応用情報技術者 2021年 春期 午後 問03
クラスタ分析に用いる k-means 法に関する次の記述を読んで、設問1〜3に答えよ。
k-means 法によるクラスタ分析は、異なる性質のものが混ざり合った母集団から互いに似た性質をもつものを集め、クラスタと呼ばれる互いに素な部分集合に分類する手法である。新聞記事のビッグデータ検索、店舗の品ぞろえ分類、教師なし機械学習などで利用されている。ここでは、2 次元データを扱うこととする。
〔分類方法と例〕
N個の点をK個(N未満)のクラスタに分類する方法を (1)〜(5) に示す。
(1) N個の点(1 からNまでの番号が付いている)からランダムにK個の点を選び(以下、初期設定という)、それらの点をコアと呼ぶ。コアには1 からKまでのコア番号を付ける。なお、K個のコアの座標は全て異なっていなければならない。
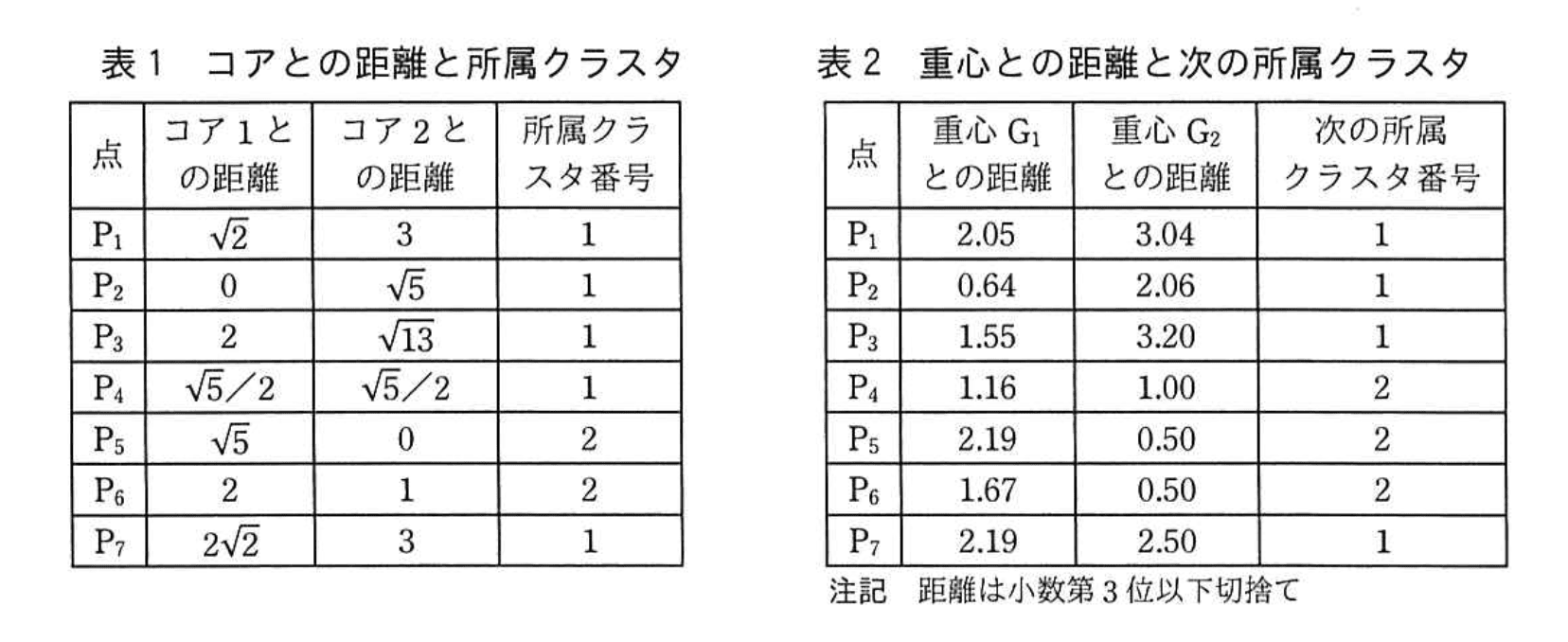
(2) N個の点とK個のコアとの距離をそれぞれ計算し、各点から見て、距離が最も短いコア(複数存在する場合は、番号が最も小さいコア)を選ぶ。選ばれたコアのコア番号を、各点が所属する1 回目のクラスタ番号(1 からK)とする。ここで、二つの点を XY 座標を用いて P=(a, b) と Q=(c, d) とした場合、P と Q の距離をで計算する。
(3) K個のクラスタのそれぞれについて、クラスタに含まれる全ての点を使って重心を求める。ここで、重心の X 座標をクラスタに含まれる点の X 座標の平均、Y 座標をクラスタに含まれる点の Y 座標の平均と定義する。ここで求めた重心の番号はクラスタの番号と同じとする。
(4) N個の点と各クラスタの重心 (、・・・、) との距離をそれぞれ計算し、各点から見て距離が最も短い重心(複数存在する場合は、番号が最も小さい重心)を選ぶ。選ばれた重心の番号を、各点が所属する次のクラスタ番号とする。
(5) 重心の座標が変わらなくなるまで、(3) と (4) を繰り返す。
次の座標で与えられる7 個の点を、この分類方法に従い、二つのクラスタに分類する例を図1に示す。
=(1, 0) =(2, 1) =(4, 1) =(1.5, 2) =(1, 3) =(2, 3) =(4, 3)

〔クラスタ分析のプログラム〕
この手法のプログラムを図2に、プログラムで使う主な変数、関数及び配列を表3に示す. ここで、配列の添字は全て1から始まり、要素の初期値は全て0とする.


〔初期設定の改良〕
