ネットワークスペシャリスト 2011年 午後1 問02
メールアーカイブシステム導入に関する次の記述を読んで、設問1~3に答えよ。
A社は、電子メール(以下、メールという)サーバを2年前に導入した。5,000名の社員が、本社、支社、支店に設置されたPCから、このサーバを利用している。メールは業務不可欠であり、情報管理と事業継続の両面から重要な位置を占めている。
現在、A社の情報システム部では、来年度のIT予算を検討している。その中で、メールに関する次の二つの課題に対応するため、メールアーカイブシステム(以下、アーカイブという)の追加導入を計画している。
一つ目の課題は、メールデータの管理である。メールサーバが送受信する全てのメールデータを数年間保管し、必要な情報を即座に抽出できるようにする。二つ目の課題は、災害対策である。メールデータの保管場所を複数にし、片方が被災した場合にもメールデータが消失しないようにする。
A社のネットワークシステム構成図(抜粋)を図1に示す。
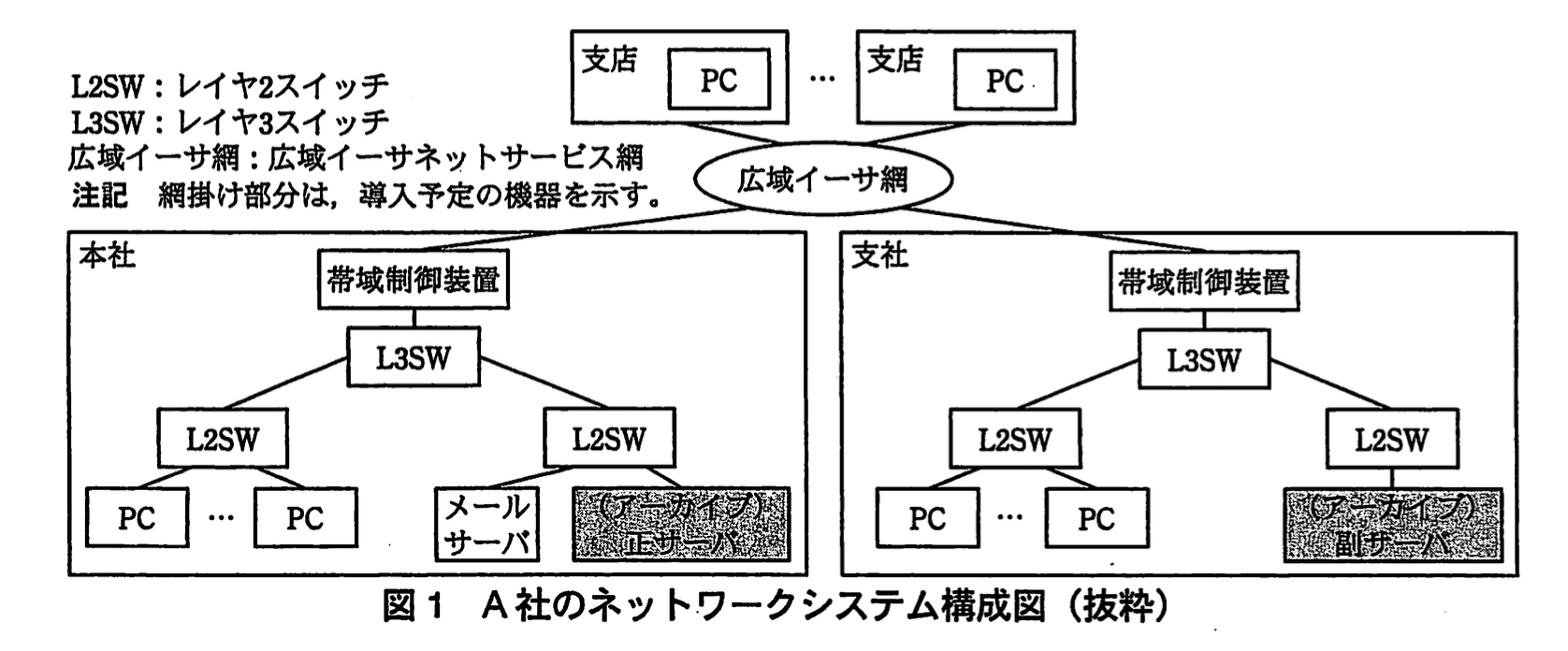
各拠点の接続には、広域イーサ網を用いている。大規模拠点である本社と支社には、帯域制御装置を設置し、広域イーサ網に送出する単位時間当たりのデータ量を通信の用途ごとに制御している。
アーカイブは、正サーバと副サーバで構成し、正サーバを本社に、副サーバを遠隔地の支社に設置する予定である。正サーバから副サーバへは大量のデータが転送されることから、帯域制御装置を使い、アーカイブに必要な帯域を割り当てる予定である。
アーカイブの処理時間には幾つか懸念事項がある。情報システム部長は、ネットワーク技術者のB君に、その検討を命じた。
〔システム要件と処理性能モデル〕
メール到着の都度、メールサーバは、全てのメールを、到着時刻順に1件ずつ正サーバへ転送する。正サーバは、受信したメールにディジタル署名を付加し、高速検索に用いるインデックス情報を作成し、データを圧縮した上で格納する。これらの処理を、保管プロセスと呼ぶ。
正サーバは、保管プロセスとは非同期に、格納されているメールを、保管時刻の古い順に、1件ずつ副サーバへ転送する。副サーバは、受信したメールを正サーバと同様に格納する。これらの処理を、複製プロセスと呼ぶ。
