データベーススペシャリスト 2019年 午後1 問03
部品表の設計及び処理に関する次の記述を読んで、設問1〜4に答えよ。
E社は、機械メーカである。 E社では、RDBMS に構築した生産部品表(以下、部品表という)を用いて生産管理を行っている。 情報システム部門のFさんは、新たに配属された DB 管理者のために、部品表に関する研修を担当することになった。
〔RDBMS の主な仕様〕
(1) 索引は、ユニーク索引と非ユニーク索引に分けられる。
(2) DML のアクセスパスは,RDBMSによって索引探索又は表探索に決められる。
(3) 索引探索に決められるためには、WHERE 句の AND だけで結ばれた一つ以上の等値比較の述語の対象列が、索引キーの全体又は先頭から連続した一つ以上の列に一致していなければならない。 ON 句の場合も同様である。
〔部品表の概要〕
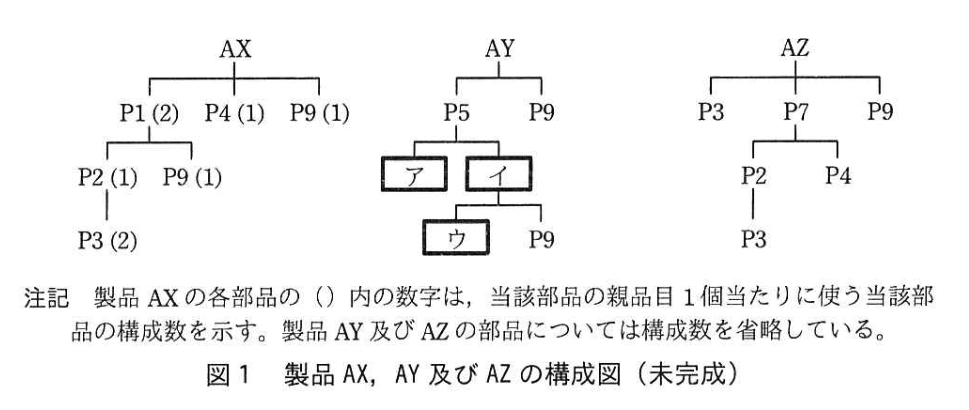
部品表は,E社が製造する製品と製品を構成する部品との関係を表すものである。 Fさんは、研修で使用するために E社の製品を簡略化して表した製品 AX AY 及び AZの構成図を図1に示し、次のように説明することにした。
1.品目
(1) 品目は、品番で識別し、品目ごとに在庫をもっている
(2) 品目には、製品と、他の部品を使って組み立てられる中間部品、単独で使われる単体部品があり、品目区分で分類する。 例えば、図1中の AX は製品、P1及びP2は中間部品、P3, P4及びP9は単体部品である。
2.製品の構成
(1) 製品は、複数種類の部品で構成され、構成図は、階層で表現される。製品からの階層の深さをレベルという。 製品のレベルを0として、階層を一つ下るごとにレベルに1を加算する。 例えば、製品 AX を構成する部品について、レベル1に部品 P1, P4 及び P9, レベル2に部品 P2 及び P9, レベル3に部品 P3がある。
(2) 各部品について、当該部品を使う全ての製品の構成図の中で、当該部品が出現するレベルの最大値を、最も深い階層を示すことから、ローレベルコード(以下、LLC という)という。 例えば、図1では、部品 P5 の LLC は 1, 部品P9のLLCは3である。
(3) ある品目が他の品目から構成される場合、当該品目を親品目といい、親品番で識別する。また、当該親品目の一つ下のレベルの品目を子品目といい、子品番で識別する。
(4) 親品目1個当たりに使う各子品目の個数を構成数という。 例えば、製品 AX の製造に使う各部品の構成数は、次のとおりである。
① 製品 AX は、1個当たり、部品 P1を2個、部品 P4, P9 をそれぞれ1個ずつ使う。
② 部品 P1は,1個当たり、部品 P2, P9 をそれぞれ1個ずつ使う。
③ 部品P2は、1個当たり、部品P3を2個使う。
3.主なテーブルのテーブル構造
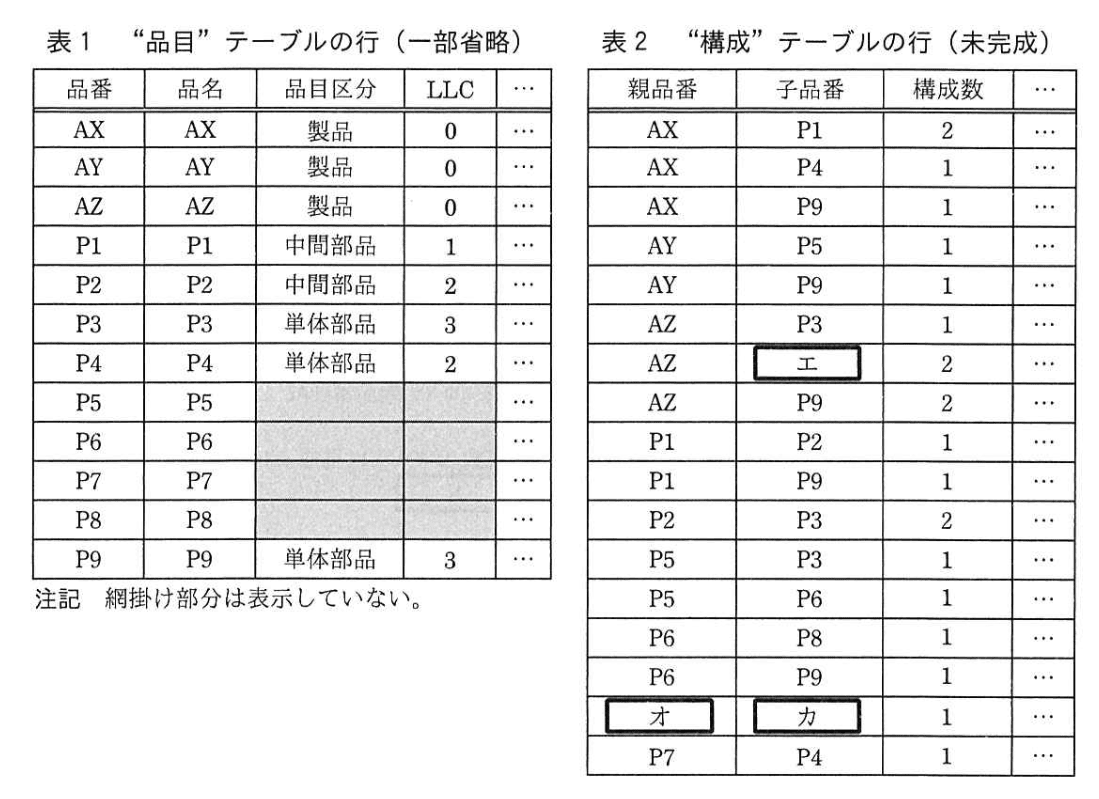
E社が生産管理に用いている主なテーブルのテーブル構造を図2に示す。図1に基づいて登録した“品目” テーブルの行を表1に、“構成” テーブルの行を表2に示す。
なお、各テーブルには主索引だけが定義されている。 索引キーが複合列の場合、テーブル構造に示した列の順番で定義される。

〔部品表に対する基本的な処理〕
1.正展開処理、逆展開処理及び所要量計算処理の概要
Fさんは、部品表に対する三つの基本的な処理として、正展開処理、逆展開処理及び所要量計算処理を挙げた。
