応用情報技術者 2022年 春期 午後 問03
パズルの解答を求めるプログラムに関する次の記述を読んで、設問1~3に答えよ。
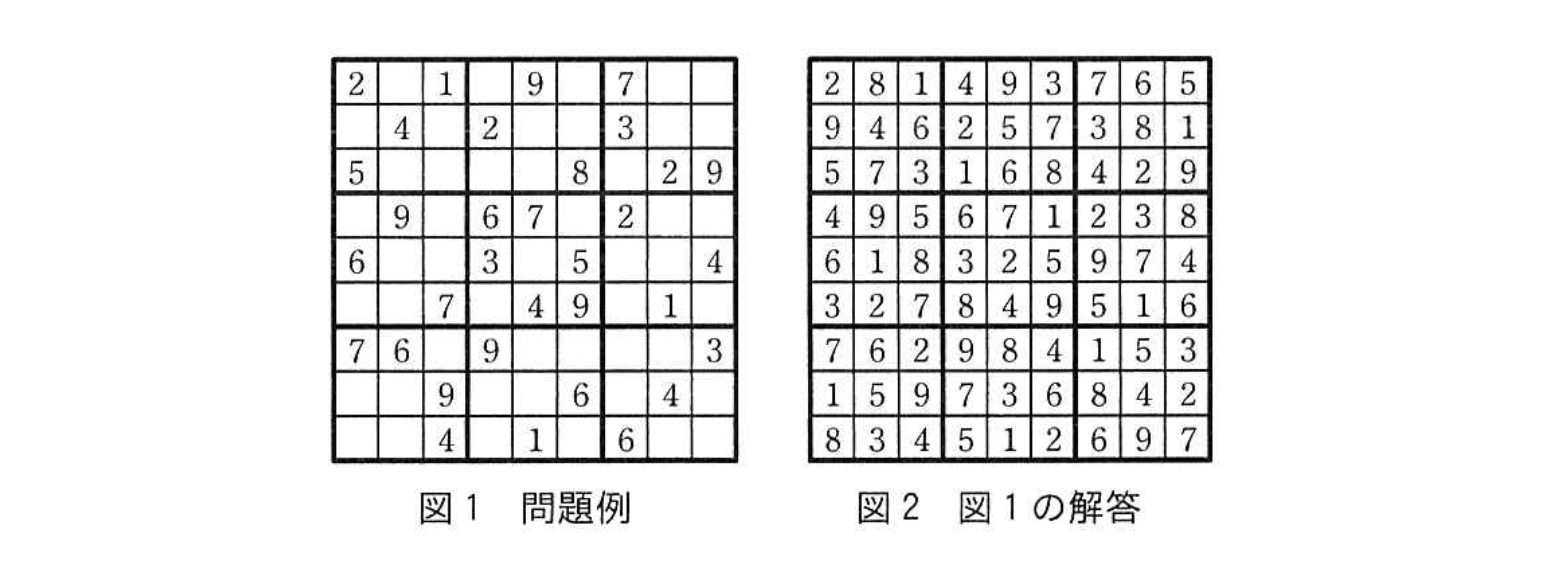
太線で 3×3 の枠に区切られた 9×9 のマスから成る正方形の盤面に、1~9 の数字を入れるパズルの解答を求めるプログラムを考える。このパズルは、図1に示すように幾つかのマスに数字が入れられている状態から、数字の入っていない各マスに、1~9 のうちのどれか一つの数字を入れていく。このとき、盤面の横1行、縦1列、及び太線で囲まれた 3×3 の枠内の全てにおいて、1~9 の数字が一つずつ入ることが、このパズルのルールである。パズルの問題例を図1に、図1の解答を図2に示す。
このパズルを解くための方針を次に示す。

この方針に沿ってパズルを解く手順を考える。
〔パズルを解く手順〕
(1) 盤面の左上端から探索を開始する。マスは左端から順に右方向に探索し、右端に達したら一行下がり、左端から順に探索する。
(2) 空白のマスを見つける。
(3) (2) で見つけた空白のマスに、1~9 の数字を順番に入れる。
(4) 数字を入れたときに、その状態がパズルのルールにのっとっているかどうかをチェックする。
(4-1) ルールにのっとっている場合は、(2)に進んで次の空白のマスを見つける。
