データベーススペシャリスト 2021年 午後1 問02
データベースの実装に関する次の記述を読んで、設問1〜3に答えよ。
クレジットカード会社のC社では、キャッシュレス決済の普及に伴いカード決済システムのオンライントランザクションの処理量が増えている。 情報システム部のFさんは、将来の処理量から懸念される性能低下の対策を検討することになった。
〔RDBMS の主な仕様〕
1.アクセス経路、区分化、再編成
(1) アクセス経路は、RDBMS によって表探索又は索引探索に決められる。 表探索では、索引を使わずに先頭ページから順に全行を探索する。 索引探索では,WHERE 句中の述語に適した索引によって絞り込んでから表の行を読み込む。
(2) テーブルごとに一つ又は複数の列を区分キーとし、区分キーの値に基づいて物理的な表領域に分割することを区分化という。
(3) 区分方法にはハッシュとレンジの二つがある。 どちらも、テーブルを検索する SQL 文の WHERE 旬の述語に区分キー列を指定すると、区分キー列で特定した区分だけを探索する。
① ハッシュは、区分キー値を基に RDBMS が生成するハッシュ値によって一定数の区分に行を分配する方法である。
② レンジは、区分キー値の範囲によって区分に行を分配する方法である。
(4) テーブル又は区分を再編成することによって、行を主キー順に物理的に並び替えることができる。 また、各ページ中に指定した空き領域を予約することができる。
(5) INSERT 文で行を挿入するとき、RDBMS は、主キー値の並びの中で、挿入行の主キー値に近い行が格納されているページに空き領域があればそのページに、なければ表領域の最後のページに格納する。 最後のページに空き領域がなければ、新しいページを表領域の最後に追加する。
2.データ入出力とログ出力
(1) データとログはそれぞれ別のディスクに格納される。 同じディスクに対し同時に入出力は行われないものとする。
(2) データ入出力とログ出力は4,000バイトのページ単位に行われる。
(3) データバッファはテーブルごとに確保される。
(4) ページをランダムに入出力する場合、SQL 処理中の CPU 処理と入出力処理は並行して行われない。これを同期データ入出力処理と呼び、SQL 処理時間は次の式で近似できる。
SQL処理時間= CPU 時間 + 同期データ入出力処理時間
(5) ページを順次に入出力する場合、SQL 処理中の CPU 処理と入出力処理は並行して行われる。これを非同期データ入出力処理と呼び、SQL 処理時間は次の式で近似できる。ここで関数 MAXは引数のうち最も大きい値を返す。
SQL処理時間 = MAX(CPU 時間、非同期データ入出力処理時間)
(6) 行を挿入、更新、削除した場合、変更内容がログとして RDBMS に一つ存在するログバッファに書き込まれる。 ログバッファが一杯の場合、トランザクショインの INSERT文 UPDATE 文、DELETE 文の処理は待たされる。
(7) ログは、データより先にログバッファからディスクに出力される。 これをログ出力処理と呼ぶ。 このとき、トランザクションのコミットはログ出力処理の完了まで待たされる。 ログ出力処理は、次のいずれかの事象を契機に行われる。
① ログバッファが一杯になった。
② トランザクションがコミット又はロールバックを行った。
③ あるテーブルのデータバッファが変更ページによって一杯になった。
〔カード決済システムの概要〕
1.テーブル