(1) 正展開処理は、親品目がどの子品目を使っているかを、階層を上から下に 1階層ずつたどることで調べる。
(2) 逆展開処理は、子品目がどの親品目に使われているかを、正展開処理とは逆に、階層を下から上に1階層ずつたどることで調べる。 逆展開処理は、ある部品が廃番になったとき、その部品がどの品目に影響するかを調べるときなどに行われる。
(3) 所要量計算処理は、製品の生産計画に基づいて、各製品の製造に必要な部品の所要量を計算し、計算した所要量を部品の引当可能数から差し引くことで、在庫を引き当てる。
2.正展開処理、逆展開処理及び所要量計算処理に用いる SQL
Fさんは、部品表に対する三つの基本的な処理に用いられる SQL の構文の例を、表3に示した。

〔所要量計算処理プログラムの概要〕
所要量計算処理プログラムは、表3中のSQL3 及び SQL4 を用いる。 Fさんは、製品をN個製造する場合の所要量計算処理プログラムの処理手順を、表4に示した。
なお、当該処理は、次の前提で行うものとする。
(1) 各部品の所要量の計算は、SQL3 を用いて調べた構成数に基づいて、プログラムこのロジックで行う。
(2) ISOLATION レベルは、READ COMMITTED とする。
(3) 製品が複数ある場合、製品の品番順に、製品ごとに手順 ①〜⑥を繰り返す。
(4) 在庫は、適切に管理されているので、引当可能数が負の数になることはない。

〔Fさんの研修内容に対する K部長の指示〕
表4について、K部長から次のような指示があった。
指示1:表4中の手順③の SQL3 の発行回数を減らすために、手順①及び③のSQL3 で部品の品目区分を調べている。 その理由を説明すること。
指示2:品目の設計変更において、例えば、製品 AX の部品 P3 を新部品 P11 に置き換えるべきところ、誤って部品 P1 を “構成” テーブルに登録してしまった場合、SQL3 の構文中に下線部分の述語が指定されていなければ、プログラムは不具合を起こすことを説明すること。
指示3:製品は多品種なので、スループット向上のために所要量計算を製品ごとに分割して並行処理している。 しかし、表4の処理手順のままではデッドロックが起きるので、プログラムを改良したことを説明すること。
設問1:図1及び表2について、(1)、(2)に答えよ。
(1)図1中の(ア)〜(ウ)に入れる適切な字句を答えよ。
模範解答
ア:P3
イ:P6
ウ:P8
解説
解答の論理構成
-
製品 AY の一次子部品を確認
-
表2よりAY | P5 | 1 AY | P9 | 1
-
よってレベル1で AY が持つ部品は P5 と P9。
-
-
部品 P5 の子部品を確認
-
表2よりP5 | P3 | 1 P5 | P6 | 1
-
したがってレベル2で P5 が持つ部品は P3 と P6。
-
ここで図1の(ア)・(イ)は “P5 の子” に該当する。
⇒ (ア)= P3、(イ)= P6
-
-
部品 P6 の子部品を確認
-
表2よりP6 | P8 | 1 P6 | P9 | 1
-
したがってレベル3で P6 が持つ部品は P8 と P9。
-
図1の(ウ)は “(イ)=P6 の子” のうち、まだ図に現れていない方。
⇒ (ウ)= P8
-
-
以上より(ア)P3, (イ)P6, (ウ)P8
誤りやすいポイント
- 図の矢印や枝数に惑わされ、「P9」ばかりに注目してしまう。子部品の網羅は表2で確認するのが安全です。
- “構成数”の列と“親子関係”の列を混同し、同じ親品番が複数行に現れることを見落としやすい。
