応用情報技術者 2018年 秋期 午後 問03
ウェーブレット木に関する次の記述を読んで、設問1~4に答えよ。
ウェーブレット木は、文字列内の文字の出現頻度を集計する場合などに用いられる2分木である。ウェーブレット木は、文字列内に含まれる文字を符号化して、それを基に構築される。特に計算に必要な作業領域を小さくできるので、文字列が長大な場合に効果的である。
例えば、DNAはA(アデニン)、C(シトシン)、G(グアニン)、T(チミン)の4種類の文字の配列で表すことができ、その配列は長大になることが多いので、ウェーブレット木はDNAの塩基配列(以下、DNA配列という)の構造解析に適している。
ウェーブレット木において、文字の出現回数を数える操作と文字の出現位置を返す操作を組み合わせることによって、文字列の様々な操作を実現することができる。本問では、文字の出現回数を数える操作を扱う。
〔ウェーブレット木の構築〕
文字の種類の個数が4の場合を考える。DNA配列を例に文字列Pを“CTCGAGAGTA”とするとき、ウェーブレット木が構築される様子を図1に示す。
ここで、2分木の頂点のノードを根と呼び、子をもたないノードを葉と呼ぶ。根からノードまでの経路の長さ(経路に含まれるノードの個数-1)を、そのノードの深さと呼ぶ。各ノードにはキー値を登録する。
図1では、文字列Pの文字Aを00、文字Cを01、文字Gを10、文字Tを11の2ビットのビット列に符号化して、ウェーブレット木を構築する様子を示している。また、図1の文字列の振り分けは、ウェーブレット木によって文字列Pが振り分けられる様子を示している。
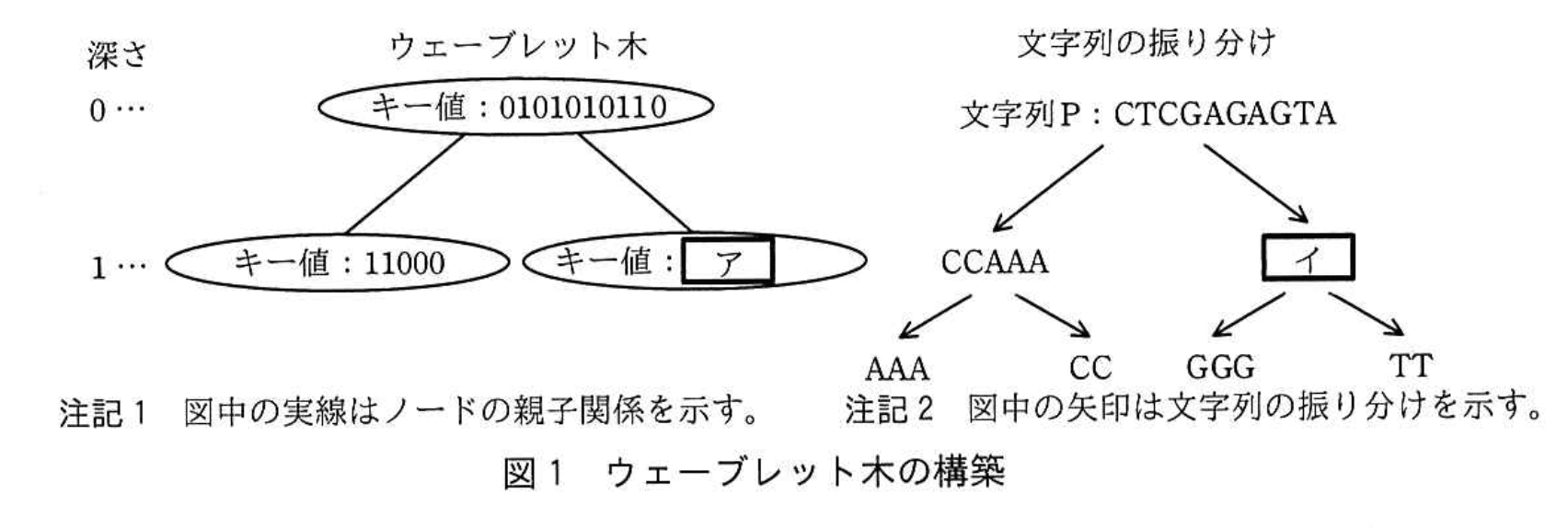
ウェーブレット木は、次の(1)〜(3)の手順で構築する。
(1) 根(深さ0)を生成し、文字列Pを対応付ける。
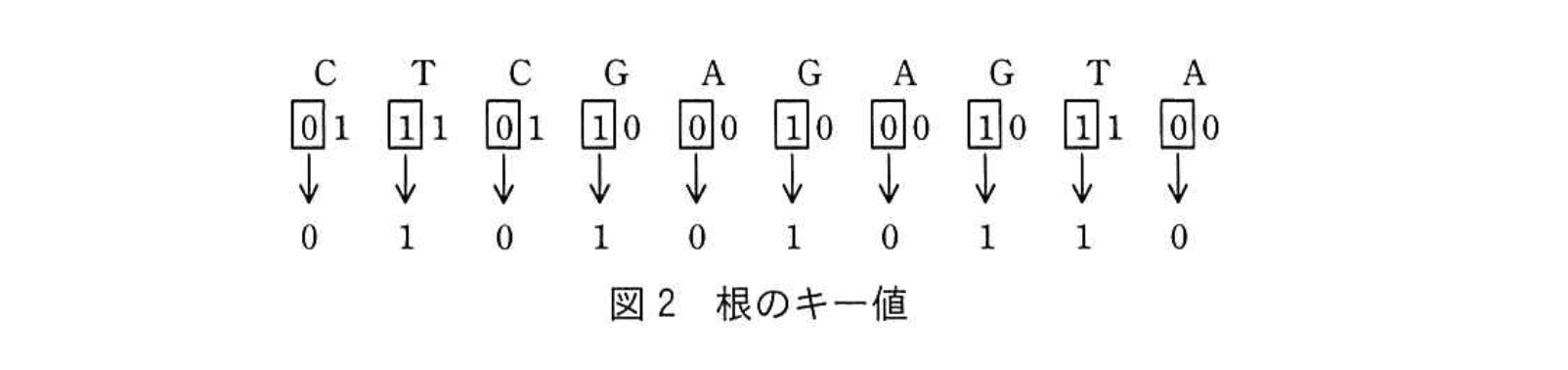
(2) ノードに対応する文字列の各文字を表す符号に対して、ノードの深さに応じて決まるビット位置のビットの値を取り出し、文字の並びと同じ順番で並べてビット列として構成したものをキー値としてノードに登録する。ここで、ノードの深さに応じて決まるビット位置は、“左から(深さ+1)番目”とする。