アーカイブのシステム要件を表1に示す。
B君は、アーカイブの所要時間に関する要件(表1中の項目 d, f)を実現できるかどうかを検討するために、図2に示す処理性能モデルを作成した。
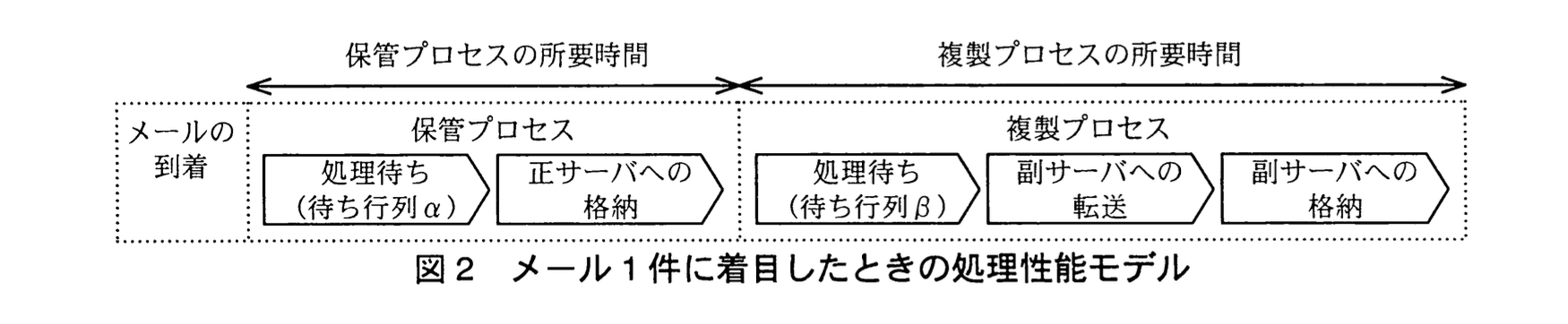
このモデルでは、メール1件に対する保管プロセスと複製プロセスを、二つの待ち行列と三つの処理に分解している。
B君は、各プロセスの所要時間を、次のように検討した。
〔保管プロセスに関する検討〕
図2中の待ち行列αについて考える。正サーバへの格納はメール到着の都度行われるので、①その到着は M/M/1 の条件を満たすと仮定し、最繁時の平均待ち時間を算出する。最繁時には、ア件/秒の処理要求(λ)が発生する。また、単位時間の平均処理数(μ)は、サーバの処理能力からイ件/秒である。したがって、利用率(ρ)はウとなり、処理途中のものを含めた待ち行列の長さの平均(平均滞列数)は4.0、平均待ち時間はエ秒と算出できる。以上から、保管プロセスの平均所要時間は、1秒未満であるから、平均所要時間の上限(表1中の項目d)は超えていない。
〔複製プロセスに関する検討〕
図2中の待ち行列βには、M/M/1は適用できない。最繁時には、利用率(ρ)が1以上となり、大量のメールが正サーバに滞留する。そこで、処理性能モデルを見直し、滞留したメールが連続的に転送されると仮定する。その場合、1日に転送されるメールデータ量(189,000件/日×12.5×バイト/件)を、転送効率50%で24時間以内に転送することになる。B君は、②これらの条件で必要となる回線速度を算出し、アーカイブに0.5Mビット/秒の帯域を割り当てることとした。
次に、B君は、メールの到着時刻と転送時刻の関係を調べるため、図3を作成した。
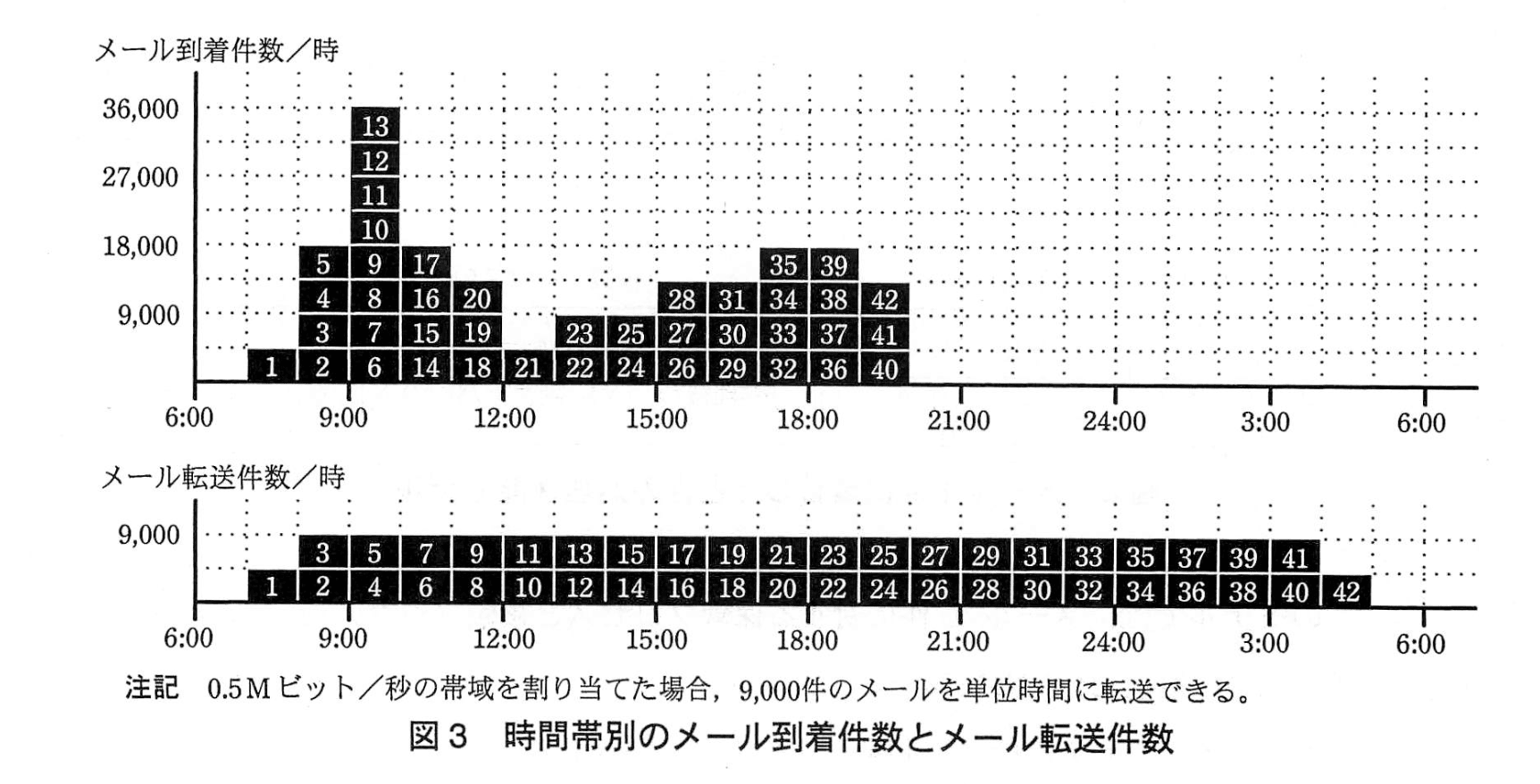
図3中の上段のグラフは、時間帯別のメールの到着数を示している。同じ時間帯に到着したメールは、到着順に4,500件を1グループとし、1~42のIDを付与している。
図3中の下段のグラフは、到着したメールが0.5Mビット/秒の帯域で順次転送される場合、どの時間帯に転送されるのかを示している。
