応用情報技術者 2018年 秋期 午後 問04
並列分散処理基盤を用いたビッグデータ活用に関する次の記述を読んで、設問1~4に答えよ。
S社は、スーパーマーケットやドラッグストアなどの小売チェーン(以下、チェーンという)で販売されている衣料用洗剤や食器用洗剤などを製造する大手消費財メーカーである。商品企画部による商品力強化や、営業部による拡販施策検討のために、取引先である複数のチェーンから匿名化されたPOSデータを週次で購入し、独自に集計・分析することになった。購入するPOSデータの件数は約10億件/週と予想されるので、情報システム部のTさんをリーダとして、並列分散処理基盤を利用したPOSデータ集計・分析システムを構築することになった。
〔並列分散処理基盤のシステム構成〕
Tさんは、S社が保有している並列分散処理基盤のシステム構成を調査した。並列分散処理基盤のシステム構成を図1に示す。
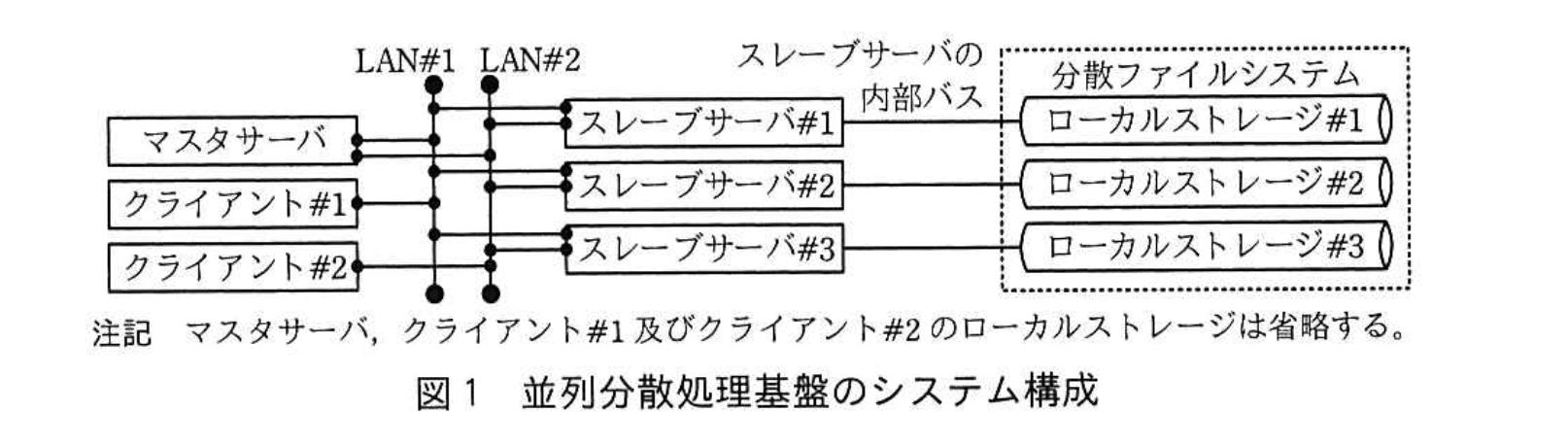
処理対象のデータはブロック単位に分割され、物理的には、各スレーブサーバの内部バスに接続されたローカルストレージに分散して格納されているが、論理的には、単一のファイルシステム(以下、分散ファイルシステムという)で管理されている。分散ファイルシステムのブロックサイズは128Mバイトに設定されている。任意のスレーブサーバ1台に障害が生じた場合でも処理を継続できるように、ブロックは2台のスレーブサーバのローカルストレージに非同期で複製して格納されている。ファイル名、ブロック位置、所有者、権限などのメタデータは、マスタサーバが保持している。
マスタサーバはクライアントからジョブの実行依頼を受け付け、ジョブを複数の実行単位(以下、タスクという)に分割し、処理対象のデータを格納しているスレーブサーバに対してタスクの実行を依頼する。データを分割した際にデータサイズのばらつきが小さいほど、タスクが均等に分散される。また、同一ジョブ内のタスク間で処理するデータが依存しており、タスクが逐次的に処理される場合、それらのタスクは分散されない。各スレーブサーバで同時に実行可能なタスクの数は、CPUの物理コア数-1を上限とする。並列分散処理基盤全体で同時に実行するタスクの数を多重度という。
