応用情報技術者 2016年 春期 午後 問06
コンビニエンスストアにおけるデータウェアハウス構築及び分析に関する次の記述を読んで、設問1〜4に答えよ。
W社は、コンビニエンスストアを全国展開する企業である。店舗ごとの売上を分析するために、データウェアハウスを構築することになった。
〔売上ファクト表の作成〕
売行きが悪い商品を見つけるために、販売実績と在庫実績のデータを1日単位で集計して売上ファクト表を作成する。
販売実績と在庫実績のデータは一つのデータベースによって管理されており、新たに追加するデータウェアハウスのデータも同じデータベース内に格納する。データベースのE-R図の抜粋を図1に、各エンティティの概要を表1に示す。
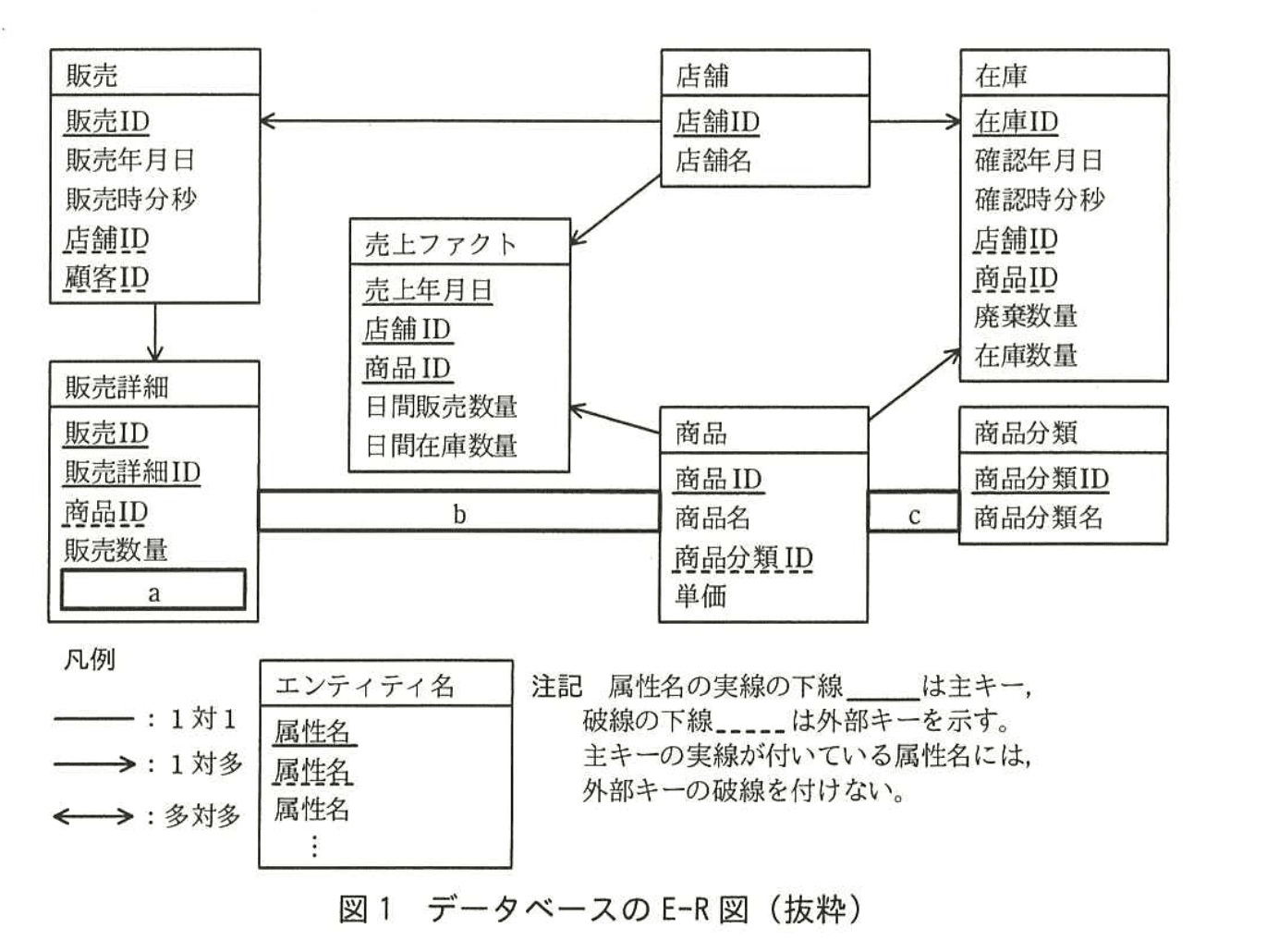

このデータベースでは、E-R図のエンティティ名を表名にし、属性名を列名にして、適切なデータ型で表定義した関係データベースによって、データを管理する。
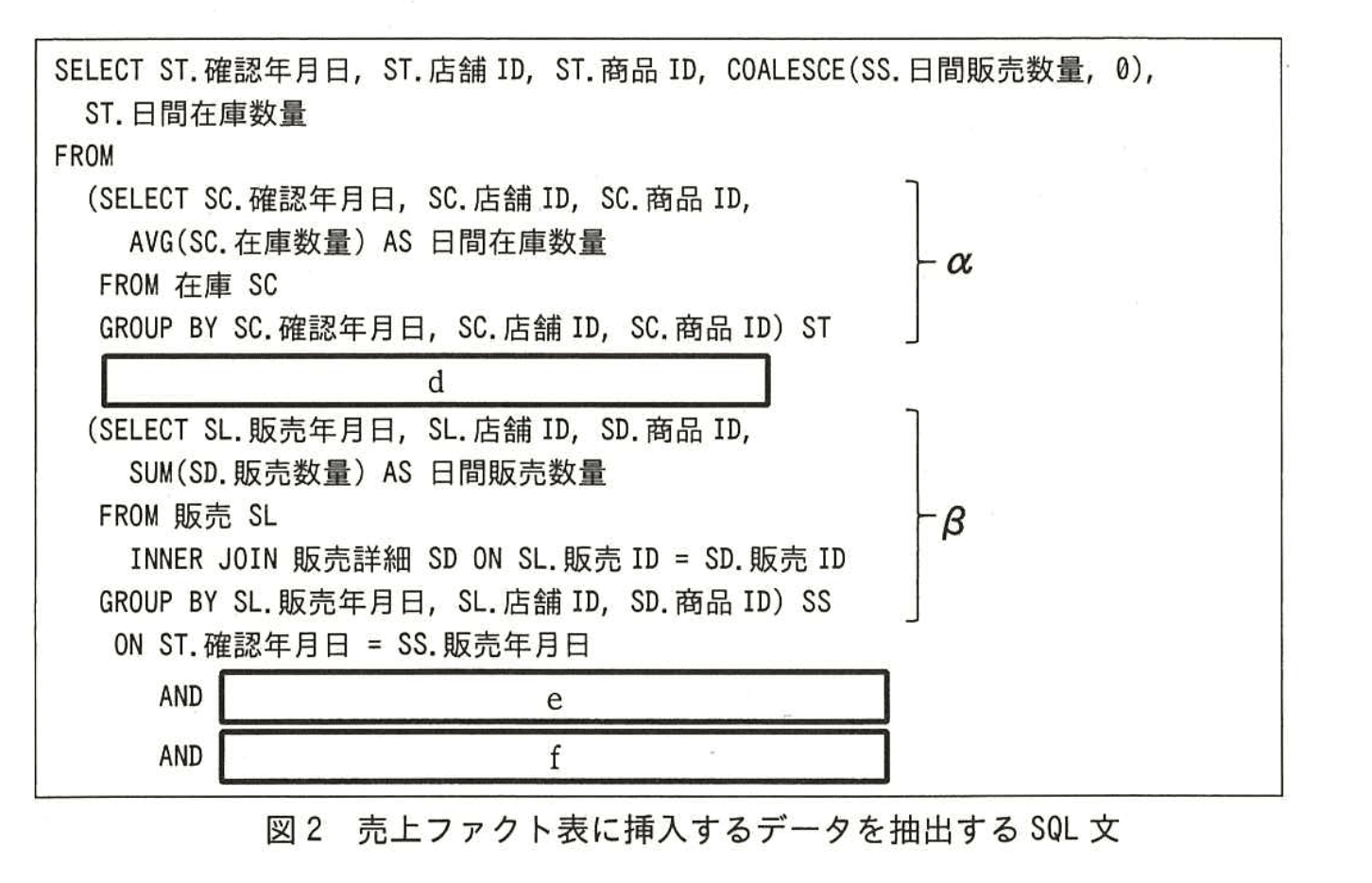
売上ファクト表に挿入するデータを抽出するSQL文を図2に示す。
なお、店舗に在庫はあるが販売実績がない商品は日間販売数量を0とする。関数COALESCE(A, B)は、AがNULLでないときはAを、AがNULLのときはBを返す。
〔先行きが悪い商品分類の一覧の作成〕
店舗ごとの月間の先行きが悪い商品分類の一覧を作成するために、図3のSQL文を作成した。一覧は、売上年月が新しいものから、店舗IDを昇順にして、平均在庫数量が多い順に表示させる。
なお、関数 TO_YYYYMM は日付型の引数を受け、年月を6文字の文字列として返す。

