応用情報技術者 2009年 春期 午後 問02
探索アルゴリズムであるハッシュ法の一つ、チェイン法に関する次の記述を読んで、設問1~4に答えよ。
配列に対して、データを格納すべき位置(配列の添字)をデータのキーの値を引数とする関数(ハッシュ関数)で求めることによって、探索だけでなく追加や削除も効率よく行うのがハッシュ法である。
通常、キーのとり得る値の数に比べて、配列の添字として使える値の範囲は狭いので、衝突(collision)と呼ばれる現象が起こり得る。衝突が発生した場合の対処方法の一つとして、同一のハッシュ値をもつデータを線形リストによって管理するチェイン法(連鎖法ともいう)がある。
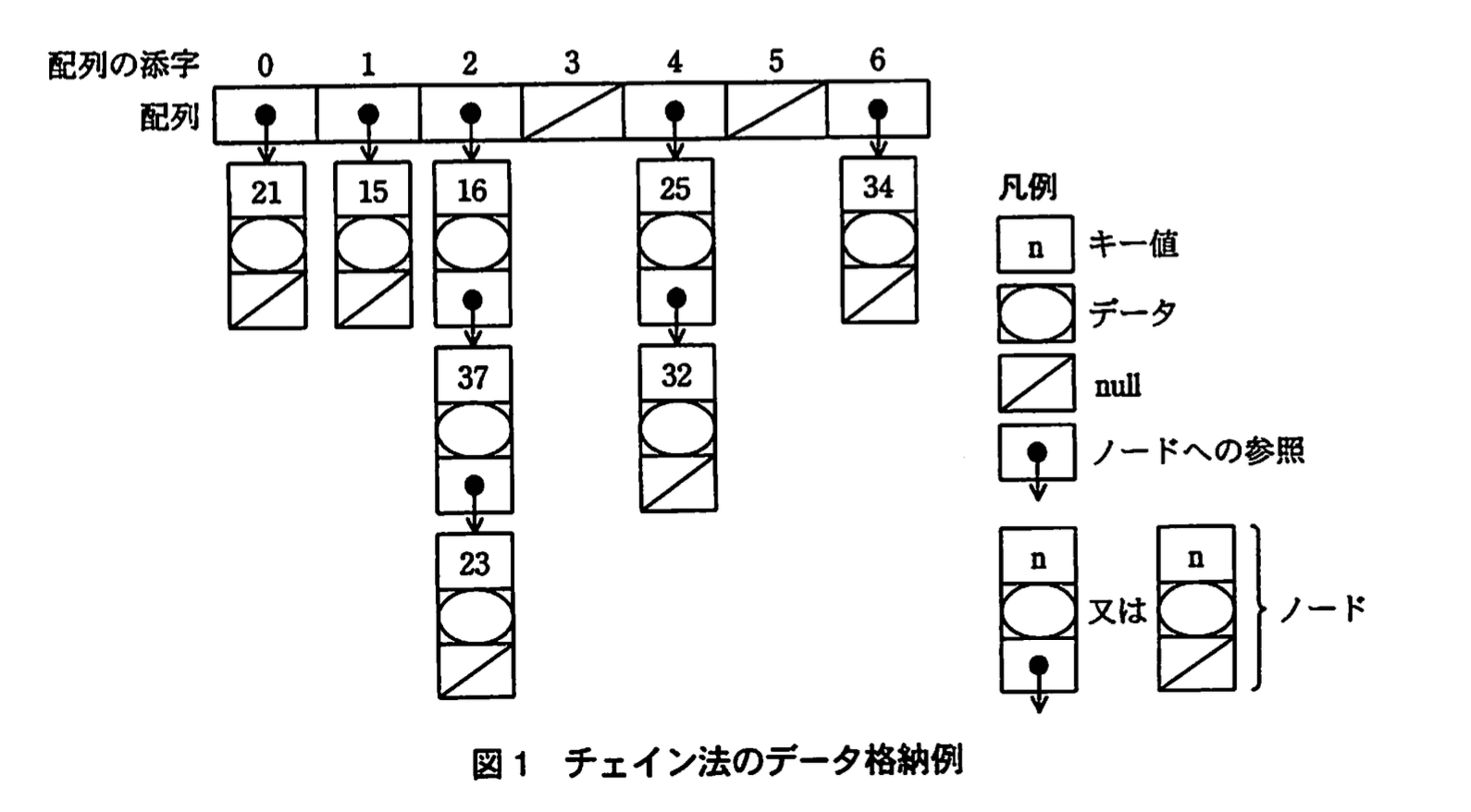
8個のデータを格納したときの例を図1に示す。
このとき、キー値は正の整数、配列の添字は0~6の整数、ハッシュ関数は引数を7で割った剰余を求める関数とする。
 このチェイン法を実現するために、表に示す構造体、配列及び関数を使用する。
このチェイン法を実現するために、表に示す構造体、配列及び関数を使用する。
このチェイン法を実現するために、表に示す構造体、配列及び関数を使用する。
構造体を参照する変数からその構造体の構成要素へのアクセスには “.” を用いる。