マスタサーバの仕様は、CPU物理コア数2、メモリ容量8Gバイト、ローカルストレージのディスクI/O速度60Mバイト/秒である。スレーブサーバの仕様は、CPU物理コア数4、メモリ容量16Gバイト、ローカルストレージのディスクI/O速度60Mバイト/秒である。
Tさんが調査結果を上司のU課長に報告したところ、①可用性の観点からリスクがあるとの指摘を受けた。本リスクを評価した結果、それを受容してシステム構築を進めることになった。
〔POSデータ集計・分析システムのジョブ構成〕
POSデータ集計・分析システムを構成するジョブの一覧を表1に示す。
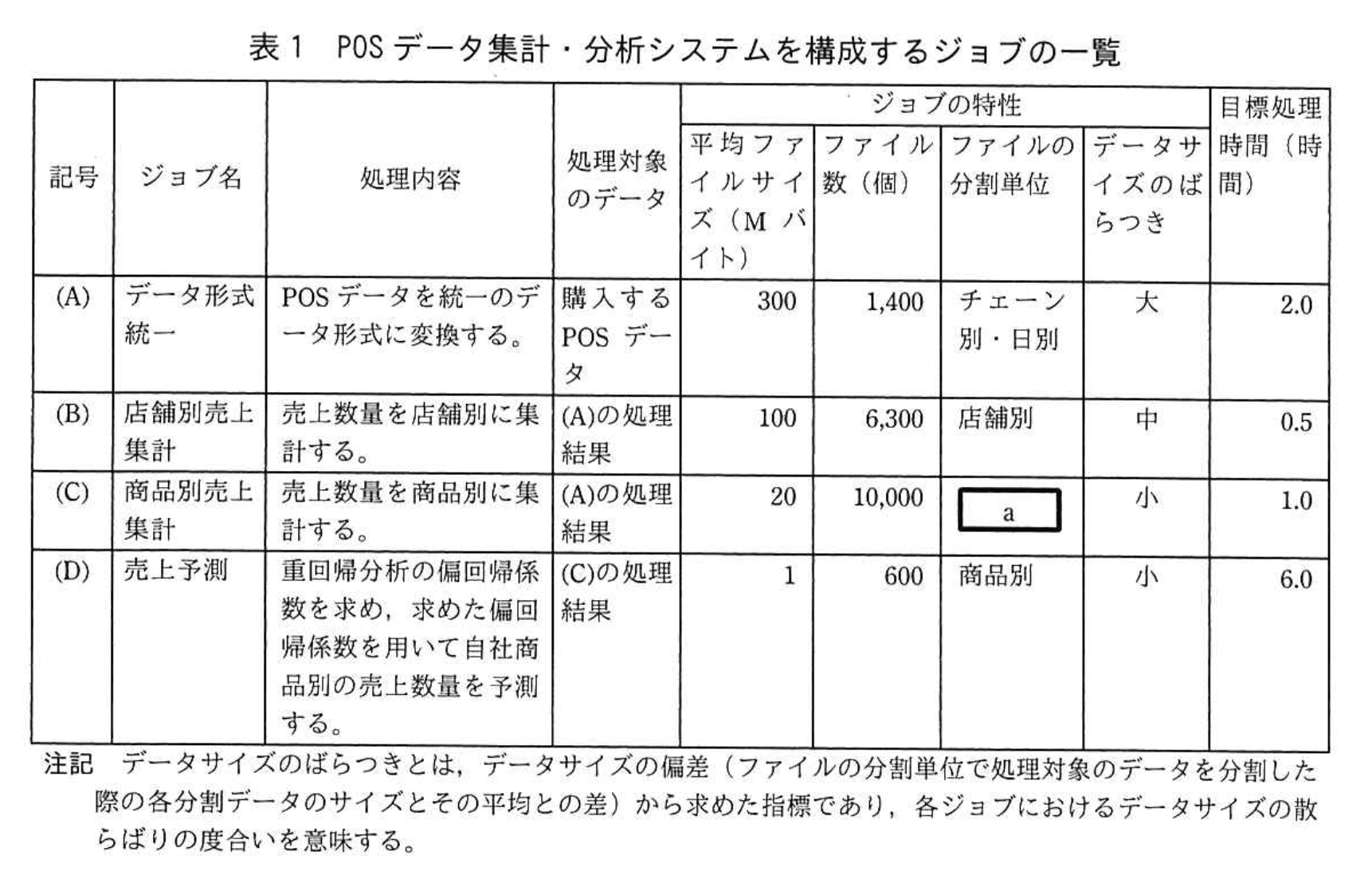
POSデータの購入元は200チェーンあり、POSデータは日別にファイル分割されている。1週間分のPOSデータのファイル数は1,400個であり、総データサイズは420Gバイトとなる。店舗数は全チェーン合わせて6,300店舗であり、取り扱われている商品数は10,000点である。そのうち、S社の商品は600点である。
ジョブの実行順序は(A)、(B)、(C)、(D)の順であり、各ジョブは同時には実行されない。
毎週月曜日23時までには、前週月曜日から日曜日までの全てのPOSデータが分散ファイルシステムに格納される。商品企画部や営業部からは、毎週火曜日の9時には最新の分析結果を見られるようにしてほしいとの要望が挙がっているので、月曜日23時から火曜日9時までの間に一連のジョブを完了させる必要がある。
〔性能テスト〕
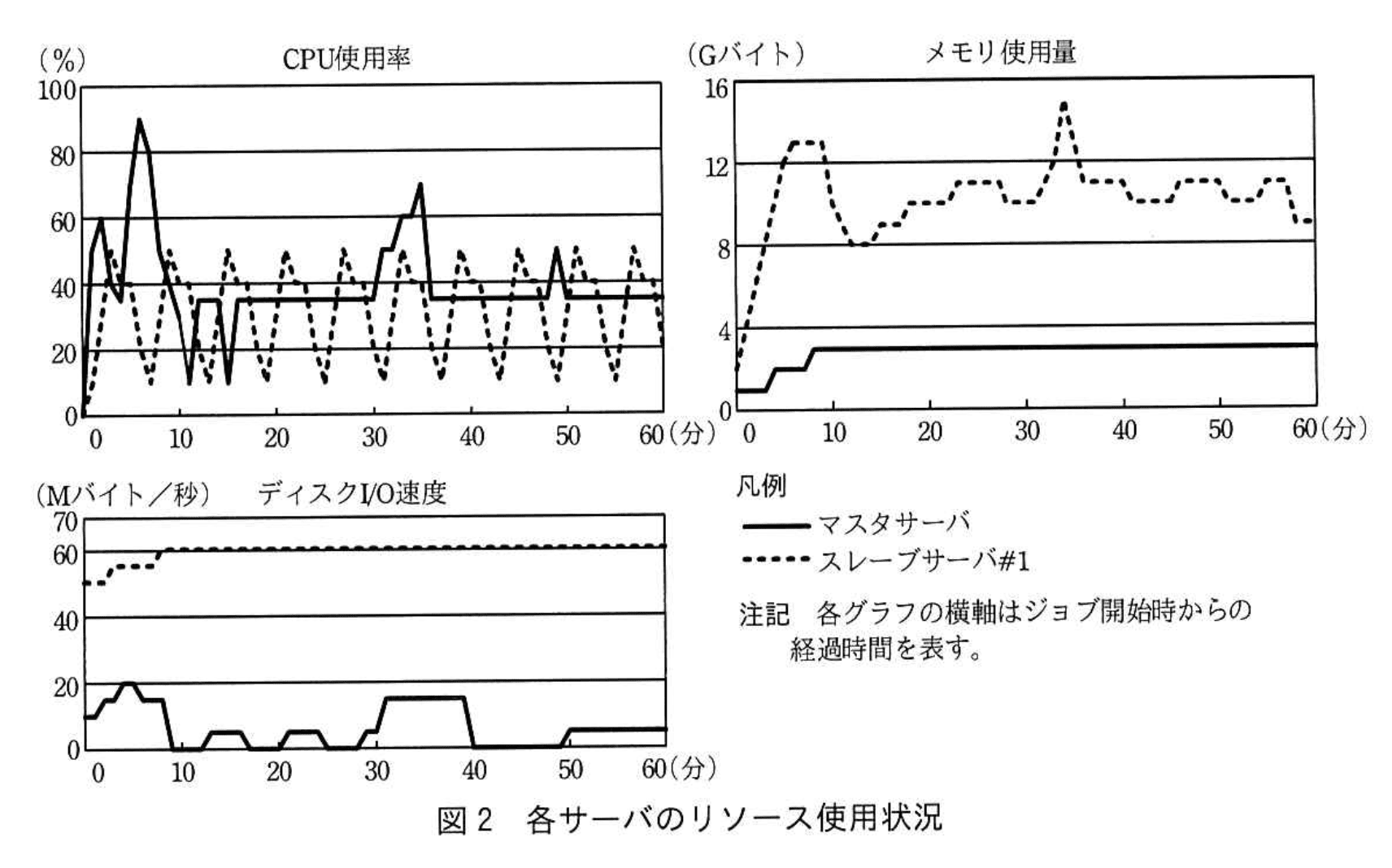
POSデータ集計・分析システムを開発し、性能テストを実施したところ、②ジョブ(B)が目標処理時間内に完了しないことが判明した。ジョブ(B)実行中のマスタサーバ及びスレーブサーバ#1のリソース使用状況を図2に示す。