ノードが根の場合は、ビット位置は左から(0+1=1)番目となるので、図2に示すように、文字列P “CTCGAGAGTA”に対応する根のキー値はビット列0101010110となる。
(3) キー値のビット列を左から1ビットずつ順番に見ていき、キー値の元になった文字列から、そのビットに対応する文字を、ビットの値が0の場合とビットの値が1の場合とで分けて取り出し、それぞれの文字を順番に並べて新たな文字列を作成する。
文字列Pに対応する根のキー値の場合は、ビットの値が0の場合の文字列として“CCAAA”を取り出し、ビットの値が1の場合の文字列として“イ”を取り出す。
ビットの値が0の場合に取り出した文字列内の文字が2種類以上の場合は、その文字列に対応する新たなノードを生成して、左の子ノードとする。取り出した文字列内の文字が1種類の場合は、新たなノードは生成しない。
ビットの値が1の場合に取り出した文字列内の文字が2種類以上の場合は、その文字列に対応する新たなノードを生成して、右の子ノードとする。取り出した文字列内の文字が1種類の場合は、新たなノードは生成しない。
生成した子ノードに対して、(2)、(3)の処理を繰り返す。新たなノードが生成されなかった場合は、処理を終了する。
〔文字の出現回数を数える操作〕
文字列P全体での文字C(=01)の出現回数は、次の(1)、(2)の手順で求める。
(1) 文字Cの符号の左から1番目のビットの値は0なので、文字Cは根から左の子ノードに振り分けられる。左の子ノードに振り分けられる文字の個数は、根のキー値の0の個数に等しく、ウである。
(2) 文字Cの符号の左から2番目のビットの値は1である。(1)で振り分けられた左の子ノードのキー値の1の個数は2で、このノードは葉であるので、これが文字列P全体での文字Cの出現回数となる。
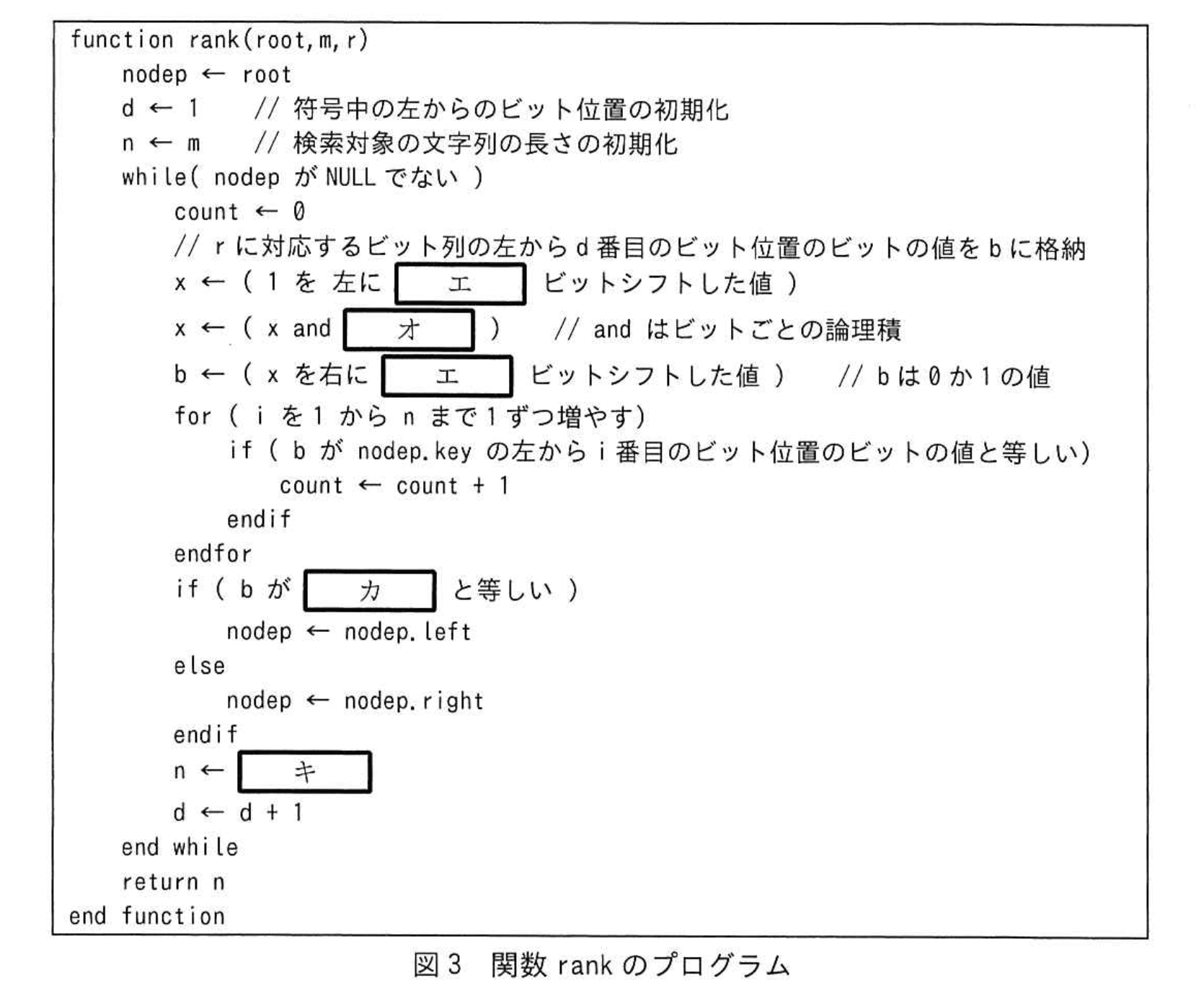
〔文字の出現回数を数えるプログラム〕