- レベル概念(0,1,2…)と “親子テーブル” の関係を対応付けないまま図を補完しようとしてミスを誘発。
FAQ
Q: 図が未完成でも表2だけで正解できますか?
A: はい。【問題文】に「図1に基づいて登録した“構成”テーブルの行を表2に示す」とあるため、親子関係は表2が公式情報です。
A: はい。【問題文】に「図1に基づいて登録した“構成”テーブルの行を表2に示す」とあるため、親子関係は表2が公式情報です。
Q: 構成数(例えば 1 や 2)は今回の空欄補充に影響しますか?
A: いいえ。空欄は“品番”を問うもので、数量は解答に影響しません。構成数は所要量計算など別処理で使用します。
A: いいえ。空欄は“品番”を問うもので、数量は解答に影響しません。構成数は所要量計算など別処理で使用します。
Q: P9 が複数レベルに登場しますがレベル判定のコツは?
A: 親品番を起点に階層を一段ずつ下りながらカウントします。AY→P5→P6→P9 の場合、P9 はレベル3になります。
A: 親品番を起点に階層を一段ずつ下りながらカウントします。AY→P5→P6→P9 の場合、P9 はレベル3になります。
関連キーワード: 部品表、親子関係、階層レベル、所要量計算
設問1:図1及び表2について、(1)、(2)に答えよ。
(2)表2中の(エ)〜(カ)に入れる適切な字句を答えよ。
模範解答
エ:P7
オ:P7
カ:P2
解説
解答の論理構成
-
図1には製品 AZ がレベル1で三つの部品を持ちます。その一つが「P7」である。
よって、親「AZ」に対する欠損行は親品番 = 'AZ'、子品番 = 'P7'であり、(エ)は「P7」です。 -
同じく図1において、部品 P7 の一つ下のレベル(レベル2)に「P2」と「P4」が存在します。
表2を確認すると、P7 P4 1の行は既に登録済みですが、P7→P2 の行が抜けています。
したがって不足行は親品番 = 'P7'、子品番 = 'P2'であり、(オ)は「P7」、(カ)は「P2」です。 -
構成数については図1に具体値が提示されていないため、既に表2に記載されている同列行と照合し、構成数「1」を引き継ぎます。
誤りやすいポイント
- 「P7」は AZ と P7 の二ヵ所で登場します。親側と子側の別を取り違えると (エ) と (オ) を混同しがちです。
- 図1と表2を並べて見ずに暗記頼みで判断すると、既に存在する行「P7 P4 1」を新設と誤認しやすいです。
- 図1でレベルが深くなると、同じ部品番号(例:P3)が複数箇所に現れるため、親品番を必ずセットで確認する必要があります。
FAQ
Q: 構成数が図に書かれていない場合、どうやって決めるのですか?
A: 問題文中に「構成数を省略している」と明記されている場合は、既存の表2を参照して一貫性を取ります。本問では同レベルの他行がすべて「1」なので、それに合わせて「1」と判断します。
A: 問題文中に「構成数を省略している」と明記されている場合は、既存の表2を参照して一貫性を取ります。本問では同レベルの他行がすべて「1」なので、それに合わせて「1」と判断します。
Q: 図1で同じ部品が複数階層に現れたとき、LLC はどう使いますか?
A: LLC は“最も深い階層”を示す値です。逆展開処理で影響範囲を調べるときに利用しますが、本問の空欄補充では親‐子関係の確認だけで足ります。
A: LLC は“最も深い階層”を示す値です。逆展開処理で影響範囲を調べるときに利用しますが、本問の空欄補充では親‐子関係の確認だけで足ります。
Q: エラーチェック用に親品番と子品番を逆にして登録したらどうなりますか?