なお、スレーブサーバ#2及びスレーブサーバ#3のリソース使用状況もスレーブサーバ#1のリソース使用状況と類似している。
Tさんは、ボトルネックとなったリソースを特定して適切な対策を講じることによって、ジョブ(B)を目標処理時間内に完了させることができた。
〔スケールアウトの計画〕
今後はPOSデータの購入元を増やし、分析精度を高めることを検討している。1年後には取り扱うPOSデータの件数を現在の10億件/週から30億件/週に増大させることが目標である。処理対象のデータ件数が増えると一部のジョブが目標処理時間内に完了しなくなる懸念があるので、並列分散処理基盤のスレーブサーバの増設(以下、スケールアウトという)を計画しておくことになった。性能テストにおいて調査した、POSデータの件数と処理時間の関係、及び多重度と処理時間の関係を図3に示す。Tさんは、1年後のスケールアウトに向けて予算を確保するために、図3を基に追加が必要となるスレーブサーバの台数を試算した。
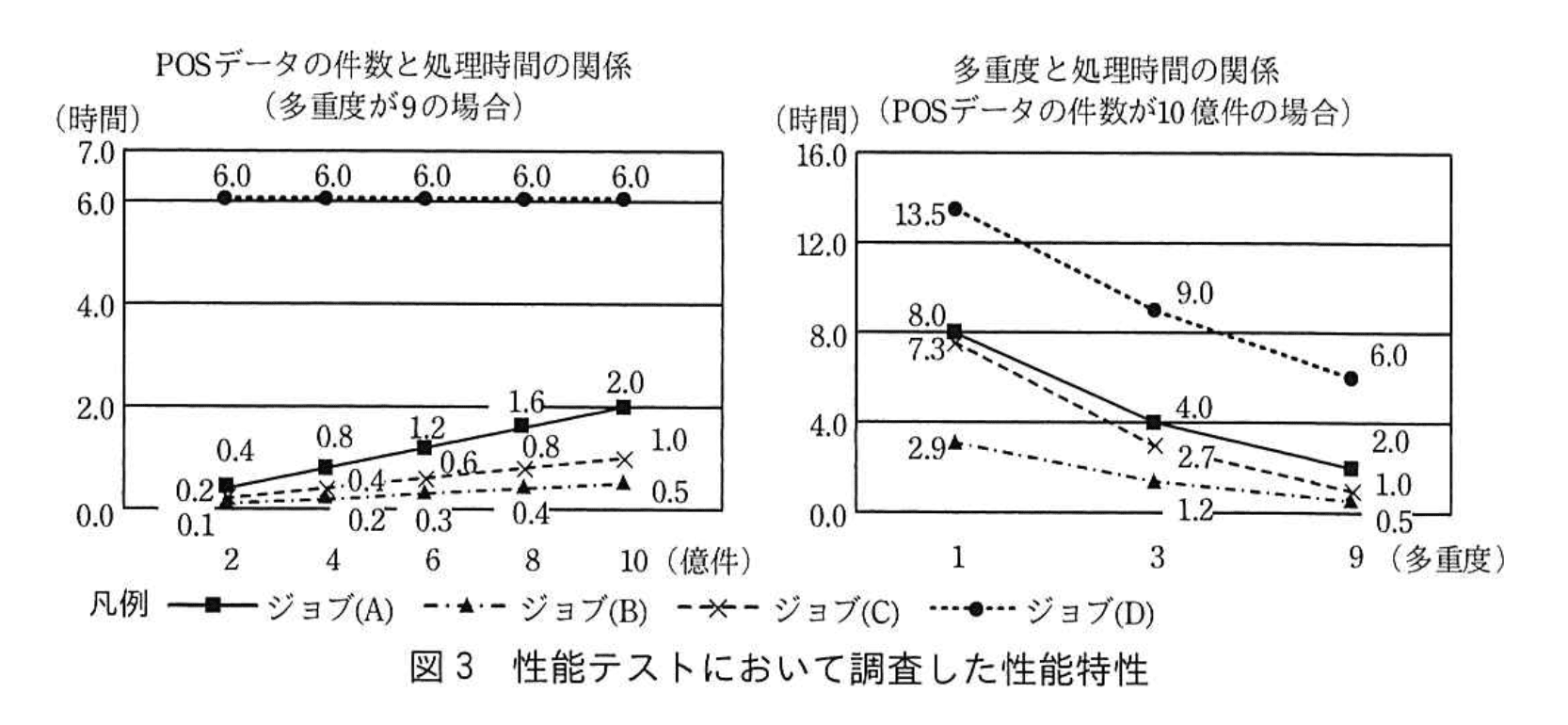
1年後にPOSデータの件数が3倍になること、及び図3のPOSデータの件数と処理時間の関係におけるジョブ(A)〜(C)の傾向から、1年後の並列分散処理基盤に要求されるスループットは現行の並列分散処理基盤の3倍と推定される。処理時間がPOSデータの件数に依存しないジョブ(D)はスケールアウトにおいて考慮する必要がない。図3の多重度と処理時間の関係から、スケールアウトにおいて考慮する必要があるジョブのうち、多重度を増やしても処理時間が最も短縮されにくいジョブはジョブ(A)である。多重度を3倍にした場合、ジョブ(A)におけるスループットは2倍となる。並列分散処理基盤のスループットを3倍にするために最低限必要な多重度は、現行の並列分散処理基盤のb倍にあたるである。したがって、1年後までに少なくともd台のスレーブサーバを追加する必要がある
設問1:〔並列分散処理基盤のシステム構成〕について、(1)、(2)に答えよ。
(1)図1のシステム構成での多重度の上限を答えよ。
模範解答
9
解説