主なテーブルのテーブル構造を図1, 将来の容量見積りを表1に示す。 各テーブルの主キーには索引が定義されており、索引キーを構成する列の順はテーブルの列の順と同じである。


2.オーソリ処理 (オンライン処理)
オーソリ処理は、会員がカードで支払う際にカード有効期限、与信限度額を超過していないかなどを判定する処理である。 判定した結果、可ならば審査結果を'Y' に、否ならば 'N' に設定した行を “オーソリ履歴” テーブルに挿入する。オーソリ処理は最大 100 多重で処理される。 “オーソリ履歴” テーブルには直近5年分を保持する。
3.利用明細抽出処理 (バッチ処理)
請求書作成に必要な1か月分の利用明細の記録を “オーソリ履歴” テーブルから抽出しファイルに出力する。
〔参照処理の性能見積り〕
将来の処理時間が懸念される利用明細抽出処理の SQL文を、図2に示す。

Fさんは、利用明細抽出処理の処理時間を、次のように見積もった。
1.このSQL文での表の結合方法を調べたところ、“オーソリ履歴” テーブルを外側、“加盟店” テーブルを内側とする入れ子ループ法だった。 “オーソリ履歴” テーブルのアクセス経路は表探索だったので、(a)ページを非同期に読み込む。
2.ディスク転送速度を100M バイト/秒と仮定すれば、(a)ページを非同期に読み込むデータ入出力処理時間は、(b)秒である。
3.カード数を 1,000万枚、カード・月当たり平均オーソリ回数を80 回、審査結果が全て可であると仮定すると、“オーソリ履歴” テーブルの結果行数は、(c)行である。これに掛かる CPU 時間は、96,000 秒である。
4.この結合では、外側の表の結果行ごとに “加盟店” テーブルの主キー索引を索引探索し、“加盟店” テーブルを1行、ランダムに合計(d) 回読み込む。
5.索引はバッファヒット率 100%、テーブルはバッファヒット率 0%と仮定すれば、“加盟店” テーブルを合計で (e)ページを同期的に読み込むことになる。
同期読込みにページ当たり1ミリ秒掛かると仮定すれば、同期データ入出力処理時間は(f)秒である。
6.内側の表の索引探索と結合に掛かる CPU 時間は、1 結果行当たり 0.01 ミリ秒掛かると仮定すれば、(g)秒である。
7.外側の表の CPU 時間は 96,000 秒、内側の表の CPU 時間は(g)秒、内側の表の同期データ入出力処理時間は(f)秒なので、SQL 文の処理時間を(h)秒と見積もった。
処理時間が長くなることが分かったので時間短縮のため、次の2案を検討した。
案1:“加盟店” テーブルのデータバッファを増やしバッファヒット率 100%にする。
案2: “オーソリ履歴” テーブルの利用日列をキーとする副次索引を追加する。
〔“オーソリ履歴” テーブルの区分化〕
Fさんは、上司であるG氏から、次の課題の解決策の検討を依頼された。
課題1:月末近くに起きるオーソリ処理の INSERT文の性能低下を改善すること
課題2:将来懸念される利用明細抽出処理の処理時間を短縮すること
課題3:月初に行う “オーソリ履歴” テーブル再編成の処理時間を短縮すること
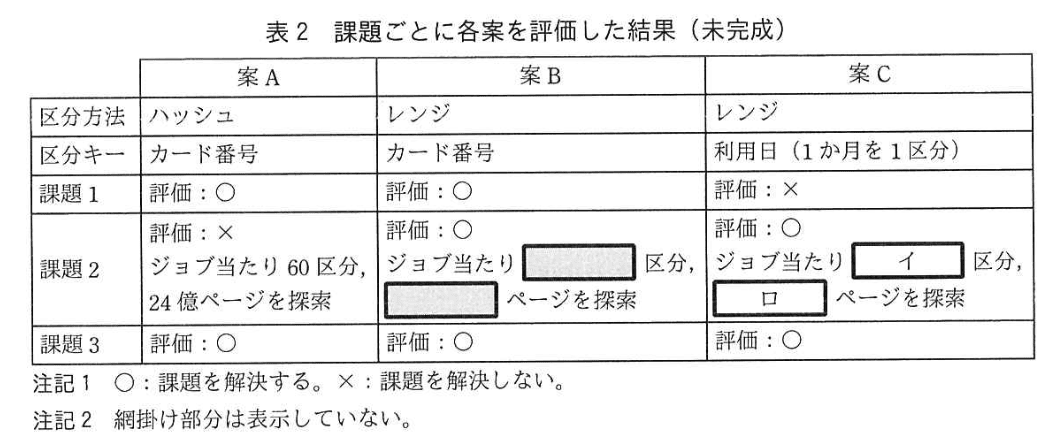
Fさんは、課題を解決するために、“オーソリ履歴” テーブルを区分化することにし、区分キーについて表2に示す3案を評価した。 いずれの案も 60 区分に行を均等に分配する前提であり、図2のSQL文を基に区分化に対応したSQL文を作成した。作成したSQL文のWHERE句を図3に示す。 利用明細抽出処理及び再編成について、アクセスする総ページ数が最小になるようにジョブを設計した。 このときジョブは、必要に応じて並列実行させる。