例えば、図1のキー値25のデータは table[4].data でアクセスできる。また、構造体の実体を生成するには、次のように書き、生成された構造体への参照が値になる。
new Node(key, data, nextNode)
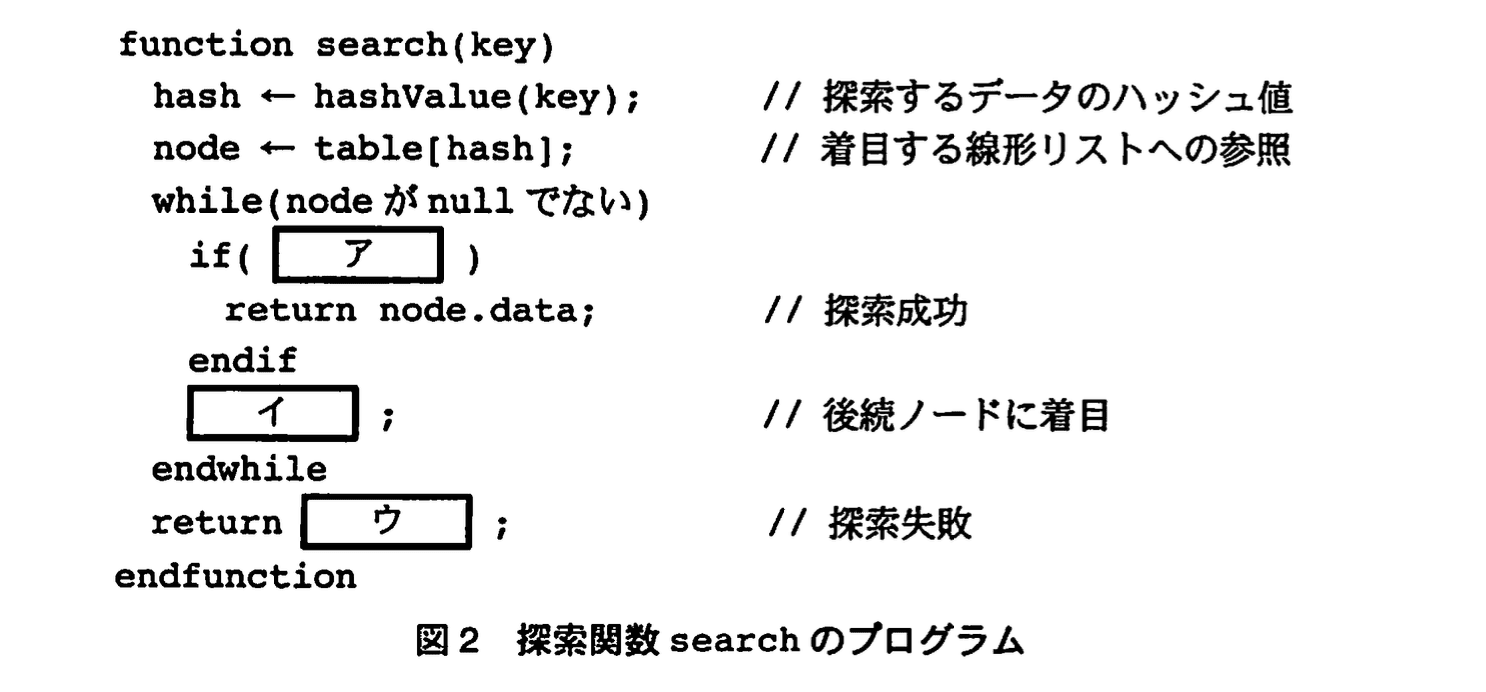
〔探索関数search〕
探索のアルゴリズムを実装した関数 search の処理手順を次の(1)〜(3)に、そのプログラムを図2に示す。
(1) 探索したいデータのキー値からハッシュ値を求める。
(2) ハッシュ表中のハッシュ値を添字とする要素が参照する線形リストへ着目する。
(3) 線形リストのノードに先頭から順にアクセスする。キー値と同じ値が見つかれば、そのノードに格納されたデータを返す。末尾まで探して見つからなければ null を返す。
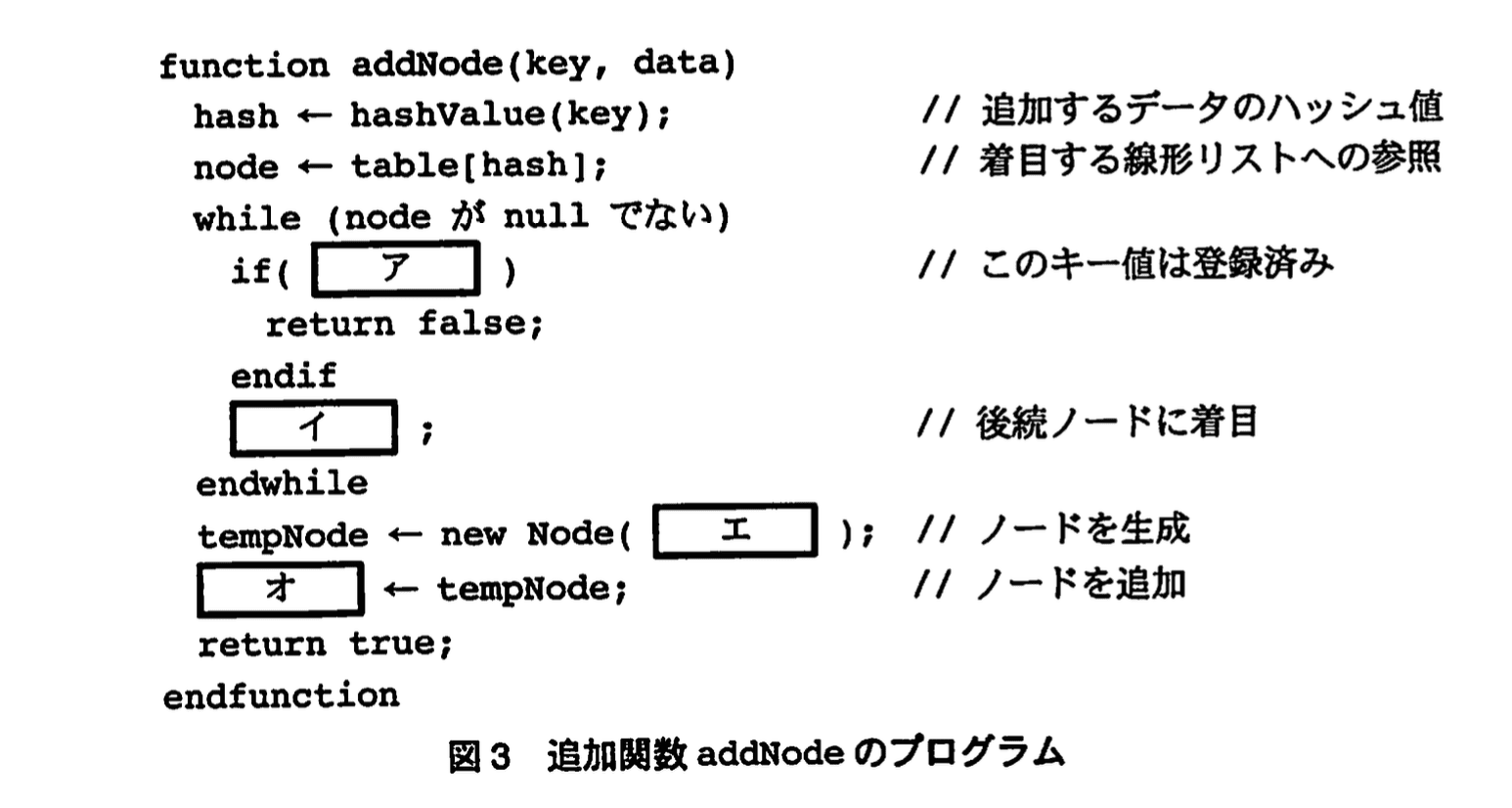
〔追加関数addNode〕
データの追加手続きを実装した関数 addNode の処理手順を次の(1)~(3)に、プログラムを図3に示す。図3中のア、イには、図2中のア、イと同一のものが入る。
(1) 追加したいデータのキー値からハッシュ値を求める。
(2) ハッシュ表中のハッシュ値を添字とする要素が参照する線形リストに着目する。