解答の論理構成
-
まず、タスク数の上限をサーバ単位で求めます。
【問題文】に「各スレーブサーバで同時に実行可能なタスクの数は、CPUの物理コア数-1を上限とする。」とあります。
また、同じ箇所に「スレーブサーバの仕様は、CPU物理コア数4」と明記されています。
よって、1 台のスレーブサーバが同時に処理できるタスク数の上限は
です。 -
次に、スレーブサーバの台数を確認します。
図1には「スレーブサーバ#1」「スレーブサーバ#2」「スレーブサーバ#3」の 3 台が描かれています。 -
多重度は「並列分散処理基盤全体で同時に実行するタスクの数」を指します。したがって、
が全体の上限となります。 -
以上より、図1のシステム構成における多重度の上限は 9 です。
誤りやすいポイント
- CPU コア数をそのまま多重度に採用してしまい、4 × 3 = 12 と計算してしまう。
「CPUの物理コア数-1」という条件を見落とすミスが頻発します。 - マスタサーバのコア数を合算してしまう。多重度の定義は“スレーブサーバで動くタスク数の総和”であり、マスタサーバは含まれません。
- 図1のスレーブサーバ台数を読み違える。図では 3 台ですが、設問を急いで読むと 2 台や 4 台と誤認することがあります。
FAQ
Q: マスタサーバの CPU コア数は多重度に影響しないのですか?
A: 影響しません。多重度はスレーブサーバ上で同時実行されるタスク数を指すため、マスタサーバは計算に含めません。
A: 影響しません。多重度はスレーブサーバ上で同時実行されるタスク数を指すため、マスタサーバは計算に含めません。
Q: 「CPUの物理コア数-1」としているのはなぜですか?
A: 1 コアを OS やデータ転送などの管理処理に残しておくことで、ユーザタスクがコア競合による性能劣化を受けにくくする設計慣行です。
A: 1 コアを OS やデータ転送などの管理処理に残しておくことで、ユーザタスクがコア競合による性能劣化を受けにくくする設計慣行です。
Q: スレーブサーバを追加すれば上限の多重度も比例して増えますか?