図3によると、7:00~8:00に到着したID1のメール群は、同時間帯に転送される。一方、9:00~10:00に到着したID13のメール群の転送は、同時間帯ではなく、オ:00~カ:00に行われる。このことから、ID13のメール群の各メールに関する、複製プロセスの所要時間は、約キ時間とみなせる。
このようにして、B君は、図3から、複製プロセスの所要時間が最大となるのは、IDクのメール群であり、その所要時間は、約ケ時間になると推定し、所要時間の上限(表1中の項目f)は超えないと判断した。
以上の検討から、B君は、広域イーサ網の帯域1.5Mビット/秒(表1中の項目h)のうち、0.5Mビット/秒を割り当てることで、アーカイブの所要時間に関する要件(表1中の項目d, f)を実現できることを、情報システム部長に報告した。
設問1:〔システム要件と処理性能モデル〕について、(1)、(2)に答えよ。
(1)正サーバが、メール⇔ディジタル署名を付加する目的を、20字以内で述べよ。
模範解答
メールデータの改ざん防止のため
解説
解答の論理構成
- 【問題文】には「正サーバは、受信したメールにディジタル署名を付加し、高速検索に用いるインデックス情報を作成し、データを圧縮した上で格納する。」とあります。
- ディジタル署名は公開鍵暗号方式を利用し、電子的な“封印”を施す技術です。
- この“封印”により、署名後のデータが途中で書き換えられると検証に失敗します。
- したがって、署名の主目的はメールデータの真正性・整合性を維持し、改ざんを防ぐことです。
- 上記を踏まえ「メールデータの改ざん防止のため」とまとめれば設問の意図を満たします。
誤りやすいポイント
- ディジタル署名=暗号化と誤解し「盗聴防止」と答えてしまう。署名は暗号化とは別で改ざん検知が主目的です。
- 「送信者認証」を主目的と断定してしまう。認証機能もありますが、設問は「メール⇔ディジタル署名を付加する目的」とし、データ保管フェーズの説明なので改ざん防止が核心です。
- 長文説明を書いてしまい減点される。キーワードを絞る必要があります。
FAQ
Q: 暗号化とディジタル署名は同じものですか?
A: 別物です。暗号化は内容を読めないようにし、ディジタル署名は改ざん検知と真正性証明を行います。
A: 別物です。暗号化は内容を読めないようにし、ディジタル署名は改ざん検知と真正性証明を行います。
