データベーススペシャリスト 2014年 午後1 問01
データベースの設計に関する次の記述を読んで、設問1〜3に答えよ。
A社は、ソフトウェアパッケージの開発及び販売を主力事業としている会社である。 A社ではこれまで、ソフトウェアの開発中に発生したバグの管理に表計算ソフトを用いてきたが、大規模なBソフトウェアパッケージ開発プロジェクト (以下、Bプロジェクトという)の立上げを機に、新たにバグ管理システムを構築することになった。バグ管理システムの設計担当には、C君が任命された。
〔Bプロジェクトの概要〕
Bプロジェクトの概要は、次のとおりである。
(1) 組織は、階層構造の複数のチーム編成である。
(2) チームは、チームID で一意に識別され、チーム名、リーダを任されたメンバ、上位階層のチームが定められている。
(3) メンバは、メンバIDで一意に識別され、所属するチームが定められている。 メンバは、主担当として必ず一つのチームに所属するほか、他の一つ又は複数のチームを兼任する場合もある。
(4) 開発モデルは、ウォータフォールモデルを採用している。 開発工程は、工程IDで一意に識別され、工程名、工程の順序番号が定められている。
(5) 各開発工程では、設計書、ソースコードなどの様々な成果物が作成される。 成果物は、成果物IDで一意に識別される。 成果物には、成果物名、成果物の作成工程、作成担当チームが記される。
〔バグ管理の概要〕
Bプロジェクトにおけるバグ管理の概要は、次のとおりである。
(1) ソフトウェアのテストを実施し、期待するテスト結果と実際のテスト結果にかい離があり、何らかの対応が必要と考えられる現象をバグと呼ぶ。
(2) バグ種別とは、バグの原因を分類するための区分であり、バグ種別名及び成果物の修正有無が定められている。
(3) バグが発見されたら、表1のプロセスに従って解決する。
(4) ソフトウェアの品質分析を行うメンバは、登録されたバグの集計及び分析を行う。品質分析の対象とするバグは、成果物の修正が必要なバグ種別が設定されたバグである。
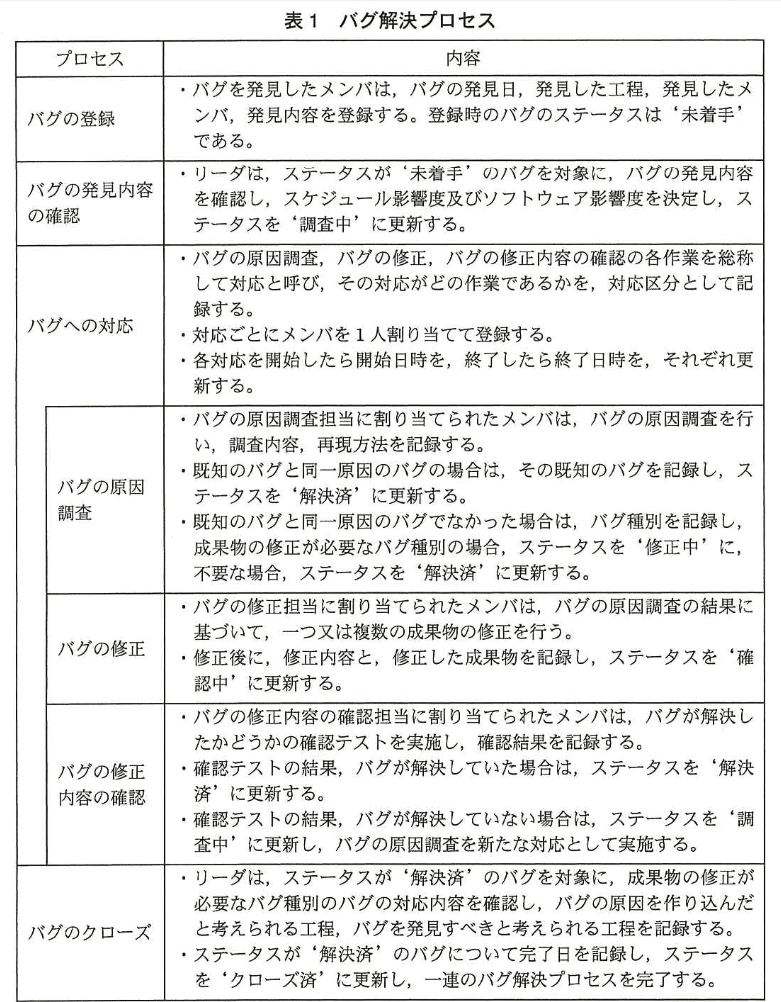
〔データモデルの設計〕
C君は、バグ管理システムの構築に当たり、具体例を用いて、概念データモデル (図1)及び関係スキーマ (図2) の設計を行った。
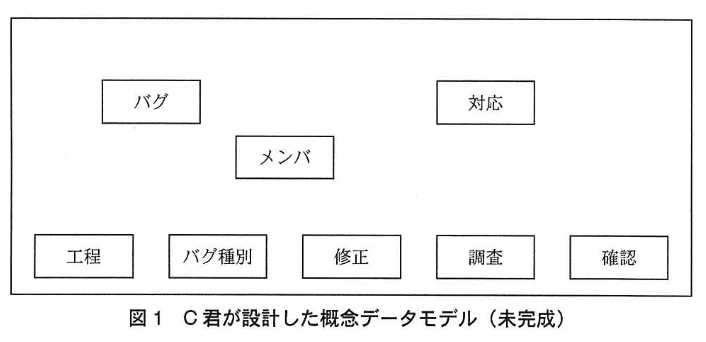
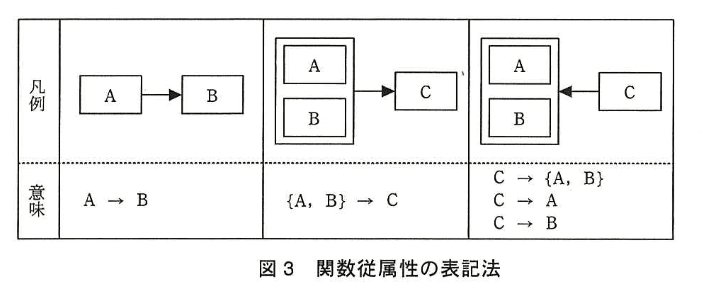
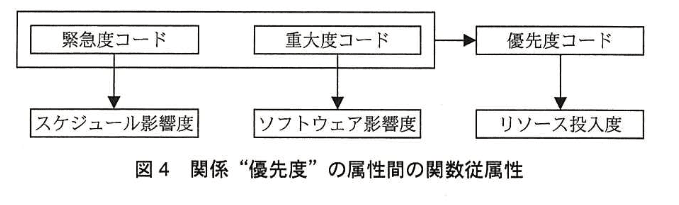