与えられた文字列Q内に含まれる文字の種類の個数をσとするとき、あらかじめ生成したウェーブレット木を用いて、与えられた文字列内で指定した文字の出現回数を数えるプログラムを考える。ウェーブレット木の各ノードを表す構造体Nodeを表1に示す。左の子ノード、又は右の子ノードがない場合は、それぞれ、left、rightにはNULLを格納する。

文字列Qに対応して生成したウェーブレット木の根へのポインタをrootとする。文字列Q内に存在する一つの文字(以下、対象文字という)をビット列に符号化して、整数(0~σ-1)に変換したものをrとする。
このとき、文字列Qの1文字目からm文字目までの部分文字列で、対象文字の出現回数を数える関数rank(root,m,r)のプログラムを図3に示す。
文字の符号化に必要な最小のビット数は、大域変数DEPTHに格納されているものとする。
〔ウェーブレット木の評価〕
文字列Qが与えられたとき、文字列Qの長さをN、文字の種類の個数を0とする。ここで、議論を簡潔にするためには2以上の2のべき乗とする。
文字列Qが与えられたときのウェーブレット木の構築時間は、文字ごとにか所のノードで操作を行い、各ノードでの操作は定数時間で行うことができるので、合計でO(ケ ✕ )である。
構築されたウェーブレット木が保持するキー値のビット列の長さの総和は、コである。
設問1:
図1中のア、図1及び本文中のイに入れる適切な字句を答えよ。
模範解答
ア:10001
イ:TGGGT
解説
解答の論理構成
-
文字列の符号化
【問題文】には「文字列Pの文字Aを00、文字Cを01、文字Gを10、文字Tを11の2ビットのビット列に符号化して、ウェーブレット木を構築する」とあります。
そこで P=“CTCGAGAGTA” を 2 ビットごとに並べると、上位ビット(1 ビット目)はC T C G A G A G T A 0 1 0 1 0 1 0 1 1 0となり、根のキー値が “0101010110” になることが【問題文】で示されています。 -
根からの振り分け