A: はい。追加したスレーブサーバも同じ仕様(物理コア数4)の場合、1 台ごとに多重度が 3 ずつ増えます。ただしネットワーク帯域やストレージ I/O がボトルネックになる可能性も考慮する必要があります。
A: はい。追加したスレーブサーバも同じ仕様(物理コア数4)の場合、1 台ごとに多重度が 3 ずつ増えます。ただしネットワーク帯域やストレージ I/O がボトルネックになる可能性も考慮する必要があります。
関連キーワード: 分散ファイルシステム、タスク並列度、ボトルネック、スケールアウト、CPUコア数
設問1:〔並列分散処理基盤のシステム構成〕について、(1)、(2)に答えよ。
(2)本文中の下線①について、どのようなリスクを指摘されたか。30字以内で述べよ。
模範解答
マスタサーバが冗長化されておらず、単一障害点である。
解説
解答の論理構成
- 【問題文】は、システムの要件として「任意のスレーブサーバ1台に障害が生じた場合でも処理を継続できるように、ブロックは2台のスレーブサーバのローカルストレージに非同期で複製」と述べ、スレーブ側の耐障害性を確保していることを示しています。
- 一方で、メタデータを一括管理するのは「マスタサーバ」であり、ジョブの受付・タスク分割・割当ても同一サーバが実施すると記載されています。
- さらに、マスタサーバの構成について冗長化や待機系の説明がなく、【問題文】で下線部「①可用性の観点からリスクがあるとの指摘」を受けたとあります。
- 以上から、マスタサーバが故障した場合にはメタデータ喪失やジョブ制御不能により全体が停止する=“単一障害点”になることがリスクだと論理的に導けるため、解答は以下になります。
- 解答:マスタサーバが冗長化されておらず、単一障害点である。
誤りやすいポイント
- スレーブサーバの複製機構を読んで「可用性は十分」と早合点し、マスタサーバに着目し忘れる。
- 「LAN#1」「LAN#2」が二重化されているかどうかに目を奪われ、本質的な制御点の冗長性を見落とす。
- “メタデータの保持”と“ジョブ制御”が同一サーバで行われることを意識せず、メタデータだけの問題だと誤解する。
FAQ
Q: マスタサーバが落ちてもブロックは2重化されているから安全では?
A: データブロックは残っても、メタデータを失うとファイルシステムが機能せずアクセスできません。またジョブ管理も停止するためシステム全体が利用不能になります。
A: データブロックは残っても、メタデータを失うとファイルシステムが機能せずアクセスできません。またジョブ管理も停止するためシステム全体が利用不能になります。
Q: マスタサーバをクラスタリングせずに運用するケースはありますか?
A: 検証環境や可用性がそれほど求められないバッチ処理などで一時的に単一構成とすることはありますが、本番で長期運用する場合は冗長化が推奨されます。
A: 検証環境や可用性がそれほど求められないバッチ処理などで一時的に単一構成とすることはありますが、本番で長期運用する場合は冗長化が推奨されます。
Q: スレーブサーバを増やしても単一障害点の問題は解決しますか?
A: いいえ。増設は処理性能の向上には寄与しますが、マスタサーバ故障時の停止リスクは残るため、別途マスタサーバの冗長化が必要です。
A: いいえ。増設は処理性能の向上には寄与しますが、マスタサーバ故障時の停止リスクは残るため、別途マスタサーバの冗長化が必要です。
関連キーワード: 単一障害点、冗長化、可用性、分散ファイルシステム、メタデータ管理
設問2:〔POSデータ集計・分析システムのジョブ構成〕について(1)、(2)に答えよ。
(1)表1中のaに入れる適切な字句を答えよ。
模範解答
a:商品別
解説
解答の論理構成
- 表1でジョブ(C)の“ジョブ名”は「商品別売上集計」、“処理内容”は「売上数量を商品別に集計する。」と明記されています。
- “ファイルの分割単位”欄は、ジョブ(B)では「店舗別」が記入されており、処理内容「売上数量を店舗別に集計する。」と対応しています。
- 同一の対応関係をジョブ(C)にも当てはめれば、商品ごとに集計する処理では“ファイルの分割単位”も商品単位になるのが自然です。
- したがって a には「商品別」が入ると導けます。
誤りやすいポイント
- ジョブ名ではなく“処理内容”との対応を見落とし、別の粒度(例:チェーン別など)を答えてしまう。
- ジョブ(B)の例を参照せずに勘で埋めてしまう。表内のパターン化を意識すると失点を防げます。
FAQ
Q: 「商品別」と「商品カテゴリ別」を混同しやすいです。違いは?
A: 本問では“取り扱われている商品数は10,000点”と具体的な商品アイテム数が示されています。カテゴリではなく個々の商品を指すため「商品別」が適切です。
A: 本問では“取り扱われている商品数は10,000点”と具体的な商品アイテム数が示されています。カテゴリではなく個々の商品を指すため「商品別」が適切です。
Q: “ファイルの分割単位”が処理内容と異なるケースはありますか?
A: あります。例えば大量データを均等化する目的で“日付別”に分割してから“月別集計”するなど。ただし本問はジョブ(B)の例に倣い、集計単位=分割単位という前提で設計されています。
A: あります。例えば大量データを均等化する目的で“日付別”に分割してから“月別集計”するなど。ただし本問はジョブ(B)の例に倣い、集計単位=分割単位という前提で設計されています。
Q: 分割単位を細かくし過ぎると何が問題ですか?