〔更新処理の多重化〕
“オーソリ履歴” テーブルの請求済フラグと請求日を更新する処理も同様に、将来の処理時間が懸念された。 更新処理の SQL 文を図4に示す。 更新処理はバッチ処理であり、カーソルを使用して1,000行を更新するごとにコミットする。

Fさんは、次のように、区分化と併せて、更新処理を多重化することにした。
1.“オーソリ履歴” テーブルについて、カード番号、利用日の順の組で区分キーとし、レンジによって区分化する。
2.区分ごとのジョブで更新処理を多重化する。
3.更新処理を多重化しても競合しないように、各区分を異なるディスクに配置し、データバッファを十分に確保する。
設問1:〔参照処理の性能見積り〕について、(1)〜(3)に答えよ。
(1)本文中の(a)〜(h)に入れる適切な数値を答えよ。
模範解答
a:2,400,000,000
b:96,000
c:800,000,000
d:800,000,000
e:800,000,000
f:800,000
g:8,000
h:904,000<
解説
解答の論理構成
- ページ数の決定
【問題文】「“オーソリ履歴” テーブル…ページ数 24億」より (a)=2,400,000,000。 - 非同期 I/O 時間
【問題文】「ディスク転送速度を100M バイト/秒」「ページを非同期に読み込む」
ページサイズ 4,000 バイトなので
→ (b)。 - 結果行数
【問題文】「カード数を 1,000万枚」「平均オーソリ回数 80 回」
→ (c)。 - 内側テーブルアクセス回数
入れ子ループ結合で外側結果行ごとに 1 回 → (d)=800,000,000。 - ページ読込み回数
バッファヒット率 0% ⇒ (e)=(d)=800,000,000。 - 同期 I/O 時間
1ms/頁より 秒 → (f)。 - 内側 CPU 時間
0.01ms/行 → 秒 → (g)。 - SQL 全体時間
• 外側:非同期 ⇒ 秒
• 内側:同期 ⇒ 秒
合計 秒 → (h)。
誤りやすいポイント
- 非同期 I/O なのに CPU と I/O を単純加算する
- ページサイズ “4,000 バイト” を KB と誤解する
- “1,000万” と “80” を掛け忘れ、結果行数を 80 億と誤算する
- バッファヒット率 100% を索引だけでなくテーブルにも適用してしまう
- 1ms/頁を秒換算せずに 800,000 ではなく 800 を書いてしまう
FAQ
Q: なぜ外側表の CPU 時間と I/O 時間が重複できるのですか?
A: 【問題文】「ページを順次に入出力する場合…CPU 処理と入出力処理は並行して行われる」とあるためです。表探索は先頭から順に読む順次 I/O なので非同期処理になります。
A: 【問題文】「ページを順次に入出力する場合…CPU 処理と入出力処理は並行して行われる」とあるためです。表探索は先頭から順に読む順次 I/O なので非同期処理になります。
Q: 内側の “加盟店” は索引ヒット率 100% なのにページ読込みが必要なのは?
A: 索引ページはバッファに常駐している(ヒット率 100%)ため I/O が発生しませんが、実データページはヒット率 0% と仮定しているので毎回ディスクから読み込む必要があります。
A: 索引ページはバッファに常駐している(ヒット率 100%)ため I/O が発生しませんが、実データページはヒット率 0% と仮定しているので毎回ディスクから読み込む必要があります。
Q: 904,000 秒はおよそ何時間ですか?