根のキー値 “0101010110” を左から走査し、ビットが0の位置の文字を左側、1の位置の文字を右側に順序を保って集めます。- 0 だった位置(1,3,5,7,10 文字目)→ “C C A A A”
- 1 だった位置(2,4,6,8,9 文字目)→ “T G G G T”
【問題文】に示された「ビットの値が0の場合の文字列として“CCAAA”」「ビットの値が1の場合の文字列として“イ”」より、 イ=“TGGGT” で確定します。
-
深さ1(右子ノード)のキー値
右子ノードは “TGGGT” に対応します。深さ1 なので【問題文】の規定「ノードの深さに応じて決まるビット位置は、“左から(深さ+1)番目”」より、2 ビット目(下位ビット)を並べたものがキー値です。T G G G T 1 0 0 0 1したがって右子ノードのキー値は “10001”。
図1中の ア に入る文字列は “10001” となります。 -
結論
ア:10001
イ:TGGGT
誤りやすいポイント
- 文字列の順序保持を忘れ、ビット0・1ごとにソートしてしまう
- 深さに応じたビット位置の数え方(“左から(深さ+1)番目”)を取り違え、1 ビット目を再利用してしまう
- 2 ビット符号の上位・下位を逆に読んで “01010…” と “10101…” を取り違える
- “TGGGT” の G を3個ではなく4個、または T を1個見落として “TGGG” としてしまう
FAQ
Q: 文字列の順序は本当にそのまま保たないといけませんか?
A: はい。ウェーブレット木は区間数え上げにも使えるため、各ビットで振り分ける際に元の並び順を厳密に維持します。
A: はい。ウェーブレット木は区間数え上げにも使えるため、各ビットで振り分ける際に元の並び順を厳密に維持します。
Q: 深さが増えたときは常に “左から(深さ+1)番目” のビットですか?
A: そのとおりです。深さ0 なら1 ビット目、深さ1 なら2 ビット目、…という規則で符号のビットを参照します。
A: そのとおりです。深さ0 なら1 ビット目、深さ1 なら2 ビット目、…という規則で符号のビットを参照します。
Q: “10001” の後にさらに子ノードはできますか?