Q: 設問はなぜ「送信時」ではなく「保管時」に署名を付加しているのですか?
A: 送信後のメールも長期間アーカイブに保管するため、保管中の改ざんリスクを排除して証拠能力を高める狙いがあります。
A: 送信後のメールも長期間アーカイブに保管するため、保管中の改ざんリスクを排除して証拠能力を高める狙いがあります。
Q: 署名鍵の管理はどこで行うのですか?
A: 一般的には正サーバ側で安全な鍵管理システムを用意し、秘密鍵を厳重に保護します。公開鍵は検証時に利用されます。
A: 一般的には正サーバ側で安全な鍵管理システムを用意し、秘密鍵を厳重に保護します。公開鍵は検証時に利用されます。
関連キーワード: ディジタル署名, 改ざん防止, データ真正性, 公開鍵暗号, メールアーカイブ
設問1:〔システム要件と処理性能モデル〕について、(1)、(2)に答えよ。
(2)表1の要件における、本社被災に関するメールデータのRPO(リカバリポイント目標)を答えよ。
模範解答
24時間
解説
解答の論理構成
- 災害対策に関する要件は、本社が被災してもメールデータを失わないようにすることです。
引用:「二つ目の課題は、災害対策である。メールデータの保管場所を複数にし、片方が被災した場合にもメールデータが消失しないようにする。」 - どの程度の最新データまで確保できればよいかを示す指標が RPO(Recovery Point Objective)です。
- 表1の「複製プロセスに関する項目」で、遠隔地(副サーバ)へのコピーが完了すべき期限が明示されています。
引用:「f 所要時間の上限 24時間以内(前日同時刻のメールは複製されていること)」 - この「24時間以内」が、最大でどこまでのデータを失ってよいか(=許容データ損失時間)を定義しているため、RPO は「24時間」となります。
誤りやすいポイント
- RPO と RTO を混同し、復旧完了までの時間(RTO)と勘違いする。
- 「24時間以内」を“最長 1 日遅延で良い”と読み流し、数値を答え忘れる。
- 「複製プロセス」の要件を見落とし、「保管プロセス」の 1 秒を RPO と誤解する。
FAQ
Q: RPO が「24時間」ということは、最悪 1 日分のメールが失われる可能性があるのですか?
