応用情報技術者 2009年 秋期 午後 問02
文字列照合処理に関する次の記述を読んで、設問1~3に答えよ。
ある文字列(テキスト)中で特定の文字列(パターン)が最初に一致する位置を求めることを文字列照合という。そのための方法として、次の二つを考える。ここで、テキストとパターンの長さは、どちらも1文字以上とする。
〔方法1 単純な照合方法〕
テキストを先頭から1文字ずつパターンと比較して、不一致の文字が現れたら、比較するテキストの位置(比較位置)を1文字分進める。この方法による処理例を図1に示す。
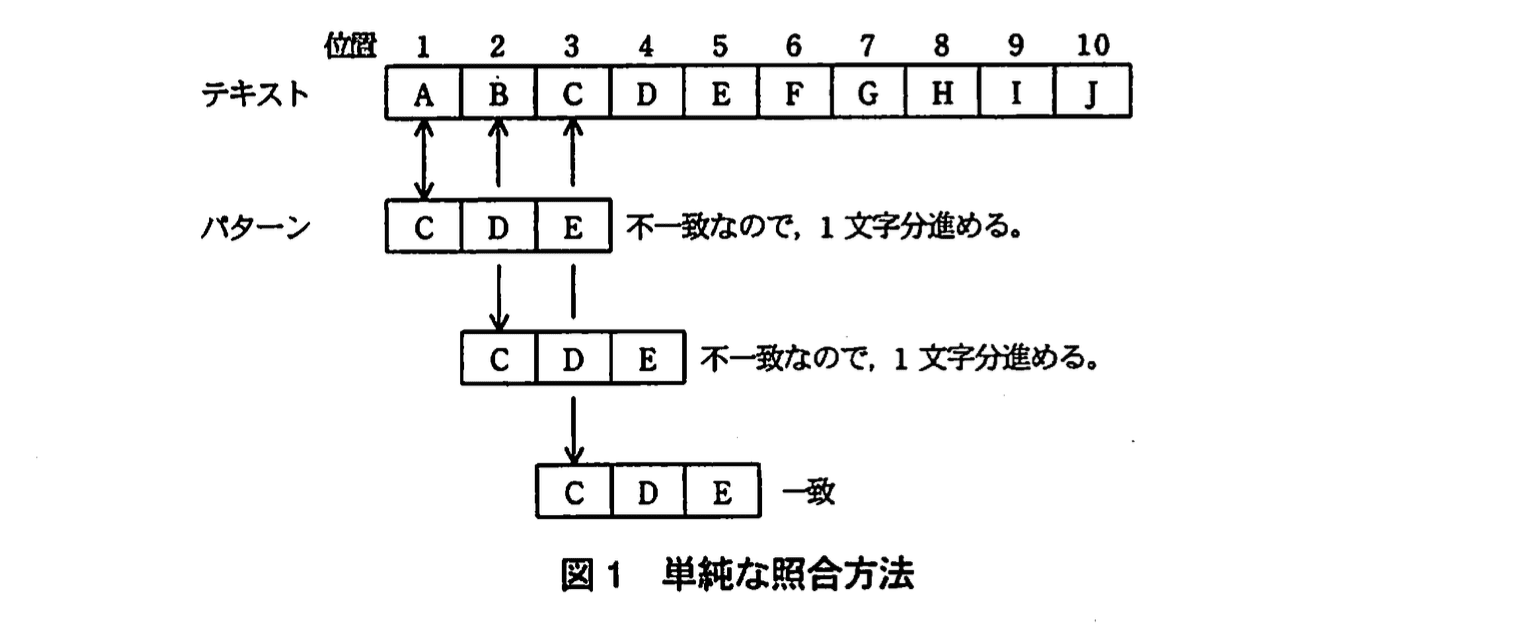
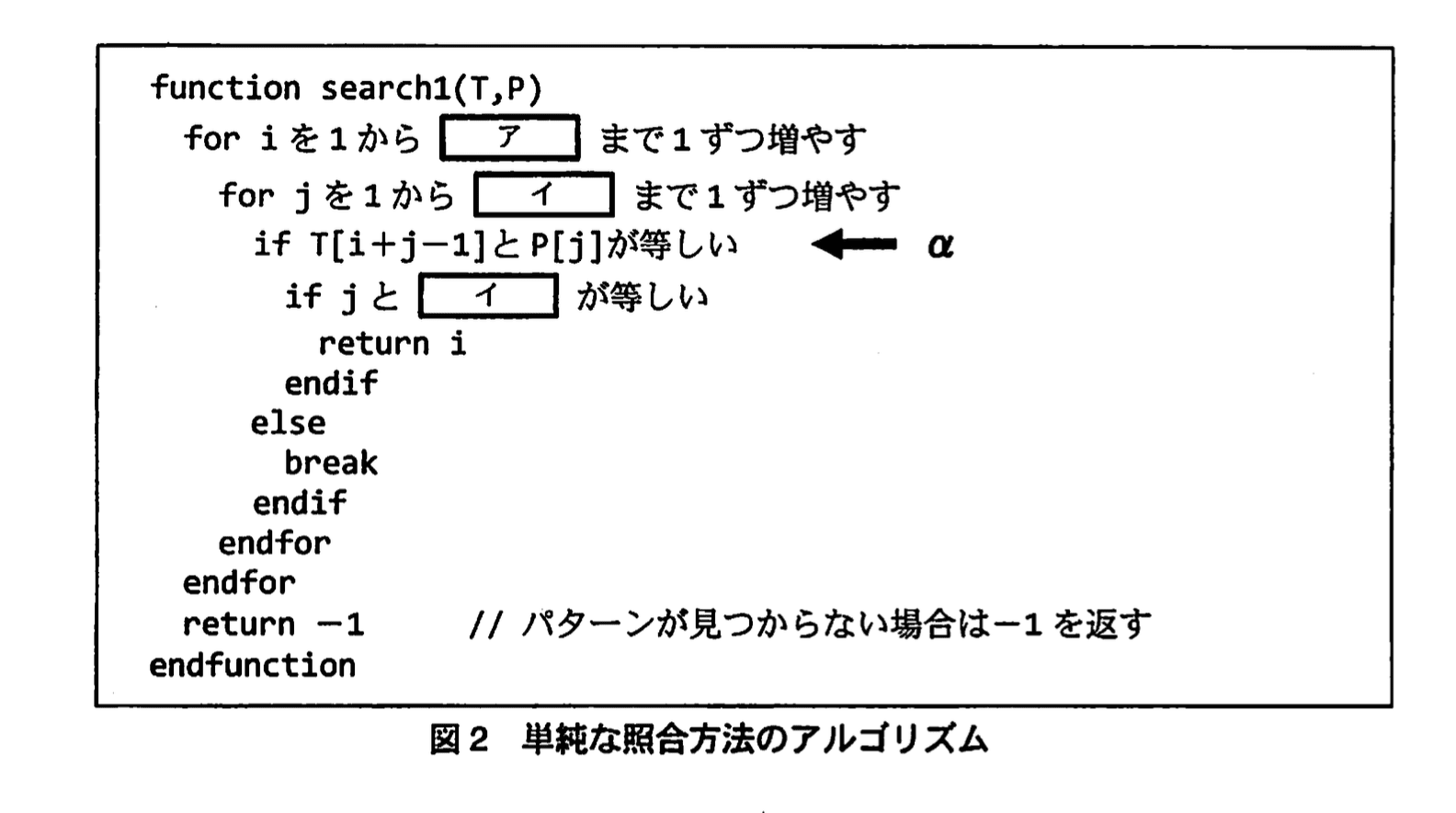
この手順を基に、テキストとパターンを与えると、最初に一致した文字位置を返すアルゴリズムを作成した。このアルゴリズムを図2に示す。
なお、テキストは配列T、パターンは配列Pに格納されており、T[n]及びP[n]はそれぞれのn番目の文字を、T.length及びP.lengthはそれぞれの長さを示す。
〔方法2 効率的な照合方法〕
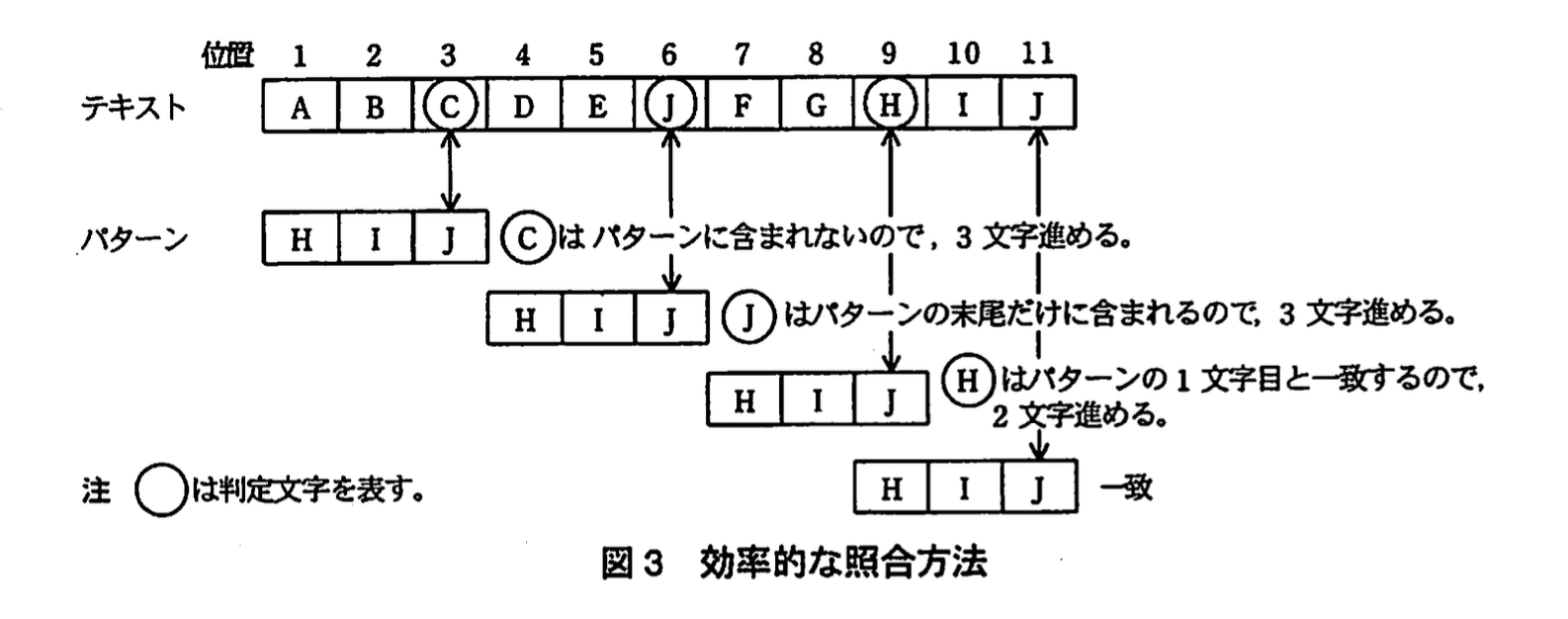
方法1では、パターンとテキストの文字が不一致となった場合、比較位置を1文字分進めている。ここでは、比較位置をなるべく多くの文字数分進めることで、照合における比較回数を減らすことを考える。
パターンの末尾に対応する位置にあるテキストの文字(判定文字)に着目すると、次のように比較位置を進める文字数(スキップ数)が決定できる。
(1) 判定文字がパターンに含まれていない場合は、判定文字とパターン内の文字の比較は常に不一致となるので、パターンの文字数分だけ比較位置を進める。また、判定文字がパターンの末尾だけに含まれている場合も、同様にパターンの文字数分だけ比較位置を進める。
(2) 判定文字がパターンの末尾以外に含まれている場合は、判定文字と一致するパターン内の文字が、テキストの判定文字に対応する位置に来るように比較位置を進める。ただし、パターン内に判定文字と一致する文字が複数ある場合は、パターンの末尾から最も近く(ただし、末尾を除く)にある判定文字と一致するパターン内の文字が、判定文字に対応する位置に来るように比較位置を進める。