このアルゴリズムの最終結果は初期設定に依存し、そこでのコア間の距離が短いと適切な分類結果を得にくい。そこで、関数 initial において一つ目のコアはランダムに選び、それ以降はコア間の距離が長くなる点が選ばれやすくなるアルゴリズムを検討した。検討したアルゴリズムでは、t 番目までのコアが決まった後、t+1 番目のコアを残った点から選ぶときに、それまでに決まったコアから離れた点を、より高い確率で選ぶようにする。具体的には、それまでに決まったコア(コア 1~コア t)と、残った N−t 個の点から選んだ点との距離の和をとする。N−t 個の全ての点についてを求め、がカほど高い確率で点が選ばれるようにする。このとき、点が t+1 番目のコアとして選ばれる確率としてキを適用する。
設問1:〔分類方法と例〕について、(1)、(2)に答えよ。
(1)図1中のアに入れる語句を答えよ。
模範解答
ア:(1.5, 3)
解説
解答の論理構成
- 【問題文】の手順(3)には
「クラスタの重心を求める。ここで、重心の X 座標をクラスタに含まれる点の X 座標の平均、Y 座標をクラスタに含まれる点の Y 座標の平均と定義する。」
とあります。したがって重心G₂はクラスタ2に入った点の平均座標で決まります。 - クラスタ番号は手順(2)によって決まり、その結果が【表1】です。表1で「所属クラスタ番号」が"2"になっているのは
・=(1, 3)
・=(2, 3)
の2点だけです。 - そこで平均を取ります。
X 座標:
Y 座標:
よって重心G₂=(1.5, 3)。 - 図1中のアはG₂の座標を示す欄なので、解答は(1.5, 3)となります。
誤りやすいポイント
- 【表1】を読み違え、をクラスタ2に含めてしまうと平均値がずれます。クラスタ2に属するのは「所属クラスタ番号」が"2"の行のみです。
- 手順(3)の「平均」は各座標軸ごとに求める点が重要です。X と Y を合算して2で割るなどの操作は誤りです。
- 重心が一意に決まるのは手順(2)を正しく実施したときだけです。初期設定のコア座標を使って平均を取ってしまうミスが散見されます。
FAQ
Q: 点が2個しかないクラスタでも重心は求められますか?
A: はい。平均を取る点数が2点でも式は同じです。今回のクラスタ2が該当し、との平均で求めています。
A: はい。平均を取る点数が2点でも式は同じです。今回のクラスタ2が該当し、との平均で求めています。
Q: 座標値が小数になる場合、小数第何位まで書くべきですか?