A: はい。副サーバへの複製が最大 24 時間遅延する設計なので、本社が突然被災した場合、直近 24 時間以内に到着したメールは失われるリスクがあります。
A: はい。副サーバへの複製が最大 24 時間遅延する設計なので、本社が突然被災した場合、直近 24 時間以内に到着したメールは失われるリスクがあります。
Q: RTO(復旧時間目標)は問題文に示されていますか?
A: 本問では RTO に相当する具体的な数値は示されておらず、設問も RPO のみを問うています。
A: 本問では RTO に相当する具体的な数値は示されておらず、設問も RPO のみを問うています。
Q: 複製プロセスが 24 時間以内に終われば、帯域はどの程度でもよいのですか?
A: いいえ。表1 の「転送効率」「広域イーサ網の余裕度」などを踏まえ、B 君は 0.5Mビット/秒を割り当てる設計としています。
A: いいえ。表1 の「転送効率」「広域イーサ網の余裕度」などを踏まえ、B 君は 0.5Mビット/秒を割り当てる設計としています。
関連キーワード: RPO, ディザスタリカバリ, データ複製, 広域イーサ網, 帯域制御
設問2:〔保管プロセスに関する検討〕について、(1)、(2)に答えよ。
(1)本文中の下線①について、到着条件を20字以内で述べよ。
模範解答
メールがランダムに到着する
解説
解答の論理構成
- 本文の該当部分
「①その到着は M/M/1 の条件を満たすと仮定」とあるように、待ち行列αを解析する前提としてメール到着過程を “M/M/1” 型とみなしています。 - “M/M/1” 型待ち行列の第一の前提は「到着がポアソン過程(マルコフ到着)=完全にランダムである」ことです。
- よって設問が求める「到着条件」は、メールが規則的でも一定間隔でもなく、“ランダムに到着する” という一文で表せます。
- 以上より解答は「メールがランダムに到着する」となります。
誤りやすいポイント
- 「M/M/1」を“サービスが1台”の意味だけと捉え、到着過程の仮定を回答し忘れる。
- ランダムの代わりに「一定平均間隔」などと書き、ポアソン到着を誤解する。
- 待ち行列αではなくβ側の条件(連続転送など)と混同してしまう。
- 「メールが次々に来る」など曖昧な表現で具体性を欠き、M/M/1 の必須要件を示せていない。
FAQ
Q: M/M/1 の「M」は何を表していますか?
A: 「Markovian(指数分布)」を意味し、到着間隔とサービス時間がともに指数分布であることを示します。
A: 「Markovian(指数分布)」を意味し、到着間隔とサービス時間がともに指数分布であることを示します。
Q: 到着がポアソン過程だとなぜ解析しやすいのですか?
A: メモリレス性(過去に依存しない)が成り立つため、利用率や平均待ち時間を簡潔な式で求められます。
A: メモリレス性(過去に依存しない)が成り立つため、利用率や平均待ち時間を簡潔な式で求められます。
Q: 本社と支社間の帯域設定(0.25Mビット/秒単位)と到着条件は関係しますか?