この方法による処理例を図3に示す。
パターンが与えられると、判定文字に対応するスキップ数を一意に決定することができる。例えば、パターンHIJに対して判定文字とスキップ数の対応表を作成すると表1のようになる。

この考え方を基に作成したアルゴリズムを図4に示す。
なお、テキストは配列T、パターンは配列P、スキップ数を決める表の判定文字は配列C、スキップ数は配列Dに格納されており、T[n]、P[n]、C[n]、D[n]はそれぞれのn番目の文字又は数値を、T.length及びP.lengthはテキストとパターンの長さを示す。
このアルゴリズムは、三つの主要部分から成っている。一つ目は、与えられたパターンについて判定文字とスキップ数の対応表を作成する処理である。ここでは、配列Cに格納される空白文字は表1の“その他の文字”及びパターンの末尾の文字“J”を表現するために使用している。テキストとパターンは空白文字を含まないものとする。二つ目は、文字を比較する処理である。ここでは、現在の比較位置に対応したテキストとパターンを方法1と同様に1文字ずつ比較して、パターンに含まれる文字と対応するテキストの文字がすべて一致するか、不一致となる文字が見つかるまで繰り返す。三つ目は、判定文字とスキップ数の対応表を引いてスキップ数を決定する処理である。

設問1:
図2及び図4中のア~ウに入れる適切な字句を答えよ。
模範解答
ア:T.length - P.length+1
イ:P.length
ウ:P.length - j
解説
解答の論理構成
-
外側ループの上限[ア]
- 図2の外側 for は「for i を 1 から ア まで」とあります。
- 内側 for では「if T[i+j–1] と Pj が等しい」と比較しており、j は最大で[イ]。
- 「Tn 及び Pn はそれぞれのn番目の文字を」格納し、インデックスは 1 から始まる配列です。
- i+j-1 が T.length を超えると配列外参照になるため、i の最大値は
となります。よって
[ア]=T.length - P.length + 1
-
内側ループの上限[イ]
- 図2・図4ともに「for j を 1 から イ まで」とあり、すべてのパターン文字を順番に比較する仕様です。
- 比較対象はパターン全体なので上限は P.length 以外にあり得ません。
