応用情報技術者 2015年 秋期 午後 問06
人事情報のデータ構造に関する次の記述を読んで、設問1~3に答えよ。
R社では、人事システムの改善を検討している。現行システムでは、現時点での情報しか管理していないが、過去の履歴や将来の発令予定も管理できるようにしたいと考えている。
現行システムでの社員と部署のE-R図を図1に示す。部署の階層は木構造になっており、再帰リレーションシップで表現している。最上位は会社で、下に向かって本部、部、課などが配置されている。上位部署IDには、上位部署の部署IDを保持し、最上位である会社の上位部署IDにはNULLを設定する。社員は必ず一つの部署だけに所属している。部署には部署長が必ず一人存在するが、一人の社員が複数の部署の部署長を兼任している場合もある。また、各社員に携帯電話機を1台ずつ配布しており、電話番号は部署ではなく、社員に割り当てられている。
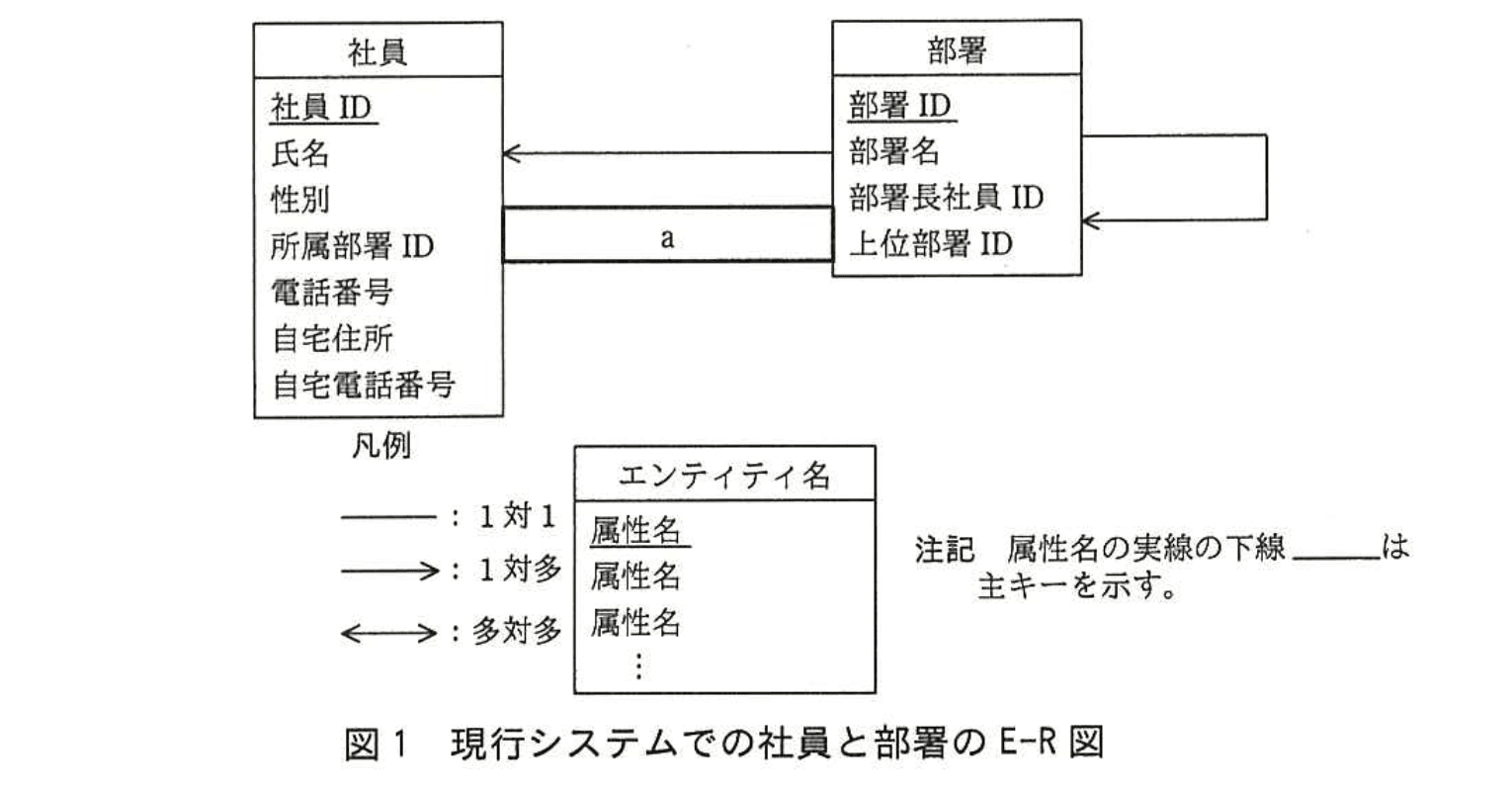
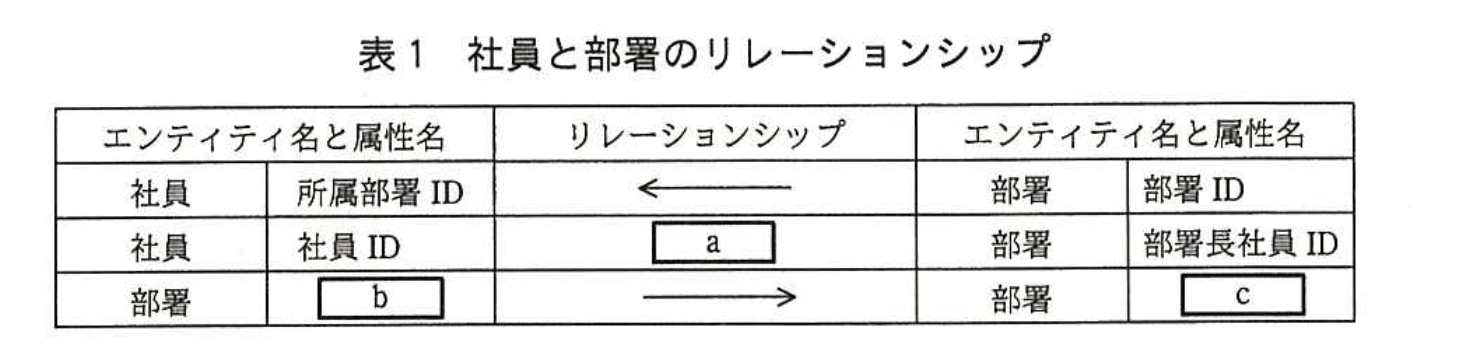