〔先行きが悪い商品分類の一覧を作成する SQL 文の不具合〕
図3のSQL文を、過去の実績データを用いてテストしたところ、複数の商品分類の平均販売数量に誤った値が見つかった。そこで、幾つかの店舗における販売及び在庫管理の運用方法を確認したところ、店舗や商品によって在庫数量を記録する頻度にばらつきがあることが判明した。ある店舗では、販売実績が少ない商品は1日3回ではなく、1週間に1回だけ、在庫数量を記録していた。この点に注目して、処理を見直すことにした。まず、①図2中のある副問合せを抜き出して、その結果を新たに作成した表に格納する。次に、この表に②不足しているデータを追加する。図2中のある副問合せをこうして得られた表と置き換えることで、問題を解決することができた。
設問1:
図1のE-R図中のa~cに入れる適切なエンティティ間の関連及び属性名を答え、E-R図を完成させよ。
なお、エンティティ間の関連及び属性名の表記は、図1の凡例に倣うこと。
模範解答
a:販売時単価
b:←
c:←
解説
解答の論理構成
-
図1によると、エンティティ “販売詳細” には
- 「商品ID」
- 「販売数量」
のみが示されています。しかし【問題文】表1には
「販売詳細:顧客に販売した商品の数量や販売単価を記録」
とあり、“販売単価” を保持する属性が必須です。したがって
「販売時単価」を a に補うことで、E-R 図の属性が表1の説明と一致します。
-
“商品” と “販売詳細” の関係は図1で「商品 → 販売詳細(1対多)」と記されています。
しかし、一つの販売明細は必ず一つの商品に従属し、複数明細が同一商品の下にぶら下がる構造です。
図1の矢印ルール(元エンティティから多側エンティティに “→” を描く)に照らすと、