A: 直接は関係しません。到着条件は待ち行列理論上の仮定、帯域は複製プロセスの転送能力に影響します。
A: 直接は関係しません。到着条件は待ち行列理論上の仮定、帯域は複製プロセスの転送能力に影響します。
関連キーワード: ポアソン過程, 待ち行列理論, メモリレス性, 利用率
設問2:〔保管プロセスに関する検討〕について、(1)、(2)に答えよ。
(2)本文中のア~エに入れる適切な数値を答えよ。
模範解答
ア:10
イ:12.5
ウ:0.8
エ:0.32
解説
解答の論理構成
-
最繁時の到着件数を秒に換算
【問題文】「最繁時到着件数 36,000 件/時(9:00~10:00)」
1時間は3,600秒なので
よって
ア:10 -
サーバの平均処理能力
【問題文】「サーバの処理能力 12.5件/秒」
これをそのまま μ とするので
イ:12.5 -
利用率 ρ の算出
よって
ウ:0.8 -
平均待ち時間 の算出
M/M/1 待ち行列の平均待ち時間は
により
したがって
エ:0.32 -
要件との照合
【問題文】「平均所要時間の上限 1秒以内」
保管プロセスの待ち時間 0.32 秒は 1 秒未満であり、条件を満たすと判断できる。
誤りやすいポイント
- 件/時をそのまま λ にしてしまい、ρ が 1 を超えてしまう計算ミス。必ず秒単位に換算すること。
- 平均待ち時間にサービス時間を含めてしまい、 を使って 0.4 秒ではなく 0.32 秒になる理由を誤認するケース。
- 表中の「12.5件/秒」を 12.5秒/件と読み違え、λ と μ を逆にしてしまう誤読。
FAQ
Q: ρ が 1 に近い場合でも M/M/1 の式は使えますか?
A: ρ<1 であれば理論上は適用可能です。本問では 0.8 と十分余裕があるため適用に問題はありません。
A: ρ<1 であれば理論上は適用可能です。本問では 0.8 と十分余裕があるため適用に問題はありません。
Q: 平均待ち時間 0.32 秒はキュー待ちだけですか、処理時間も含みますか?
A: 0.32 秒はキュー待ち時間 です。処理中の 1/μ=0.08 秒を加えた系全体の平均滞在時間は 0.40 秒になります。
A: 0.32 秒はキュー待ち時間 です。処理中の 1/μ=0.08 秒を加えた系全体の平均滞在時間は 0.40 秒になります。
Q: サービス率 μ を件/秒で与える理由は?
A: M/M/1 モデルでは到着率 λ、サービス率 μ の単位を合わせる必要があるためです。秒単位に統一するとスループットと待ち時間を直接比較できます。
A: M/M/1 モデルでは到着率 λ、サービス率 μ の単位を合わせる必要があるためです。秒単位に統一するとスループットと待ち時間を直接比較できます。
関連キーワード: M/M/1, 利用率, 到着率, 平均待ち時間, 待ち行列理論
設問3:〔複製プロセスに関する検討〕について、(1)〜(3)に答えよ。
(1)本文中の下線②について、必要となる回線速度を求めよ。答えは小数第3位を四捨五入して、小数第2位まで求めよ。
模範解答
0.44
解説
解答の論理構成
-
1日に転送すべきメール量を算定
- 問題文の引用:
「189,000件/日×12.5×10^3バイト/件」 - 計算
- 問題文の引用:
-
ビット換算
- 1byte=8bit より
- 1byte=8bit より
-
24時間で送る場合の平均転送レート(ペイロード)
- 問題文の引用:
「24時間以内」 - 1日=
- 計算
- 問題文の引用:
-
回線効率を考慮
- 問題文の引用:
「転送効率 50%」 - 実効帯域=物理帯域×効率 ⇒ 物理帯域=実効帯域/0.5
- 計算
- 問題文の引用:
-
指定の丸め
- 問題文の指示:
「小数第3位を四捨五入して、小数第2位まで」 - を四捨五入 → 0.44
- 問題文の指示:
誤りやすいポイント
- byte と bit の換算(×8)を忘れる。
- 「転送効率 50%」を読み飛ばし、÷0.5 をしない。
- 秒数換算で 1日=86,400 秒を取り違える(例:84,600 秒など)。
- 最後の四捨五入を誤り 0.43 や 0.45 にしてしまう。
FAQ
Q: 転送効率が 50% とは具体的に何を指しますか?
A: プロトコルヘッダや再送制御によるオーバヘッドで、回線帯域のうち実際にデータを運べる割合が半分という意味です。そのため計算では実効レート÷0.5 を行います。
A: プロトコルヘッダや再送制御によるオーバヘッドで、回線帯域のうち実際にデータを運べる割合が半分という意味です。そのため計算では実効レート÷0.5 を行います。
Q: ピーク時ではなく 1日総量で計算して良いのはなぜですか?