A: 正展開・逆展開ともに誤結果を返し、特に所要量計算では不足部品を過小・過大計算する恐れがあります。登録時に外部キーまたは整合性チェックを設けるべきです。
A: 正展開・逆展開ともに誤結果を返し、特に所要量計算では不足部品を過小・過大計算する恐れがあります。登録時に外部キーまたは整合性チェックを設けるべきです。
関連キーワード: BOM, 階層構造、親子関係、構成数
設問2:〔部品表に対する基本的な処理〕 の正展開処理について、(1)、(2)に答えよ。
(1)表3中の SQL1の(a)、(b)に入れる適切な字句を答えよ。
模範解答
a:子品番
b:親品番
解説
解答の論理構成
- 【問題文】の説明
- 構成テーブルの列名は 「親品番」「子品番」「構成数」。
- 正展開処理は「親品目がどの子品目を使っているかを、階層を上から下に 1階層ずつたどる」方法。
- SQL1 の意図
- 第1SELECTで レベル1(親品番='AZ')を取得。
- UNION ALL 直後のSELECTで レベル2 を取得するために、別名 L1(レベル1行)と L2(レベル2行)を自己結合。
- 結合条件を決める
- レベル1行の 「子品番」 が、次階層行の 「親品番」 と一致したときにのみ階層がつながる。
- よって L1.(a) = L2.(b) には
- (a) → 子品番
- (b) → 親品番
を入れるのが唯一妥当。
- 結果
- (a) = 子品番
- (b) = 親品番
誤りやすいポイント
- 正展開なのに L1.親品番 = L2.子品番 と逆に書いてしまう。
- 品番 と 親品番/子品番 を混同する。品目テーブルの列は結合に関与しません。
- UNION と UNION ALL の違いを無視して重複排除を行い、所要量が過少になる。
FAQ
Q: なぜ自己結合が必要なのですか?
A: 構成テーブルは1行で1階層分しか保持していないため、レベル間をつなぐには同じテーブルを階層数分だけ重ねて結合する必要があります。
A: 構成テーブルは1行で1階層分しか保持していないため、レベル間をつなぐには同じテーブルを階層数分だけ重ねて結合する必要があります。
Q: UNION ALL ではなく UNION にすると何が起こりますか?
A: 同一部品が複数経路で現れた場合に重複行が除外され、SUM(QTY) が小さく計算されます。したがって正しい所要量になりません。
A: 同一部品が複数経路で現れた場合に重複行が除外され、SUM(QTY) が小さく計算されます。したがって正しい所要量になりません。
Q: レベル3以降も取得したい場合は?
A: 同じパターンで自己結合を追加し、ON L2.子品番 = L3.親品番 … と階層数分チェーンを延ばします。再帰SQLを使う方法もあります。
A: 同じパターンで自己結合を追加し、ON L2.子品番 = L3.親品番 … と階層数分チェーンを延ばします。再帰SQLを使う方法もあります。
関連キーワード: 正展開、階層問い合わせ、自己結合、隣接リスト、UNION ALL
設問2:〔部品表に対する基本的な処理〕 の正展開処理について、(1)、(2)に答えよ。
(2)製品 AZ を1個製造するのに必要な、部品 P2, P3 及び P4 の所要量をそれぞれ答えよ。
模範解答
P2:2
P3:5
P4:2
解説
解答の論理構成
-
階層の把握
【問題文】には「製品のレベルを0として、階層を一つ下るごとにレベルに1を加算する」とある。図1を正展開するとレベル0 : AZ
レベル1 : P3(1)、P7(2)、P9(2)
レベル2 : P2(1×2)、P4(1×2) ※P7 の下
レベル3 : P3(2×2) ※P2 の下 -
経路ごとの掛け算
- AZ→P7→P2 … 2 × 1 = 2(P2)
- AZ→P7→P4 … 2 × 1 = 2(P4)
- AZ→P3 … 1 (P3)
- AZ→P7→P2→P3 … 2 × 1 × 2 = 4(P3)
-
品番別に集計
- P2:2
- P4:2
- P3:1+4=5
-
よって答案は 「P2:2」「P3:5」「P4:2」 となる。
誤りやすいポイント
- レベル1の 「P3」(直接子)とレベル3の 「P3」(P2 の下)を合計し忘れる。
- 「AZ→P7」の構成数 2 を掛け忘れ、P2 と P4 をそれぞれ1個と誤算する。
- 正展開では“下へたどるたびに掛け算”であり、加算から入ってしまうとミスが出やすい。
FAQ
Q: 「構成数」はどこで確認できますか?
A: 【問題文】表2“構成”テーブルの「構成数」列、及び図1の枝に付く数字が該当します。
A: 【問題文】表2“構成”テーブルの「構成数」列、及び図1の枝に付く数字が該当します。
Q: 直接子と間接子が同じ品番の場合、LLCを使ってフィルタすべきですか?