「販売詳細(多) → 商品(1)」となるべきです。よって矢印の向きを修正し、b には「←」を補います。 -
“商品分類” と “商品” についても同様です。図1では「商品分類 → 商品(1対多)」となっていますが、
1つの商品分類に複数の商品が属するため、“商品(多)” 側から “商品分類(1)” へ向けた矢印が適切です。
したがって c も「←」となります。 -
以上より、E-R 図に追加すべき内容は
a:「販売時単価」
b:「←」
c:「←」
となります。
誤りやすいポイント
- 【問題文】表1の記述と E-R 図を照合せずに、既に図に載っている属性だけで完成したと誤認する。
- 矢印の向きは「1 側→多側」と覚えていても、与えられた行の語順(左‐右)を修正し忘れ、向きを誤答する。
- “販売単価” と “販売時単価” を混同し、原文どおりの名称「販売時単価」を書かず減点される。
FAQ
Q: 矢印の向きを判断する最も簡単な方法は?
A: 「1 つのレコードに対して複数行が発生する側が矢印の行き先」と覚えると混乱しにくいです。
A: 「1 つのレコードに対して複数行が発生する側が矢印の行き先」と覚えると混乱しにくいです。
Q: “販売時単価” を「販売単価」と書くと減点になりますか?
A: 設問は「数字・固有名詞は必ず原文を正確に引用」と指示しているため、表1に記載の「販売単価」ではなく、図1で求められる正式名「販売時単価」を用いる必要があります。
A: 設問は「数字・固有名詞は必ず原文を正確に引用」と指示しているため、表1に記載の「販売単価」ではなく、図1で求められる正式名「販売時単価」を用いる必要があります。
Q: そもそも “販売詳細” に単価が必要な理由は?