(4-2) ルールにのっとっていない場合は、(3)に戻って次の数字を入れる。このとき、入れる数字がない場合には、マスを空白に戻して一つ前に数字を入れたマスに戻り、(3)から再開する。
(5) 最後のマスまで数字が入り、空白のマスがなくなったら、それが解答となる。
〔盤面の表現〕
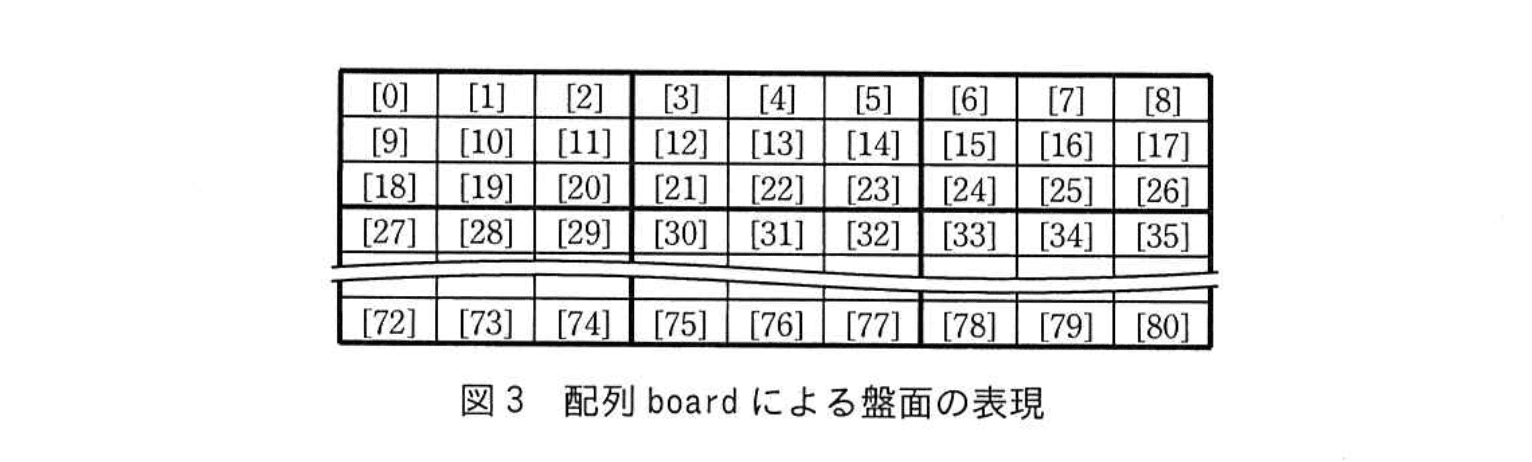
この手順をプログラムに実装するために、9×9 の盤面を次のデータ構造で表現することにした。
・9×9 の盤面を 81 個の要素をもつ 1 次元配列 board で表現する。添字は 0 から始まる。各要素にはマスに入れられた数字が格納され、空白の場合は 0 を格納する。
配列 board による盤面の表現を図3に示す。ここで括弧内の数字は配列 board の添字を表す。
〔ルールのチェック方法〕
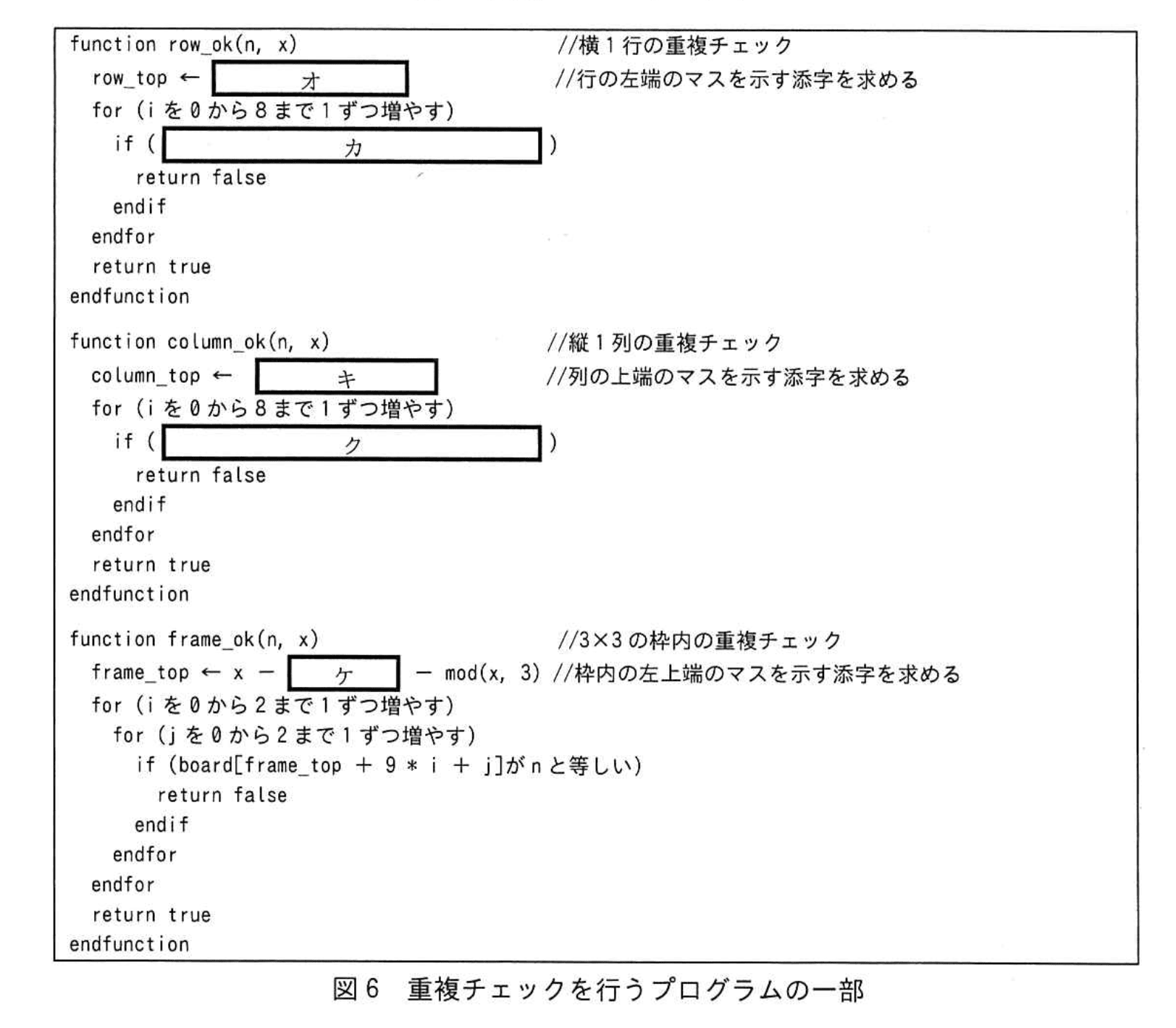
パズルのルールにのっとっているかどうかのチェックでは、数字を入れたマスが含まれる横 1 行の左端のマス、縦 1 列の上端のマス、3×3 の枠内の左上端のマスを特定し、行、列、枠内のマスに既に格納されている数字と、入れた数字がそれぞれ重複していないことを確認する。このチェックを“重複チェック”という。
〔解法のプログラム〕
プログラムで使用する配列、関数、変数及び定数の一部を表1に示す。なお、表1の配列及び変数は大域変数とする。