[イ]=P.length
-
スキップ数格納値[ウ]
- 図4の表作成部では「Dk ← ウ」とあります。
- 本方法は判定文字がパターン末尾に一致するときに “パターンの文字数分だけ” スキップするという規則を持ち、一般の場合は「パターンの末尾から最も近く…にある判定文字」と整列させるため、 スキップ数 = パターン長 − 判定文字の位置(j)
- 位置は 1 から数えているので
よって
[ウ]=P.length - j
-
まとめ
- [ア]T.length - P.length + 1
- [イ]P.length
- [ウ]P.length - j
誤りやすいポイント
- “+1” を忘れて T.length - P.length としてしまう
- 0 始まりの添字と 1 始まりを混同し、境界条件をずらす
- スキップ数を j - 1 や P.length - j + 1 と誤算しがち
- 表作成段階で「末尾文字は常にパターン長」を理解せず、すべて同じ数にしてしまう
FAQ
Q: P.length - j ではなく P.length - j + 1 では?
A: 位置が 1 から始まるため、末尾文字(j = P.length)のときはスキップ数 0 ではなく「パターンの文字数分」=P.length が必要です。表作成ループは P.length−1 までなので、このずれは発生しません。
A: 位置が 1 から始まるため、末尾文字(j = P.length)のときはスキップ数 0 ではなく「パターンの文字数分」=P.length が必要です。表作成ループは P.length−1 までなので、このずれは発生しません。
Q: 図2と図4で[ア]と[イ]が同じになる理由は?
A: どちらも「方法1の手順を基に」比較を行う部分を共通で使っており、境界条件が一致するためです。
A: どちらも「方法1の手順を基に」比較を行う部分を共通で使っており、境界条件が一致するためです。
Q: 空白文字 " " を使うのはなぜ?
A: 「配列Cに格納される空白文字は…“その他の文字”及びパターンの末尾の文字“J”を表現」と問題文にある通り、未登録文字と末尾文字を区別するためのダミーとして用いています。
A: 「配列Cに格納される空白文字は…“その他の文字”及びパターンの末尾の文字“J”を表現」と問題文にある通り、未登録文字と末尾文字を区別するためのダミーとして用いています。