図1のリレーションシップが、どの属性と関連しているかを表1に示す。表1の1行目は、エンティティ“社員”の属性“所属部署ID”がエンティティ“部署”の属性“部署ID”を参照する外部キーとなっていて、“社員”と“部署”の間には多対1のリレーションシップがあることを示している。多対1のリレーションシップの多側が外部キーの属性、1側が主キーの属性と対応している。
現行システムは、図1のE-R図のエンティティ名を表名に、属性名を列名にして、適切なデータ型で表定義した関係データベースによって、データを管理している。
指定した部署とその配下の全ての部署の部署ID、部署名、上位部署IDを出力するSQL文を図2に示す。ここで、“:部署ID”は、指定した部署の部署IDを格納する埋込み変数である。

図2では、SQL:1999で導入されたWITH RECURSIVE構文を用いて再帰的なクエリを実現している。まず2、3行目のSELECTで、埋込み変数“:部署ID”で指定した部署の部署ID、部署名、上位部署IDから成る1行の表“関連部署”が導出される。次に5、6行目のSELECTで、“関連部署”の中にある部署IDと一致する上位部署IDをもつ部署の部署ID、部署名、上位部署IDから成る行の集まりが新たに表“関連部署”として導出される。これが、表“関連部署”の新たな行がなくなるまで繰り返される。最後に8行目のSELECTで、それまで導出された“関連部署”の全ての行について部署ID、部署名、上位部署IDが出力される。