解法のプログラムのメインプログラムを図4に、関数 solve のプログラムを図5に、重複チェックを行うプログラムの一部を図6に示す。

〔プログラムの改善〕
解法のプログラムは深さ優先探索であり、探索の範囲が広くなるほど、再帰呼出しの回数が指数関数的に増加し、重複チェックの実行回数も増加する。
そこで、重複チェックの実行回数を少なくするために、各マスに入れることができる数字を保持するためのデータ構造 Z を考える。データ構造 Z は盤面のマスの数×9 の要素をもち、添字 i は 0 から、添字 n は 1 から始まる 2 次元配列とする。Z[i][n] は、ゲームのルールにのっとって board[x] に数字 n を入れることができる場合は要素に 1 を、できない場合は要素に 0 を格納する。データ構造 Z の初期化処理と更新処理を表2のように定義した。
なお、データ構造 Z は大域変数として導入する。

〔パズルを解く手順〕の (1) の前にデータ構造 Z の初期化処理を追加し、〔パズルを解く手順〕の (2)~(5) を次の (2)~(4) のように変更した。
(2) 空白のマスを見つける。
(3) データ構造 Z を参照し、(2) で見つけた空白のマスに入れることができる数字のリストを取得し、リストの数字を順番に入れる。
(3-1) 入れる数字がある場合、①処理A を行った後、マスに数字を入れる。その後、データ構造 Z の更新処理を行い、(2) に進んで次の空白のマスを見つける。
