応用情報技術者 2011年 春期 午後 問02
集計表をHTMLに変換して出力するプログラムに関する次の記述を読んで、設問1〜4に答えよ.
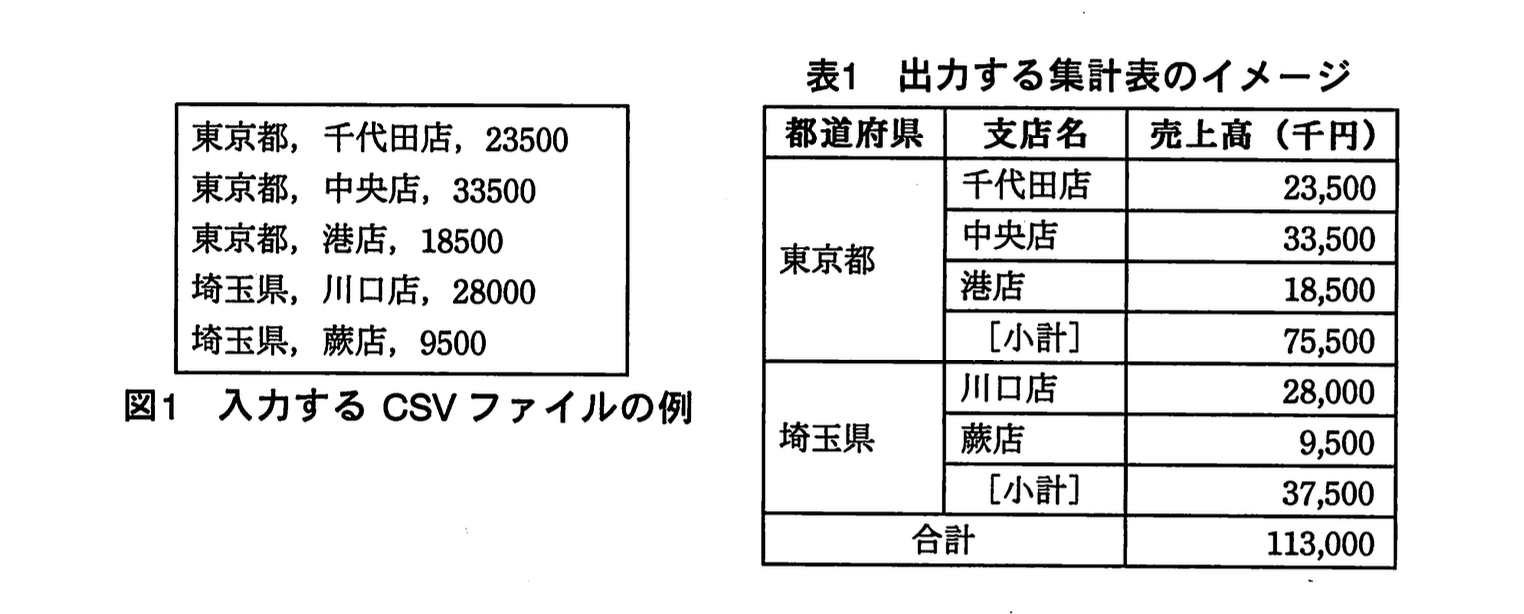
図1に示すような、都道府県及び支店ごとに整理された売上高一覧のCSVファイルを入力し、表1のような都道府県ごとの売上高の集計表をHTMLで出力するプログラムがある. ここで、一つの都道府県における支店数は500未満とする.
〔使用する HTML について〕
使用するHTMLタグ及びその属性を表2に示す.

