応用情報技術者 2011年 秋期 午後 問02
ハッシュ法と排他制御に関する次の記述を読んで、設問1~3に答えよ。
T社は、ソフトウェア開発を行う会社である。現在、LAN環境で利用するクライアントサーバシステム(以下、本システムという)を開発中である。
本システムは、クライアントPC上で画面にデータを表示する画面プログラムと、画面プログラムが使用するデータをサーバ上で管理するデータ管理プログラムから構成される。
〔データ構造〕
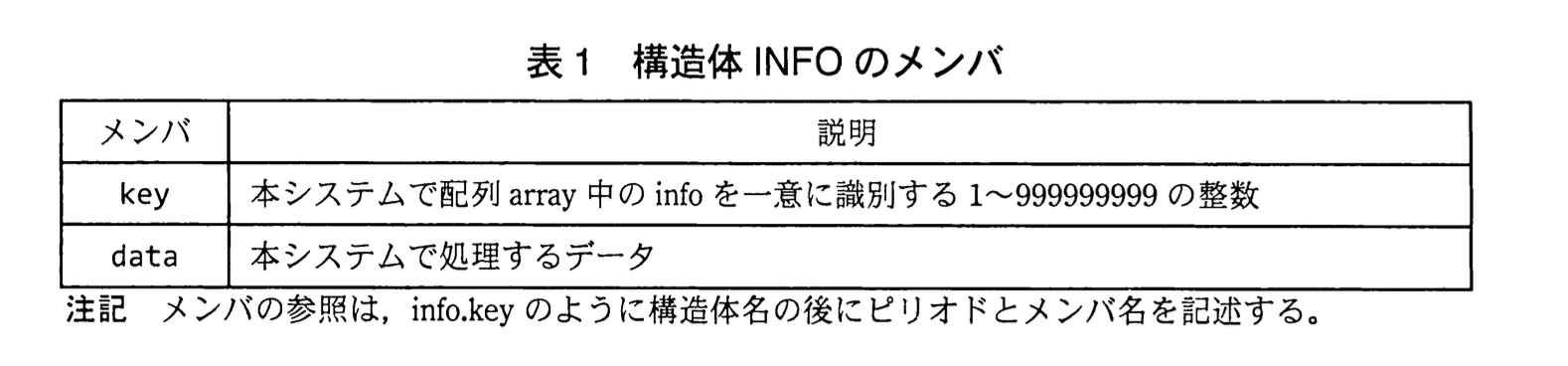
配列arrayは、クライアントPCで使用するデータinfoを格納する配列であり、配列の添え字は1~Nである。infoのデータ型は構造体INFOである。表1に構造体INFOのメンバを示す。構造体メンバの初期値は、全て0(未使用を意味する)を設定する。
ハッシュ関数Hash(key)は、keyを基にデータの格納位置を算出して、戻り値として戻す。格納位置は1~Nの整数となる。関数Hash(key)が、異なるkeyから同じ格納位置を算出することを、シノニムの発生という。この影響で、格納位置の配列要素が既に使用されていて、データを格納できないことがある。この場合は、配列arrayを格納位置の次から順次検索し、最初に見つかった未使用の配列要素にデータを格納する。配列arrayの最後に到達しても未使用の配列要素がない場合には、配列arrayの先頭に戻り、未使用の配列要素の検索を続ける。
〔データ管理プログラム〕
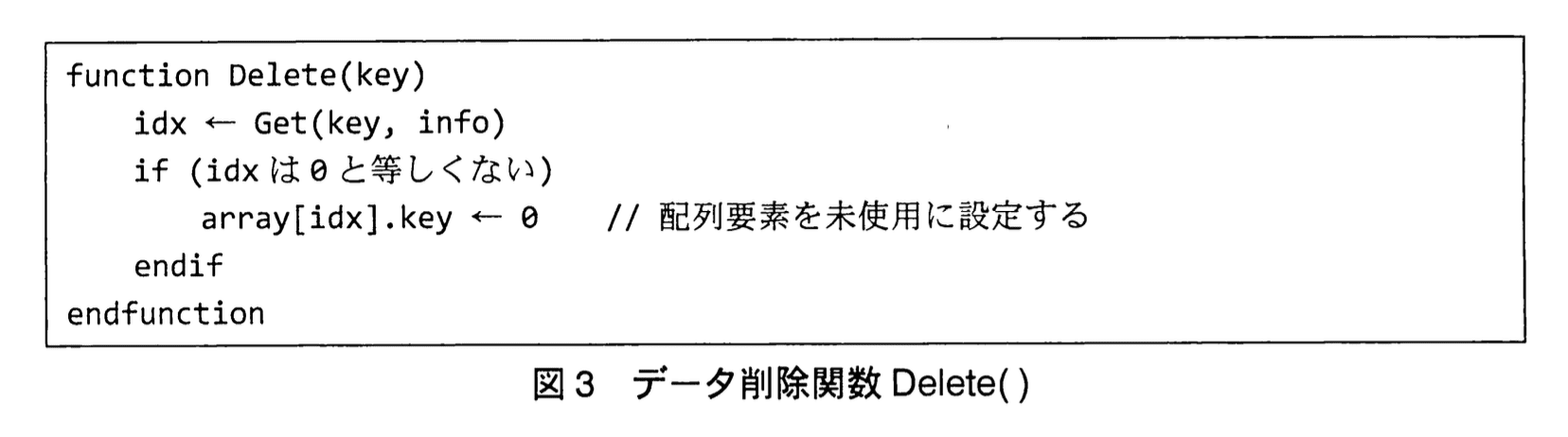
図1のデータ格納関数Set()、図2のデータ取得関数Get()、図3のデータ削除関数Delete()をデータ管理プログラムと呼ぶ。
関数Get()は、データ取得に成功すると、取得したデータを引数infoに格納する。
関数Set()と関数Get()は戻り値として格納位置を戻す。処理結果が正しくない場合は、戻り値として0を戻す。


 〔画面プログラム〕
ユーザは、画面プログラムを使用して、infoの作成、検索、編集、削除を行う。
画面プログラムから配列arrayへのアクセスにはデータ管理プログラムを使用する。
複数のクライアントPCから同時に配列arrayにアクセスできるので、画面プログラムから配列arrayへのアクセスには排他制御が必要である。そこで、バイナリセマフォの確保関数Lock()、解放関数Unlock()を使用した占有ロックを用いて排他制御を実現する。
図4は画面プログラムの一部である。ユーザが画面から入力したkeyとdataが配列array内に存在しない場合は、データを配列arrayに格納している。
〔画面プログラム〕
ユーザは、画面プログラムを使用して、infoの作成、検索、編集、削除を行う。
画面プログラムから配列arrayへのアクセスにはデータ管理プログラムを使用する。