(3-2) 入れる数字がない場合、マスを空白に戻し、②処理Bを行った後、一つ前に数字を入れたマスに戻り、戻ったマスで取得したリストの次の数字から再開する。
(4) 最後のマスまで数字が入り、空白のマスがなくなったら、それが解答となる。
設問1:
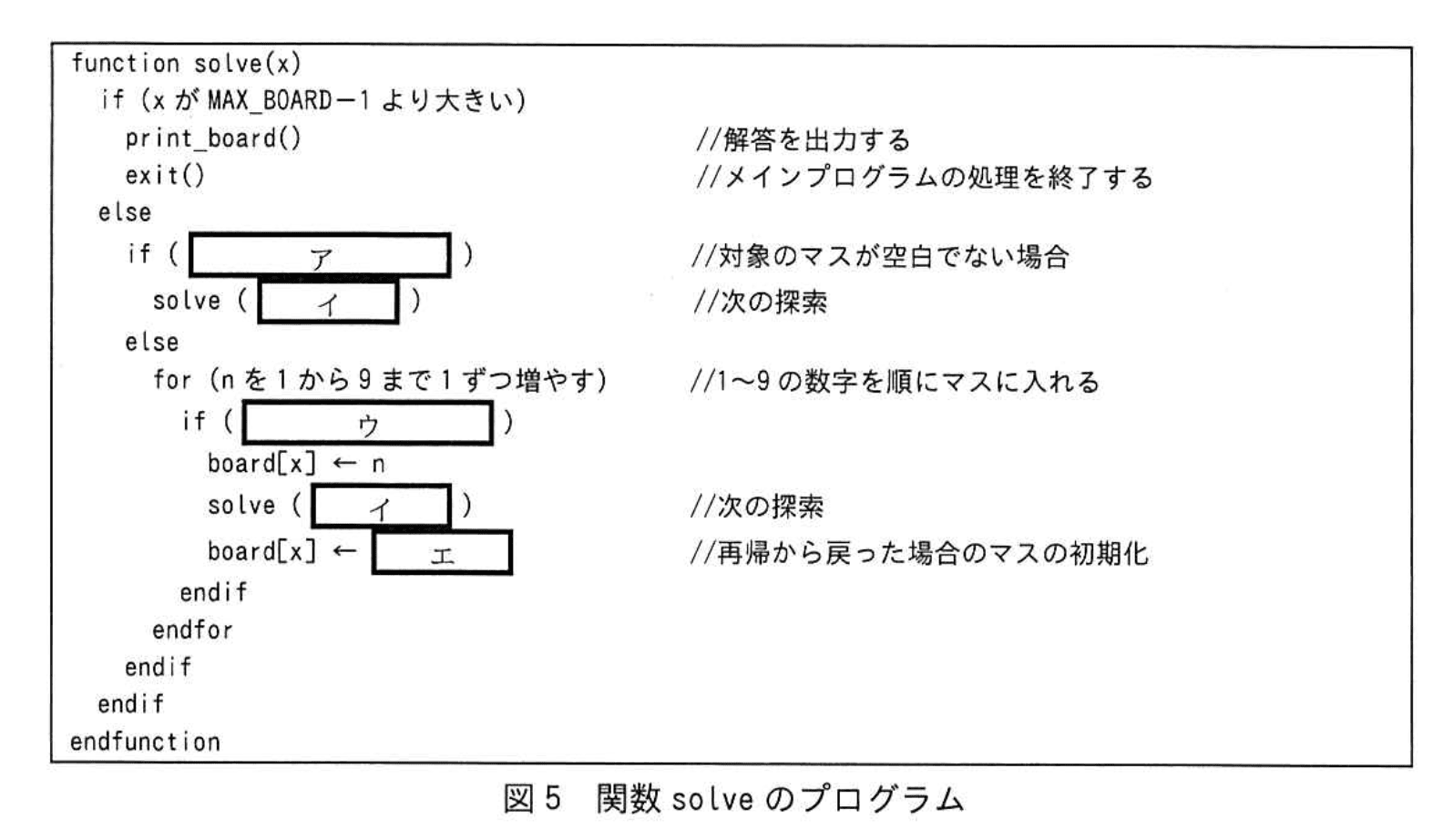
図5中のア~エに入れる適切な字句を答えよ。
模範解答
ア:board[x]が0でない
イ:x+1
ウ:check_ok(n, x)がtrueと等しい
エ:0
解説
解答の論理構成
-
[ア] の判断基準
- 盤面の配列について【問題文】には「各要素にはマスに入れられた数字が格納され、空白の場合は 0 を格納する。」とあります。
- したがって “対象のマスが空白でない” とは board[x] に 0 以外の値が入っている場合であり、条件式は「board[x]が0でない」となります。
-
[イ] の添字計算
- 探索順序は〔パズルを解く手順〕(1) にある通り「左端から順に右方向に探索し、右端に達したら一行下がり…」ですが、1次元配列で実装しているため右隣のマスはインデックスを1増やすだけで得られます。
- よって次に処理すべきマスは x+1 です。
-
[ウ] の成立条件
- 1~9 の数字を試す for ループの中では「数字を入れたときに、その状態がパズルのルールにのっとっているかどうかをチェックする。」とあり、チェック用関数は【表1】で示された check_ok(n, x) です。
- true が返れば「ルールにのっとっている」と解釈し再帰に進むため、判定式は「check_ok(n, x)がtrueと等しい」。
-
[エ] の巻き戻し処理
- 再帰から戻ったときには「マスを空白に戻して…」という 〔パズルを解く手順〕(4-2) の指示があります。空白は 0 で表現されるので board[x] ← 0 が必要です。
誤りやすいポイント
- 1 行 9 列を 1 次元配列で表す際、右端から次の行頭に移る計算(x + 1 ではなく (x+1) mod 9 など)と混同する。
- [ウ] で row_ok・column_ok・frame_ok を個別に呼び出してしまい、記述が長くなる。実際には check_ok(n, x) が包括している。
- 「空白に戻す」処理を忘れ、バックトラック時に盤面が汚れたままになる。
FAQ
Q: x+1 ではなく、行末処理を意識した複雑な式が必要では?
A: 盤面全体を solve が再帰で探索するため、行末・列末の切り替えは再帰のレベルで解決されます。したがって単純に x+1 で問題ありません。
A: 盤面全体を solve が再帰で探索するため、行末・列末の切り替えは再帰のレベルで解決されます。したがって単純に x+1 で問題ありません。
Q: check_ok が true になる確率を高める工夫はありますか?