表1をHTMLで記述した例を図2に示す。

〔プログラムの概要〕
プログラムの処理手順の概要を次の(1)〜(5)に、使用する構造体、配列、変数及び関数の一部を表3に、構造体及び配列の使い方を表4に示す。
(1) CSVファイルを配列 CSVArray に読み込む。
(2) <table>の開始タグ及び集計表のヘッダ行を出力する。
(3) 配列 CSVArray の先頭要素から末尾まで1件ずつ読み、配列 shitenArray に支店名と売上高を追加していく。途中で都道府県が変わった場合、支店名と売上高を追加する前に、①都道府県、支店名、売上高、小計の HTML タグ及びデータを出力し、配列 shitenArray の全要素を削除する。
(4) ②都道府県、支店名、売上高、小計の HTML タグ及びデータを出力する。
(5) 合計及び<table>の終了タグを出力する。

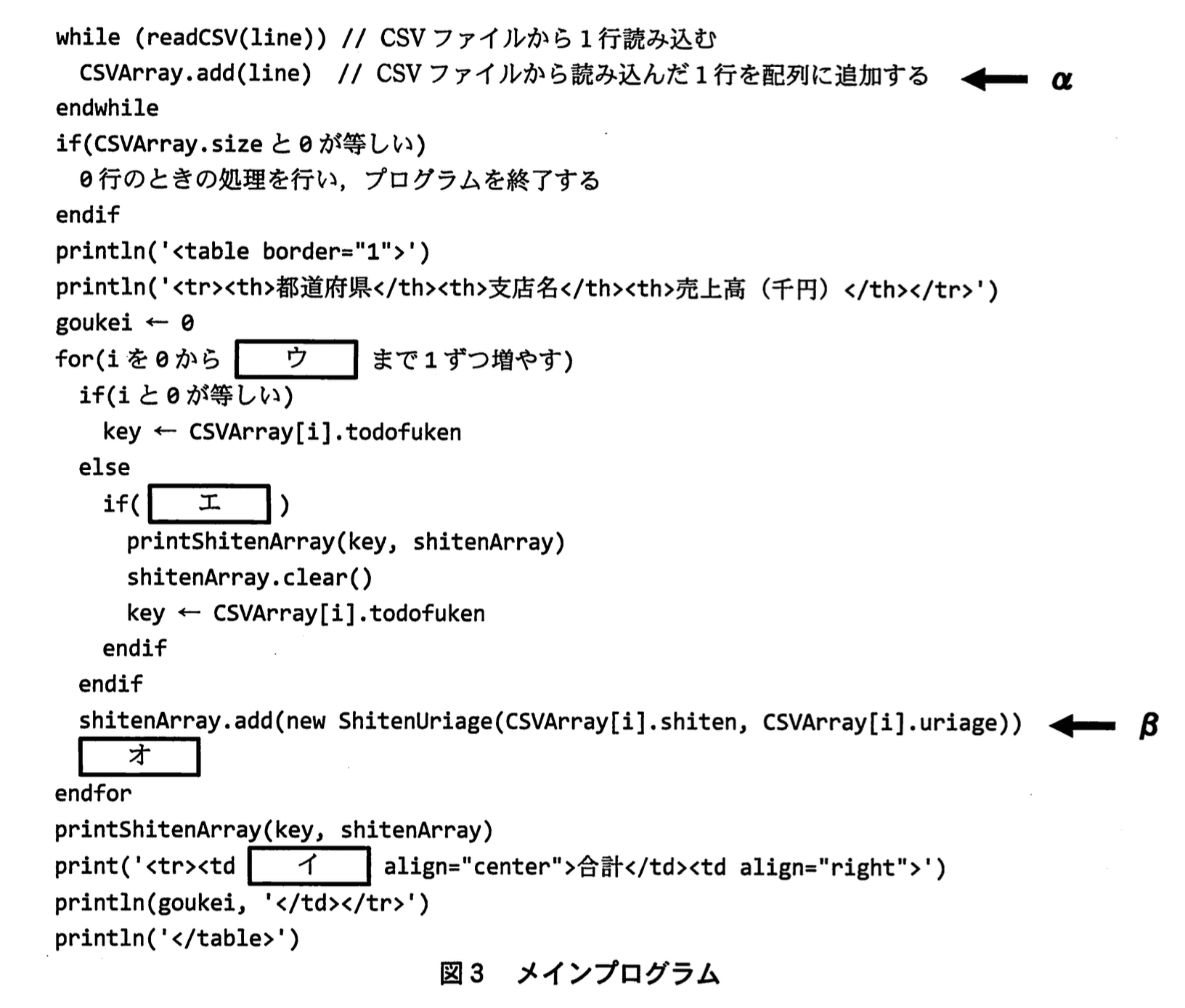
メインプログラムを図3に、関数 printShitenArray のプログラムを図4に示す。ここで、図3の イ には、図2の イ と同じ字句が入る。

〔プログラムに関する考察〕
・図3のαでは、CSVファイルのデータを1行ずつ全行を配列に読み込んでいる。その結果、読み込むデータ量が多いほど、時間だけでなく ク を多く消費してしまう、という問題がある。
・図3のβでは、③都道府県のセルを出力するために、同一都道府県の各支店の情報をその都度出力するのではなく、順次配列 shitenArray に追加している。
設問1:
図2中のア、イに入れる適切な字句を答えよ。
模範解答
ア:rowspan=“4”
イ:colspan=“2”
解説
解答の論理構成
-
表1の「東京都」ブロックを確認すると、データ行は
“千代田店”、“中央店”、“港店”、“[小計]” の4行です。
【問題文】では「<td ア>東京都」と示し、同一都道府県で4行を縦に結合する必要があります。HTMLでは縦結合に rowspan を用いるので、ア には
rowspan="4"
が入ります。数字“4”は行数そのものを表しています。 -
「合計」行は、見出し3列(都道府県/支店名/売上高)のうち、最初の2列を横に結合して1セルにまとめています。プログラムの該当部分は
print('<td イ align="center">合計')
であり、このあと売上高セルを1つだけ出力しているため、残りの2列を1セルにする必要があります。横結合は colspan を使うので、イ には
colspan="2"
が入ります。
以上より
ア:rowspan="4"
イ:colspan="2"
ア:rowspan="4"
イ:colspan="2"
誤りやすいポイント
- [小計] 行を数え忘れて「3」としてしまう。rowspan に含める行はデータ行だけでなく小計行も対象です。
- rowspan と colspan を取り違える。縦結合は rowspan、横結合は colspan です。
- 「合計」行で colspan="3" と書いてしまう。実際には売上高列を残すので2列分だけ結合します。
FAQ
Q: 小計行を別の色や太字にしたい場合はどうすればよいですか?
A: に style 属性や class を追加し、CSS で装飾します。今回の設問は装飾が要件外なので align のみです。