複数のクライアントPCから同時に配列arrayにアクセスできるので、画面プログラムから配列arrayへのアクセスには排他制御が必要である。そこで、バイナリセマフォの確保関数Lock()、解放関数Unlock()を使用した占有ロックを用いて排他制御を実現する。
図4は画面プログラムの一部である。ユーザが画面から入力したkeyとdataが配列array内に存在しない場合は、データを配列arrayに格納している。
コーディングを完了したプログラムのテストを実施したところ、次のような障害が発生した。
①あるデータを削除すると、別のデータの取得に失敗した。削除するデータと取得できなくなるデータには関連があり、再現方法は容易に分かった。プログラムを修正して障害は解決した。
②複数のクライアントPCから図4の画面プログラムの操作を同時に行った場合に、同じkeyをもつデータが重複して配列arrayに格納されてしまった。この障害は、再現頻度が低く、原因究明に時間が掛かった。この障害についてもプログラムを修正して障害は解決した。
設問1:
図1及び図2中のア〜エに入れる適切な字句を答えよ。
模範解答
ア:countはNより小さい
イ:idxはNより大きい
ウ:Hash(key)
エ:array[idx].keyはkeyと等しくない
解説
解答の論理構成
-
ループ継続条件に着目
【問題文】では、シノニムが発生したときに「配列arrayを格納位置の次から順次検索し…未使用の配列要素の検索を続ける」とあります。
しかし全要素を探索し切ったらオーバフローと判断しなければなりません。その判定に使われるのが count です。よって
ア=「countはNより小さい」
とすれば、count が N に達した時点で while ループを抜けられます。 -
配列末尾に到達したかの判定
検索中に idx ← idx + 1 した結果、idx が N を超えたら「配列の最後を検出」したことになります。従って
イ=「idxはNより大きい」
となります。 -
Get() の探索開始位置
データ取得はハッシュ表の本来の格納位置から探し始めます。ハッシュ関数の定義は【問題文】「ハッシュ関数Hash(key)…戻り値として戻す」より明確なので
ウ=「Hash(key)」
です。 -
Get() で探索を続ける条件
取得対象が見つかるまでリニアプロービングを続けるためには、 a. その位置が使用中であること
b. まだ全件探索していないこと
c. “探している key と一致していない” こと
の3点が必要です。c. が エ に対応し、原文の書式通り
エ=「array[idx].keyはkeyと等しくない」
になります。
誤りやすいポイント
- ア を「array[idx].key が 0 でない」としてしまうミス
既使用・未使用の判定だけでは全探索かどうかを判断できません。 - イ を「idxはNと等しい」と書くミス
idx は 1 から始まり idx ← idx + 1 で進むので、末尾検出は “超えた” 瞬間です。 - エ を「array[idx].keyは0より大きい」などと誤記