A: 今回の正展開では全レベルを対象に合算するため、LLC で除外せず品番単位で集計します。
A: 今回の正展開では全レベルを対象に合算するため、LLC で除外せず品番単位で集計します。
Q: 正展開処理と所要量計算処理の違いは?
A: 正展開は品番と数量を階層展開で取得するだけ、所要量計算は取得結果を用いて在庫を更新する点が異なります。
A: 正展開は品番と数量を階層展開で取得するだけ、所要量計算は取得結果を用いて在庫を更新する点が異なります。
関連キーワード: 正展開、構成数、階層構造、所要量、集計
設問3:〔部品表に対する基本的な処理〕 の逆展開処理について、(1)、(2)に答えよ。
(1)表3 中の SQL2の(c)、(d)に入れる適切な字句を答えよ。
また、SQL2 を用いて得られる図1中の製品の品番を全て答えよ。
模範解答
c:親品番
d:子品番
品番:AX
解説
解答の論理構成
- SQL2 の目的確認
【問題文】「逆展開処理において、レベル2に部品 P9 を使っている全ての製品の品番を調べる。」
⇒ 子品目 “P9” がレベル2 で使用される位置を起点に、1階層上(親)→さらに1階層上(製品)へさかのぼる。 - 自己結合で階層を上がる列
-
“構成” テーブルの列は【問題文】「親品番」「子品番」「構成数」。
-
子から親へ上がるにはL2.親品番 = L1.子品番しかない。
⇒ (c)=“親品番”、(d)=“子品番”。
-
- LLC=0 の意味
- 【問題文】「製品のレベルを0」と定義。
- “品目” テーブル行を LLC=0 でフィルタすれば“製品”だけ残る。
- これにより自己結合で 2 階層上がった先が製品かどうかを保証。
- 結果判定
- 図1の構成より、レベル2 で “P9” が現れるのは “AX” → “P1” → “P9”。
- 他の製品 (“AY”、“AZ”) では “P9” はレベル1 または 3 で使用。
⇒ 出力は “AX”。
誤りやすいポイント
- “L2.子品番 = 'P9'” を「レベル1 の使用」と早合点し、自己結合条件を逆に書いてしまう。
- “LLC = 0” があるので “品目” テーブルを必ず結合しなければならない点を忘れ、製品以外も結果に含めてしまう。
- “構成” テーブルに複合主索引が定義されていると想定し、索引列順を (親品番、子品番) と勘違いして列名を入れ替える。
FAQ
Q: “構成” テーブルを 2 回結合せずにレベル2 を取得できますか?
A: 再帰 SQL を使えば 1 つの WITH 句で任意レベルまで展開できます。ただし本試験の想定は SQL 標準の自己結合で 1 階層ずつ上がる方法です。
A: 再帰 SQL を使えば 1 つの WITH 句で任意レベルまで展開できます。ただし本試験の想定は SQL 標準の自己結合で 1 階層ずつ上がる方法です。
Q: “LLC” を使わずに製品行かどうかを判定する方法は?
A: 例えば “品目区分 = '製品'” で絞る設計も可能ですが、【問題文】には “LLC” が用意されているため、設問では “LLC = 0” を使う前提になっています。
A: 例えば “品目区分 = '製品'” で絞る設計も可能ですが、【問題文】には “LLC” が用意されているため、設問では “LLC = 0” を使う前提になっています。
Q: レベル3 以上を調べたい場合の書き換えポイントは?
A: 自己結合の回数を増やすか、WITH 句の再帰結合を利用して階層数をパラメータ化します。
A: 自己結合の回数を増やすか、WITH 句の再帰結合を利用して階層数をパラメータ化します。
関連キーワード: 自己結合、階層問い合わせ、ローレベルコード、逆展開処理
設問3:〔部品表に対する基本的な処理〕 の逆展開処理について、(1)、(2)に答えよ。
(2)SQL2 が参照する全てのテーブルのアクセスパスは、索引探索に決められるようにしたい。 “構成” テーブルにユニーク索引を追加する場合、その索引を構成する全ての列名を定義順に答えよ。
模範解答
子品番、親品番
解説
解答の論理構成
-
【問題文】RDBMS の主な仕様(3)
「WHERE 句…等値比較の述語の対象列が、索引キーの全体又は先頭から連続した一つ以上の列に一致」 -
SQL2 の等値比較を列挙
sql WHERE L2.子品番 = 'P9' -- L2 に対する検索条件 ON L2.親品番 = L1.子品番 -- L2 と L1 の結合条件 ON L1.親品番 = 品番 -- L1 と 品目 の結合条件・L2 は 子品番 で選択される。
・L1 は 子品番 と 親品番 の両方で結合される。 -
索引候補の比較
- 親品番→子品番
- L2:先頭列に等値条件が無い → 表探索
- 子品番→親品番
- L2:子品番='P9' で先頭列一致 → 索引探索
- L1:子品番 と 親品番 の両等値で先頭から連続一致 → 索引探索
- 親品番→子品番
-
したがって「子品番、親品番」の順でユニーク索引を定義すると、SQL2 が参照する 両方の “構成” テーブル別名(L1・L2)で索引探索 が選択される。
誤りやすいポイント
- 「ユニークなら列順は関係ない」と思い込む
→ 先頭列が等値条件に使われなければ索引探索になりません。 - 主キー=親品番、子品番 と推測し、そのまま流用する
→ L2 の検索条件を満たせずパフォーマンス低下。 - 「JOIN 句にも索引は効くから WHERE 句だけ見れば良い」と判断
→ 仕様(3)は ON 句も同じ条件で評価される点を見落としやすい。
FAQ
Q: 非ユニーク索引でも良いのでは?