A: 手順(3)の重心計算では丸め指示がない限り exact 値を示します。本設問では整数と「1.5」のみなのでそのまま記載します。
A: 手順(3)の重心計算では丸め指示がない限り exact 値を示します。本設問では整数と「1.5」のみなのでそのまま記載します。
Q: 初期コアが異なる場合でもアは変わりますか?
A: 初期コアが変わればクラスタ分けが変わる可能性があり、重心も変動します。本問は「初期設定はコア1=、コア2=とする」と固定されているため計算結果は一意です。
A: 初期コアが変わればクラスタ分けが変わる可能性があり、重心も変動します。本問は「初期設定はコア1=、コア2=とする」と固定されているため計算結果は一意です。
関連キーワード: k-means, 重心, クラスタ番号, 平均座標, 距離計算
設問1:〔分類方法と例〕について、(1)、(2)に答えよ。
(2)図1中の下線①のように分類が完了したときに,P1と同じクラスタに入る点を全て答えよ。
模範解答
, ,
解説
解答の論理構成
- 【問題文】の手順(1)により初期設定は「コア1=、コア2=」です。
- 手順(2)で全点とコアの距離を計算した結果が【表1】です。ここで「所属クラスタ番号」が
・クラスタ1:、、、、
・クラスタ2:、
となります。 - 手順(3)で各クラスタの重心を求めます。クラスタ1の重心は【問題文】にあるとおり
「クラスタ1の重心 は (2.5, 1.4)」です。
クラスタ2は と だけなので - 手順(4)で各点と , の距離を比較した結果が【表2】です。ここで「次の所属クラスタ番号」は
・クラスタ1:、、、
・クラスタ2:、、
となり、 と同じクラスタに残ったのは , , です。 - 手順(5)で重心を再計算しても座標が変化しないため【問題文】の「①分類が完了する」状態に到達します。
- 以上より、求める解答は【模範解答】のとおり
, , となります。
誤りやすいポイント
- 【表1】と【表2】の「距離」を眺めただけで判断し、クラスタ番号を写し間違える。距離が小さい方に対応する番号を再確認しましょう。
- が最後にクラスタ2へ移動する点を見落とし、 まで解答に含めてしまう。
- 最終重心を再計算せず「1 回目の結果=最終結果」と思い込む。k-means 法は“重心が変わらなくなるまで”が条件です。
FAQ
Q: 途中でクラスタ数が変わることはありますか?
A: k-means 法では「K 個のクラスタ」に固定して重心と所属を見直すため、クラスタ数自体は変わりません。
A: k-means 法では「K 個のクラスタ」に固定して重心と所属を見直すため、クラスタ数自体は変わりません。
Q: 初期設定が違えば解答も変わりますか?
A: はい。手順(1)で選ぶコアが異なると重心の収束先が変わる可能性があります。本問は初期設定が指定されているため解答が一意に決まります。
A: はい。手順(1)で選ぶコアが異なると重心の収束先が変わる可能性があります。本問は初期設定が指定されているため解答が一意に決まります。
Q: のようにコアとの距離が同じ場合はどう扱いますか?