A: ブロックやファイルが増え過ぎるとメタデータ管理負荷が高まり、ジョブ起動オーバヘッドが増大します。128Mバイトのブロックサイズとのバランスを取ることが重要です。
A: ブロックやファイルが増え過ぎるとメタデータ管理負荷が高まり、ジョブ起動オーバヘッドが増大します。128Mバイトのブロックサイズとのバランスを取ることが重要です。
関連キーワード: ファイル分割、データ粒度、集計単位、分散処理、ワークロード
設問2:〔POSデータ集計・分析システムのジョブ構成〕について(1)、(2)に答えよ。
(2)並列分散処理を行わない場合と比較して、並列分散処理を行う場合のスループットの変化の比率が最も大きくなると見込めるジョブの記号を答えよ。
模範解答
(C)
解説
解答の論理構成
-
並列分散処理でスループットが伸びやすいジョブの条件
- タスクが大量に生成できること
- 各タスクに割り当てるデータ量がほぼ均一であること
- タスク間に依存関係がなく並列実行できること
これらがそろうと CPU コアやノードを増やした分だけスループットが向上します。
-
表1から各ジョブの特性を比較
- (A) はファイルが大きくばらつきも「大」で、データ不均衡が発生しやすい。
- (B) は (A) より改善されるが、ばらつきは「中」。
- (C) はファイルサイズが最小かつファイル数が最多で、ばらつきも「小」。データ分割が極めて均一でタスク数も潤沢に確保できる。
- (D) はタスク間の依存(重回帰分析のモデル計算→予測)があり、そもそも並列化が限定的。
-
図3「多重度と処理時間の関係」でも確認
- 多重度を1→9にしたときの処理時間短縮率
- ジョブ(A):8.0→2.0 時間で 4 倍
- ジョブ(B):2.9→0.5 時間で 5.8 倍
- ジョブ(C):7.3→1.0 時間で 7.3 倍
- ジョブ(D):13.5→6.0 時間で 2.25 倍
最も比率が大きいのは「ジョブ(C)」。
- 多重度を1→9にしたときの処理時間短縮率
-
よって、並列分散処理導入によるスループット向上効果が最大と見込めるジョブは
「(C)」。
誤りやすいポイント
- 「平均ファイルサイズ」が小さい=データ量が少ないから並列化効果が薄いと早合点する。実際は“タスクを細切れにしやすい”ため効果が高い。
- 図3の絶対時間だけを見て「(B) が一番速くなる」と判断し、倍率計算を忘れる。あくまで比較すべきは改善“率”。
- ジョブ(D)はファイルサイズも小さくばらつきも小さいが、処理フローに『「重回帰分析の偏回帰係数を求め」てから「予測」』という依存があり、並列度が上がっても劇的には短縮しない点を見落とす。
FAQ
Q: 「データサイズのばらつき」が大きいと何が問題ですか?
A: タスク間の処理量に差が出て、速く終わるタスクはアイドル時間が増えます。結果として全体の並列効率が下がります。
A: タスク間の処理量に差が出て、速く終わるタスクはアイドル時間が増えます。結果として全体の並列効率が下がります。
Q: ファイル数が多いとメタデータ(マスタサーバ)への負荷は心配ありませんか?
A: マスタサーバの CPU コアが「2」である点は注意が必要ですが、(C) のファイルサイズが小さいため IO 負荷が分散され、タスク処理の方が支配的になるので効果の方が勝ります。
A: マスタサーバの CPU コアが「2」である点は注意が必要ですが、(C) のファイルサイズが小さいため IO 負荷が分散され、タスク処理の方が支配的になるので効果の方が勝ります。
Q: ジョブ(B)の改善倍率が 5.8 倍で十分大きいのに、なぜ (C) を選ばないと減点ですか?
A: 問題は「比率が最も大きくなるジョブ」を尋ねています。「7.3 倍」の (C) が最大なので (B) を選ぶと誤答になります。
A: 問題は「比率が最も大きくなるジョブ」を尋ねています。「7.3 倍」の (C) が最大なので (B) を選ぶと誤答になります。
関連キーワード: スループット、多重度、データ分散、タスク並列、負荷分散
設問3:〔性能テスト〕について、(1)、(2)に答えよ。
(1)本文中の下線②が発生した際にボトルネックとなった原因を、図2中の各サーバのリソース使用状況から判断して答えよ。
模範解答
スレーブサーバのディスクI/O速度
解説
解答の論理構成
- 図2のディスクグラフを確認
– スレーブサーバ#1のディスクI/Oはジョブ実行開始直後から「約60Mバイト/秒」で張り付いたまま推移しています。
– この値は【問題文】で示されたスレーブサーバの仕様「ローカルストレージのディスクI/O速度60Mバイト/秒」に一致し、ハードウェア上限に到達していることを示します。 - CPU・メモリに余裕があることを確認
– CPU使用率は「20~50%」程度で振動しており上限には全く届いていません。
– メモリ使用量も「11~15Gバイト」で、搭載量「16Gバイト」を使い切っていません。
– したがって計算資源やメモリ資源はボトルネックではありません。 - データ処理の特性を踏まえて判断
– ジョブ(B)の処理は表1にあるとおり「売上数量を店舗別に集計する。」で、入力ファイルは平均「100Mバイト」を「6,300個」読み込みます。
– 分散ファイルシステムのブロックサイズは「128Mバイト」なので、ほぼ全ファイルが1ブロックに収まり、タスクはファイル数分発行されます。
– タスクが CPU ではなく大量の読み込み中心であるため、ディスク I/O が集中すると上限に達しやすい構造です。 - 結論
– CPU とメモリには余裕があり、ディスク I/O が連続して上限の「60Mバイト/秒」に張り付いているため、ボトルネックは「スレーブサーバのディスクI/O速度」です。
誤りやすいポイント
- マスタサーバのディスクがときどき 0 付近になるので「マスタの I/O が原因」と誤認する。実際はスレーブが継続的に上限に張り付いている点が本質です。
- CPU 使用率が周期的に変動しているのを見て「CPU が不足」と判断してしまう。変動していても平均値が高くなければボトルネックではありません。
- 表1の「データサイズのばらつき 中」を見てネットワーク負荷を疑う。ジョブ(B)はローカルストレージからの読み込み主体なので、まずディスク I/O を確認する必要があります。
FAQ
Q: ディスク I/O がボトルネックかどうかは必ず上限張り付きで判断するのですか?