関連キーワード: 文字列照合、線形探索、配列インデックス、スキップテーブル
設問2:
パターンHIPOPOTAMUSに対するスキップ数を表2に示す。エ、オに入れる適切な数値を答えよ。

模範解答
エ:10
オ:6
解説
解答の論理構成
-
ルールの確認
- 【問題文】には、スキップ数決定規則として
「(1) 判定文字がパターンに含まれていない場合は…パターンの文字数分だけ比較位置を進める。また、判定文字がパターンの末尾だけに含まれている場合も、同様にパターンの文字数分だけ比較位置を進める。」
「(2) 判定文字がパターンの末尾以外に含まれている場合は…パターンの末尾から最も近く(ただし、末尾を除く)にある判定文字…が、判定文字に対応する位置に来るように比較位置を進める。」
と記載されています。 - さらに、例として「表1 パターンHIJに対するスキップ数」で
H→2, I→1, J→3, その他→3
が提示され、 という計算式が暗示されています。
- 【問題文】には、スキップ数決定規則として
-
パターン “HIPOPOTAMUS” の各文字出現位置1:H 2:I 3:P 4:O 5:P 6:O 7:T 8:A 9:M 10:U 11:S(末尾)
- 長さは 11。
-
スキップ数の算出
① H は先頭 (位置1) にのみ出現 → 規則(2)より
② I は位置2のみ → (表2に既掲)
③ P は位置3と5に存在。末尾から最も近いのは位置5 →
④ O は位置4と6 →
⑤ T は位置7のみ →
⑥ A は位置8 →
⑦ M は位置9 →
⑧ U は位置10 →
⑨ S は末尾 (位置11) のみ → 規則(1)より 11
⑩ “その他の文字” はパターンに含まれない → 規則(1)より 11 -
表2への反映
- H の欄 エ = 10
- P の欄 オ = 6
誤りやすいポイント
- 末尾文字 “S” は規則(1)に該当し、「11」を入れ忘れやすいです。
- 重複文字 “P”“O” は「末尾から最も近い位置」を採用します。先頭側の位置で計算すると誤答になります。
- パターン長さが基準なので、 を取り違えると全てのスキップ数がずれます。
FAQ
Q: 重複している文字が3回以上出る場合はどう数えますか?