A: 【問題文】手順(2)に「複数存在する場合は、番号が最も小さいコア」と明記されています。同様に重心にも“番号が最も小さい”ルールを適用します。
A: 【問題文】手順(2)に「複数存在する場合は、番号が最も小さいコア」と明記されています。同様に重心にも“番号が最も小さい”ルールを適用します。
関連キーワード: k-means法, 重心計算, ユークリッド距離, クラスタ収束, 教師なし学習
設問2:
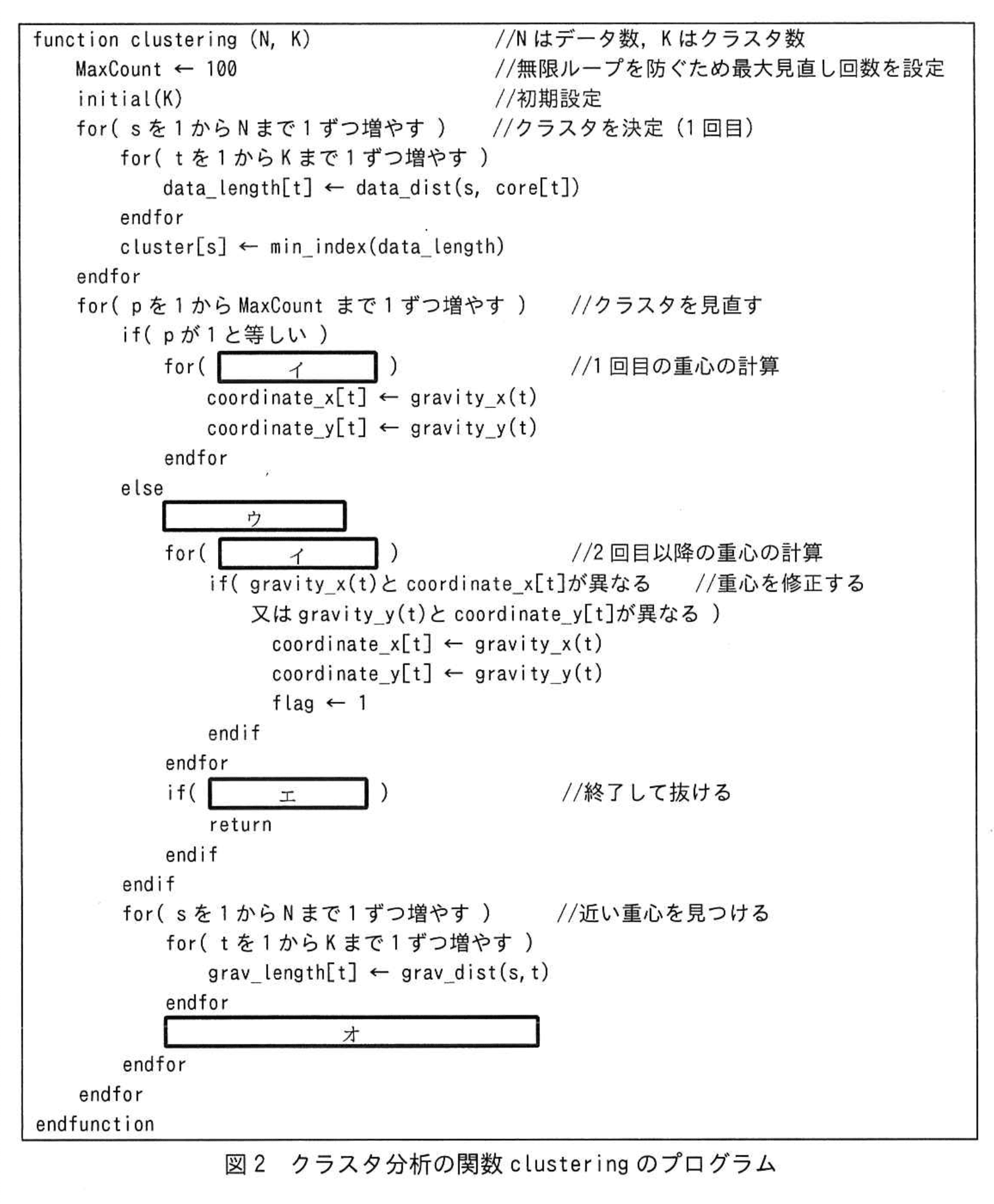
図2中のイ~オに入れる適切な字句を答えよ。
模範解答
イ:tを1からKまで1ずつ増やす
ウ:flag ← 0
エ:flagが0と等しい
オ:cluster[s] ← min_index(grav_length)
解説
解答の論理構成
-
【問題文】図2には
for( イ ) //1 回目の重心の計算
とあり、直前の行で if( p が 1 と等しい ) と分岐しています。重心はクラスタごとに 1 つなので、ここでループ変数はコアや重心に対応する t でなければなりません。さらに他のループ宣言は
for( t を 1 から K まで 1 ずつ増やす )
という書式で統一されています。したがってイは
tを1からKまで1ずつ増やす
となります。 -
2 回目以降の見直しでは、重心を修正したかどうかを判定するフラグが必要です。図2には
flag <- 1
とセットする処理が示されており、その前で必ず 0 に初期化する必要があります。従って ウ は
flag ← 0
です。 -
フラグが更新されなければ収束したと判断して終了します。図2のコメント
//終了して抜ける
に対応する条件は「flag が 0 と等しい」となります。よって エ は
flagが0と等しい
です。 -
各データ点が最も近い重心に属するようクラスタ番号を付け替える処理が
for( s を 1 から N まで 1 ずつ増やす ) //近い重心を見つける
の後に置かれています。距離を格納した grav_length 配列から最小値の添字を取り、その添字をクラスタ番号とするのは 1 回目の割当てと同じパターンです。図2の 1 回目では
cluster[s] <- min_index(data_length)
を使っているため、オ は同じ書式で
cluster[s] ← min_index(grav_length)
となります。
以上より、解答は
イ:tを1からKまで1ずつ増やす
ウ:flag ← 0
エ:flagが0と等しい
オ:cluster[s] ← min_index(grav_length)
イ:tを1からKまで1ずつ増やす
ウ:flag ← 0
エ:flagが0と等しい
オ:cluster[s] ← min_index(grav_length)
誤りやすいポイント
- イを s を 1 から N まで と誤ってデータ数で回してしまうと、重心計算が「クラスタ×データ点」の二重ループになり計算量が激増します。
- ウの初期化を忘れると、前回のループで立てた flag が残り続け、実際は重心が動いているのに即終了するバグが発生します。