〔新システムでの履歴管理〕
新システムでは、(1)~(4)の要件を実現したいと考えている。
(1) 指定した社員が、今までに所属していた部署の履歴が分かる。
(2) 指定した日の、会社全体の部署構造が分かる。
(3) 人事異動後の部署、所属の情報をあらかじめ入力しておき、異動が発生したらすぐに有効とする。
(4) 所属情報以外の社員の情報は履歴管理する必要はなく、最新の情報だけを管理すればよい。
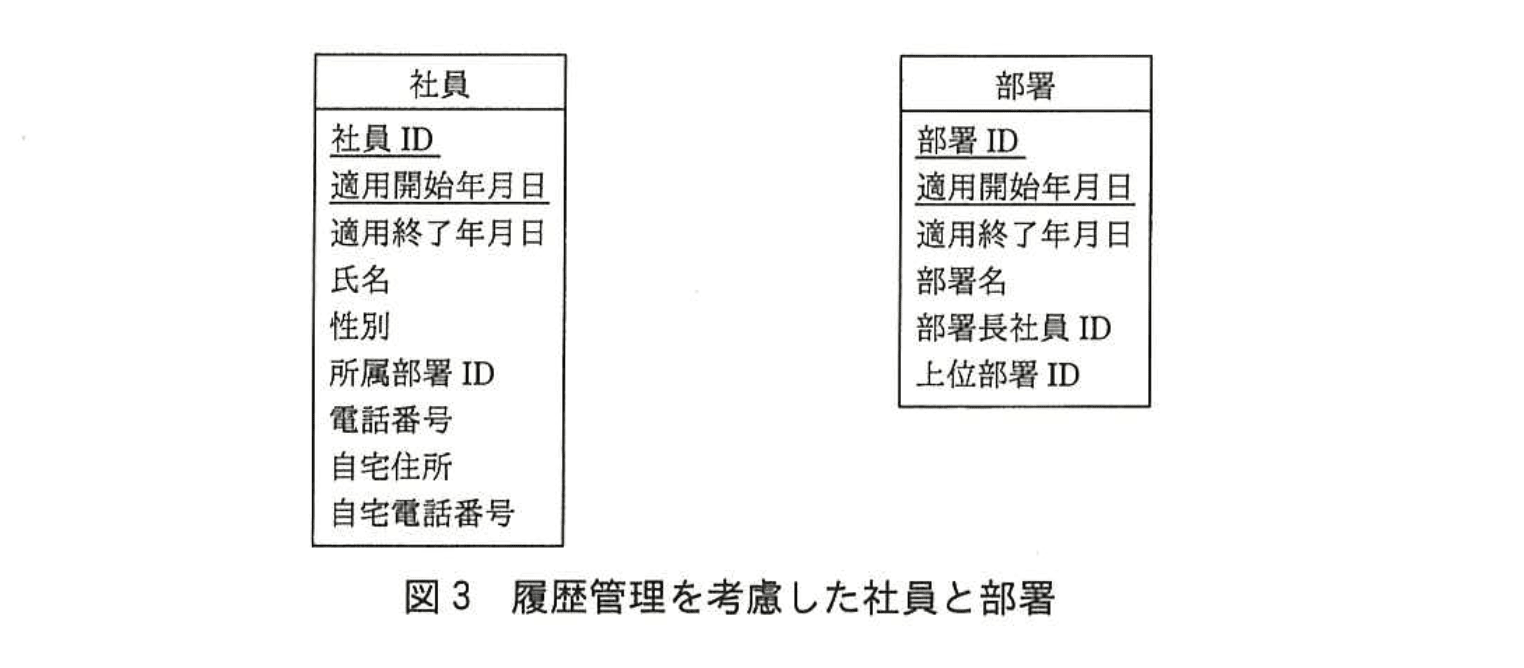
これらの要件を実現するために、エンティティ“社員”と“部署”に、属性“適用開始年月日”と“適用終了年月日”を追加して、各タプルの有効期間を管理する方法を考えた。指定した日が適用開始年月日から適用終了年月日までの範囲内であれば、その日の時点で有効なタプルである。適用終了年月日が未定の場合は、‘9999-12-31’を設定する。新しいエンティティ“社員”と“部署”を図3に示す。
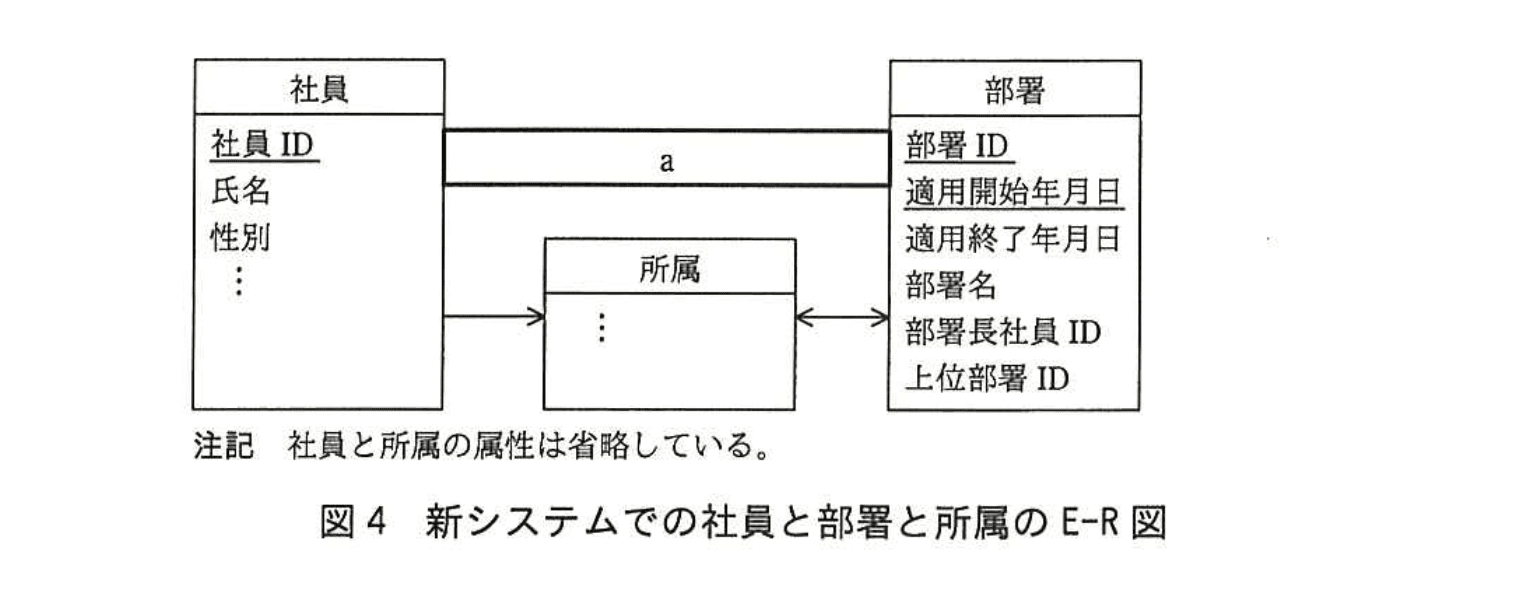
しかし、①図3のエンティティ“社員”は十分に正規化されていないとの指摘を受け、エンティティ“所属”を新たに追加し、エンティティ“社員”を第3正規形とした。新システムでの社員と部署と所属のE-R図を図4に示す。