A: 時間、約 10 日強となり、性能問題が顕在化することが分かります。
A: 時間、約 10 日強となり、性能問題が顕在化することが分かります。
関連キーワード: 非同期I/O, 入れ子ループ結合、バッファヒット率、ページキャッシュ、同期I/O
設問1:〔参照処理の性能見積り〕について、(1)〜(3)に答えよ。
(2)案1 について、“加盟店” テーブルのデータバッファを増やすのはなぜか。 また、“オーソリ履歴” テーブルはデータバッファを増やさないのはなぜか。アクセス経路に着目し、それぞれ理由を25字以内で述べよ。
模範解答
加盟店:ランダムアクセスの処理時間を短縮できるから
オーソリ履歴:順次アクセスの処理時間に影響しないから
解説
解答の論理構成
- アクセス経路の確認
- 外側表:「“オーソリ履歴” テーブルのアクセス経路は表探索」→順次 I/O。
- 内側表:「“加盟店” テーブルを…ランダムに合計(d) 回読み込む」→ランダム I/O。
- RDBMS の I/O モデル
- 順次 I/O は【問題文引用】「SQL処理時間 = MAX(CPU 時間、非同期データ入出力処理時間」→CPU と重畳されページキャッシュの寄与が小さい。
- ランダム I/O は【問題文引用】「SQL処理時間= CPU 時間 + 同期データ入出力処理時間」→キャッシュ未命中分だけ直に遅延になる。
- 効果の差
- 「加盟店」テーブルをバッファヒット率 100%にすると同期データ入出力処理時間がほぼ 0 になる。
- 「オーソリ履歴」テーブルは全ページを順に読むため、ディスクからのストリーミング速度が律速でキャッシュを増やしても MAX 式の支配項は変わらない。
- よって
- 加盟店:ランダムアクセス短縮 → バッファ増設が有効。
- オーソリ履歴:順次アクセス → バッファ増設の効果が無視できる。
誤りやすいポイント
- 順次読込みでもキャッシュを増やせば必ず速くなると思い込む。非同期 I/O では CPU と重畳され、瓶頸はディスク帯域である。
- 「索引はバッファヒット率 100%」とあるのでテーブルも同様と早合点する。索引とテーブルは別管理。
- ランダム I/O のみが同期だと気づかず計算式を混同する。
FAQ
Q: 「加盟店」テーブルは小さいのにバッファを増やす必要がありますか?
A: ランダムアクセス回数が多いほど 1 ページ読み込み遅延が積算されるため、ページ数よりアクセスパターンが重要です。
A: ランダムアクセス回数が多いほど 1 ページ読み込み遅延が積算されるため、ページ数よりアクセスパターンが重要です。
Q: 「オーソリ履歴」テーブルを部分的にキャッシュする意味は全くないのでしょうか?
A: 抽出処理では全ページを順に読むため効果は限定的ですが、他のオンライン処理がランダムに参照する場合は別途検討価値があります。
A: 抽出処理では全ページを順に読むため効果は限定的ですが、他のオンライン処理がランダムに参照する場合は別途検討価値があります。
Q: ディスク転送速度が向上すればバッファ増設は不要ですか?
A: 転送速度が上がってもランダムアクセスはシーク等の固定遅延が残り、バッファでの回避が依然有効です。
A: 転送速度が上がってもランダムアクセスはシーク等の固定遅延が残り、バッファでの回避が依然有効です。
関連キーワード: 表探索、索引探索、非同期入出力、データバッファ、ランダムアクセス
設問1:〔参照処理の性能見積り〕について、(1)〜(3)に答えよ。
(3)案2を適用した場合、オーソリ処理の処理時間が長くなると考えられる。その理由を25字以内で述べよ。
模範解答
行の挿入時に更新する索引が増えるから
解説
解答の論理構成
- オンラインの「オーソリ処理」は最大 100 多重で大量 INSERT を実行(【問題文】)。
- 案2では「利用日列」をキーとする副次索引を追加すると明示(【問題文】)。
- RDBMS は INSERT 時に
• 行データ
• 既存の主キー索引
• 新たに追加した副次索引
の3か所すべてを更新し、各ページへの書込みとログ出力を行う。 - 索引の本数が増えるほど CPU 処理・同期 I/O・ログ出力量が増加し、結果としてオーソリ処理全体の処理時間が延びる。
- よって「行の挿入時に更新する索引が増えるから」が適切な理由となる。
誤りやすいポイント
- SELECT 性能向上だけを評価し、INSERT 負荷を見落とす。
- 「副次索引は検索専用なので更新は不要」と誤解する。
- バッファを増やせば I/O がゼロになると思い込み、ログ書込みやラッチ取得の時間を軽視する。
FAQ
Q: 副次索引を追加してもメモリヒット率が高ければ問題ないのでは?