A: キャンペーンなどで単価が変動する場合、販売時点の価格を保持しないと、後に商品マスタの単価が更新された際に正しい販売金額を再計算できなくなるためです。
A: キャンペーンなどで単価が変動する場合、販売時点の価格を保持しないと、後に商品マスタの単価が更新された際に正しい販売金額を再計算できなくなるためです。
関連キーワード: 正規化, 外部キー, 1対多, E-Rモデル, 属性設計
設問2:
図2中のd〜fに入れる適切な字句又は式を答えよ。
なお、表の列名には必ずその表の別名を付けて答えよ(eとfは順不同)。
模範解答
d:LEFT OUTER JOIN
e:ST.店舗ID = SS.店舗ID
f:ST.商品ID = SS.商品ID
解説
解答の論理構成
-
前提条件の整理
問題文には次の指示があります。
「店舗に在庫はあるが販売実績がない商品は日間販売数量を0とする。」
この要件から、在庫(ST)の行は必ず残し、販売(SS)の行がなくても結果集合に含める必要があります。 -
JOIN 方式の決定
・在庫を基準に販売をくっつける――販売がなくても在庫は残す。
・したがって、在庫側(ST)が “残る” 外部結合を選択する。
⇒ d には「LEFT OUTER JOIN」が入る。 -
結合キーの特定
図2の ON 句にはすでに
ST.確認年月日 = SS.販売年月日
が示されており、残るキーは “店舗” と “商品” です。
在庫と販売を 1 日単位で紐付けるには、
・店舗を一致させる条件
・商品を一致させる条件
が不可欠です。別名付きで書くと
ST.店舗ID = SS.店舗ID と ST.商品ID = SS.商品ID になります。
店舗か商品のどちらを先に書いても意味は変わらないので、e と f は順不同と指定されています。 -
まとめ
・d LEFT OUTER JOIN
・[ e ] ST.店舗ID = SS.店舗ID
・[ f ] ST.商品ID = SS.商品ID
誤りやすいポイント
- INNER JOIN を選んでしまい、販売実績がない商品が欠落する
→ 要件「販売実績がない商品は日間販売数量を0」に反します。 - RIGHT OUTER JOIN と混同する
→ 結合の基準テーブルが逆転し、在庫のない販売だけが残る恐れがあります。 - 別名を付け忘れる
→ 「表の列名には必ずその表の別名を付けて答えよ」という指示違反になります。 - 結合キーを1つだけにする
→ 店舗・商品を両方指定しないと、異なる店舗や商品のデータが混ざり集計値が壊れます。
FAQ
Q: LEFT JOIN と LEFT OUTER JOIN の違いはありますか?
A: 多くの RDBMS では同義ですが、ANSI SQL の正式キーワードは LEFT OUTER JOIN です。試験では明示的に “OUTER” を書いておくと安全です。
A: 多くの RDBMS では同義ですが、ANSI SQL の正式キーワードは LEFT OUTER JOIN です。試験では明示的に “OUTER” を書いておくと安全です。
Q: 結合条件に WHERE 句を使ってはいけませんか?
A: ON 句で書くのが鉄則です。WHERE 句に混在させると外部結合の意味が変わり、除外される行が発生します。
A: ON 句で書くのが鉄則です。WHERE 句に混在させると外部結合の意味が変わり、除外される行が発生します。
Q: COALESCE 関数はなぜ必要なのですか?