要件(2)を実現するSQL文を図5に示す。ここで、“:年月日”は、指定した日の日時を格納する埋込み変数である。

現時点での部署テーブルの内容を表2に示す。
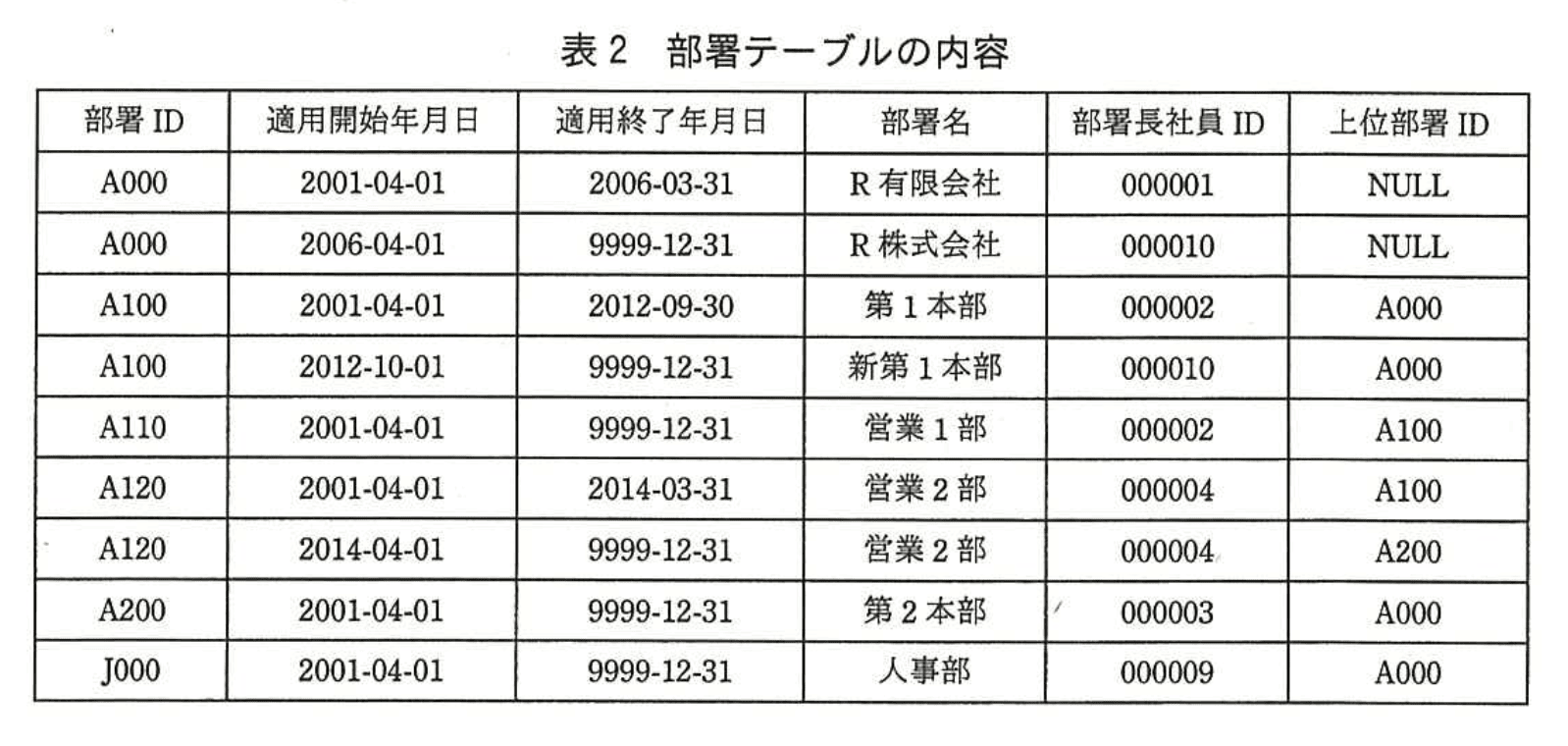
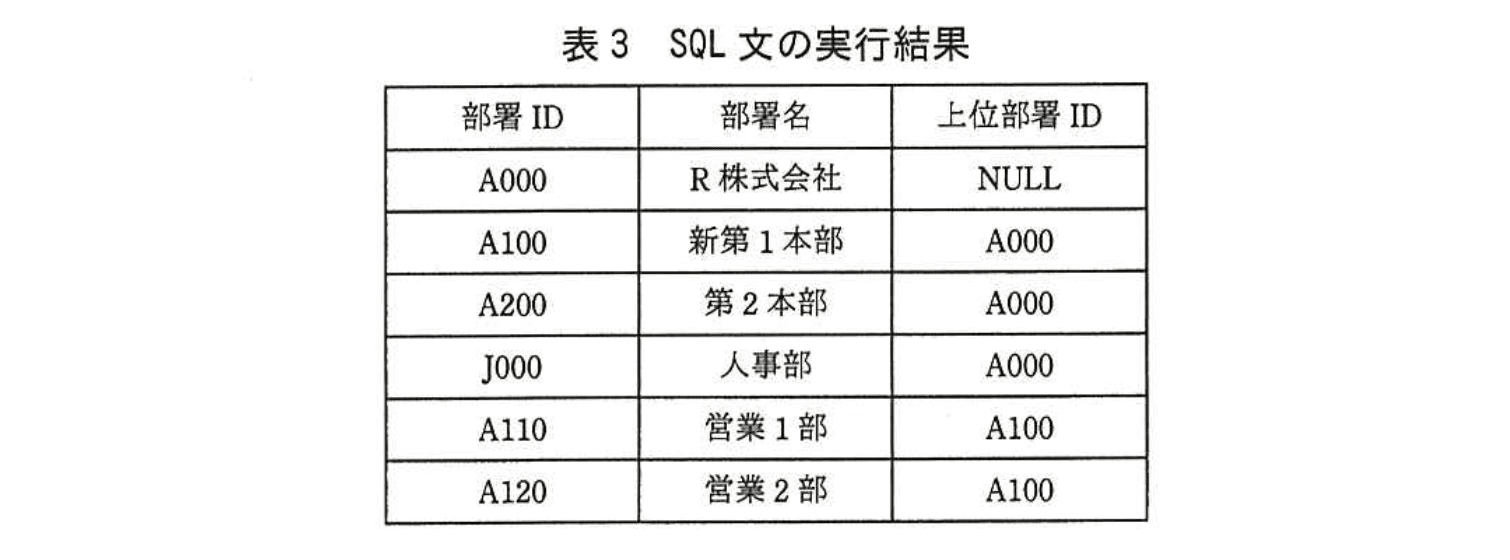
埋込み変数“:年月日”にeからfまでの範囲の日付を設定して、表2の部署テーブルに対して図5のSQL文を実行すると、その結果は表3のとおりとなる。
設問1:現行システムについて(1)、(2)に答えよ。
(1)図1及び表1中のaに入れる適切なリレーションシップを答え、E-R図を完成させよ。図1の凡例に倣って解答すること。
模範解答
a:→
解説
解答の論理構成
- 【問題文】には「“社員”と“部署”の間には多対1のリレーションシップがある」と明示されています。
引用:“社員”と“部署”の間には多対1のリレーションシップがあることを示している。 - 多対1では「多側 → 1側」の矢印表記を用いると、図1の凡例と整合します。
引用:多対1のリレーションシップの多側が外部キーの属性、1側が主キーの属性と対応している。 - 外部キー“所属部署ID”を持つのはエンティティ“社員”であり、多側(社員)から1側(部署)へ向かうため、リレーションシップは「→」となります。
- 以上より、a に入る記号は「→」が正しいと結論付けられます。
誤りやすいポイント
- 多対1と1対多を混同し、矢印方向を逆に書いてしまう。
- 部署長の兼任(1人が複数部署の長)という文脈に引きずられ、部署→社員が1対多だと早合点する。
- 図の記号(実線・矢印)の凡例を確認せず、一般的な UML の表記法と混同する。
FAQ
Q: 部署長の兼任があるのに多対1で良いのですか?
A: 部署長は“部署”の属性“部署長社員ID”で表され、所属関係とは別です。所属は「社員は必ず一つの部署だけに所属」であり、多対1が成立します。
A: 部署長は“部署”の属性“部署長社員ID”で表され、所属関係とは別です。所属は「社員は必ず一つの部署だけに所属」であり、多対1が成立します。
Q: “所属部署ID”が NULL になるケースは考慮しなくて良い?
A: 【問題文】に「社員は必ず一つの部署だけに所属している」とあるため、NULL は発生しません。
A: 【問題文】に「社員は必ず一つの部署だけに所属している」とあるため、NULL は発生しません。
Q: 1対多と多対1の矢印向きを忘れやすいのですがコツは?