A: 検討箇所は「24時間以内 に全件を複製」という要件であり、正サーバでの滞留を想定しているため、ピーク時の瞬時帯域ではなく 1日総量を平均化した値で判断します。
A: 検討箇所は「24時間以内 に全件を複製」という要件であり、正サーバでの滞留を想定しているため、ピーク時の瞬時帯域ではなく 1日総量を平均化した値で判断します。
Q: 計算結果が 0.44Mbit/s でも、帯域制御装置の最小設定単位は 0.25Mbit/s ですが?
A: 0.44Mbit/s は 0.25Mbit/s の倍数ではないため、実際の設定では切り上げて 0.5Mbit/s を確保し、マージンを持たせています。
A: 0.44Mbit/s は 0.25Mbit/s の倍数ではないため、実際の設定では切り上げて 0.5Mbit/s を確保し、マージンを持たせています。
関連キーワード: M/M/1, 回線容量計算, 帯域利用率, データ転送効率, バイト/ビット換算
設問3:〔複製プロセスに関する検討〕について、(1)〜(3)に答えよ。
(2)本文中のオ~ケに入れる適切な整数を答えよ。
模範解答
オ:13
カ:14
キ:4
ク:42
ケ:9
解説
解答の論理構成
-
必要な転送能力を算出
- 表1「転送効率」は“50%”、割当帯域は本文中“0.5Mビット/秒”です。
- 有効帯域は
- 1件当たりの平均サイズは表1“12.5×10^3バイト/件”、すなわち
- 1時間(3 600 秒)で転送できるメール件数は = 9\,000\,[\text{件/時}]$$
-
グループ単位の考え方
- 本文に“到着順に4,500件を1グループとし、1~42のIDを付与”とあるので、
1時間に処理できる 9 000 件はちょうど2グループに相当します。
- 本文に“到着順に4,500件を1グループとし、1~42のIDを付与”とあるので、
-
ID13 がいつ転送されるか
- 転送開始は本文の例示どおり“7:00~8:00に到着したID1…同時間帯に転送”。
- 7:00 から 1 時間ごとに 2 グループずつ処理されるため
- 7:00~13:00 の 6 時間で 2×6=12 グループ消化
- ID13 は 13 番目なので次の 1 時間で処理
⇒ 13:00~14:00 に転送
- よって
- オ=13
- カ=14
-
ID13 の複製プロセス所要時間
- 到着は“9:00~10:00”、転送完了は 14:00。
- おおよその差は 4 時間 ⇒ キ=4
-
最大所要時間を与えるグループ
- 全 42 グループを 2 グループ/時で処理すると必要時間は
- 7:00 開始の場合、最後の転送は 7:00+21h=翌 4:00。
- 最終グループは ID42 なので ク=42
- ID42 の到着は夕方(18:00~19:00 頃)で、転送完了は翌 4:00。
おおよそ 9 時間差 ⇒ ケ=9
- 全 42 グループを 2 グループ/時で処理すると必要時間は
誤りやすいポイント
- 50% の転送効率を掛け忘れ、必要帯域や件数/時を 2 倍に見積もってしまう。
- 4,500 件を 1 時間で転送できると誤解し、グループ数カウントがずれる。
- 「到着から転送完了まで」の時間を平均ではなく開始-開始で計ってしまう。
- グループ番号と時間帯を取り違え、ID13 や ID42 の位置がずれる。
FAQ
Q: 9 000 件/時をどうして導けるのですか?
A: 有効帯域は “0.5Mビット/秒×転送効率50%=0.25Mビット/秒”。
1時間当たりの転送量は 0.25×10^6×3 600=9.0×10^8 ビット。
1件は 100 000 ビットなので 9.0×10^8÷100 000=9 000 件です。
A: 有効帯域は “0.5Mビット/秒×転送効率50%=0.25Mビット/秒”。
1時間当たりの転送量は 0.25×10^6×3 600=9.0×10^8 ビット。
1件は 100 000 ビットなので 9.0×10^8÷100 000=9 000 件です。
Q: ID13 の所要時間を「5 時間」と数えてはいけないのですか?