A: SQL2 の目的はアクセスパスの最適化でありユニーク性は必須ではありません。ただし部品表では (子品番、親品番) の組み合わせが一意であるため、ユニークにしてデータ整合性も確保するのが一般的です。
A: SQL2 の目的はアクセスパスの最適化でありユニーク性は必須ではありません。ただし部品表では (子品番、親品番) の組み合わせが一意であるため、ユニークにしてデータ整合性も確保するのが一般的です。
Q: 親品番='AZ' のような固定値検索では親品番先頭の索引の方が速い?
A: 検索条件の列が変更されるクエリごとに最適な列順は異なります。今回の要件は「SQL2 を索引探索にすること」なので 子品番 先頭が最適です。
A: 検索条件の列が変更されるクエリごとに最適な列順は異なります。今回の要件は「SQL2 を索引探索にすること」なので 子品番 先頭が最適です。
Q: 品目表は追加の索引が不要なのですか?
A: 品目表の主索引キーは【問題文】図2より「品番」であると読み取れます。SQL2 では 品番 に等値が指定されているため追加索引は不要です。
A: 品目表の主索引キーは【問題文】図2より「品番」であると読み取れます。SQL2 では 品番 に等値が指定されているため追加索引は不要です。
関連キーワード: 索引探索、複合索引、等値比較、アクセスパス、ユニーク索引
設問4:〔Fさんの研修内容に対する K部長の指示〕 について、(1)〜(4)に答えよ。
(1)指示に対して、なぜ部品の品目区分を調べれば、SQL3の発行回数を減らすことができるのか、その理由を30字以内で述べよ。
模範解答
単体部品は子部品がないので SQL3 の発行は不要だから
解説
解答の論理構成
- 前提整理
- SQL3 は「子品番、構成数、品目区分」を取得し、次階層の部品探索に用いる。
- 品目区分が与える意味
- 「単体部品」は【問題文】にあるとおり「単独で使われる」=子品番を持たない。
- 発行回数削減の仕組み
- 手順①または③で取得した部品の品目区分が「単体部品」であれば、その部品については以後 SQL3 を発行しても結果集合が空であることが確定。
- よって単体部品を見つけた時点で探索を打ち切れば、SQL3 の呼び出し総数を「単体部品の個数」だけ減らせる。
- まとめ
- 以上から「単体部品は子部品がないので SQL3 の発行は不要」となる。
誤りやすいポイント
- 「単体部品でも誤って複数レベルを持つ可能性がある」と思い込み、SQL3 を発行し続ける。
- 品目区分が NULL の場合を考慮せずに判定ロジックを組み、例外で落ちる。
- 中間部品と単体部品を品目コードだけで判別し、区分カラムを参照しない実装にしてしまう。
FAQ
Q: 中間部品でも実際には子部品が無い場合、SQL3 をスキップして良いですか?
A: 区分が「中間部品」でも登録ミスで子部品が無いケースを否定できません。区分だけでなく件数チェックも併用すると安全です。
A: 区分が「中間部品」でも登録ミスで子部品が無いケースを否定できません。区分だけでなく件数チェックも併用すると安全です。
Q: 品目追加時に区分を誤登録するとどうなりますか?