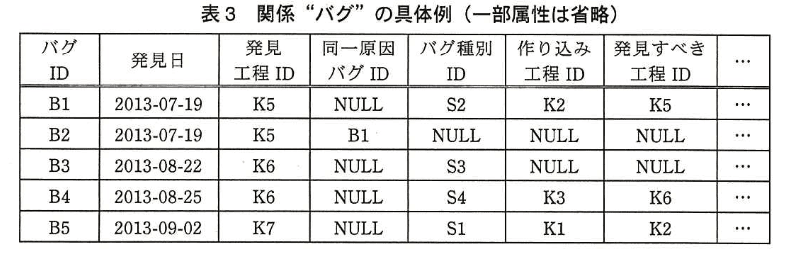
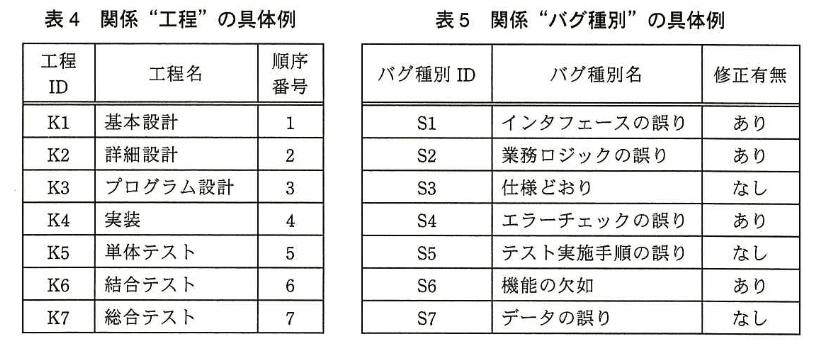
図2の関係スキーマの主な属性とその意味 制約を表2に示す。図4は、図3の関数従属性の表記法に従って、関係 “優先度” の属性間の関数従属性を示したもの である。表 3〜5 は、関係 “バグ”、“工程”、“バグ種別” の具体例である。
〔D部長の指摘事項〕
C君の上司のD部長はC君が設計した内容をレビューし、次の指摘をした。
指摘事項① 図1は、リレーションシップが記入されていない。 また、図2の関係スキーマの一部も未記入である。
指摘事項② 関係 “チーム”、“メンバ”には、プロジェクトの組織構造の一部を管理できない不具合がある。
指摘事項③ 成果物と、バグの修正を行ったときに修正した成果物の情報を管理する関係スキーマが設計されていない。
〔バグの集計及び分析〕
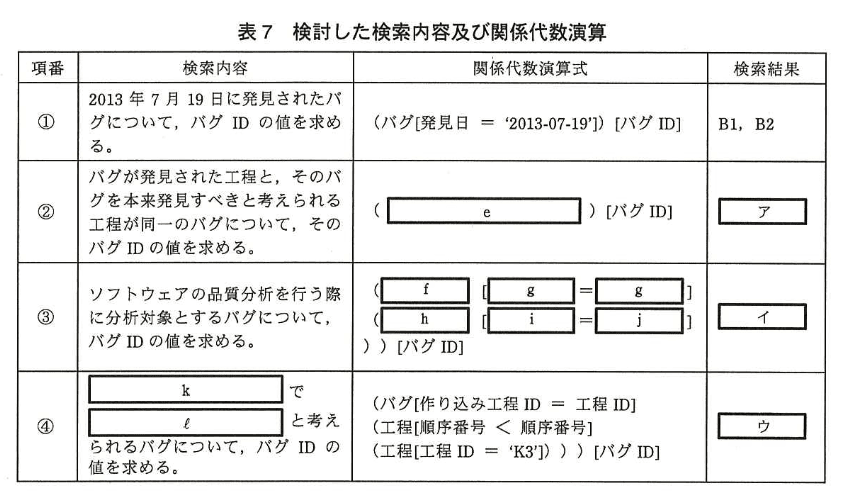
C君は、バグの集計及び分析を行う際に使用する、関係 “バグ”、“工程”、“バグ種別” に対する検索内容と関係代数演算について検討した。 表 6は、関係代数演算の表記法を示したものであり、表7は、表 3〜5の具体例を用いて検討した検索内容及び関係代数演算である。

解答に当たっては、巻頭の表記ルールに従うこと。 関係スキーマの解答に当たっては、主キー及び外部キーを明記せよ。
設問1:図2及び図4の関係 “優先度” について、(1)、(2)に答えよ。
(1)関係“優先度” の候補キーを全て答えよ。 また、部分関数従属性、推移的関数従属性の有無を、“あり” 又は “なし” で答えよ。“あり”の場合は、その関数従属性の具体例を、図3中の意味の欄に示した表記法に従って示せ。
模範解答
候補キー:{緊急度コード、重大度コード}
部分関数従属性の有無:あり
推移的関数従属性の有無:あり
部分関数従属性:
・緊急度コード → スケジュール影響度
・重大度コード → ソフトウェア影響度
推移的関数従属性:
{緊急度コード、重大度コード} → 優先度コード → リソース投入度
解説
解答の論理構成
- 関係 “優先度” の全属性を把握
- 【図2】より「緊急度コード、スケジュール影響度、重大度コード、ソフトウェア影響度、優先度コード、リソース投入度」。
- 関数従属性の読取り
- 【図4】がそのまま関数従属性を示す。
- 「緊急度コード → スケジュール影響度」
- 「重大度コード → ソフトウェア影響度」
- 「{緊急度コード、重大度コード} → 優先度コード」