A: に style 属性や class を追加し、CSS で装飾します。今回の設問は装飾が要件外なので align のみです。
Q: rowspan や colspan に 0 を指定できると聞きましたが?
A: HTML5では rowspan="0" は非推奨です。本設問のように具体的な結合数を明示してください。
A: HTML5では rowspan="0" は非推奨です。本設問のように具体的な結合数を明示してください。
Q: データ行が500行を超える場合の対策は?
A: 問題設定では「一つの都道府県における支店数は500未満」と明示されています。超えるケースではメモリ使用量や rowspan の数値上限を考慮した分割出力が必要です。
A: 問題設定では「一つの都道府県における支店数は500未満」と明示されています。超えるケースではメモリ使用量や rowspan の数値上限を考慮した分割出力が必要です。
関連キーワード: HTMLテーブル, rowspan, colspan, CSV, 集計処理
設問2:
図3中のウ〜オに入れる適切な字句を答えよ。
模範解答
ウ:CSVArray.size - 1
エ:CSVArray[i].todofukenとkeyが等しくない
オ:goukei ← goukei + CSVArray[i].uriage
解説
解答の論理構成
- ループ回数の決定([ウ])
- 原文では「配列 CSVArray の先頭要素から末尾まで1件ずつ読み」とあります。配列の添字は 0 から始まるので、末尾の添字は CSVArray.size - 1 です。したがって for ループの上限は 「CSVArray.size - 1」 となります。
- 都道府県が変わったかの判定([エ])
- プログラム概要(3) に「途中で都道府県が変わった場合…」と記されており、現在行の todofuken と直前に保持している key を比較します。よって条件式は 「CSVArray[i].todofukenとkeyが等しくない」 です。
- 合計値の更新([オ])
- (5) に「合計及びの終了タグを出力する」とあるため、ループ内で売上高を累積する必要があります。売上高は CSVArray[i].uriage に格納されているので、合計変数 goukei に加算する文は 「goukei ← goukei + CSVArray[i].uriage」 です。
以上より、
[ウ] CSVArray.size - 1
[エ] CSVArray[i].todofukenとkeyが等しくない
[オ] goukei ← goukei + CSVArray[i].uriage誤りやすいポイント
- 末尾添字の取り違え
size と size - 1 を混同し、1 件読み飛ばすケースが頻出です。 - 判定対象の変数ミス
key を更新するタイミングを誤り、同一都道府県内でも printShitenArray を呼び出してしまう失敗が見られます。 - 合計計算の位置
小計出力後に goukei を加算してしまい、都道府県ごとの小計が二重計上になるミスが起こりやすいです。
FAQ
Q: 都道府県が 1 つしかない場合でも printShitenArray を 2 回呼び出しますか?