A: メモリヒットでも索引ページへの変更はログ出力が必要で I/O は不可避です。
A: メモリヒットでも索引ページへの変更はログ出力が必要で I/O は不可避です。
Q: 索引更新のコストはどの処理に現れる?
A: CPU でのエントリ挿入、同期ディスク書込み、ログ出力待ち時間として現れます。
A: CPU でのエントリ挿入、同期ディスク書込み、ログ出力待ち時間として現れます。
Q: INSERT が少ないテーブルなら副次索引を付けても問題ない?
A: はい。読み取り中心なら索引追加のメリットが上回る場合が多いです。本問は大量 INSERT が主用途なのでデメリットが勝ります。
A: はい。読み取り中心なら索引追加のメリットが上回る場合が多いです。本問は大量 INSERT が主用途なのでデメリットが勝ります。
関連キーワード: インデックス更新、INSERT性能、同期I/O, ログ出力
設問2:〔“オーソリ履歴 ” テーブルの区分化〕 について、(1)〜(4)に答えよ。
(1)課題1について、案Aと案Bは案Cに比べてオーソリ処理の INSERT文の性能が良いと考えられる。その理由を25字以内で具体的に述べよ。
模範解答
挿入される行が複数の区分に分散するから
解説
解答の論理構成
- オンライン処理の特性
【問題文】「オーソリ処理は最大 100 多重で処理される。」
同時 INSERT が多いほど、書込み先ページの競合が性能を左右します。 - RDBMS の挿入動作
【RDBMS の主な仕様】「挿入行の主キー値に近い行が格納されているページに空き領域があればそのページに…」
つまり同じ区分に連続して挿入すると、同一ページや隣接ページを奪い合います。 - 区分キーの違い
・案A/案B:区分キー=“カード番号” → 各カードで値が散らばる → “60” 区分へ均等分配
・案C:区分キー=“利用日(1か月を1区分)” → 月末の全トランザクションが 1 区分へ集中 - 結果
案A/案Bではページロック・ページ分割が分散し INSERT が高速。
案Cではホットスポットが生じ、INSERT が遅延。 - したがって、模範解答「挿入される行が複数の区分に分散するから」となります。
誤りやすいポイント
- ハッシュ vs レンジの違いに目を奪われ、分散効果の本質が「キーの値のばらつき」であることを見落とす。
- 「60 区分あれば十分」と考え、区分キーとデータ分布の関係を検討しない。
- 案Cでも月が替われば分散すると誤解し、月末集中の INSERT 負荷を軽視する。
FAQ
Q: レンジ区分でもカード番号なら分散しますか?
A: はい。カード番号のレンジ指定でも値が均等なら 60 区分に平均的に分配され、ハッシュと同様に競合を抑制できます。
A: はい。カード番号のレンジ指定でも値が均等なら 60 区分に平均的に分配され、ハッシュと同様に競合を抑制できます。
Q: 月初の INSERT は案Cでも問題ないのでは?
A: 月初は行数が少なく問題になりにくいですが、ピークは “月末近く” です。集中する区分が 1 つしかない点がボトルネックです。
A: 月初は行数が少なく問題になりにくいですが、ピークは “月末近く” です。集中する区分が 1 つしかない点がボトルネックです。
Q: 区分化せず索引だけでは対応不可ですか?