- 「優先度コード → リソース投入度」
- 【図4】がそのまま関数従属性を示す。
- 候補キーの決定
- どの属性集合が他の全属性を決定するかを確認。
- 「緊急度コード」と「重大度コード」を組みにすると「優先度コード」が決定でき、さらに「リソース投入度」も導出可能。したがって {緊急度コード、重大度コード} が候補キー。
- 片方のコードだけでは残り全属性を決定できない(スケジュール影響度またはソフトウェア影響度しか決まらない)。
- 部分関数従属性の判定
- 候補キーが複合なので、その部分集合への従属を調べる。
- 「緊急度コード → スケジュール影響度」および「重大度コード → ソフトウェア影響度」は部分関数従属性。
- 推移的関数従属性の判定
- 候補キーから直接ではなく、中間属性を経由して決まる従属性。
- 「{緊急度コード、重大度コード} → 優先度コード → リソース投入度」が該当。
- 設問の出力形式に合わせて整理
- 【図3】の意味の欄の記法で
- 部分: 緊急度コード → スケジュール影響度 / 重大度コード → ソフトウェア影響度
- 推移: {緊急度コード、重大度コード} → 優先度コード / 優先度コード → リソース投入度
- 【図3】の意味の欄の記法で
誤りやすいポイント
- 「コード」と「尺度」を混同し、スケール項目まで候補キーに入れてしまう。
- 「{緊急度コード、重大度コード} → リソース投入度」を直接の従属と誤認し、推移的従属性を見落とす。
- 部分関数従属性を列挙する際、複合キーのどちら側の属性かを省略して不完全な記述になる。
FAQ
Q: 「スケジュール影響度」が重複可とありますが、それでも関数従属性は成り立つのですか?
A: はい。「緊急度コード」を決めればスケジュール影響度が一意に決まる、という意味なので重複の有無は無関係です。値が重複しても決定元は一意のままです。
A: はい。「緊急度コード」を決めればスケジュール影響度が一意に決まる、という意味なので重複の有無は無関係です。値が重複しても決定元は一意のままです。
Q: 「優先度コード」単独は候補キーにならないのですか?
A: 【表2】に「優先度コードが異なるが、リソース投入度が同一となる場合がある」とあるため、「優先度コード → 緊急度コード、重大度コード」は成立せず、候補キー条件を満たしません。
A: 【表2】に「優先度コードが異なるが、リソース投入度が同一となる場合がある」とあるため、「優先度コード → 緊急度コード、重大度コード」は成立せず、候補キー条件を満たしません。
Q: 第2正規形・第3正規形に沿って再設計する必要がありますか?