“未使用ではない” だけでは一致判定が抜け、無限ループの原因になります。
FAQ
Q: count を使わずに探索しても動きませんか?
A: オーバフロー時に無限ループを防ぐために「countはNより小さい」で打ち切る必要があります。
A: オーバフロー時に無限ループを防ぐために「countはNより小さい」で打ち切る必要があります。
Q: 末尾検出を idx == N で判定してはいけませんか?
A: idx ← idx + 1 後にチェックするため、“超えた” 状態(idxはNより大きい)が正確です。
A: idx ← idx + 1 後にチェックするため、“超えた” 状態(idxはNより大きい)が正確です。
Q: 削除後に取得に失敗した障害の原因は?
A: 削除時に array[idx].key ← 0 とするだけでは削除位置より後ろに連続したシノニム鎖が切れ、Get() が途中で探索を止めてしまうためです(いわゆる削除ホール問題)。
A: 削除時に array[idx].key ← 0 とするだけでは削除位置より後ろに連続したシノニム鎖が切れ、Get() が途中で探索を止めてしまうためです(いわゆる削除ホール問題)。
関連キーワード: ハッシュ関数、リニアプロービング、オープンアドレス法、セマフォ、排他制御
設問2:本文中の下線①の障害について、(1)、(2)に答えよ。
(1)障害の原因を40字以内で述べよ。
模範解答
シノニムの発生を考慮せずに配列要素を削除するから
解説
解答の論理構成
- 問題文には、ハッシュ表上で「シノニムの発生」を避けるために「配列arrayを格納位置の次から順次検索し、最初に見つかった未使用の配列要素にデータを格納」する ― すなわち線形探索(線形開放)を採用していることが示されています。
- この方式では、衝突して後ろに退避したデータを探し当てるまで、Hash(key) で得た位置から順に配列をたどる必要があります。途中のどれか 1 要素でも“不連続”になると、それより後ろのデータは見つけられません。
- ところが「図3のデータ削除関数Delete()」は、対象データを削除する際、該当要素をただちに“未使用”状態に戻します(key を “0” に初期化)。
- これにより、衝突で後方に格納されていた別 key の探索経路が途中で途切れ、「あるデータを削除すると、別のデータの取得に失敗」する現象が発生します。
- したがって障害①の直接原因は、「線形開放で生じるシノニムを考慮せずに要素を空欄へ戻したこと」と論理づけられます。
誤りやすいポイント
- 削除処理=要素を空に戻すだけ、と短絡的に実装しがち
- “探索経路が途切れる”理屈をハッシュ表の図解なしでイメージしづらい
- 線形開放と「墓標(トゥームストーン)」方式の違いを混同
- 取得失敗を「ハッシュ関数の不備」と誤診し、アルゴリズム側を調べない
FAQ
Q: なぜ“未使用”に戻すのがいけないのですか?