A: 外部キーを持つ側(子テーブル)が多側です。「外部キー → 主キー」と覚えると矢印方向を誤りにくくなります。
A: 外部キーを持つ側(子テーブル)が多側です。「外部キー → 主キー」と覚えると矢印方向を誤りにくくなります。
関連キーワード: 外部キー、多対1, リレーションシップ、正規化、ER図
設問1:現行システムについて(1)、(2)に答えよ。
(2)表1中のb、cに入れる適切な属性名を答えよ。
模範解答
b:部署ID
c:上位部署ID
解説
解答の論理構成
-
再帰リレーションシップの概要確認
- 問題文には「部署の階層は木構造になっており、再帰リレーションシップで表現している。」とあります。さらに「上位部署IDには、上位部署の部署IDを保持し…」と述べられており、自己参照の外部キーが存在することが分かります。
-
外部キーと主キーの対応ルール
- 表1の説明に「多対1のリレーションシップの多側が外部キーの属性、1側が主キーの属性と対応している。」と明記されています。
-
部署テーブルの自己参照関係に当てはめる
-
多側(“子”部署)が持つ外部キーは「上位部署ID」、
-
1側(“親”部署)が持つ主キーは「部署ID」です。
-
したがって、表1の自己参照行部署 b ――――> 部署 cでは、左側が主キー「部署ID」、右側が外部キー「上位部署ID」となるのが整合的です。
-
-
結論
- b に入るのは「部署ID」
- c に入るのは「上位部署ID」
誤りやすいポイント
- 矢印の向きを逆に読み、外部キーと主キーを取り違える。
- 「部署ID」も「上位部署ID」も同じテーブルにあるため、どちらが外部キーか混同しやすい。
- 「NULL」は最上位のみ許されるという説明に気を取られ、属性名自体の判断を後回しにしてしまう。
FAQ
Q: 「部署ID」が外部キーになるケースはありませんか?
A: ありません。「部署ID」は各タプルを一意に識別する主キーです。外部キーになるのは「上位部署ID」です。
A: ありません。「部署ID」は各タプルを一意に識別する主キーです。外部キーになるのは「上位部署ID」です。
Q: 矢印の向きは常に“外部キー → 主キー”ですか?
A: 本問題の表1では「多対1のリレーションシップの多側が外部キー」というルールに従い、矢印の先が多側(外部キー)になります。
A: 本問題の表1では「多対1のリレーションシップの多側が外部キー」というルールに従い、矢印の先が多側(外部キー)になります。
Q: 再帰リレーションシップでも正規化は必要ですか?
A: 必要です。ただし自己参照そのものは非正規形ではありません。主キーと外部キーの役割が明確であれば第3正規形を保てます。
A: 必要です。ただし自己参照そのものは非正規形ではありません。主キーと外部キーの役割が明確であれば第3正規形を保てます。
関連キーワード: 外部キー、主キー、再帰リレーションシップ、木構造、自己参照
設問2:新システムの要件を実現するためのエンティティについて、(1)、(2)に答えよ。
(1)本文中の下線①で、エンティティ“社員”は第1正規形、第2正規形、第3正規形のうち、どこまで正規化されているか答えよ。また、その理由を30字以内で述べよ。
模範解答
第1正規形
理由:「主キーの一部に関数従属している属性があるから」
または
「主キーに部分関数従属している属性があるから」
または
「社員IDだけに従属している属性があるから」
解説
解答の論理構成
- 問題文では「①図3のエンティティ“社員”は十分に正規化されていない」と指摘されています。
- 図3の主キーは「社員ID、適用開始年月日」という複合キーです。
- しかし「氏名」「性別」「電話番号」「自宅住所」「自宅電話番号」は時間に依存せず、複合キーのうち「社員ID」のみで一意に決まります。
- これは “主キーの一部に関数従属している属性” が存在する状態であり、第2正規形の要件(主キーの完全関数従属)を満たしていません。
- よって当該エンティティは「第1正規形」までしか到達していないと結論付けられます。
- 解答例は以下のとおりです。
• 正規化段階:第1正規形
• 理由:「主キーに部分関数従属している属性があるから」
誤りやすいポイント
- 「適用開始年月日」も主キーに含まれるため、単純に“単一主キーだから第2正規形”と早合点しやすいです。
- 時間とともに変わらない属性(氏名など)が複合キーの一部に従属している事実を見落としがちです。
- 第3正規形の条件(推移的関数従属の排除)と混同し、「まだ推移的従属が無いから第2正規形」と誤答するケースが多いです。
FAQ
Q: なぜ「適用開始年月日」を主キーに入れる必要があるのですか?
A: 履歴管理では同じ「社員ID」でも複数期間のレコードが存在します。期間差異を識別するために「適用開始年月日」をキーに含めます。
A: 履歴管理では同じ「社員ID」でも複数期間のレコードが存在します。期間差異を識別するために「適用開始年月日」をキーに含めます。
Q: 部分関数従属と推移的関数従属の違いは?