- エの判定を flag が 1 と等しい と逆に書くと、重心が動いたときに終了してしまい、正しい収束判定ができません。
- オを min_value といった距離の最小値に置き換えてしまうと、「どのクラスタに属するか」という“添字”情報が失われます。
FAQ
Q: 重心の座標がまったく同じになるまで続けるのは計算コストが高くないですか?
A: 実装例では MaxCount <- 100 で安全策を取りつつ、フラグによる早期終了を併用しています。実務では座標差が閾値以下になったら収束とみなす手法もよく用いられます。
A: 実装例では MaxCount <- 100 で安全策を取りつつ、フラグによる早期終了を併用しています。実務では座標差が閾値以下になったら収束とみなす手法もよく用いられます。
Q: コアをランダムに選ぶと毎回結果が変わるのは問題では?
A: 【問題文】の「関数 initial において一つ目のコアはランダムに選び、それ以降はコア間の距離が長くなる点が選ばれやすくなるアルゴリズム」で改良できます。これにより初期設定の偏りを抑え、安定したクラスタリング結果を得やすくなります。
A: 【問題文】の「関数 initial において一つ目のコアはランダムに選び、それ以降はコア間の距離が長くなる点が選ばれやすくなるアルゴリズム」で改良できます。これにより初期設定の偏りを抑え、安定したクラスタリング結果を得やすくなります。
Q: min_index は ties(同距離が複数)をどう処理しますか?
A: 【問題文】では「複数存在する場合は、番号が最も小さいコア/重心を選ぶ」と明示されています。min_index はこのルールを実装しており、同じ距離ならインデックスの小さい方を返します。
A: 【問題文】では「複数存在する場合は、番号が最も小さいコア/重心を選ぶ」と明示されています。min_index はこのルールを実装しており、同じ距離ならインデックスの小さい方を返します。
関連キーワード: -means, クラスタリング, ユークリッド距離, 重心計算, 収束判定
設問3:〔初期設定の改良〕について、(1)、(2)に答えよ。
(1)本文中のカに入れる適切な字句を解答群の中から選び、記号で答えよ。
解答群
ア:大きい
イ:小さい
模範解答
カ:ア
解説
解答の論理構成
-
問題文は初期設定の改良意図を次のように述べています。
「それまでに決まったコアから離れた点を、より高い確率で選ぶようにする。」
ここで“離れた”とは距離の総和 が大きい点を指します。 -
続いて
「がカほど高い確率で点が選ばれるようにする。」
という一文があり、“離れた点ほど”に対応して カ には「大きい」が入るのが自然です。 -
以上より、カ=「大きい」と判断できます。
誤りやすいポイント
- 「離れた点を高確率で選ぶ」の逆に解釈し、“距離が小さい点”を優先すると勘違いしやすいです。
- は“距離の和”なので、距離が大きいほど も大きくなることを見落とすと判断を誤ります。
- k-means 全体の手順と“初期コア選択”の目的を混同し、後半の重心計算ロジックと同じ最小距離基準で考えてしまう失敗がよく見られます。
FAQ
Q: なぜ距離が大きい点を選ぶと精度が上がるのですか?