A: 基本的には最大スループット近辺で長時間推移していれば I/O ボトルネックと判断できます。短時間のピークだけでは別要因のこともあるので平均的な使用状況を確認します。
A: 基本的には最大スループット近辺で長時間推移していれば I/O ボトルネックと判断できます。短時間のピークだけでは別要因のこともあるので平均的な使用状況を確認します。
Q: ディスク I/O ボトルネックを解消する典型的な方法は?
A: ストレージを高速化(SSD へ換装、RAID 構成の見直しなど)、データの複製数を増やして並列読み取り経路を確保、またはスレーブサーバを増やして I/O を分散する方法があります。
A: ストレージを高速化(SSD へ換装、RAID 構成の見直しなど)、データの複製数を増やして並列読み取り経路を確保、またはスレーブサーバを増やして I/O を分散する方法があります。
Q: CPU 使用率が 100% に張り付いていなくても CPU が原因になるケースはありますか?
A: I/O 待ち時間が長いと CPU 使用率は低く見えますが処理が進まないことがあります。この場合は I/O が主因なので、CPU より I/O を先に疑います。
A: I/O 待ち時間が長いと CPU 使用率は低く見えますが処理が進まないことがあります。この場合は I/O が主因なので、CPU より I/O を先に疑います。
関連キーワード: ディスクスループット、I/Oボトルネック、分散ファイルシステム、タスク分散、パフォーマンスチューニング
設問3:〔性能テスト〕について、(1)、(2)に答えよ。
(2)ボトルネックの解消に有効な対策を解答群の中から二つ選び、記号で答えよ。
解答群
ア:スレーブサーバのCPUを物理コア数が多いモデルに換装する。
イ:スレーブサーバのローカルストレージを高速なモデルに換装する。
ウ:スレーブサーバを増設し、1台当たりで同時実行するタスク数を減らす。
エ:分散ファイルシステムのブロックサイズを64Mバイトに変更する。
オ:マスタサーバのメモリを増設する。
模範解答
イ、ウ
解説
解答の論理構成
-
ボトルネックの特定
- 問題文では「②ジョブ(B)が目標処理時間内に完了しないことが判明した」とあり、図2のディスク I/O グラフではスレーブサーバ側が終始ほぼ飽和しています。
- スレーブサーバの仕様は「ローカルストレージのディスクI/O速度60Mバイト/秒である」と明示されており、グラフの値もほぼこの上限付近で張り付いていることから、ディスク I/O が性能ネックと判断できます。
-
有効な対策の選定
- 対策イ「スレーブサーバのローカルストレージを高速なモデルに換装する」
・ボトルネックとなっているディスク I/O の上限値を引き上げる直接的な施策です。 - 対策ウ「スレーブサーバを増設し、1台当たりで同時実行するタスク数を減らす」
・ノードを横に増やせば分散ファイルシステム上の同時 I/O が複数台に分散され、各ノードのディスク負荷が低下します。 - 以上より、イとウが採用されます。
- 対策イ「スレーブサーバのローカルストレージを高速なモデルに換装する」
-
他の選択肢が不適切な理由
- ア「CPUを物理コア数が多いモデルに換装」
・図2では CPU 使用率が 100% に張り付いておらず、CPU はボトルネックではありません。 - エ「ブロックサイズを64Mバイトに変更」
・ブロック数が増え、メタデータ管理やタスク分割のオーバヘッドが増大する恐れがあり、I/O 上限そのものは改善されません。 - オ「マスタサーバのメモリを増設」
・ジョブ(B)中、マスタサーバはメモリ 4G バイト程度で頭打ちになっており、メモリ不足の兆候は見られません。 - よって採用は見送ります。
- ア「CPUを物理コア数が多いモデルに換装」
誤りやすいポイント
- CPU グラフの短時間ピークを見て「CPU が足りない」と早合点する。長時間平均で見ると余裕があることを見落としやすいです。
- 「ブロックサイズを小さくすれば読み込み量が減る」と誤解する。実際には読み込み量は同じで I/O リクエストが細かくなり、逆効果になる場合があります。
- マスタサーバのリソースばかり注視し、スレーブサーバのディスク飽和を見落とす。
FAQ
Q: ディスク I/O を高速化する場合、SSD への換装だけで十分ですか?