A: 本問後半で紹介されるデータ構造 Z のように事前に候補数字を絞り込むことで、check_ok 呼び出し回数を削減できます。
A: 本問後半で紹介されるデータ構造 Z のように事前に候補数字を絞り込むことで、check_ok 呼び出し回数を削減できます。
Q: 0 を空白とする実装の利点は?
A: 配列を整数型で統一できるため追加フラグが不要です。また「0 はパズルの合法数字 1~9 とは重複しない」という性質を利用し、条件判定が簡潔になります。
A: 配列を整数型で統一できるため追加フラグが不要です。また「0 はパズルの合法数字 1~9 とは重複しない」という性質を利用し、条件判定が簡潔になります。
関連キーワード: バックトラック, 深さ優先探索, 再帰呼出し, ブール評価, 1次元配列
設問2:
図6中のオ~ケに入れる適切な字句を答えよ。
模範解答
オ:div(x, 9)9
カ:board[row_top+i]がnと等しい
キ:mod(x, 9)
ク:board[column_top+9i]がnと等しい
ケ:mod(div(x, 9)*9, 27)
解説
解答の論理構成
-
行の左端インデックス計算([オ])
- 盤面は「9×9 の盤面を 81 個の要素をもつ 1 次元配列 board で表現する。添字は 0 から始まる。」という仕様です。
- 1行は9マスなので、マス x が属する行の左端は
div(x, 9)(行番号)×9=div(x, 9)*9 となります。 - よって [オ] は原文どおり「div(x, 9)*9」です。
-
行内の重複判定式([カ])
- 行の左端 row_top から8回ループし、対象値 n と同じ数字があれば重複と判定します。
- したがって if 文の中身は
board[row_top+i]がnと等しい で決まり、模範解答では「board[row_top+i]がnと等しい」。
-
列の上端インデックス計算([キ])
- 列は 9 行にまたがるため、列番号は mod(x, 9) で求められます。
- よって [キ] は「mod(x, 9)」。
-
列内の重複判定式([ク])
- 列の上端 column_top から下方向へ9マスを調べます。
- 配列位置は column_top + 9i なので if 条件は
board[column_top+9i]がnと等しい となり、模範解答はこれをそのまま採用しています。
-
3×3 枠の左上端オフセット([ケ])
- 行方向については、行の左端 div(x, 9)*9 を3行区切り(27=3×9)で見た余りが、その行が枠内で何行目かを示します。
例:行 0~2 → 0, 9, 18、行 3~5 → 0, 9, 18 … - よって余り計算 mod(div(x, 9)*9, 27) を x から引けば、行方向で枠の最上段まで戻ることができます。
- 枠の左上端は「x − 行方向オフセット − 列方向オフセット (mod(x, 3))」なので、[ケ] に当たる行方向オフセットは
mod(div(x, 9)*9, 27) が最適です。
- 行方向については、行の左端 div(x, 9)*9 を3行区切り(27=3×9)で見た余りが、その行が枠内で何行目かを示します。
以上より模範解答の5語
- 「div(x, 9)*9」
- 「board[row_top+i]がnと等しい」
- 「mod(x, 9)」
- 「board[column_top+9*i]がnと等しい」
- 「mod(div(x, 9)*9, 27)」
がすべて論理的に導けます。
誤りやすいポイント
- 行頭を x - mod(x,9) としてしまい、列番号と混同する。
- 列上端を求める際に div(x,9) を使い、行と列を逆に認識するミス。
- 3×3 枠の計算で「27」を「9*9=81」と誤って設定し、枠の範囲が崩れる。
- if 条件の添字計算で i に 1 を足し忘れたり、引数 n と board の位置を逆に書く実装ミス。
FAQ
Q: div と単なる /(整数除算)を区別する必要がありますか?
A: はい。問題文に「div(n, m) は整数 n を整数 m で割った商を求める関数」と定義されているため、言語仕様に依存せず確実に整数商を得る意図があります。
A: はい。問題文に「div(n, m) は整数 n を整数 m で割った商を求める関数」と定義されているため、言語仕様に依存せず確実に整数商を得る意図があります。
Q: 3×3 枠のオフセットに 27 を使う理由は?