A: 初期コアが互いに遠いほどクラスタの種が散らばり、局所最適解に陥りにくくなるためです。
A: 初期コアが互いに遠いほどクラスタの種が散らばり、局所最適解に陥りにくくなるためです。
Q: に他の関数(例:距離の二乗和)を使っても問題ありませんか?
A: 可能ですが、値の大小関係が保たれれば効果は似ています。実装の単純さから“距離の和”がよく使われます。
A: 可能ですが、値の大小関係が保たれれば効果は似ています。実装の単純さから“距離の和”がよく使われます。
Q: 初期コアをランダムに複数回選び直す方法と比べてどちらが良いですか?
A: ランダム再試行は試行回数が必要ですが、この改良法は1回の試行で分散したコアを得やすいという利点があります。
A: ランダム再試行は試行回数が必要ですが、この改良法は1回の試行で分散したコアを得やすいという利点があります。
関連キーワード: k-means, クラスタ分析, 初期コア選択, ユークリッド距離, 重心計算
設問3:〔初期設定の改良〕について、(1)、(2)に答えよ。
(2)本文中のキに入れる適切な式をTtとSumを使って答えよ。
ここで、SumはN−t個の全てのの和とする。
模範解答
キ:/Sum
解説
解答の論理構成
- 問題文は「それまでに決まったコア(コア 1~コア t)と、残った N−t 個の点から選んだ点 との距離の和を とする。N−t 個の全ての点について を求め、 がカほど高い確率で点 が選ばれるようにする。」と述べています。
- つまり「 が大きい点ほど選ばれやすい=確率は に比例」させたい、という要求です。
- 確率の総和は 1 でなければなりません。よって、 をそのまま使うのではなく正規化します。
- 正規化の最も標準的な方法は「個々の を全体の和で割る」ことです。問題文でも「N−t 個の全ての の和」を Sum と定義しています。
- したがって、点 が t+1 番目のコアとして選ばれる確率は
となり、これが解答欄 キ に入る式です。
誤りやすいポイント
- 「大きい ほど高い確率」と読んで、単に を確率として採用してしまう。確率は 0〜1 に収まり、合計が 1 になる必要がある点を失念しがちです。
- を「最大値」や「平均値」と勘違いしてしまう。問題文は「N−t 個の全ての の和」と明記しているので注意しましょう。
- ではなく と逆に書いてしまうミス。比例・反比例の違いを図で確認すると防げます。
FAQ
Q: が 0 になるケースはありますか?
A: 距離が 0 となるのは既にコアとして選ばれた点自身だけです。残存点に対しては必ず 1 点以上離れたコアがあるため となり、確率計算で割り算の問題は生じません。
A: 距離が 0 となるのは既にコアとして選ばれた点自身だけです。残存点に対しては必ず 1 点以上離れたコアがあるため となり、確率計算で割り算の問題は生じません。
Q: が非常に大きくなると計算誤差が心配です。
A: double など通常の浮動小数点で十分扱える範囲です。極端に大規模なデータセットでは を分割計算し、最後に正規化することで数値安定性を確保できます。
A: double など通常の浮動小数点で十分扱える範囲です。極端に大規模なデータセットでは を分割計算し、最後に正規化することで数値安定性を確保できます。
Q: k-means++ と同じ考え方ですか?
A: はい。「距離が遠い点を高確率で初期コアに選ぶ」という点で k-means++ と同趣旨ですが、本問題では距離の“二乗”ではなく “和” を用いている点が実装上の違いです。
A: はい。「距離が遠い点を高確率で初期コアに選ぶ」という点で k-means++ と同趣旨ですが、本問題では距離の“二乗”ではなく “和” を用いている点が実装上の違いです。
関連キーワード: k-means, クラスタリング, 重心, 確率分布, ユークリッド距離