A: 索引で検索は速くできますが、INSERT のページ競合は解決できません。データ物理配置を分散する区分化が有効です。
A: 索引で検索は速くできますが、INSERT のページ競合は解決できません。データ物理配置を分散する区分化が有効です。
関連キーワード: パーティショニング、ホットスポット、ページ分割、ロック競合、インサート性能
設問2:〔“オーソリ履歴 ” テーブルの区分化〕 について、(1)〜(4)に答えよ。
(2)課題2について、区分限定の表探索を行う場合、1 ジョブが探索する区分数及びページ数の最小値はそれぞれ幾らか。 表2中の(イ)、(ロ)に入れる適切な数値を答えよ。
模範解答
イ:1
ロ:40,000,000
解説
解答の論理構成
- 区分化の動作
【問題文】「どちらも、テーブルを検索する SQL 文の WHERE 句中の述語に区分キー列を指定すると、区分キー列で特定した区分だけを探索する。」
──案Cでは 利用日 BETWEEN :hv1 AND :hv2 が区分キーに一致するので、対象月の 1 区分のみが読まれる。 - ページ数の算定
(1) 【問題文】表1より “オーソリ履歴” は “24億” ページ。
(2) 表2の前提「いずれの案も 60 区分に行を均等に分配」より、1 区分当たりのページ数は (3) 0.4 億ページを十進表記に直すと 40,000,000 ページ。 - したがって
- (イ)= 1
- (ロ)= 40,000,000
誤りやすいポイント
- 「区分限定でも 60 区分すべてにアクセスする」と思い込む。検索条件に区分キーが含まれる場合は 1 区分で済む。
- 24 億 ÷ 60 を「4,000 万」ではなく「4,000 万ページ」と単位を落とす。
- 月単位レンジを「30 区分/月末だけ複数区分」などと勝手に再解釈する。問題文は「1か月を1区分」。
FAQ
Q: 区分化しても索引を作ればさらに速くなりますか?
A: 本問の想定は“区分限定の表探索”なので索引を使いません。索引追加は別設計ですが、全ページ走査が必要な処理なら区分限定だけで十分効果があります。
A: 本問の想定は“区分限定の表探索”なので索引を使いません。索引追加は別設計ですが、全ページ走査が必要な処理なら区分限定だけで十分効果があります。
Q: 均等に分配されない実データでも 1 区分だけ読むのでしょうか?
A: 物理的に分配が偏っても “区分キーで特定した区分だけ” という動作は同じです。ただし不均等なら 1 区分当たりのページ数は計算値とずれます。
A: 物理的に分配が偏っても “区分キーで特定した区分だけ” という動作は同じです。ただし不均等なら 1 区分当たりのページ数は計算値とずれます。
Q: 案Bと案Cはどちらが高速ですか?
A: 本問はページ数のみを比較し、案Bはジョブ当たり 60 区分を読むため案Cより多くなります。実運用では更新・再編成のしやすさも加味して選択します。
A: 本問はページ数のみを比較し、案Bはジョブ当たり 60 区分を読むため案Cより多くなります。実運用では更新・再編成のしやすさも加味して選択します。
関連キーワード: 区分化、レンジパーティション、表探索、ページ数計算、物理設計
設問2:〔“オーソリ履歴 ” テーブルの区分化〕 について、(1)〜(4)に答えよ。
(3)課題2について、案Aではカード番号に BETWEEN 述語を追加しても改善効果を得られないと考えられる。その理由を30字以内で具体的に述べよ。
模範解答
区分方法がハッシュでは探索する区分を限定できないから
解説
解答の論理構成
- 【表2】で “案 A” は「区分方法 ハッシュ」「区分キー カード番号」と明示。
- ハッシュ分割は【問題文】のとおり“ハッシュ値によって一定数の区分に行を分配”し、カード番号の大小関係を保持しません。
- よって WHERE 句に カード番号 BETWEEN :hv3 AND :hv4 を加えても、対象行がどの区分に入るかはハッシュ計算結果次第となり、“60 区分” すべてを読まざるを得ません。
- したがって課題2(抽出処理高速化)に寄与せず、「改善効果を得られない」と結論づけます。
誤りやすいポイント
- ハッシュ区分でも “区分キーを指定すれば限定できる” と早合点する
- BETWEEN ではなく “= 条件なら一部区分だけで済む” ことを混同する
- レンジ区分とハッシュ区分の特性差を覚え違える
FAQ
Q: ハッシュ区分でも等価検索なら区分数を減らせますか?
A: はい。カード番号 = :hv のような完全一致なら対応区分は一つに絞れます。
A: はい。カード番号 = :hv のような完全一致なら対応区分は一つに絞れます。
Q: レンジ区分でカード番号をキーにした場合、範囲検索は速くなりますか?