A: 部分関数従属は“複合キーの一部”への従属、推移的関数従属は“キー以外の属性”を経由した従属です。今回のケースは前者です。
A: 部分関数従属は“複合キーの一部”への従属、推移的関数従属は“キー以外の属性”を経由した従属です。今回のケースは前者です。
Q: 第2正規形に上げるにはどうすればよいですか?
A: 「社員ID」を持つ時間非依存の属性群を別エンティティ(社員基本情報)に分離し、履歴は「所属」など別エンティティに切り出す方法が一般的です。
A: 「社員ID」を持つ時間非依存の属性群を別エンティティ(社員基本情報)に分離し、履歴は「所属」など別エンティティに切り出す方法が一般的です。
関連キーワード: 第1正規形、部分関数従属、複合主キー、履歴管理、関数従属
設問2:新システムの要件を実現するためのエンティティについて、(1)、(2)に答えよ。
(2)図4中のエンティティ“所属”の属性を、本文中又は図中の字句を用いて答えよ。属性が主キーの一部となる場合は、実線の下線を付けること。
模範解答
社員ID、適用開始年月日、適用終了年月日、所属部署ID
解説
解答の論理構成
-
“所属”が追加された理由
- 問題文に「図3のエンティティ“社員”は十分に正規化されていないとの指摘を受け、エンティティ“所属”を新たに追加し、エンティティ“社員”を第3正規形とした。」とあります。
- 図3では“社員”が「所属部署ID」「適用開始年月日」「適用終了年月日」を内部に抱え、履歴管理と人事属性が混在していました。これを分離し、履歴(時点‐部署)だけを“所属”に持たせることで第3正規形を実現します。
-
“所属”が保持すべき最小属性の抽出
- 履歴行を特定するために“社員”側の主キーである「社員ID」が必須です。
- 期間履歴管理には開始と終了の日付が必要で、問題文では「属性“適用開始年月日”と“適用終了年月日”を追加」と明示されています。
- 所属先を示すのが「所属部署ID」であり、これは部署を参照する外部キーです。
-
主キー判定
- 同一社員が異動するたびにレコードが追加されるため、一意に識別できる組は「社員ID」+「適用開始年月日」。
- したがって、この 2 項目に実線の下線を付けて主キーと表記します。
-
まとめ
以上より、“所属”の属性は
・社員ID ・適用開始年月日 ・適用終了年月日 ・所属部署ID
が最小かつ十分な構成となります。
誤りやすいポイント
- 「所属部署ID」に下線を付けてしまう
- 主キーは期間の開始日で区別できるため不要です。
- 「適用終了年月日」を主キーに含める
- 未確定時は “9999-12-31” 固定値になるため一意制約に不向きです。
- “社員”テーブル側に履歴列を残す
- 履歴を分離しないと第3正規形違反(従属の混在)が解消しません。
FAQ
Q: 「所属部署ID」は NULL を許容しますか?
A: 社員は必ず一部署に所属するという前提なので NULL 不可の非 NULL 制約を付ける設計が一般的です。
A: 社員は必ず一部署に所属するという前提なので NULL 不可の非 NULL 制約を付ける設計が一般的です。
Q: 履歴期間の整合性はどのように担保しますか?
A: 社員ID に対して [適用開始年月日、適用終了年月日] が重複しないよう排他制約を設け、トリガで連続性・非重複を検査します。
A: 社員ID に対して [適用開始年月日、適用終了年月日] が重複しないよう排他制約を設け、トリガで連続性・非重複を検査します。
Q: “所属”テーブルの外部キーは?
A: 「所属部署ID」が部署テーブルの「部署ID」を参照し、参照整合性を保ちます。
A: 「所属部署ID」が部署テーブルの「部署ID」を参照し、参照整合性を保ちます。
関連キーワード: 正規化、第3正規形、履歴管理、外部キー制約、ERモデル
設問3:新システムの要件(2)について、(1)、(2)に答えよ。
(1)図5中のdに入れる適切な字句又は式を答えよ。
模範解答
d:IS NULL
解説
解答の論理構成
- 問題文には「最上位は会社で、下に向かって本部、部、課などが配置されている。上位部署IDには、上位部署の部署IDを保持し、最上位である会社の上位部署IDにはNULLを設定する。」とあります。
- 図5のSQLは WITH RECURSIVE で階層展開を行います。再帰クエリの“アンカー”部分(最初の SELECT)では、あらかじめ最上位の部署を取得し、その下位を UNION ALL で再帰的に追い掛けます。
- したがってアンカーに必要なのは「上位部署ID が NULL である行」です。
- SQLでNULLとの比較には IS NULL を用います。= NULL と書いても真にならないため、正しい句は 上位部署ID IS NULL です。
- よって図5中の d には「IS NULL」が入ります。
誤りやすいポイント
- = NULL と書いてしまう
NULL は“未知”を表すため、等価演算子では比較できません。IS NULL/IS NOT NULL を必ず使用します。 - 「会社ID」など具体的なIDを固定値で書いてしまう
部署テーブルには履歴があり、会社名・会社IDが変わる可能性があります。固定値では階層の根が正しく取れない場合があります。 - アンカーを 部署ID = :会社ID のようにしてしまう
問題の要件は「会社全体の部署構造」です。特定IDを指定すると、その部署以下しか取得できず不正解になります。
FAQ
Q: 「NULL」は 0 や空文字と何が違いますか?