A: 設問は候補キーと従属性の列挙のみ要求していますが、判断結果から分かるように現行の “優先度” は第1正規形にとどまり、第2、第3へ正規化余地があると評価できます。
A: 設問は候補キーと従属性の列挙のみ要求していますが、判断結果から分かるように現行の “優先度” は第1正規形にとどまり、第2、第3へ正規化余地があると評価できます。
関連キーワード: 関数従属性、候補キー、部分関数従属性、推移的関数従属性、正規化
設問1:図2及び図4の関係 “優先度” について、(1)、(2)に答えよ。
(2)関係“優先度”は、第1正規形、第2正規形、第3正規形のうち、どこまで正規化されているかを答えよ。 また、第3正規形でない場合は、第3正規形に分解した関係スキーマを示せ。
模範解答
正規形:第1正規形
関係スキーマ:
緊急度(緊急度コード、スケジュール影響度)
重大度(重大度コード、ソフトウェア影響度)
優先度変換(緊急度コード、重大度コード、優先度コード)
優先度(優先度コード、リソース投入度)
解説
解答の論理構成
- 関係 “優先度” の候補キー決定
- 図4より「{緊急度コード、重大度コード} → 優先度コード → リソース投入度」が成り立つ。
- さらに「緊急度コード → スケジュール影響度」「重大度コード → ソフトウェア影響度」。
- {緊急度コード、重大度コード} だけで全属性を導出でき、これが主キー。
- 正規形の判定
- 第1正規形は属性が単一値で満たす。
- 第2正規形:非キー属性は主キー全体に完全関数従属していなければならない。
• スケジュール影響度 は 緊急度コード のみで決定
• ソフトウェア影響度 は 重大度コード のみで決定
→ 部分関数従属があるため第2正規形を満たさない。 - よって現状は第1正規形。
- 第3正規形への分解
- 部分関数従属を解消
• 緊急度 と 重大度 の各リストを分離。 - 推移関数従属を解消
• 優先度コード → リソース投入度 により「緊急度コード、重大度コード → 優先度コード → リソース投入度」がある。
優先度コードを別表にし、リソース投入度をそこへ移す。 - 得られた四つの関係は上記スキーマであり、すべて第3正規形を満たす。
- 部分関数従属を解消
誤りやすいポイント
- 「優先度コード」を主キーと誤認し、第2正規形と判断してしまう。
- 先に優先度コード表を切り出しただけで満足し、部分関数従属の解消を忘れる。
- 分解後の外部キーを明記しないため減点される。
FAQ
Q: 「緊急度コード」と「重大度コード」の組に重複がある場合でも正規化は必要ですか?
A: はい。重複の有無ではなく、関数従属性に基づいて正規形を判定します。部分関数従属が存在する限り第2正規形にはなりません。
A: はい。重複の有無ではなく、関数従属性に基づいて正規形を判定します。部分関数従属が存在する限り第2正規形にはなりません。
Q: 「優先度変換」表の主キーは何ですか?
A: 「緊急度コード、重大度コード」の複合キーです。図4よりこの組み合わせで一意に「優先度コード」が決まります。
A: 「緊急度コード、重大度コード」の複合キーです。図4よりこの組み合わせで一意に「優先度コード」が決まります。
Q: 第3正規形とボイス・コッド正規形(BCNF)の違いは気にするべきですか?
A: この問題では第3正規形までを求めています。図4の依存性では得られた四関係はBCNFも満たしますが、設問範囲外です。
A: この問題では第3正規形までを求めています。図4の依存性では得られた四関係はBCNFも満たしますが、設問範囲外です。
関連キーワード: 正規化、関数従属性、候補キー、部分関数従属、データベース設計
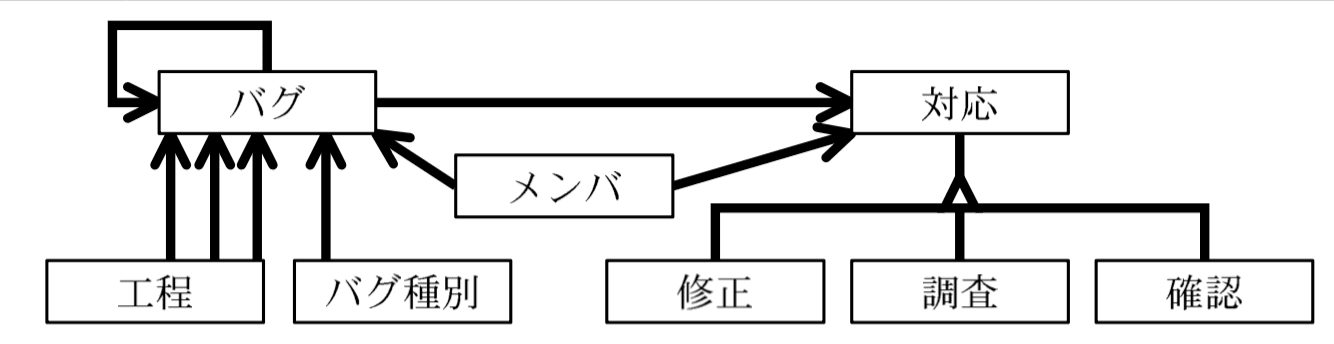
設問2:図1,図2及び 〔D部長の指摘事項〕 について、(1)〜(4)に答えよ。
(1)指摘事項 ① について、図1のエンティティタイプ間のリレーションシップを全て記入せよ。 同一のエンティティタイプ間に異なる役割をもつ複数のリレーションシップが存在する場合、役割の数のリレーションシップを表す線を記入すること。
なお、図に表示されていないエンティティタイプは考慮しなくてよい。 また、エンティティタイプ間の対応関係にゼロを含むか否かの表記は不要である。
模範解答
解説
解答の論理構成
- 外部キーを列挙
【問題文】図2 “バグ” の属性には “発見工程ID”、“作り込み工程ID”、“発見すべき工程ID”、“同一原因バグID”、“バグ種別ID”、“発見メンバID” がある。これは「バグ」が「工程」「バグ」「バグ種別」「メンバ」に依存していることを示す。 - 役割の数だけ線を引く
指示文「同一のエンティティタイプ間に異なる役割をもつ複数のリレーションシップが存在する場合、役割の数のリレーションシップを表す線を記入すること。」より、工程との関係は3役割(発見/作り込み/発見すべき)なので3本必要。 - 自己参照の明示
“同一原因バグID” は【問題文】表1「既知のバグと同一原因のバグの場合…既知のバグを記録」とある。従って「バグ」内でループ線を描く。 - 「対応」と下位3表の接続
図2 “対応” には “バグID” が含まれる(親子関係)。また “調査”、“修正”、“確認” は “バグID, 対応連番” を持つため「対応」からの従属関係となる。 - メンバとの二方向
“発見メンバID” はバグ発見者、“(c)” は対応担当者なので「メンバ」から「バグ」「対応」へ2本の太線を引く。
誤りやすいポイント
- 工程に対する役割を一つの線で済ませてしまう
- “同一原因バグID” による自己参照を描き忘れる
- 「対応」と「メンバ」の関係を「バグ」で代替できると勘違いし、直接線を引かない
- 「調査」「修正」「確認」を独立エンティティと考えず、「対応」に包含してしまう
FAQ
Q: 工程とのリレーションシップはなぜ3本なのですか?