A: LEFT OUTER JOIN で対応行がない場合、SS.日間販売数量 は NULL になります。COALESCE により NULL を 0 に置き換え、集計や表示を正しく行えます。
A: LEFT OUTER JOIN で対応行がない場合、SS.日間販売数量 は NULL になります。COALESCE により NULL を 0 に置き換え、集計や表示を正しく行えます。
関連キーワード: 外部結合, NULL処理, 集約関数, データウェアハウス, 正規化
設問3:
図3中のgに入れる適切な字句又は式を答えよ。
なお、表の列名には必ずその表の別名を付けて答えよ。
模範解答
g:ORDER BY SF.売上年月 DESC, SF.店舗ID ASC, 平均在庫数量 DESC
解説
解答の論理構成
- 並び替えの条件は【問題文】の「売上年月が新しいものから、店舗IDを昇順にして、平均在庫数量が多い順に表示させる。」という記述に明示されています。
- SQL で並び順を指定するには ORDER BY 句を用い、降順は DESC、昇順は ASC を付与します。
- 現在の SELECT 句では、年月を表す列が SF.売上年月、店舗を示す列が SF.店舗ID、平均在庫を示す列が 平均在庫数量 という別名で取得されています。
- したがって、条件をそのまま SQL の句に置き換えると
• 年月:SF.売上年月 DESC
• 店舗:SF.店舗ID ASC
• 在庫:平均在庫数量 DESC
となります。 - 以上より、g に入る字句は
sql ORDER BY SF.売上年月 DESC, SF.店舗ID ASC, 平均在庫数量 DESC
誤りやすいポイント
- SF.売上年月 を降順にするのを忘れて、最新月が最後に並ぶ。
- 平均在庫数量 を別名のまま使わず、AVG(SF.日間在庫数量) と書き直してしまう。
- 並び替えの優先順位を誤り、SF.店舗ID を先頭に置いてしまう。
- 別名に表別名 SF. を付け忘れ、SQL シンタックスエラーとなる。
FAQ
Q: 別名 平均在庫数量 には表別名を付けられませんか?
A: 集計結果に付けたカラム別名には表別名を付けません。ORDER BY で参照する場合もカラム別名のみ記述します。
A: 集計結果に付けたカラム別名には表別名を付けません。ORDER BY で参照する場合もカラム別名のみ記述します。
Q: GROUP BY で指定した列も ORDER BY に書かなければなりませんか?
A: 必須ではありません。ORDER BY は表示順を制御するだけなので、集計列以外でも自由に指定できます。
A: 必須ではありません。ORDER BY は表示順を制御するだけなので、集計列以外でも自由に指定できます。
Q: 別名 SF のサブクエリを省略し、直接 売上ファクト を参照してもよいですか?
A: 年月変換関数 TO_YYYYMM の結果を再利用するためにサブクエリ SF を設けています。直接参照すると同じ式を複数回書くことになり、可読性が落ちます。
A: 年月変換関数 TO_YYYYMM の結果を再利用するためにサブクエリ SF を設けています。直接参照すると同じ式を複数回書くことになり、可読性が落ちます。
関連キーワード: ORDER BY, ソート順序, カラム別名, DESC ASC, 集計関数
設問4:〔売行きが悪い商品分類の一覧を作成するSQL文の不具合〕について、(1)、(2)に答えよ。
(1)本文中の下線①に該当する副問合せは図2中のどの位置にあるか。α又はβで答えよ。
模範解答
α
解説
解答の論理構成
- 問題文には、誤った平均値の原因を解消するために
「まず、①図2中のある副問合せ を抜き出して、その結果を新たに作成した表に格納する。」
とあります。 - ここで抜き出す副問合せは、後続の手順で
「この表に ②不足しているデータ を追加する」
と述べられており、
すなわち “本来存在すべきなのに欠けている在庫情報を補完する” ためのものです。 - 図2の SQL は、日単位の在庫・販売情報を集計し、最終的に JOIN しています。
a. 片方の副問合せは在庫表を GROUP BY して日間在庫数量を求めるもの
b. もう一方の副問合せは販売表+販売詳細表を GROUP BY して日間販売数量を求めるもの - 問題文は「店舗や商品によって在庫数量を記録する頻度にばらつきがある」と指摘しており、
補完対象は “在庫” であると読み取れます。
販売データは POS システムで確実に記録される一方、在庫データは欠損しやすいからです。 - したがって、抜き出すべき副問合せは在庫を集計している側、すなわち図2の [α] に位置する副問合せです。
- よって解答は α となります。
誤りやすいポイント
- 「不足しているデータ=販売データ」と早合点し、[β] を選んでしまう。実際には販売数量は POS により自動収集されるため欠損しにくい。
- 副問合せを “外側 SELECT の直前” といった位置情報で判断しようとして混乱する。α/β という記号で指定されているので、内容(在庫か販売か)に注目することが重要。
- ②の「不足しているデータ」を “NULL 行の削除” と解釈し、処理の意図を取り違える。本質は NULL を 0 に置き換えるのではなく、そもそも存在しない在庫行を追加すること。
FAQ
Q: 販売データにも欠損が起こる可能性はありませんか?