A: “10001” 内には0と1が両方あるため、左右それぞれに文字列を分け、種類が1種類にならない限り再帰的に分割を続けることができます。
A: “10001” 内には0と1が両方あるため、左右それぞれに文字列を分け、種類が1種類にならない限り再帰的に分割を続けることができます。
関連キーワード: ウェーブレット木、2分木、文字列処理、ビット列、符号化
設問2:
本文中のウに入れる適切な字句を答えよ。
模範解答
ウ:5
解説
解答の論理構成
- 根ノードのキー値
問題文には「文字列P “CTCGAGAGTA”に対応する根のキー値はビット列0101010110となる。」と明記されています。 - 0 の個数を数える
同じく問題文で「左の子ノードに振り分けられる文字の個数は、根のキー値の0の個数に等しく、ウである。」とあります。
0101010110 の各ビットを左から確認すると
0,1,0,1,0,1,0,1,1,0 の計10ビットのうち
0 は 1・3・5・7・10 番目の 5 か所です。 - よって ウ には 5 が入ります。
誤りやすいポイント
- ビット列「0101010110」を 2 進数の値として解釈してしまい、0 の“個数”ではなく“値”で比較してしまう。
- ビットを左からではなく右から数えて 0 の位置を取り違える。
- 「0101010110」を 8 ビットや 12 ビットと誤認し、桁数を増減して数えてしまう。
FAQ
Q: 文字列Pを実際に左半分・右半分に分けて数える必要はありますか?
A: いいえ、根ノードのキー値に含まれる 0 の個数だけで左側に振り分けられる総文字数が分かります。
A: いいえ、根ノードのキー値に含まれる 0 の個数だけで左側に振り分けられる総文字数が分かります。
Q: 0 と 1 の個数を同時に数えた方が安全でしょうか?
A: 問題が求めているのは 0 の個数だけです。0 を数えれば 1 の個数は全長から差し引いて求められるため、二重作業は不要です。
A: 問題が求めているのは 0 の個数だけです。0 を数えれば 1 の個数は全長から差し引いて求められるため、二重作業は不要です。
Q: キー値が長い場合でも同じ手順で良いですか?
A: はい。ビット列が長くても「0 の個数を数える → 左側の文字数」とするルールは変わりません。
A: はい。ビット列が長くても「0 の個数を数える → 左側の文字数」とするルールは変わりません。
関連キーワード: ウェーブレット木、ビット列、出現回数、文字列処理
設問3:
図3中のエ〜キに入れる適切な字句を答えよ。
模範解答
エ:DEPTH - d
オ:r
カ:0
キ:count
解説
解答の論理構成
-
取得したいのは “対象文字の符号の左から d 番目のビット”
【問題文】には
“// r に対応するビット列の左から d 番目のビット位置のビットの値を b に格納”
と明記されています。
そこで
text x ← ( 1 を左に エ ビットシフト… ) x ← ( x and オ ) b ← ( x を右に エ ビットシフト… )という 3 ステップで r の該当ビットだけを取り出します。 -
エ の決定
r は “文字の符号化に必要な最小のビット数” で表され、その値は “大域変数DEPTH” に保持されるとあります。
左から d 番目のビットを取り出すには、右寄せ表現で
シフト量 = DEPTH - d
とするのが定石です。
したがって
エ=“DEPTH - d”。 -
オ の決定
and でマスクする相手は符号そのもの、すなわち “r” です。
よって
オ=“r”。 -
カ の決定
ビット値が 0 なら左部分列へ、1 なら右部分列へ進むのは
【問題文】“文字Cの符号の左から1番目のビットの値は0なので、文字Cは根から左の子ノードに振り分けられる”
から明らかです。比較対象は数値リテラル “0”。
よって
カ=“0”。 -
キ の決定
ループの最後で n を次レベルの文字列長に更新する行です。
その値は for ループで数え上げた count に置き換わります。
“count ← count + 1” により得られるのは “次ノードに渡す部分文字列長” なので
キ=“count”。
以上より
エ:DEPTH - d
オ:r
カ:0
キ:count
エ:DEPTH - d
オ:r
カ:0
キ:count
誤りやすいポイント
- DEPTH と d の引き算の向きを逆に書き “d - DEPTH” としてしまう
(左端基準か右端基準かを取り違え)。 - オ に nodep.key を入れてしまい、ビット抽出対象を誤る。
- b==1 を左に、b==0 を右に進むと勘違いして条件を反転。
- n ← m - count のように減算してしまい、次レベルの長さを壊す。
FAQ
Q: ビット列長 DEPTH が 3 なら、d=1 のときシフト量はいくつですか?