A: 図2 “バグ” には “発見工程ID”、“作り込み工程ID”、“発見すべき工程ID” の3属性があり、それぞれが別々の意味(役割)で “工程ID” を参照しています。指示文で「役割の数のリレーションシップを表す線」とあるため3本必要です。
A: 図2 “バグ” には “発見工程ID”、“作り込み工程ID”、“発見すべき工程ID” の3属性があり、それぞれが別々の意味(役割)で “工程ID” を参照しています。指示文で「役割の数のリレーションシップを表す線」とあるため3本必要です。
Q: 自己参照は必ずループ矢印で描かなければならないのでしょうか?
A: ER図では同一エンティティ間の関係はループ線か、同じエンティティを2回描いて結ぶ方法のどちらでも可ですが、図1の形式に合わせループで示すのが最も簡潔です。
A: ER図では同一エンティティ間の関係はループ線か、同じエンティティを2回描いて結ぶ方法のどちらでも可ですが、図1の形式に合わせループで示すのが最も簡潔です。
Q: 「調査」「修正」「確認」を「対応」にまとめた方がシンプルでは?
A: システム要件に「対応区分ごとにメンバを1人割り当てて登録する」「開始日時・終了日時を更新する」など個別管理が必要と明示されているため、独立エンティティとして分ける方が正規化・運用の両面で有利です。
A: システム要件に「対応区分ごとにメンバを1人割り当てて登録する」「開始日時・終了日時を更新する」など個別管理が必要と明示されているため、独立エンティティとして分ける方が正規化・運用の両面で有利です。
関連キーワード: 外部キー、自己参照、ER図、関係スキーマ、正規化
設問2:図1,図2及び 〔D部長の指摘事項〕 について、(1)〜(4)に答えよ。
(2)指摘事項 ① について、図2中の(a)〜(d)に入れる属性名を答えよ。(a, bは順不同、c, dは順不同)
模範解答
a:ステータス
b:完了日
c:対応区分
d:対応メンバID
解説
解答の論理構成
- バグ表に必要な属性の洗い出し
- 【問題文】「登録時のバグのステータスは『未着手』」
- 「ステータスが『解決済』のバグについて完了日を記録し、ステータスを『クローズ済』に更新」
- よってバグの状態管理には“ステータス”と“完了日”が不可欠 → (a)(b) に充当。
- 対応表に必要な属性の洗い出し
- 【問題文】「その対応がどの作業であるかを、対応区分として記録」
- 「対応区分ごとにメンバを1人割り当てて登録」
- 作業種別を示す“対応区分”と割り当てられた“メンバID”が要件 → (c)(d) に充当。
- 順不同指定の確認
- 問題指示により“a,b は順不同”“c,d は順不同”なので、ペア内の並びは評価に影響しない。
誤りやすいポイント
- “完了日”を対応側に置いてしまうミス。完了日はバグ全体のライフサイクル終了を示すためバグ表に属する。
- “対応メンバID”を氏名で設計する誤り。IDでないと他表(メンバ)との参照整合性が取れない。
- “対応区分”と“ステータス”を混同するミス。前者は作業種別、後者はバグ解決プロセス全体の状態。
FAQ
Q: “完了日”はなぜ対応ではなくバグ表に置くのですか?
A: 【問題文】の「ステータスが『解決済』のバグについて完了日を記録」という文が“バグ”に対する操作であるためです。
A: 【問題文】の「ステータスが『解決済』のバグについて完了日を記録」という文が“バグ”に対する操作であるためです。
Q: “対応メンバID”を外部キーとする根拠は?
A: 「対応区分ごとにメンバを1人割り当てて登録」という要件から、メンバ表と参照整合性を保つ必要があるためです。
A: 「対応区分ごとにメンバを1人割り当てて登録」という要件から、メンバ表と参照整合性を保つ必要があるためです。
Q: ステータスはコード化すべきですか?