A: POS で自動連携される想定なので欠損は非常に稀です。問題文でも在庫記録の頻度ばらつきのみが指摘されています。
A: POS で自動連携される想定なので欠損は非常に稀です。問題文でも在庫記録の頻度ばらつきのみが指摘されています。
Q: COALESCE で NULL を 0 にしているのに、なぜ行追加が必要なのですか?
A: COALESCE は “行が存在している” ことが前提です。行自体がなければ NULL 判定の対象にならないため、欠損行を補完する処理が必要となります。
A: COALESCE は “行が存在している” ことが前提です。行自体がなければ NULL 判定の対象にならないため、欠損行を補完する処理が必要となります。
Q: 抜き出した在庫副問合せを表化する利点は?
A: 先に在庫だけを独立して持つことで、後からスクリプトやバッチで欠損行を効率的に INSERT でき、月次分析時の平均値が正しくなります。
A: 先に在庫だけを独立して持つことで、後からスクリプトやバッチで欠損行を効率的に INSERT でき、月次分析時の平均値が正しくなります。
関連キーワード: サブクエリ, JOIN, 集計関数, NULL処理
設問4:〔売行きが悪い商品分類の一覧を作成するSQL文の不具合〕について、(1)、(2)に答えよ。
(2)本文中の下線②とはどのようなデータか。40字以内で述べよ。
なお、販売及び在庫管理の運用方法は変更しないこと。
模範解答
在庫数量を記録していない日の商品の在庫数量を実績から導出したデータ
解説
解答の論理構成
- 【問題文】には「店舗や商品によって在庫数量を記録する頻度にばらつきがある」とあり、具体例として「ある店舗では、販売実績が少ない商品は1日3回ではなく、1週間に1回だけ、在庫数量を記録していた」と述べています。
- その結果、図2の在庫側副問合せでは「在庫数量を記録した日」しか抽出されません。よって「記録していない日」の在庫数量が欠落し、後続の平均計算で販売数量だけが増えて在庫数量が小さく見積もられるという誤差が生じます。
- 【問題文】は「②不足しているデータを追加する」と指示しています。この“不足”とは「在庫数量を記録していない日」の情報であり、記録が無いだけで実際の在庫は存在します。
- そこで過去の在庫実績を利用し、たとえば「直近の記録値をその後の未記録日に補完する」などの方法で「在庫数量を記録していない日の商品の在庫数量」を導出し、新しい表に追加入力します。
- 以上より、下線②が指すのは「在庫数量を記録していない日の商品の在庫数量を実績から導出したデータ」です。
誤りやすいポイント
- 「記録していない=在庫ゼロ」と誤解し、欠測値補完を行わないまま平均を計算してしまう。
- 販売側は毎日データがあるため、在庫側だけの欠測に気付きにくい。
- SQL の不足データ補完を JOIN で済ませようとして、ロジックが複雑化する。
FAQ
Q: なぜ販売側には補完処理が不要なのですか?
A: 販売実績は「売れたときのみ」記録され、売れなかった日は販売数量0として COALESCE で補完済みだからです。
A: 販売実績は「売れたときのみ」記録され、売れなかった日は販売数量0として COALESCE で補完済みだからです。
Q: 在庫数量の補完方法に決まりはありますか?
A: 実務では「直近値コピー」「線形補間」などが使われますが、本設問は手法を限定せず“実績から導出”できれば良いと読み取れます。
A: 実務では「直近値コピー」「線形補間」などが使われますが、本設問は手法を限定せず“実績から導出”できれば良いと読み取れます。
Q: 図3の平均計算が誤る根本原因は?
A: 分母(日数)は全日分なのに、分子(在庫数量)は記録日のみの合計になるため、平均在庫数量が実際より小さく算出されます。
A: 分母(日数)は全日分なのに、分子(在庫数量)は記録日のみの合計になるため、平均在庫数量が実際より小さく算出されます。
関連キーワード: 欠測値補完, 集計関数, データ品質, 外れ値対策