A: DEPTH - d = 3 - 1 = 2 ビット左シフトです。
A: DEPTH - d = 3 - 1 = 2 ビット左シフトです。
Q: なぜ nodep.key ではなく r に and を取るのですか?
A: 抽出したいのは “対象文字 r のビット値” で、nodep.key は “文字列側の並び情報” を保持するためです。
A: 抽出したいのは “対象文字 r のビット値” で、nodep.key は “文字列側の並び情報” を保持するためです。
Q: ループ終了後に return する値が n のままなのは?
A: while ループで n ← count と更新を繰り返すことで “探索区間内の対象文字数” が n に蓄積され、葉到達時にそのまま出現回数になります。
A: while ループで n ← count と更新を繰り返すことで “探索区間内の対象文字数” が n に蓄積され、葉到達時にそのまま出現回数になります。
関連キーワード: ビットマスク、シフト演算、文字頻度集計、2分探索木
設問4:
本文中のク〜コに入れる適切な字句を答えよ。
模範解答
ク:σ
ケ:N
コ:
解説
解答の論理構成
-
【問題文】には
“与えられた文字列Q内に含まれる文字の種類の個数をσとするとき”
と明記されています。この “σ” が以後の計算量評価でそのまま使われるため、 “文字ごとにか所のノードで操作を行い”
の ク には “σ” が入ります。
⇒ ク = σ -
同じ段落で
“文字列Qが与えられたとき、文字列Qの長さをN”
と置いています。よって式
“合計でO(ケ ✕ )である。”
の ケ には “N” が入ります。
⇒ ケ = N -
文字が1文字あたり ビットずつ複数レベルに分散してキー値に格納されるので、全体のビット列長は
。
【問題文】の
“構築されたウェーブレット木が保持するキー値のビット列の長さの総和は、コである。”
に当てはめると
⇒ コ =
以上より
ク:σ
ケ:N
コ:
ク:σ
ケ:N
コ:
誤りやすいポイント
- “σ” と “N” の取り違え
σは“種類数”、Nは“文字列長”です。両者を逆に入れると計算量が O(σ log₂N) となり意味が変わってしまいます。 - 乗算か指数かの混同
は “N と log を掛ける” 形です。 ではありません。 - 2 のべき乗の前提を見落とす
“ここで、議論を簡潔にするためには2以上の2のべき乗とする” という一文は、深さ= が整数になることを保証しています。これを忘れると “天井関数” 付きの式を誤って書きがちです。
FAQ
Q: なぜ文字ごとに レベルをたどるのですか?
A: 文字を “0…σ−1” の整数に符号化すると、その2進表現は高々 ビットです。ウェーブレット木は各レベルで1ビットずつ消費して分岐するため、1文字あたり必要なノード訪問数が になります。
A: 文字を “0…σ−1” の整数に符号化すると、その2進表現は高々 ビットです。ウェーブレット木は各レベルで1ビットずつ消費して分岐するため、1文字あたり必要なノード訪問数が になります。
Q: ビットはメモリ量としてどの程度効率的ですか?
A: 生の配列保存では2ビット/塩基×N= ビット必要です。本問の符号化も2ビットですが、ウェーブレット木はそのまま検索構造を兼ねているため、“追加のインデックスなしで同じオーダ” という点が効率的です。
A: 生の配列保存では2ビット/塩基×N= ビット必要です。本問の符号化も2ビットですが、ウェーブレット木はそのまま検索構造を兼ねているため、“追加のインデックスなしで同じオーダ” という点が効率的です。
Q: σ が 4 以外でも式は変わりませんか?
A: はい。σを一般化しても深さは常に 、総ビット長は となります。σ が2のべき乗でない場合は に読み替えれば同様です。
A: はい。σを一般化しても深さは常に 、総ビット長は となります。σ が2のべき乗でない場合は に読み替えれば同様です。
関連キーワード: ウェーブレット木、出現回数、時間計算量、空間計算量、ビット操作