A: 所要時間は「到着時刻帯の開始(9:00)から転送完了(14:00)」を大まかに測るため
9→14 で 5 時間と思いがちですが、到着は 9:00~10:00 にばらけます。
本文では “約” として平均的に 4 時間とみなしています。
A: 所要時間は「到着時刻帯の開始(9:00)から転送完了(14:00)」を大まかに測るため
9→14 で 5 時間と思いがちですが、到着は 9:00~10:00 にばらけます。
本文では “約” として平均的に 4 時間とみなしています。
Q: 最大待ち時間が 24 時間を超えないことはなぜ保証できますか?
A: 42 グループ×4 500 件=189 000 件を 9 000 件/時で送ると 21 時間で完了します。
転送開始 7:00 でも翌 4:00 に終わるため、表1「所要時間の上限 24時間以内」を満たします。
A: 42 グループ×4 500 件=189 000 件を 9 000 件/時で送ると 21 時間で完了します。
転送開始 7:00 でも翌 4:00 に終わるため、表1「所要時間の上限 24時間以内」を満たします。
関連キーワード: M/M/1, 有効帯域, データ圧縮, 災害対策, 待ち行列
設問3:〔複製プロセスに関する検討〕について、(1)〜(3)に答えよ。
(3)割り当てる帯域を0.5Mビット/秒から1.5Mビット/秒に増やした場合、複製プロセスの所要時間は最長何時間となるかを整数で答えよ。また、その根拠を50字以内で具体的に述べよ。
模範解答
所要時間:1
根拠:到着件数が転送可能件数を上回るのはピーク時間帯だけで、次の時間帯には滞留が解消するため
解説
解答の論理構成
- 転送性能の基準
- 問題文は「0.5Mビット/秒の帯域を割り当てた場合、9,000 件のメールを単位時間に転送できる。」と示しています。
- 帯域を3倍に増速
- 「本社・支社間の余裕度…最大1.5Mビット/秒まで利用可能」とあるので、0.5→1.5Mビット/秒へはちょうど3倍です。
- よって転送件数も3倍の となります。
- 到着件数との比較
- 「最繁時到着件数 36,000 件/時(9:00~10:00)」は転送能力を上回り、この 1 時間だけ 9,000 件の滞留が発生します。
- その後の時間帯は 27,000 件/時以下(図3上段)なので、到着分と滞留分を合わせても 件/時の転送能力で吸収できます。
- 最大遅延の算出
- 滞留する 9,000 件は“次の 1 時間”で転送されるため、ピーク時に到着したメールの複製プロセスは最長でも 1 時間後に完了します。
∴ 最長所要時間は 1 時間、根拠は下記のとおりです。
【所要時間】1
【根拠】到着件数が転送可能件数を上回るのはピーク時間帯だけで、次の時間帯には滞留が解消するため
【所要時間】1
【根拠】到着件数が転送可能件数を上回るのはピーク時間帯だけで、次の時間帯には滞留が解消するため
誤りやすいポイント
- 0.5→1.5Mビット/秒で「帯域は+1.0Mビット/秒」と捉え、1.0Mビット/秒分しか能力を増やさず計算してしまう。
- 「転送効率 50%」を再計算に含め忘れ、理論帯域の3倍ではなく6倍と誤認。
- 図3の到着分布を見ずに「36,000 件/時が続く」と思い込み、遅延が連鎖すると判断してしまう。
FAQ
Q: 27,000 件/時の算出に転送効率 50% は再度掛けるのですか?
A: 9,000 件/時という値は既に「50%効率」を考慮した結果なので、帯域を3倍にすると 27,000 件/時でそのまま使用します。
A: 9,000 件/時という値は既に「50%効率」を考慮した結果なので、帯域を3倍にすると 27,000 件/時でそのまま使用します。
Q: 24 時間要件との比較は不要ですか?
A: 1 時間で複製が終わるので、自然に「24時間以内」を大きく下回り、追加検証は不要です。
A: 1 時間で複製が終わるので、自然に「24時間以内」を大きく下回り、追加検証は不要です。
Q: メールサイズは計算に影響しませんか?
A: 0.5Mビット/秒→9,000 件/時という換算にサイズが組み込まれているため、帯域だけを倍率換算すれば足ります。
A: 0.5Mビット/秒→9,000 件/時という換算にサイズが組み込まれているため、帯域だけを倍率換算すれば足ります。
関連キーワード: M/M/1モデル, 帯域制御, 転送効率, バックログ, ピークトラフィック