(3) 線形リストのノードに先頭から順にアクセスする。キー値と同じ値が見つかれば、キー値は登録済みであり追加失敗として false を返す。末尾まで探して見つからなければ、リストの先頭にノードを追加して true を返す。
〔チェイン法の計算量〕
チェイン法の計算量を考える。
計算量が最悪になるのは、カの場合である。しかし、ハッシュ関数の作り方が悪くなければ、このようなことになる確率は小さく、実際上は無視できる。
チェイン法では、データの個数をnとし、表の大きさ(配列の長さ)をmとすると、線形リスト上の探索の際にアクセスするノードの数は、線形リストの長さの平均n/mに比例する。mの選び方は任意なので、nに対して十分に大きくとっておけば、計算量がキとなる。この場合の計算量は 2 分探索木による O(log n) より小さい。
設問1:
衝突(collision)とはどのような現象か。“キー”と“ハッシュ関数”という単語を用いて、35字以内で述べよ。
模範解答
違うキーの値でも、ハッシュ関数を適用した結果が同じ値になること
解説
解答の論理構成
- 問題文は「配列の添字として使える値の範囲は狭いので、衝突(collision)と呼ばれる現象が起こり得る。」と述べています。
- また、「同一のハッシュ値をもつデータを線形リストによって管理するチェイン法」とあり、衝突とは“同一のハッシュ値”が複数データに発生する状況を指しています。
- したがって「違うキーの値」に「ハッシュ関数」を適用した結果が「同じハッシュ値」になる現象をまとめれば、模範解答の「違うキーの値でも、ハッシュ関数を適用した結果が同じ値になること」となります。
誤りやすいポイント
- 「同じ配列要素に格納されること」だけを説明し、ハッシュ関数との因果を省略してしまう。
- 「キーが重複する」と誤記し、異なるキーでも起こる点を落とす。
- 衝突=エラーと捉え、回避策(チェイン法など)と混同する。
FAQ
Q: 衝突が起こる理由は配列サイズが小さいからだけですか?
A: 主因は「キーのとり得る値の数」が「配列の添字範囲」より多い点ですが、ハッシュ関数の設計が偏っている場合も衝突は増えます。
A: 主因は「キーのとり得る値の数」が「配列の添字範囲」より多い点ですが、ハッシュ関数の設計が偏っている場合も衝突は増えます。
Q: 衝突が発生すると必ず処理速度は落ちますか?
A: チェイン法では平均リスト長が に抑えられるため、適切に を取れば計算量は 近くを維持できます。
A: チェイン法では平均リスト長が に抑えられるため、適切に を取れば計算量は 近くを維持できます。
Q: 衝突を完全に防ぐ方法はありますか?