A: なります。カード番号の大小がそのまま区分の物理配置に対応するため、対象範囲に含まれる区分だけを走査できます。
A: なります。カード番号の大小がそのまま区分の物理配置に対応するため、対象範囲に含まれる区分だけを走査できます。
関連キーワード: ハッシュ区分、レンジ区分、範囲検索、パーティションプルーニング、SQL性能
設問2:〔“オーソリ履歴 ” テーブルの区分化〕 について、(1)〜(4)に答えよ。
(4)課題3 について、特に案Cは、区分キーの特徴から、案Aと案Bに比べて再編成の効率が良いと考えられる。その理由を20字以内で具体的に述べよ。
模範解答
1区分だけを再編成すれば良いから
解説
解答の論理構成
- 課題3の目的
【問題文】「課題3:月初に行う “オーソリ履歴” テーブル再編成の処理時間を短縮すること」 - 区分方式の違い
・案A:ハッシュ+「カード番号」
・案B:レンジ+「カード番号」
・案C:レンジ+「利用日(1か月を1区分)」
(いずれも【表2】より引用) - 月初再編成では「直前月」のページを並び替えるのが主目的。
利用日を月単位でレンジ分割する案Cなら、直前月は 1区分に完全包含される。 - そのため再編成ジョブが読み書きするのは 当該1区分だけ。
カード番号で散在する案A・Bは「直前月データが全60区分に散らばる」ため 60区分を全走査する必要があり、処理時間が伸びる。 - よって「1区分だけを再編成すれば良いから」という20字以内の解答が成立する。
誤りやすいポイント
- カード番号で分散すれば一見均等 I/O に見えるが、月初再編成は期間条件でありカード番号とは無関係である点を見落としがち。
- ハッシュとレンジの違いを「物理順序が無い/ある」だけで覚えていると、月単位アクセス範囲のメリットを説明しきれない。
- 「区分が60なら常に60ジョブ」と短絡し、案Cの1ジョブ完結性を見逃す。
FAQ
Q: ハッシュ区分でも並列実行すれば速くなりませんか?
A: 月初再編成では期間条件で対象行が全区分に散在するため、60ジョブを起動しても全区分の読み込みが必要です。I/O総量が減らないので効果は限定的です。
A: 月初再編成では期間条件で対象行が全区分に散在するため、60ジョブを起動しても全区分の読み込みが必要です。I/O総量が減らないので効果は限定的です。
Q: レンジ区分なら「カード番号」でも良さそうに思えますが?
A: 期間条件とカード番号に相関が無いため、月初再編成では依然として全区分を走査します。利用日レンジのみが期間条件と一致して1区分に収まります。
A: 期間条件とカード番号に相関が無いため、月初再編成では依然として全区分を走査します。利用日レンジのみが期間条件と一致して1区分に収まります。
Q: 区分再編成はどのように行われますか?
A: 多くのRDBMSでは ALTER TABLE … REORGANIZE PARTITION 等のコマンドで指定区分だけをオンライン再編成できます。案Cなら当月区分だけを対象にすれば良いので短時間で完了します。
A: 多くのRDBMSでは ALTER TABLE … REORGANIZE PARTITION 等のコマンドで指定区分だけをオンライン再編成できます。案Cなら当月区分だけを対象にすれば良いので短時間で完了します。
関連キーワード: レンジ区分、ハッシュ区分、再編成、パーティション、I/O最適化
設問3:〔更新処理の多重化〕について、(1)、(2)に答えよ。
(1)ジョブの多重度を幾ら増やしても、それ以上は更新処理全体の処理時間を短くできない限界がある。このときボトルネックになるのはログである。その理由を RDBMS の仕様に基づいて30字以内で述べよ。
模範解答
・コミットはログ出力処理の完了まで待たされるから
・ログ出力処理は並列化されないから
・ログ出力処理は逐次化されるから
・ログバッファが一杯だと更新が待たされるから
解説
解答の論理構成
- 【問題文】2.(6)
「行を挿入、更新、削除した場合、変更内容がログとして RDBMS に一つ存在するログバッファに書き込まれる。」
ここで“ 一つ ”しかないため、スレッドが増えても書込み先は共有です。 - 同 2.(6)
「ログバッファが一杯の場合、トランザクショインの INSERT文 UPDATE 文、DELETE 文の処理は待たされる。」
更新量が増えるほど待ち行列が発生します。 - 同 2.(7)
「トランザクションのコミットはログ出力処理の完了まで待たされる。」
つまり各ジョブは自分のコミット完了までブロックされ、スループット上限が“ログ出力速度”で決まります。 - データ I/O は区分ごとに分散できますが、ログ I/O は「データより先にログバッファからディスクに出力」される 1 系列の処理なので、ジョブを増やしてもここで律速されます。
以上から、30字以内の解答例は
「コミットはログ出力処理完了待ちとなるため」
となります。
「コミットはログ出力処理完了待ちとなるため」
となります。
誤りやすいポイント
- データバッファやディスク台数を増やせば解決すると考え、ログバッファの単一性を見落とす。
- 「同じディスクに対し同時に入出力は行われない」の文をデータ I/O だけの制限と誤解する。
- コミット待ち=アプリケーション側の遅延と捉え、DB 内部のログフラッシュ待ちを意識しない。
FAQ
Q: ログディスクを RAID で高速化すれば多重化限界は上がりますか?