A: 試験問題では文字列記録ですが、実システムではコード化し状態遷移表で管理する方が整合性を高められます。
A: 試験問題では文字列記録ですが、実システムではコード化し状態遷移表で管理する方が整合性を高められます。
関連キーワード: 外部キー、関係スキーマ、状態遷移、正規化、データモデリング
設問2:図1,図2及び 〔D部長の指摘事項〕 について、(1)〜(4)に答えよ。
(3)指摘事項 ②の不具合を二つ挙げ、それぞれ 25 字以内で述べよ。また、不具合を解消した関係スキーマを示せ。
模範解答
不具合:① チームの上位階層のチームを管理できない。
② メンバが兼任しているチームを複数管理できない。
関係スキーマ:チーム(チームID、チーム名、リーダメンバID、上位チームID)
メンバ(メンバID、氏名、主担当チームID)
兼任(メンバID、兼任チームID)
解説
解答の論理構成
- 要件の確認
- チーム階層:【問題文】(1)(2)
「上位階層のチーム」が必須。 - メンバ兼任:【問題文】(3)
「他の一つ又は複数のチームを兼任」⇒多対多。
- チーム階層:【問題文】(1)(2)
- 現行スキーマ(図2)の欠落
- チーム関係に「上位チームID」がない。
- メンバ関係に単一列「兼任チームID」があるだけで複数値不可。
- 不具合の定義
- ①階層構造を管理できず組織図が作れない。
- ②兼任が複数ある場合に属性の繰返しまたはNULL発生。
- 修正方針
① 自己参照外部キーで階層を持つ。
② 多対多は中間表で分離し正規化。 - 修正版スキーマ
- チーム(チームID、チーム名、リーダメンバID, 上位チームID(FK→チーム.チームID))
- メンバ(メンバID、氏名、主担当チームID(FK→チーム.チームID))
- 兼任(メンバID(FK→メンバ.メンバID)、兼任チームID(FK→チーム.チームID)、PK=(メンバID, 兼任チームID))
誤りやすいポイント
- 「兼任チームID」をメンバ関係に複数列で追加してしまい第1正規形違反になる。
- 上位チームを別表に置くと自己参照でなくなり更新整合性が崩れる。
- PK/FKの記述を求められているのに省略して減点される。
FAQ
Q: 上位階層は何階層まで対応できますか?
A: 自己参照型の外部キーなので階層数に制限はありません。再帰クエリで全階層をたどれます。
A: 自己参照型の外部キーなので階層数に制限はありません。再帰クエリで全階層をたどれます。
Q: メンバが兼任しない場合、兼任表はどうなりますか?
A: レコードが存在しないだけです。NULL を格納しないので表の一貫性が保たれます。
A: レコードが存在しないだけです。NULL を格納しないので表の一貫性が保たれます。
Q: 兼任表のPKを単一列にできませんか?
A: 多対多の組み合わせを一意にする必要があるため、複合主キー (メンバID, 兼任チームID) が適切です。
A: 多対多の組み合わせを一意にする必要があるため、複合主キー (メンバID, 兼任チームID) が適切です。
関連キーワード: 正規化、自己参照外部キー、多対多リレーション、第1正規形、階層データ
設問2:図1,図2及び 〔D部長の指摘事項〕 について、(1)〜(4)に答えよ。
(4)指摘事項 ③ で設計されていないとしている関係スキーマを設計せよ。
模範解答
成果物:(成果物ID、成果物名、作成工程ID、作成担当チームID)
修正成果物:(バグID、対応連番、成果物ID)
解説
解答の論理構成
-
成果物を表すエンティティの必要性
- 【問題文】(5) で「成果物は、成果物 ID で一意に識別される」とある。したがって、成果物IDが主キーとなる基本表「成果物」を設ける。
- 同じ段落に「成果物名」「成果物の作成工程、作成担当チーム」が列挙されているため、属性として追加。
- 「作成工程」は表4「工程」、「作成担当チーム」は“チーム”と参照関係を持つため、それぞれ外部キー (FK) を設定。
-
バグ修正と成果物の多対多関係
- 【問題文】「バグの修正担当に割り当てられたメンバは…一つ又は複数の成果物の修正を行う」とあり、1 回の修正対応が複数成果物に影響します。
- 逆に、同一成果物が複数のバグ修正に関与する可能性もあるため、多対多 (n:m) 関係を解消する中間表が必須。
- 修正作業は“対応”で管理され、図2 に「対応(バグID, 対応連番、…)」が既に存在する。主キーは (バグID、対応連番)。
- よって、中間表「修正成果物」を作成し、主キーを (バグID、対応連番、成果物ID) として三つを全て外部キーにする。
-
主キー・外部キーの整理
• 成果物- PK:成果物ID
- FK1:作成工程ID → 工程.工程ID
- FK2:作成担当チームID → チーム.チームID
• 修正成果物 - PK:バグID、対応連番、成果物ID
- FK1:(バグID, 対応連番) → 対応.(バグID, 対応連番)
- FK2:成果物ID → 成果物.成果物ID
誤りやすいポイント
- 成果物の属性を“対応”や“バグ”に直接追加してしまい、第3正規形を崩す。
- 「修正成果物」の主キーに 対応連番 を含め忘れ、1 バグ 1 成果物しか登録できない設計にしてしまう。
- 「作成工程ID」を NULL 可と考えてしまうが、【問題文】に「作成工程」が必ず定められるとあるため非 NULL とする。
FAQ
Q: 「修正成果物」に修正日時や修正担当者を持たせる必要はありませんか?
A: 修正作業の時系列情報や担当者は既に“対応”で保持されます。【問題文】「開始日時」「終了日時」「対応区分ごとにメンバを1人割り当て」より、冗長になるため追加不要です。
A: 修正作業の時系列情報や担当者は既に“対応”で保持されます。【問題文】「開始日時」「終了日時」「対応区分ごとにメンバを1人割り当て」より、冗長になるため追加不要です。
Q: “成果物” と “対応” を直接結合する設計でも良いのでは?