A: 線形開放では、衝突で後ろへ追いやられたデータを探すときに連続領域を前提に順走査します。途中が空欄になると「ここ以降にはデータがない」と誤判断し、後続のデータを見落としてしまいます。
A: 線形開放では、衝突で後ろへ追いやられたデータを探すときに連続領域を前提に順走査します。途中が空欄になると「ここ以降にはデータがない」と誤判断し、後続のデータを見落としてしまいます。
Q: 対策としてよく使われる方法は?
A: 代表的には (1) 削除位置に“墓標”を置いて空欄と区別する、(2) 削除後に後ろの要素を再配置して連続性を保つ、(3) チェイン法など別の衝突解決法へ変更する――などがあります。
A: 代表的には (1) 削除位置に“墓標”を置いて空欄と区別する、(2) 削除後に後ろの要素を再配置して連続性を保つ、(3) チェイン法など別の衝突解決法へ変更する――などがあります。
Q: ハッシュ関数を変えれば解決できますか?
A: 衝突頻度は下がるかもしれませんが、ゼロにはならないため根本解決にはなりません。削除アルゴリズムの見直しが不可欠です。
A: 衝突頻度は下がるかもしれませんが、ゼロにはならないため根本解決にはなりません。削除アルゴリズムの見直しが不可欠です。
関連キーワード: ハッシュ表、線形開放、シノニム、削除アルゴリズム、墓標方式
設問2:本文中の下線①の障害について、(1)、(2)に答えよ。
(2)データ管理プログラムの修正の組合せとして適切な文章を解答群の中から二つ選び、記号で答えよ。
解答群
ア:関数Delete()中の“array[idk].key ← ”の0を-1に変更する。
イ:関数Get()中のif文の条件“array[idx].keyはkeyと等しい”を削除して、無条件にデータを取得する。
ウ:関数Get()中のwhile文の条件“(array[idx].keyは1以上)かつ(array[idx].keyは999999999以下)”を“(aray[idx].keyは0以外)”に変更する。
エ:関数Set()中でオーバフローを検出した場合は、配列arrayを動的に拡張してデータを格納する。
オ:関数Set()中のif文の条件“countはNより小さい”を削除して、無条件にデータを格納する。
カ:関数Set()中のwhile文の条件“array[idx].keyは1以上”を削除する。
模範解答
ア、ウ
解説
解答の論理構成
-
事象の整理
- 仕様では、未使用のスロットを “key が 0” で表し、格納済みは “key が 1~999999999” としています(本文【表1】「本システムで配列 array 中の info を一意に識別する 1〜999999999 の整数」)。
- 線形探索型のハッシュ(オープンアドレス法)では、シノニム発生後に “先頭スロット→次スロット…” と連鎖状にデータが格納されます。連鎖途中の要素を削除する場合、連鎖が途切れると後続の要素を探索できなくなるという欠点があります。
-
障害①のメカニズム
- 関数Delete() は削除対象を見つけると array[idx].key ← 0 としています(図3)。
- 関数Get() の while 条件は (array[idx].key は 1 以上) かつ (array[idx].key は 999999999 以下) です。
- したがって、先頭スロットが削除で “0” になると探索ループが即座に終了し、連鎖の後ろにあるはずのデータを検出できず「取得失敗」になります。これが本文の ①あるデータを削除すると、別のデータの取得に失敗した の正体です。
-
必要な修正方針
(a) “0 =未使用” と “削除済みだが連鎖の維持が必要” を区別する。
(b) Get() の探索条件を“削除済みキー”でも継続できる形にする。 -
選択肢の検証
- ア:array[idx].key ← -1 とすることで「-1 を tombstone(墓石)として扱い、連鎖は切らさない」→(a)を満たす。
- ウ:Get() の while 条件を (array[idx].key は 0 以外) に変更し、-1 であっても探索継続 →(b)を満たす。
- 他の選択肢
・イ:無条件取得は誤り。
・エ・オ:容量拡張や無条件格納は障害①と無関係。
・カ:探索条件を削るだけでは連鎖維持ができず矛盾。
よって正解は ア、ウ です。
誤りやすいポイント
- “削除時に 0 を入れる=空き” と考えがちだが、オープンアドレス法では tombstone が必須。
- 配列の循環探索ばかりに注目し、探索ループの停止条件(1~999999999の範囲チェック)が原因と気付きにくい。
- 障害①と②を混同し、排他制御系(Lock/Unlock)の修正を答えてしまう。
FAQ
Q: -1 以外の値でも tombstone にできますか?