A: ジョブ(B)のワークロードが連続読取り中心なら SSD 以外にも NVMe や RAID0 の採用でさらに帯域を伸ばす手段があります。I/O パターンを確認し、最もコスト効率の高い手段を選択してください。
A: ジョブ(B)のワークロードが連続読取り中心なら SSD 以外にも NVMe や RAID0 の採用でさらに帯域を伸ばす手段があります。I/O パターンを確認し、最もコスト効率の高い手段を選択してください。
Q: スレーブサーバを追加するとネットワーク負荷は増えませんか?
A: 分散ファイルシステムのレプリケーションやシャッフル通信で LAN 帯域は増加します。図1では「LAN#2」にスレーブを接続しているため、増設時はスイッチのバックプレーンや NIC の速度も合わせて見積もる必要があります。
A: 分散ファイルシステムのレプリケーションやシャッフル通信で LAN 帯域は増加します。図1では「LAN#2」にスレーブを接続しているため、増設時はスイッチのバックプレーンや NIC の速度も合わせて見積もる必要があります。
Q: ブロックサイズを小さくするメリットは全くないのでしょうか?
A: タスク並列性を高めたい場合は有効ですが、本問では既にディスクが飽和しており並列性より I/O 帯域が律速になっています。メリット・デメリットをケースバイケースで検討することが重要です。
A: タスク並列性を高めたい場合は有効ですが、本問では既にディスクが飽和しており並列性より I/O 帯域が律速になっています。メリット・デメリットをケースバイケースで検討することが重要です。
関連キーワード: ディスクI/O, ボトルネック解析、スケールアウト、分散ファイルシステム
設問4:
〔スケールアウトの計画〕について、本文中のb〜dに入れる適切な数値を答えよ。c、dの数値は小数点以下を切り上げて、整数で答えよ。ここで、各ジョブの目標処理時間は変更しないものとし、図3における処理時間の変化の比率は、測定範囲外においても測定範囲内とほぼ等しくなることを前提とする。また、ボトルネックを解消するために講じた対策によって、多重度やスレーブサーバの台数は変化していないものとする。
模範解答
b:4.5 (5.7, 6, 6.75, も可)
c:41 (52, 54, 61 も可)
d:11 (15, 18 も可)
解説
解答の論理構成
-
現状の多重度を確認
【問題文】には- 「並列分散処理基盤全体で同時に実行するタスクの数を多重度という。」
- 「各スレーブサーバで同時に実行可能なタスクの数は、CPUの物理コア数-1を上限とする。」
- 「スレーブサーバの仕様は、CPU物理コア数4」
とあるので、1台当たり 4-1=3 タスク。スレーブサーバは3台なので
現行の多重度 = 3台 × 3タスク/台 = 9。
-
スケール性能の基準を把握
【問題文】の記述- 「多重度を3倍にした場合、ジョブ(A)におけるスループットは2倍となる。」
より、多重度とスループットの比例係数は
3倍の多重度 → 2倍のスループット ⇒ スループット増分 = (2/3) × 多重度増分 - 「多重度を3倍にした場合、ジョブ(A)におけるスループットは2倍となる。」
-
3倍のスループット達成に必要な多重度比 b
求める多重度増分 k を(2/3) × k = 3 (現在のスループットを1とする) k = 3 × 3 / 2 = 4.5よって
b = 4.5 -
必要な多重度 c を整数化
現行多重度9の 4.5 倍なので9 × 4.5 = 40.5小数点以下切り上げ → 41 が最低限の多重度。
c = 41 -
追加すべきスレーブサーバ台数 d
1台当たり3タスクなので、必要台数はceil(41 ÷ 3) = ceil(13.666…) = 14 台現在は3台のため14 - 3 = 11 台d = 11
誤りやすいポイント
- 「多重度」を“サーバ台数”と混同し、現在の多重度を 3 として計算してしまう。
- 【問題文】の「ジョブ(A)」が “最も短縮されにくい” ことを見落とし、別ジョブの特性でスループットを計算する。
- 切り上げ指示を読み飛ばし、40.5 や 13.6 などの小数をそのまま解答に書く。
FAQ
Q: どうしてジョブ(A)だけを基準にしたのですか?
A: 【問題文】に「多重度を増やしても処理時間が最も短縮されにくいジョブはジョブ(A)である。」と明示されており、全体スループットを見積もる際のボトルネックになるためです。
A: 【問題文】に「多重度を増やしても処理時間が最も短縮されにくいジョブはジョブ(A)である。」と明示されており、全体スループットを見積もる際のボトルネックになるためです。
Q: 多重度を3倍にしてスループットが2倍になる根拠はどこにありますか?
A: 【問題文】に「多重度を3倍にした場合、ジョブ(A)におけるスループットは2倍となる。」と記載されています。図3の測定結果を要約した文です。
A: 【問題文】に「多重度を3倍にした場合、ジョブ(A)におけるスループットは2倍となる。」と記載されています。図3の測定結果を要約した文です。
Q: 追加台数を算出する際に“切り上げ”が必要なのは?
A: タスクやサーバは分割できないため、実際の運用では必要数を越えた最小の整数にそろえる必要があるからです。指示は「小数点以下を切り上げて、整数で答えよ」と明示されています。
A: タスクやサーバは分割できないため、実際の運用では必要数を越えた最小の整数にそろえる必要があるからです。指示は「小数点以下を切り上げて、整数で答えよ」と明示されています。
関連キーワード: 多重度、スループット、並列分散処理、スケールアウト、ボトルネック