A: 末尾から数えて最初に現れる位置(ただし末尾そのものは除く)を使います。規則(2)がそのまま適用できます。
A: 末尾から数えて最初に現れる位置(ただし末尾そのものは除く)を使います。規則(2)がそのまま適用できます。
Q: “その他の文字” は毎回パターン長さになりますか?
A: はい。【問題文】の「判定文字がパターンに含まれていない場合は…パターンの文字数分だけ比較位置を進める。」に該当します。
A: はい。【問題文】の「判定文字がパターンに含まれていない場合は…パターンの文字数分だけ比較位置を進める。」に該当します。
Q: スキップ表を先に作る利点は何ですか?
A: 判定文字が現れた瞬間にテーブル参照だけでスキップ量が得られ、比較回数を大幅に削減できます。
A: 判定文字が現れた瞬間にテーブル参照だけでスキップ量が得られ、比較回数を大幅に削減できます。
関連キーワード: 文字列照合、ボイヤー–ムーア法、スキップテーブル、パターンマッチング、アルゴリズム最適化
設問3:
次のテキストとパターンに対して、図2でのαと図4でのβの実行回数をそれぞれ答えよ。
テキスト:PICKLED_PEPPER
パターン:PEP
模範解答
α:12
β:8
解説
解答の論理構成
- アルゴリズムの比較対象
- 単純法では図2の if T[i+j–1] と Pj が等しい が α の比較ポイントです。
- 効率化法では図4の if T[i + j − 1] と Pj が等しい が β の比較ポイントです。
- 前提データ
- テキストは【問題文】引用「テキスト:PICKLED_PEPPER」(長さ14)。
- パターンは同「パターン:PEP」(長さ3)。
- 開始位置は から まで。
- α の実行回数
- 位置 9 で return i に到達するため以降の比較は行われません。
- よって α=12。
- β の実行回数
- スキップ表作成(図4 “(1): 表の作成”)
- P→2、E→1、空白→3 と決定。
- 照合過程(図4 “(2): 文字の比較”)
- 位置 9 で一致し return i。
- よって β=8。
- スキップ表作成(図4 “(1): 表の作成”)
誤りやすいポイント
- break 実行後も j ループが続くと誤解し、比較回数を加算しすぎる。
- return i で外側の i ループが終了する点を見落とす。
- スキップ表で空白エントリが「その他の文字」かつ「パターン末尾」を兼ねることを忘れ、d の値を間違える。
- テキスト長を「PICKLED_PEPPER」が 文字と思い込み(実際は )、開始位置の範囲を誤る。
FAQ
Q: α と β の差が 4 回なのはなぜですか?
A: 効率化法は「判定文字」に基づき 3・1 など複数文字を一気にスキップできるため、無意味な比較を 4 回省けた結果です。
A: 効率化法は「判定文字」に基づき 3・1 など複数文字を一気にスキップできるため、無意味な比較を 4 回省けた結果です。
Q: スキップ数 Dk はどう計算しますか?
A: 図4の ウ は P.length − j です。パターン末尾から見た距離を登録します。
A: 図4の ウ は P.length − j です。パターン末尾から見た距離を登録します。
Q: パターンに同じ文字が複数ある場合は?
A: 図4の内側ループで “末尾から最も近い文字” だけを最初に登録し、以降の同文字は無視されるため、常に最大スキップが得られます。
A: 図4の内側ループで “末尾から最も近い文字” だけを最初に登録し、以降の同文字は無視されるため、常に最大スキップが得られます。
関連キーワード: 文字列照合、ナイーブ法、スキップ表、比較回数