A: “成果物” と “対応” は多対多関係です。正規化の原則では、直接結合できないため中間表「修正成果物」で解消します。
A: “成果物” と “対応” は多対多関係です。正規化の原則では、直接結合できないため中間表「修正成果物」で解消します。
関連キーワード: 多対多、主キー、外部キー、正規化、トレーサビリティ
設問3:表 3〜7 及び 〔バグの集計及び分析〕 について、(1)〜(3)に答えよ。
(1)表7中の項番 ②、③の検索を行うためには、どのような関係代数演算を行えばよいか。 表 7 中の項番 ①の例に倣って、(e)〜(j)に入れる適切な字句を答えよ。
なお、関係代数演算の表記法は、表6に従うこと。(i, jは順不同)
模範解答
e:バグ[発見工程ID = 発見すべき工程ID]
f:バグ
g:バグ種別ID
h:バグ種別
i:修正有無
j:あり
解説
解答の論理構成
-
項番②の条件確認
【問題文・表7】
“バグが発見された工程と、そのバグを未発見すべきと考えられる工程が同一のバグ”
→ 同一関係 “バグ” に含まれる “発見工程ID”、“発見すべき工程ID” を比較。
→ 表6「選択」の書式:R〔X = Y〕
したがって
e:バグ〔発見工程ID = 発見すべき工程ID〕 -
射影部は例①から踏襲
・選択演算の直後に 〔バグID〕 を付けるので、演算対象となる関係名は「バグ」。
f:バグ -
項番③の条件確認
【問題文】
“品質分析の対象とするバグは、成果物の修正が必要なバグ種別が設定されたバグである。”
・“成果物の修正が必要” ⇒ 表2 “修正有無” が “あり”
・“バグ種別が設定されたバグ” ⇒ “バグ種別ID” により “バグ” と “バグ種別” を結合する必要がある。 -
関係代数演算の組み立て
(1) 結合条件
表6「結合」:R〔RA = SA〕S
RA:バグ種別ID(バグ側)
SA:バグ種別ID(バグ種別側)
よって
g:バグ種別ID
(2) 結合する相手の関係
h:バグ種別
(3) 選択条件
“修正有無 = ‘あり’”
i:修正有無
j:あり -
全体式(括弧配置の説明)
① f(バグ)と h(バグ種別)を g(バグ種別ID)で結合
② その結果に対し i = j(修正有無 = ‘あり’)で選択
③ 射影で 〔バグID〕 を取り出す
表7 が示す多重括弧はこの順序を表している。
誤りやすいポイント
- “同一のバグ” を別関係との結合と誤読し、不要な 工程 との結合を書いてしまう。
- “修正有無” を “なし” と逆に書くミス。設問は “修正が必要” と明示している。
- 選択と結合の括弧位置を省略し、演算の優先順位で減点される。
FAQ
Q: バグ種別ID の結合条件は左右どちらが先でも良いですか?
A: はい。表6の書式は R〔RA = SA〕S ですが、SA = RA と左右を入れ替えても等価です。
A: はい。表6の書式は R〔RA = SA〕S ですが、SA = RA と左右を入れ替えても等価です。
Q: 選択演算で文字列定数を比較する場合、シングルクォーテーションは必須ですか?
A: 表7の例①が '2013-07-19' と示しているので、文字列リテラルはクォーテーションで囲むのが慣例です。数値の場合は不要でもかまいません。
A: 表7の例①が '2013-07-19' と示しているので、文字列リテラルはクォーテーションで囲むのが慣例です。数値の場合は不要でもかまいません。
Q: “修正有無” の取り扱いを数値化(0/1)していても理屈は同じ?
A: 同じです。関係代数では定数の比較に過ぎないため、修正有無 = 1 のようにデータ型が異なっても演算手順は変わりません。
A: 同じです。関係代数では定数の比較に過ぎないため、修正有無 = 1 のようにデータ型が異なっても演算手順は変わりません。
関連キーワード: 関係代数、射影、選択、結合、属性比較
設問3:表 3〜7 及び 〔バグの集計及び分析〕 について、(1)〜(3)に答えよ。
(2)表7中の項番④の関係代数演算式は、どのようなバグを検索するために行うものか。k に入れる適切な字句を、工程名を含めて20字以内で、(l)に入れる適切な字句を15字以内で、それぞれ具体的に述べよ。
模範解答
k:・プログラム設計工程よりも前の工程
・基本設計又は詳細設計工程
l:原因を作り込んだ
解説
解答の論理構成
- 表4より K3 の 工程名 は「プログラム設計」、順序番号 は 3 である。
- 式 (工程〔順序番号 < 順序番号〕 (工程〔工程ID = 'K3'〕)) は、自己結合を用いて 順序番号 が 3 より小さい工程を抽出している。よって「基本設計(K1)」と「詳細設計(K2)」が対象。
- バグ〔作り込み工程ID = 工程ID〕 との結合により、作り込み工程ID がこれら前工程を示すバグのみ残る。
- したがって k は「プログラム設計工程よりも前の工程・基本設計又は詳細設計工程」と説明できる。
- 作り込み工程ID は表2で「バグの原因を作り込んだと考えられる工程」を示すため、l は「原因を作り込んだ」となる。
誤りやすいポイント
- 順序番号 < 順序番号 を単なる誤記と勘違いし、比較元が同一タプルだと解釈してしまう。
- 作り込み工程ID を「修正工程」と誤読し、バグ修正時点の工程と混同する。
- 「前工程」と聞いて「テスト工程より前」など別の基準を想像してしまう。
FAQ
Q: 自己結合かどうかはどこで判断できますか?