A: 最後の 1 回だけです。ループ中に都道府県が変わらなければ条件式が偽のままなので、終了後の呼び出し 1 回で済みます。Q: rowspan の値はどこで決まりますか?
A: printShitenArray 内で shitenArray.size を利用し、「<td rowspan=...>」 を生成します。これにより支店数に応じて自動的に行結合が行われます。Q: メモリ使用量を減らすにはどうすれば良いですか?
A: 考察にある α 部分で全行を保持せず、読み込んだ行を即座に処理・破棄するストリーム方式に変更することで、配列 CSVArray によるメモリ消費を抑制できます。
関連キーワード: 配列操作, ループ制御, 条件分岐, HTMLテーブル, メモリ効率 - 末尾添字の取り違え
- (5) に「合計及びの終了タグを出力する」とあるため、ループ内で売上高を累積する必要があります。売上高は CSVArray[i].uriage に格納されているので、合計変数 goukei に加算する文は 「goukei ← goukei + CSVArray[i].uriage」 です。
設問3:
図4中のカ、キに入れる適切な字句を答えよ。
模範解答
カ:shitenArray.size - 1
キ:shitenArray.size + 1
解説
解答の論理構成
-
ループ回数の決定
- 図4では
for(i を 0 からカまで 1 ずつ増やす)
とあります。 - 支店情報は配列 shitenArray に格納されており、配列要素数を取得する方法は表4の
配列名.size … 配列の現在の要素数を取得する。
- 配列の添字は 0 から始まるため、最後の要素添字は size - 1 です。
- 以上より カ = shitenArray.size - 1 となります。
- 図4では
-
rowspan 値の決定
- 都道府県セルは「支店行+小計行」の行数分だけ縦方向に連結します。
- 支店行の数は shitenArray.size、小計行は常に 1 行なので、総行数は
shitenArray.size + 1。 - 図4の
print('<td rowspan=" キ ">', key, '</td>')
にはこの総行数を設定する必要があるため、キ = shitenArray.size + 1 となります。
誤りやすいポイント
- カ を shitenArray.size としてしまい、配列の範囲外アクセスを起こす。
- キ を shitenArray.size としてしまい、小計行で都道府県セルが欠落する。
- 行数計算で「小計行」を忘れ、+ 1 を付け忘れる。
- .size をメソッド呼び出し風に書いてしまい、問題の記法と不一致となる。
FAQ
Q: shitenArray.size - 1 と <= を併用しても良いですか?
A: 図4の構文は「から カ まで」と明示されており、境界値を直接指定する形式です。そのため shitenArray.size - 1 が最適です。
A: 図4の構文は「から カ まで」と明示されており、境界値を直接指定する形式です。そのため shitenArray.size - 1 が最適です。
Q: 都道府県セルを小計行に含めない実装でも正しいのでは?
A: 表1・図2の HTML では都道府県セルが小計行にも及んでおり、問題文の要件でも同様です。従って rowspan は 支店行 + 1 が必須となります。
A: 表1・図2の HTML では都道府県セルが小計行にも及んでおり、問題文の要件でも同様です。従って rowspan は 支店行 + 1 が必須となります。
Q: rowspan にゼロを指定しても自動調整されませんか?
A: HTML 仕様では rowspan="0" は「残りの行すべてに及ぶ」という意味ですが、問題文は固定値を求めています。設問の意図に沿い shitenArray.size + 1 を明示する必要があります。
A: HTML 仕様では rowspan="0" は「残りの行すべてに及ぶ」という意味ですが、問題文は固定値を求めています。設問の意図に沿い shitenArray.size + 1 を明示する必要があります。
関連キーワード: rowspan, 配列添字, ループ制御, 動的配列, HTMLテーブル
設問4:〔プログラムに関する考察〕について、(1)、(2)に答えよ。
(1)本文中のクに入れる適切な字句を答えよ。
模範解答
ク:記憶領域 又は メモリ
解説
解答の論理構成
- 問題文は次のように指摘しています。
「その結果、読み込むデータ量が多いほど、時間だけでなく ク を多く消費してしまう」。
ここでプログラムは CSV から全行を CSVArray に格納しており、行数が増えるほど配列の使用量が増大します。 - プログラムが消費するリソースには主に「処理時間」と「記憶装置(主記憶)」の 2 つがあります。
- 処理時間はすでに文中で明示されているため、もう一方に当たる語を求めれば良いことが分かります。
- 配列に全件を保持すると膨らむのは RAM 上のデータサイズです。情報処理試験ではこれを「記憶領域」または「メモリ」と表現します。
- 以上より、ク には「記憶領域 又は メモリ」が入ると結論づけられます。
誤りやすいポイント
- 「記憶装置」「ディスク容量」など二次記憶を指す用語を書いてしまう
→ 問題の文脈は配列(RAM)なので不適切です。 - 「CPU 使用量」と答えてしまう
→ 処理時間に相当し、すでに別の語で言及済みです。 - 英語のまま「memory」とだけ記述すると、日本語指定の設問の場合は減点対象になる可能性があります。
FAQ
Q: 「記憶領域」と「メモリ」はどちらで書くべきですか?