A: 「単体部品」を「中間部品」として登録すると、空結果を得るためだけに SQL3 を発行する無駄が発生し、性能低下の原因になります。
A: 「単体部品」を「中間部品」として登録すると、空結果を得るためだけに SQL3 を発行する無駄が発生し、性能低下の原因になります。
関連キーワード: 階層構造、再帰問合せ、インデックス、トランザクション
設問4:〔Fさんの研修内容に対する K部長の指示〕 について、(1)〜(4)に答えよ。
(2)指示2 に対して、プログラムが起こす不具合とは、処理がどのようになることか、20字以内で述べよ。
模範解答
処理が無限ループして終わらない。
解説
解答の論理構成
- 【問題文】「SQL3 の構文中に下線部分の述語が指定されていなければ」
下線=「AND LLC >= :HLLC」 - 誤登録例
【問題文】「誤って部品 P1 を “構成” テーブルに登録」
既存行:P1 → P2 誤行:P2 → P1 を追加
⇒ P1 ⇄ P2 の循環参照が発生。 - 手順③は親品目を子品目に入れ替えて再帰的に SQL3 を実行
【問題文】「手順③…部品ごとに部品の品番を設定した SQL3 を用いて」 - LLC 条件ありの場合
P1 の LLC=1、P2 の LLC=2。
P2 → P1 行は LLC(=1) < :HLLC(=2) となり取得されず循環が切れる。 - LLC 条件なしの場合
条件が外れると P1 が再び取得され、手順③→⑤で延々と同じ二品目を行き来。 - したがってプログラムは「処理が無限ループして終わらない」。
誤りやすいポイント
- 循環参照の原因を「主キー衝突」と勘違いし、LLC 条件の役割を見落とす。
- 「LLC >= :HLLC は性能改善用」とだけ理解し、論理整合性チェックであることを逃す。
- 無限ループではなく「スタックオーバーフロー」など別の障害を想定してしまう。
FAQ
Q: LLC 条件を残したままでも循環参照が深いと無限ループしませんか?
A: LLC は常にレベルが大きくなる方向でしか取得しないため、1 回の再帰で LLC が増え続け循環できません。
A: LLC は常にレベルが大きくなる方向でしか取得しないため、1 回の再帰で LLC が増え続け循環できません。
Q: 誤登録を論理的に防ぐ制約は設定できないのですか?
A: 階層構造を持つ BOM では、CHECK 制約やトリガで「親LLC < 子LLC」を検証し循環参照を防止する方法があります。
A: 階層構造を持つ BOM では、CHECK 制約やトリガで「親LLC < 子LLC」を検証し循環参照を防止する方法があります。
Q: 誤登録後に無限ループを検知する仕組みはありますか?
A: 再帰回数や処理深さに上限を設け、超過時にアラートを出すことで検知・回復できます。
A: 再帰回数や処理深さに上限を設け、超過時にアラートを出すことで検知・回復できます。
関連キーワード: 循環参照、階層型問い合わせ、再帰処理、トランザクション制御、レベルコード
設問4:〔Fさんの研修内容に対する K部長の指示〕 について、(1)〜(4)に答えよ。
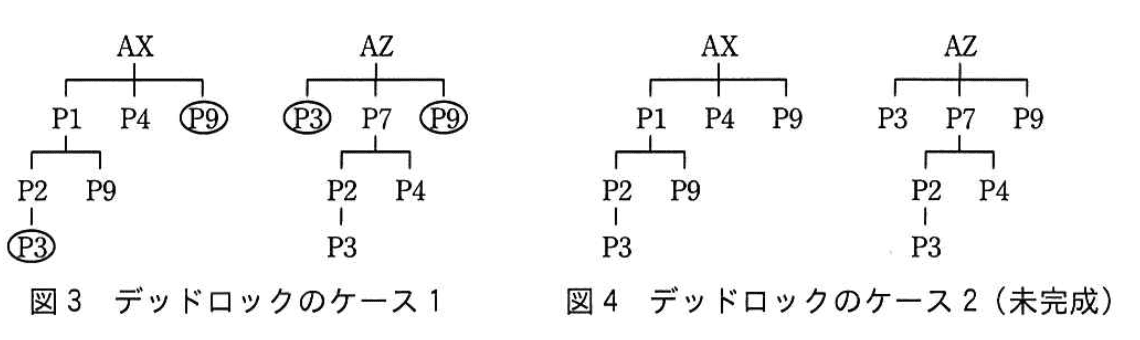
(3)指示3で述べられたデッドロックについて、F さんは、図1の製品 AX と AZ の間で起きるデッドロックの一つのケースを、ケース1として図3に示し、デッドロックに関わる2種類の部品の組合せを丸印で囲んだ。 図3に倣って、他にデッドロックが起きるケースをケース2として、図4を完成させよ。
模範解答
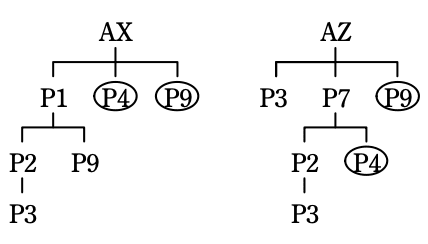
解説
解答の論理構成
- 在庫更新のロック単位
- RDBMS は行単位に排他ロックを取り、解除は COMMIT。
- 「手順②」「手順⑤」は “品番順に更新する” ので、1製品内ではロック順序は固定。
- 製品ごとのロック取得順
- 製品「AX」レベル1の子部品は【表2】より「P1」「P4」「P9」。品番順なので「P4」→「P9」。
- 製品「AZ」はレベル1で「P9」、レベル2で「P4」(「P7」の下)。したがって取得順は「P9」→「P4」。
- デッドロック条件成立
- トランザクションT₁(AX処理)が「P4」をロック済みで「P9」を要求。
- 同時にトランザクションT₂(AZ処理)が「P9」をロック済みで「P4」を要求。
- 双方が相手のロック解放を待つため循環待ち=デッドロック。
- 図4への反映
- T₁側(AXツリー):レベル1の「P4」「P9」を丸で囲む。
- T₂側(AZツリー):レベル1の「P9」とレベル2の「P4」を丸で囲む。
- これが【模範解答】の図と一致します。
誤りやすいポイント
- 「品番順に更新するからデッドロックは起きない」と早合点する。レベル違いでロック取得タイミングがずれる点を見落としやすいです。
- ケース1の「P3」「P9」の組合せだけに注目し、別レベルに同じ部品が存在する事実を読み飛ばす。
- SQL2 や正展開・逆展開処理の説明と混同し、デッドロック原因を索引やアクセスパスに求めてしまう。
FAQ
Q: なぜ「手順③」でなく「手順②」「手順⑤」が主原因になるのですか?