A: I/O 性能は向上しますが、RDBMS が“逐次的に”ログをフラッシュする仕様は変わらないため、限界は緩和されるだけで消えません。
A: I/O 性能は向上しますが、RDBMS が“逐次的に”ログをフラッシュする仕様は変わらないため、限界は緩和されるだけで消えません。
Q: ログバッファを大きくすれば待ち行列は解消しますか?
A: 一時的な緩衝にはなりますが、結局コミット時にフラッシュが必要なので、抜本的なボトルネックは残ります。
A: 一時的な緩衝にはなりますが、結局コミット時にフラッシュが必要なので、抜本的なボトルネックは残ります。
関連キーワード: ログバッファ、コミット処理、ディスクI/O, 同期処理、ボトルネック
設問3:〔更新処理の多重化〕について、(1)、(2)に答えよ。
(2)更新処理では 1,000 行更新するごとにコミットしているが、仮に1行更新するごとにコミットすると、更新処理の処理時間のうち何がどのように変わるか。本文中の用語を用いて 25字以内で述べよ。
模範解答
・ログ出力処理の待ち時間の合計が長くなる。
・コミット時の待ち時間の合計が長くなる。
解説
解答の論理構成
- 更新ごとにコミットすると
⇒ コミット実行回数が「1,000倍」増加。 - コミット時の動作は【問題文】
「ログは…ディスクに出力…このとき、トランザクションのコミットはログ出力処理の完了まで待たされる」
により必ずログ出力を伴い待機が発生。 - 待機は CPU と I/O を並行できず【問題文】「同じディスクに対し同時に入出力は行われない」。
- したがって合計の「ログ出力処理の待ち時間」「コミット時の待ち時間」が増え、全体処理時間が悪化する。
- 回答文では増える対象(ログ出力処理の待ち時間/コミット時の待ち時間)と増え方(合計が長くなる)を示す。
誤りやすいポイント
- 「ログ出力量」が増えると誤解しやすいが、量はほぼ同じで“出力回数”と“待ち時間”が増える。
- データ入出力と混同し、データバッファを増やせば解消すると考えるミス。
- ログバッファの容量を見落とし“バッファ溢れ待ち”と“コミット待ち”を区別できない。
FAQ
Q: ログバッファが大きければ待ち時間は抑えられますか?
A: バッファ溢れ待ちには効果がありますが、コミット直後のログ出力待ちは回避できません。
A: バッファ溢れ待ちには効果がありますが、コミット直後のログ出力待ちは回避できません。
Q: 非同期 I/O を使えばコミット待ちは並行できますか?
A: 【問題文】で「同じディスクに対し同時に入出力は行われない」と前提化されているため、本設問の範囲では並行できません。
A: 【問題文】で「同じディスクに対し同時に入出力は行われない」と前提化されているため、本設問の範囲では並行できません。
Q: 1,000行単位コミットのメリットは?
A: ログ出力待ちを低減しスループットを確保しつつ、適度にトランザクションサイズを抑えて障害回復時間も短縮できることです。
A: ログ出力待ちを低減しスループットを確保しつつ、適度にトランザクションサイズを抑えて障害回復時間も短縮できることです。
関連キーワード: トランザクション制御、ログバッファ、コミット、I/O待ち、バッファリング
