比で決まります。索引は行抽出の論理経路であり、ページ数計算には直接影響しません。
A: 取得方法にかかわらず、表領域から読み込む物理ページ数は行数とページ当たり行数の比で決まります。索引は行抽出の論理経路であり、ページ数計算には直接影響しません。
Q: 端数が出た場合はどう処理しますか?
A: 1ページに収まらない行が1行でもあれば1ページ追加する(切上げ)必要があります。本問では 144,000 ÷ 16 が整数なので切上げ不要です。
A: 1ページに収まらない行が1行でもあれば1ページ追加する(切上げ)必要があります。本問では 144,000 ÷ 16 が整数なので切上げ不要です。
Q: ページ長を大きくすると必ず性能が向上しますか?
A: 行単価のディスク I/O は減りますが、メモリ消費やキャッシュ効率とのバランスが必要です。観測データのように大量一括読み込みが多い場合に効果が大きくなります。
A: 行単価のディスク I/O は減りますが、メモリ消費やキャッシュ効率とのバランスが必要です。観測データのように大量一括読み込みが多い場合に効果が大きくなります。
関連キーワード: ページング、レンジ区分、テーブル設計、I/O最適化、行格納
設問2:〔“観測” テーブルの区分化〕について答えよ。
(3)区分化前では、副次索引から1行を読み込むごとに、なぜ表領域の1ページを読み込む必要があるか。 その理由を30字以内で答えよ。 ただし、副次索引の索引ページの読込みについては考慮しなくてよい。
模範解答
同じ圃場の行は、1ページに1行しか格納できないから
解説
解答の論理構成
- ページ構成とクラスタリング
【問題文】には「ページ当たり行数:4行/ページ」とあります。また主索引列の定義順は「観測日付、観測時分、圃場 ID」です。主索引でクラスタリングされるため、同一の (観測日付、観測時分) が先に並び、その下位に 1,000 個の圃場 ID が続きます。 - 行挿入の挙動
行は「表領域の最後のページに行を格納する」と明記されています。1 分ごとに 1,000 行(1,000 圃場)が到着するので、最後のページの 4 行が埋まるたびに新しいページが割り当てられます。 - ページ内の圃場分布
1 ページに 4 行しか入らず、圃場 ID はクラスタリング順で 4 つとも異なるため、同じ圃場 ID の行は別ページに散在します。 - 副次索引走査時の I/O
副次索引「圃場 ID」から取得するレコードは、ページ毎に 1 行しか含まれないので、行を 1 件読むごとに必ずデータページを 1 枚読み込むことになります。
誤りやすいポイント
- 「4 行/ページだから 4 行読める」と思い込み、同一圃場の行も 1 ページに 4 行入ると誤解する
- 挿入順仕様を見落とし、ランダム分散されると考えてしまう
- 主索引と副次索引の違い、特にクラスタリング効果を軽視する
FAQ
Q: 主索引があるのに副次索引で検索するのはなぜですか?
A: 日付・時分ではなく「圃場 ID」で抽出したい分析(積算温度など)が多いためです。主索引は (観測日付、観測時分、圃場 ID) なので、日付範囲を限定しない場合は副次索引の方が速いからです。
A: 日付・時分ではなく「圃場 ID」で抽出したい分析(積算温度など)が多いためです。主索引は (観測日付、観測時分、圃場 ID) なので、日付範囲を限定しない場合は副次索引の方が速いからです。
Q: ページ当たり行数を増やすだけで I/O は減りますか?
A: 行密度は上がりますが、同一圃場の行がページ内で隣接しない限り「1 行≒1 ページ」の関係は解消しません。区分化やクラスタリングキーの見直しが必要です。
A: 行密度は上がりますが、同一圃場の行がページ内で隣接しない限り「1 行≒1 ページ」の関係は解消しません。区分化やクラスタリングキーの見直しが必要です。
Q: ハッシュ区分を選ばなかった理由は?
A: 区分数を後から変えるたびに「全行を再分配する」ため、大量データでは運用負荷が高いからです。レンジ区分なら圃場追加時の区分追加が軽量で済みます。
A: 区分数を後から変えるたびに「全行を再分配する」ため、大量データでは運用負荷が高いからです。レンジ区分なら圃場追加時の区分追加が軽量で済みます。
関連キーワード: クラスタリング索引、データページ、行挿入アルゴリズム、セカンダリインデックス、I/O効率
設問2:〔“観測” テーブルの区分化〕について答えよ。
(4)区分化後の年末処理の期限は、なぜ 12月31日の24時ではなく元日の日出時刻なのか。 その理由を35字以内で答えよ。
模範解答
元日の日時刻までもデータは前日の農事日付に含まれるから
解説
解答の論理構成
- 農事日付の範囲
- 引用:「日出時刻から翌日の日出時刻の1分前までとする日付を、農事日付という。」
- したがって12月31日の日出~1月1日の日出直前が同じ農事日付。
- 年末処理で削除対象とする「5年以上前」は農事日付単位
- 標準日付で区切ると、12月31日24時~1月1日の日出までのデータが欠落する。
- 区分化後はパーティション単位で切り離し・削除
- 区切りを誤ると不要データが残る/必要データを失うリスク。
- 以上より、安全に前年パーティションを切り離す最終時刻は「元旦の日出時刻」となる。
誤りやすいポイント
- 0時=日付境界と思い込んで農事日付の延長分を見落とす。
- 圃場ごとに日出時刻が異なる事実を忘れ、一律タイミングで削除してしまう。
- 「区分化=自動で古いデータが消える」と誤解し、切り離し手順を怠る。
FAQ
Q: 0時ぴったりでパーティションを切り離してはいけませんか?