A: 1枠は行方向に3行×9列=27 要素連続で配置されているため、行インデックスを 27 で剰余演算すれば、同じ枠内での位置だけを抽出できます。
A: 1枠は行方向に3行×9列=27 要素連続で配置されているため、行インデックスを 27 で剰余演算すれば、同じ枠内での位置だけを抽出できます。
Q: 配列を1次元で扱う利点は何ですか?
A: 2次元配列よりメモリ管理が単純になり、インデックス計算も加算と乗算だけで済むため、処理系によっては高速化が期待できます。
A: 2次元配列よりメモリ管理が単純になり、インデックス計算も加算と乗算だけで済むため、処理系によっては高速化が期待できます。
関連キーワード: 深さ優先探索, バックトラッキング, インデックス計算, 剰余演算, 二重ループ
設問3:
〔プログラムの改善〕について、下線①の処理A及び下線②の処理Bの内容を、“データ構造Z”という字句を含めて、それぞれ20字以内で述べよ。
模範解答
処理A:データ構造Zを退避する
処理B:退避したデータ構造Zを取り出す
解説
解答の論理構成
- 問題文は、従来の深さ優先探索に対し「重複チェックの実行回数を少なくするために、各マスに入れることができる数字を保持するためのデータ構造 Z を考える」と述べています。この “データ構造 Z” は探索のたびに内容が書き換わります。
- 新しい手順の説明では
「(3-1) 入れる数字がある場合、①処理A を行った後、マスに数字を入れる。その後、データ構造 Z の更新処理を行い…」
「(3-2) 入れる数字がない場合、マスを空白に戻し、②処理B を行った後、一つ前に数字を入れたマスに戻り…」
と明記され、処理A は“数字を入れる前”、処理B は“数字を取り消した後”に呼ばれます。 - 数字を試すたびに “データ構造 Z の更新処理” が走るため、バックトラック時には更新前の Z を取り戻す必要があります。
- よって
・処理A=更新前の “データ構造 Z” をどこかに保存する(退避)
・処理B=保存していた “データ構造 Z” を元に戻す(復元)
が唯一破綻なく探索木をたどる方法です。 - 以上より模範解答どおり
「処理A:データ構造Zを退避する」
「処理B:退避したデータ構造Zを取り出す」
が導かれます。
誤りやすいポイント
- 処理A/処理Bを「board の退避・復元」と勘違いする。board は再帰から戻る直前に board[x] ← 0 としてリセットされるので別途保存は不要です。
- 「データ構造 Z の更新処理=処理A」と読み違える。処理A はあくまで更新“前”に呼び出される点に注意します。
- 「処理Bで再度更新処理を呼ぶ」と考える誤解。更新処理は数字を書き込むときだけ行うので、取り消し時は保存した Z を復元するだけで十分です。
FAQ
Q: 処理A はコピーではなく差分保存でも良いですか?
A: 問題文は具体的な実装方式を指定していませんが、探索木の復元性が保証できれば差分方式でも正解の趣旨を満たします。
A: 問題文は具体的な実装方式を指定していませんが、探索木の復元性が保証できれば差分方式でも正解の趣旨を満たします。
Q: board と Z の両方をスタックに積む実装は過剰ですか?
A: board は再帰から抜けると同時に自動的に元に戻るため、Z だけをスタックに積むほうが効率的です。
A: board は再帰から抜けると同時に自動的に元に戻るため、Z だけをスタックに積むほうが効率的です。
Q: データ構造 Z のサイズは 81×9 要素ですが、メモリ的に問題ありませんか?
A: 1 要素を 1 バイトで持てば約 729 バイトなので実用上問題ありません。探索効率向上のほうがメリットは大きいです。
A: 1 要素を 1 バイトで持てば約 729 バイトなので実用上問題ありません。探索効率向上のほうがメリットは大きいです。
関連キーワード: 深さ優先探索, バックトラック, 状態空間, スタック, 再帰