A: どちらか一方をそのまま書けば正解です。問題文が「又は」で許容しています。
A: どちらか一方をそのまま書けば正解です。問題文が「又は」で許容しています。
Q: ディスク I/O も増えませんか?
A: 1 行ずつ読み込んで配列に追加しているため、読み込み時点でのディスク I/O は一定です。増えるのは主に配列保持のための主記憶量です。
A: 1 行ずつ読み込んで配列に追加しているため、読み込み時点でのディスク I/O は一定です。増えるのは主に配列保持のための主記憶量です。
Q: もし CSV が非常に大きい場合の改善策は?
A: 配列に溜め込まず、読み込んだ行を即時集計・出力し、不要になったら破棄するストリーム処理方式が有効です。
A: 配列に溜め込まず、読み込んだ行を即時集計・出力し、不要になったら破棄するストリーム処理方式が有効です。
関連キーワード: メモリ, 配列, CSV, リソース管理, パフォーマンス最適化
設問4:〔プログラムに関する考察〕について、(1)、(2)に答えよ。
(2)本文中の下線③のように処理する理由を、HTMLタグ及びその属性を用いて、40字以内で述べよ。
模範解答
HTMLタグ<td>のrowspan属性の値を決める必要があるから
解説
解答の論理構成
- プログラムは「③都道府県のセルを出力するために、同一都道府県の各支店の情報をその都度出力するのではなく、順次配列 shitenArray に追加している」と記述されています。
- その理由は、図2の都道府県セルが複数行にまたがる設計だからです。HTMLではセル結合を行う際、タグのrowspan属性にまたがる行数を指定する必要があります。
- 行数は「一つの都道府県における支店数は500未満」と問題文にあるように可変であり、CSVを読み終えるまで確定できません。
- したがって、まず支店レコードをshitenArrayへ蓄積し、総件数を把握したうえで都道府県を出力する――これが下線③の処理方針です。
- 以上より、模範解答「HTMLタグ<td>のrowspan属性の値を決める必要があるから」となります。
誤りやすいポイント
- ではなくのrowspanと誤記する。
- colspanと混同し、横方向の結合と勘違いする。
- 先に都道府県セルを出力してしまい、後から正しいrowspan値に修正できなくなるロジックを組む。
- 「支店数が500未満だから固定値でよい」と早合点して配列蓄積を省略する。
FAQ
Q: rowspan値は必ず支店数と一致させないといけませんか?
A: はい。同一都道府県内で何行分の支店情報が続くかを正確に指定しないと、HTMLテーブルの構造が崩れます。
A: はい。同一都道府県内で何行分の支店情報が続くかを正確に指定しないと、HTMLテーブルの構造が崩れます。
Q: rowspanを動的に計算せずに最大値で埋めても表示されますか?
A: 非表示セルも生成されるため見た目は乱れ、空行が増えるなど可読性が損なわれます。仕様上も誤りです。
A: 非表示セルも生成されるため見た目は乱れ、空行が増えるなど可読性が損なわれます。仕様上も誤りです。
Q: shitenArray.clear()はいつ呼ばれますか?
A: 都道府県が変わった瞬間に小計行を含めて出力し終えた後、次の都道府県の支店情報を格納するために呼ばれます。
A: 都道府県が変わった瞬間に小計行を含めて出力し終えた後、次の都道府県の支店情報を格納するために呼ばれます。
関連キーワード: HTMLテーブル, rowspan, 動的行結合, 配列バッファリング, セル結合