A: いけません。0時~日出の観測値は「12月31日の農事日付」に属し、削除対象年度に含まれます。
A: いけません。0時~日出の観測値は「12月31日の農事日付」に属し、削除対象年度に含まれます。
Q: 圃場ごとに日出時刻が違いますが、年末処理はどう調整しますか?
A: 最も遅い圃場の日出時刻を基準にバッチ開始時刻を設定するか、圃場単位で順次処理します。
A: 最も遅い圃場の日出時刻を基準にバッチ開始時刻を設定するか、圃場単位で順次処理します。
Q: 農事日付ではなく標準日付で管理した方が簡単では?
A: 農家の業務は農事日付基準で動くため、分析や通知の正確性を保つには農事日付運用が不可欠です。
A: 農家の業務は農事日付基準で動くため、分析や通知の正確性を保つには農事日付運用が不可欠です。
関連キーワード: 区分化、パーティション、農事日付、日出時刻、データ削除
設問2:〔“観測” テーブルの区分化〕について答えよ。
(5)表7中の(イ)〜(カ)に入れる手順を、それぞれ次の①〜⑤の中から一つ選べ。①〜⑤が全て使われるとは限らない。ただし、バックアップの取得と索引の保守については考慮しなくてよい。
① “圃場カレンダ” から古い行を削除する。
② “圃場カレンダ” を再編成する。
③ “観測” から古い行を削除する。
④ “観測” を再編成する。
⑤ “観測” から古い区分を切り離す。
模範解答
イ:①
ウ:④
エ:⑤
オ:①
カ:②
解説
解答の論理構成
- 【問題文】の制約
- 外部キー制約は「ON DELETE CASCADE」。よって“圃場カレンダ”の行を削除すれば“観測”の該当行も自動削除される。
- 区分化前(非区分)
- 手順2でまず①“圃場カレンダ” から古い行を削除 → “観測”の古い行も連鎖削除。
- 手順3はすでに記載「“圃場カレンダー” を再編成」。
- 連鎖削除により“観測”表領域に空きが生じるので④“観測” を再編成してスペース回収。
- 区分化後(レンジ区分)
- 区分化では【区分を切り離すこともできる】という仕様。
- 古いデータは年度単位の区分ごと存在するため、手順3で⑤“観測” から古い区分を切り離すのが最速。ログも最小。
- “圃場カレンダ”にはまだ古い行が残るので、手順4で①“圃場カレンダ” から古い行を削除。
- 手順5で②“圃場カレンダ” を再編成し空領域を回収。
誤りやすいポイント
- 「③“観測”から古い行を削除する」を選択すると、行数が膨大で処理時間・ログ量ともに増大する。外部キーの連鎖削除を見落とさない。
- 区分化後も“圃場カレンダ”は区分化していない点を混同し、再編成②を忘れがち。
- 切り離し⑤と再編成④/②の順序を逆にすると、不要な領域を含むまま再編成してしまう。
FAQ
Q: 区分を切り離す⑤だけでは完全削除にならないのですか?
A: 区分を切り離すと“観測”側の物理ファイルを除外できますが、“圃場カレンダ”には依然として古い行が残ります。整合性と領域回収のため①②が必要です。
A: 区分を切り離すと“観測”側の物理ファイルを除外できますが、“圃場カレンダ”には依然として古い行が残ります。整合性と領域回収のため①②が必要です。
Q: なぜ区分化前で③を使わず④だけで済むのですか?
A: ①で“圃場カレンダ”の行を削除すると外部キーの「ON DELETE CASCADE」により“観測”の古い行も自動削除されるため、個別削除③は不要です。削除後の空き領域を整理するために④で再編成します。
A: ①で“圃場カレンダ”の行を削除すると外部キーの「ON DELETE CASCADE」により“観測”の古い行も自動削除されるため、個別削除③は不要です。削除後の空き領域を整理するために④で再編成します。
Q: 切り離した区分のデータを後日参照したい場合はどうすればよいですか?
A: 区分切離し時に生成される物理ファイルをアーカイブとして保管し、必要になったときは別環境にアタッチして参照する運用が一般的です。
A: 区分切離し時に生成される物理ファイルをアーカイブとして保管し、必要になったときは別環境にアタッチして参照する運用が一般的です。
関連キーワード: レンジ区分、ON DELETE CASCADE, 再編成、表領域、分割索引