A: 未使用と衝突しない値(0 でも 1~999999999 でもない値)なら何でも構いません。本問題では -1 が提案されています。
A: 未使用と衝突しない値(0 でも 1~999999999 でもない値)なら何でも構いません。本問題では -1 が提案されています。
Q: Get() の条件を “key が一致するまで” にすれば tombstone は不要では?
A: 連鎖途中に“完全な空き”が現れると検索ループが終了してしまいます。tombstone で「まだ後ろにデータがあるかもしれない」ことを示す必要があります。
A: 連鎖途中に“完全な空き”が現れると検索ループが終了してしまいます。tombstone で「まだ後ろにデータがあるかもしれない」ことを示す必要があります。
Q: 削除後に Set() で同じハッシュ位置に再格納できますか?
A: はい。Set() は “array[idx].key が -1” を「使用中」と判断するので skip し、連鎖最後で “0(未使用)” を見つけて格納します。
A: はい。Set() は “array[idx].key が -1” を「使用中」と判断するので skip し、連鎖最後で “0(未使用)” を見つけて格納します。
関連キーワード: オープンアドレス法、線形探索、墓石フラグ、ハッシュ衝突、配列添字循環
設問3:
本文中の下線②の障害について、原因を25字以内で述べよ。
模範解答
データの取得後に排他制御を開始するから
解説
解答の論理構成
- 【問題文】には、障害②が「複数のクライアントPCから図4の画面プログラムの操作を同時に行った場合に、同じkeyをもつデータが重複して配列arrayに格納」されるとあります。
- 図4のコード順は
「idx ← Get(key, info) // データが配列 array に格納済か確認」
「Lock()」
となっており、取得処理 Get() が排他制御より先に実行されています。 - 2台のクライアントが同じ key で同時に Get() を実行すると、両者とも「未格納」と判定します。その後にそれぞれ Lock() を取り、Set() で同じ key のデータを格納してしまいます。
- この流れから、障害②の直接原因は「データ取得後に排他制御を開始する」点にあります。
- よって模範解答は「データの取得後に排他制御を開始するから」です。
誤りやすいポイント
- Set() が独立して排他制御をしていると早合点し、画面プログラム側の Lock() 位置を見落とす。
- シノニム処理(オープンアドレス法)のバグと混同し、重複格納をハッシュアルゴリズムの問題と誤解する。
- Lock() を取得してから Get() を呼び出すと、検索時にも排他が掛かり性能低下を招くのでわざと後ろに置いたと考え、設計ミスだと気づけない。
FAQ
Q: Set() 内のループで重複 key をチェックすれば良いのでは?
A: Set() は新たな空き要素を探すだけで、既存要素の key と同一かどうかを判定していません。画面プログラム側で未格納判定を行う設計なので、Lock() を前に移す必要があります。
A: Set() は新たな空き要素を探すだけで、既存要素の key と同一かどうかを判定していません。画面プログラム側で未格納判定を行う設計なので、Lock() を前に移す必要があります。
Q: Get() を排他制御の外に出すと性能が上がるのでは?
A: 確かにロック範囲は狭くなりますが、一貫性が保障されません。同一 key の重複登録を防ぐ要件があるなら、検索と格納を同一クリティカルセクションに入れることが不可欠です。
A: 確かにロック範囲は狭くなりますが、一貫性が保障されません。同一 key の重複登録を防ぐ要件があるなら、検索と格納を同一クリティカルセクションに入れることが不可欠です。
Q: バイナリセマフォ以外の方法でも解決できますか?
A: 読み取り専用処理と書き込み処理を分けるならリーダライタロックの導入も有効ですが、本設問は単純な占有ロックで原因を除去できるため、まずは Lock() の位置を変更するのが基本的な解決策です。
A: 読み取り専用処理と書き込み処理を分けるならリーダライタロックの導入も有効ですが、本設問は単純な占有ロックで原因を除去できるため、まずは Lock() の位置を変更するのが基本的な解決策です。
関連キーワード: 排他制御、バイナリセマフォ、クリティカルセクション、ハッシュ法、オープンアドレス法