A: 関係代数式で同じ関係名が重ねて書かれ、別名が付いていない場合でも比較する属性が同名であれば自己結合を示します。今回の 工程〔順序番号 < 順序番号〕 が典型です。
A: 関係代数式で同じ関係名が重ねて書かれ、別名が付いていない場合でも比較する属性が同名であれば自己結合を示します。今回の 工程〔順序番号 < 順序番号〕 が典型です。
Q: 作り込み工程ID と 発見工程ID の違いは?
A: 発見工程ID は実際にバグが見つかった工程、作り込み工程ID は「バグの原因を作り込んだと考えられる工程」です。前者は結果、後者は原因を特定する分析情報です。
A: 発見工程ID は実際にバグが見つかった工程、作り込み工程ID は「バグの原因を作り込んだと考えられる工程」です。前者は結果、後者は原因を特定する分析情報です。
Q: 「基本設計」と「詳細設計」は必ず対象になりますか?
A: 表4で 順序番号 が 1 と 2 の工程名がそれぞれ「基本設計」「詳細設計」なので、K3 より小さい順序番号を条件にすると常にこの2工程が対象になります。
A: 表4で 順序番号 が 1 と 2 の工程名がそれぞれ「基本設計」「詳細設計」なので、K3 より小さい順序番号を条件にすると常にこの2工程が対象になります。
関連キーワード: 関係代数、自己結合、射影、選択、主キー
設問3:表 3〜7 及び 〔バグの集計及び分析〕 について、(1)〜(3)に答えよ。
(3)表3〜5の具体例について 表7中の項番 ②〜④の検索を行った場合の、(ア)〜(ウ)に入れる検索結果を表 7 中の項番 ①の例に倣って答えよ。
模範解答
ア:B1, B4
イ:B1, B4, B5
ウ:B1, B5
解説
解答の論理構成
-
項番②(ア)
- 検索内容:「バグが発見された工程」と「発見すべき工程」が同一。
- 判断基準:バグのタプルで「発見工程 ID = 発見すべき工程 ID」。
- 【表3】より
• B1:K5=K5 → 該当
• B4:K6=K6 → 該当
• B2, B3, B5 は NULL もしくは不一致 → 非該当 - 結果:B1, B4
-
項番③(イ)
- 検索内容:「成果物の修正が必要なバグ種別」が設定されたバグ。
- 判断基準:
• 【問題文】(4)「成果物の修正が必要なバグ種別が設定されたバグ」
• 【表5】で「修正有無」が「あり」のバグ種別 ID は S1, S2, S4, S6。 - 【表3】より
• B1:S2 → あり
• B4:S4 → あり
• B5:S1 → あり
• B2:NULL、B3:S3(なし) → 除外 - 結果:B1, B4, B5
-
項番④(ウ)
- 関係代数式読解
• 工程〔工程ID = 'K3'〕で得たタプルの「順序番号」は 3。
• そのサブクエリ外側の「工程〔順序番号 < 順序番号〕」は 3 より小さい工程 → 順序番号 1, 2(K1, K2)。
• バグ〔作り込み工程ID = 工程ID〕で「作り込み工程 ID」が K1 または K2 のバグを抽出。 - 【表3】より
• B1:作り込み工程 ID = K2 → 該当
• B5:作り込み工程 ID = K1 → 該当
• B2, B3(NULL)、B4(K3) → 非該当 - 結果:B1, B5
- 関係代数式読解
誤りやすいポイント
- NULL 比較は常に偽になるため「K5 = NULL」は成立しないことを忘れがちです。
- 「修正有無」は“バグ”ではなく“バグ種別”に属する属性であり、直接バグ表を見ても判断できません。
- 順序番号の大小比較を読み違え、「≤」と誤解して K3 を含めてしまうミスが頻発します。
FAQ
Q: NULL が含まれる列を等号比較に使うとどう扱われますか?
A: SQL 同様、関係代数でも NULL と任意の値の比較結果は偽になるため、そのタプルは選択条件を満たしません。
A: SQL 同様、関係代数でも NULL と任意の値の比較結果は偽になるため、そのタプルは選択条件を満たしません。
Q: 「修正有無」をバグ表にコピーしておけば検索は簡単になりますか?
A: 冗長性が高まり更新不整合のリスクがあるため、正規化の観点からはバグ種別表で保持し、検索時に結合・選択する設計が望ましいです。
A: 冗長性が高まり更新不整合のリスクがあるため、正規化の観点からはバグ種別表で保持し、検索時に結合・選択する設計が望ましいです。
Q: 順序番号の比較で基準値を動的に取りたい場合、関係代数ではどう書きますか?
A: 本問のように「工程〔工程ID = 'K3'〕」で得たサブリレーションから比較対象の属性値を取得し、その結果を外側の選択で用います。
A: 本問のように「工程〔工程ID = 'K3'〕」で得たサブリレーションから比較対象の属性値を取得し、その結果を外側の選択で用います。
関連キーワード: 関係代数、関数従属性、正規化、NULL処理、結合条件