A: ロックを取得するのは更新系の SQL4 です。「手順③」は検索のみなので共有ロックで済み、排他ロック競合は発生しません。
A: ロックを取得するのは更新系の SQL4 です。「手順③」は検索のみなので共有ロックで済み、排他ロック競合は発生しません。
Q: ISOLATION レベルを READ COMMITTED から READ UNCOMMITTED にすれば回避できますか?
A: ロックを取得しなくなるわけではなく、排他ロックは依然必要です。整合性を犠牲にするだけで根本解決にはなりません。
A: ロックを取得しなくなるわけではなく、排他ロックは依然必要です。整合性を犠牲にするだけで根本解決にはなりません。
Q: プログラム改良の方向性は?
A: 代表的には①全製品でロック順序を統一(品番順 × レベル順)する、②在庫テーブルに対するバッチ更新を一括で実行しロック保持時間を短縮する、などがあります。
A: 代表的には①全製品でロック順序を統一(品番順 × レベル順)する、②在庫テーブルに対するバッチ更新を一括で実行しロック保持時間を短縮する、などがあります。
関連キーワード: デッドロック、排他ロック、ロック順序、トランザクション、在庫更新
設問4:〔Fさんの研修内容に対する K部長の指示〕 について、(1)〜(4)に答えよ。
(4)指示3に対して,Fさんは、プログラムの改良について、次のように説明した。“SQL4 を、製品ごとレベルごと部品ごとに実行するのではなく、製品ごと部品ごとに集計した所要量をホスト変数 HQTY に設定してから表4の手順⑥の前に実行するように、手順②〜⑤を改良しました。”
この説明に加えて、複数回の SQL4 をどのように実行するべきか20字以内で述べよ。
模範解答
SQL4 を部品の品番順に実行する。
解説
解答の論理構成
- 問題文の該当箇所
- 「手順②…在庫の引当可能数を品番順に更新する。」
- 「手順⑤…在庫の引当可能数を品番順に更新し…」
これらは当初からロック取得順を統一する設計意図を示しています。
- デッドロックが発生した理由
- 旧処理では「製品ごとレベルごと部品ごと」に SQL4 を発行し、製品AXは P1→P4→P9、製品AZは P3→P7→P9 のように別順序でロックを取得します。
- 二つのトランザクションが交差すると相互待ちが発生し、【図3】のようなデッドロックに至ります。
- 改良内容
- 「製品ごと部品ごとに集計した所要量」を求め、SQL4 をまとめて発行する。
- そして「品番順」に統一すれば、全トランザクションが必ず同じロック順序で在庫行を更新するためデッドロックが解消します。
- 20字以内の求められた記述
- 列名と実行方法を明示する必要がある → 「SQL4 を部品の品番順に実行する。」(全角19字)
誤りやすいポイント
- 「部品ごとに実行」だけでは順序が曖昧で減点対象です。
- ロックの粒度(行ロック)だから順序は無関係と誤解しないこと。行ロックでも取得順序はデッドロック要因になります。
- ORDER BY 句を UPDATE 文に直接書けない RDBMS もあるため、アプリ側で並び替えて連続実行する実装が必要です。
FAQ
Q: なぜ「品番」以外の列順では駄目なのですか?
A: 手順②・⑤が更新順として採用している列が「品番」であり、全トランザクションが一致させる基準を問題文が指定しているためです。他の列では一意順序を保証できず問題の前提を満たしません。
A: 手順②・⑤が更新順として採用している列が「品番」であり、全トランザクションが一致させる基準を問題文が指定しているためです。他の列では一意順序を保証できず問題の前提を満たしません。
Q: LOCK TABLE でテーブル全体をロックすれば簡単では?
A: 可能ですがスループットが大幅に低下し、問題文の「多品種なので…並行処理している」という要件と矛盾します。行ロック+順序統一が現実的です。
A: 可能ですがスループットが大幅に低下し、問題文の「多品種なので…並行処理している」という要件と矛盾します。行ロック+順序統一が現実的です。
関連キーワード: デッドロック、ロック順序、排他制御、行ロック、更新順序