A: NULL は「値が存在しない/不定」を表します。0 や空文字は“値”が入っている状態です。比較演算子で評価しても真偽が決まりません。
A: NULL は「値が存在しない/不定」を表します。0 や空文字は“値”が入っている状態です。比較演算子で評価しても真偽が決まりません。
Q: 再帰クエリを使わずに階層を取得する方法はありますか?
A: 階層レベルが固定されていれば自己結合を何回も書く方法がありますが、階層数が不定の場合は WITH RECURSIVE が最も簡潔です。
A: 階層レベルが固定されていれば自己結合を何回も書く方法がありますが、階層数が不定の場合は WITH RECURSIVE が最も簡潔です。
Q: IS NULL の代わりに COALESCE(上位部署ID,'X')='X' などを書いても良いですか?
A: 技術的には成立しますが、可読性・標準性の観点から直接 IS NULL を使うのが一般的です。
A: 技術的には成立しますが、可読性・標準性の観点から直接 IS NULL を使うのが一般的です。
関連キーワード: WITH RECURSIVE, 再帰SQL, 階層構造、NULL比較、外部キー
設問3:新システムの要件(2)について、(1)、(2)に答えよ。
(2)本文中のe、fに入れることのできる最大範囲の日付の組を答えよ。
模範解答
e:2012-10-01
f:2014-03-31
解説
解答の論理構成
-
SQL の期間条件を確認
問題文の図5に
AND :年月日 BETWEEN 部署.適用開始年月日 AND 部署.適用終了年月日
とあります。したがって、抽出される行は埋込み変数“:年月日”が各行の「適用開始年月日 ≦ :年月日 ≦ 適用終了年月日」を満たす期間に限られます。 -
表3に出力されている各部署の有効期間を表2で照合
• 「A000 R株式会社」は表2で
A000 2006-04-01 9999-12-31
の行が該当します。従って :年月日は 2006-04-01 以降である必要があります。
• 「A100 新第1本部」は
A100 2012-10-01 9999-12-31
が該当し、:年月日は 2012-10-01 以降である必要があります。
• 「A120 営業2部」は 2 つの行を持ちます。- A120 2001-04-01 2014-03-31(上位部署ID=A100)
- A120 2014-04-01 9999-12-31(上位部署ID=A200)
表3には上位部署ID が A100 の行が出力されているため、:年月日は 2014-03-31 以前 でなければなりません。
-
全行を同時に満たす期間を決定
要件をまとめると
• 下限:2012-10-01(「A100 新第1本部」の適用開始日)
• 上限:2014-03-31(「A120 営業2部」の旧レコードの適用終了日)
以上により、埋込み変数“:年月日”に設定できる最大範囲は
2012-10-01 から 2014-03-31 までです。
誤りやすいポイント
- 「A120 営業2部」を 2014-04-01 以降の行と誤認し、上位部署ID が変わることに気付かない。
- 「A000 R株式会社」の変更(2006-04-01)を見落とし、2001-04-01 など早すぎる日付を下限に設定してしまう。
- BETWEEN 句は両端を含むため、上限日に 2014-03-31 を入れても条件に合致することを忘れ、2014-03-30 など 1 日前を指定してしまう。
FAQ
Q: なぜ 2012-10-01 より前の日付ではだめなのですか?
A: 「A100 新第1本部」の行は 2012-10-01 から有効であり、それ以前は「第1本部」です。表3に「新第1本部」が出力されているため、少なくともこの日付以降である必要があります。
A: 「A100 新第1本部」の行は 2012-10-01 から有効であり、それ以前は「第1本部」です。表3に「新第1本部」が出力されているため、少なくともこの日付以降である必要があります。
Q: 2014-03-31 当日を指定しても「A120 営業2部」は取得できますか?
A: はい。BETWEEN は両端を含む演算子なので、適用終了年月日が 2014-03-31 の行は当日も有効として扱われ、表3の結果と一致します。
A: はい。BETWEEN は両端を含む演算子なので、適用終了年月日が 2014-03-31 の行は当日も有効として扱われ、表3の結果と一致します。
Q: 上位部署ID を NULL に限定する d は結果に影響しますか?
A: 今回の設問は期間条件による影響のみを問うており、d の値は問われていません。:年月日の範囲が正しければ表3と同じ結果になります。
A: 今回の設問は期間条件による影響のみを問うており、d の値は問われていません。:年月日の範囲が正しければ表3と同じ結果になります。
関連キーワード: 履歴テーブル、期間条件クエリ、再帰SQL, 上位部署、正規化