A: 理論上はキー空間と同サイズの配列へ完全ハッシュを行えば可能ですが、実務ではコストが高いため確率的に衝突を低減する設計が一般的です。
A: 理論上はキー空間と同サイズの配列へ完全ハッシュを行えば可能ですが、実務ではコストが高いため確率的に衝突を低減する設計が一般的です。
関連キーワード: ハッシュ関数, ハッシュ表, 衝突, チェイン法, 計算量
設問2:〔探索関数search〕について、(1)、(2)に答えよ。
(1)図1の場合、キー値が23のデータを探索するために、ノードにアクセスする順序はどのようになるか。“key1→key2→・・・→23”のように、アクセスしたノードのキー値の順序で答えよ。
模範解答
16 → 37 → 23
解説
解答の論理構成
- ハッシュ値の決定
- 【問題文】に「ハッシュ関数は引数を7で割った剰余を求める関数とする。」とある。
- キー値が「23」の場合、 なのでハッシュ値は「2」です。
- 着目する線形リスト
- 同じく【問題文】で「配列の添字は0~6の整数」と示されている。よって table[2] が指す線形リストを参照します。
- 線形リストの走査順
- 〔探索関数search〕の手順(3)では「線形リストのノードに先頭から順にアクセスする。」とあります。
- 図1の table[2] 先頭ノードのキー値は「16」、次が「37」、最後が「23」です。
- キー一致の判定
- 手順(3)の続きで「キー値と同じ値が見つかれば、そのノードに格納されたデータを返す。」とあります。
- 先頭「16」は不一致→次ノード「37」も不一致→三番目「23」で一致し探索終了。
- 以上よりアクセス順は “16 → 37 → 23” となります。
誤りやすいポイント
- 23÷7 を切り捨て商と勘違いし「3」を添字にしてしまう。
- 図1のリストが「後ろから追加された」と誤解し、探索時の順序を逆に書く。
- table[2] に到達した段階で「23 は衝突しているからすぐ見つかる」と思い込み、途中ノードの「16」「37」を省略してしまう。
FAQ
Q: 衝突が起きると必ず線形リストが長くなりますか?
A: はい。同一ハッシュ値に複数のキーが割り当てられた場合、その箇所は線形リストとなり長さが 2 以上になります。
A: はい。同一ハッシュ値に複数のキーが割り当てられた場合、その箇所は線形リストとなり長さが 2 以上になります。
Q: 追加時にリストの先頭へ挿入する理由は何ですか?
A: 追加関数addNodeは探索後、先頭にノードを挿入すれば で済むためです。末尾挿入だとリストを最後までたどる必要がありコストが増えます。
A: 追加関数addNodeは探索後、先頭にノードを挿入すれば で済むためです。末尾挿入だとリストを最後までたどる必要がありコストが増えます。
Q: m を大きく取ると計算量はどうなりますか?
A: 【問題文】に「計算量がキとなる」とあるように、 の設計では平均アクセス数が定数に近づき が期待できます。
A: 【問題文】に「計算量がキとなる」とあるように、 の設計では平均アクセス数が定数に近づき が期待できます。
関連キーワード: ハッシュ関数, チェイン法, 衝突, 線形リスト
設問2:〔探索関数search〕について、(1)、(2)に答えよ。
(2)図2中のア~ウに入れる適切な字句を答えよ。
模範解答
ア:node.keyがkeyと等しい
イ:node←node.nextNode
ウ:null
解説
解答の論理構成
-
アルゴリズムの目的
【問題文】の「(3) 線形リストのノードに先頭から順にアクセスする。キー値と同じ値が見つかれば、そのノードに格納されたデータを返す。」とあります。よってノードを1件ずつ調べ、現在着目しているノードのキーと探索キーが一致するか判定する必要があります。
⇒ [ア] は node.key が key と等しいかどうかの比較式になります。 -
リストを順にたどる処理
同じ段落に「末尾まで探して見つからなければ」とあるため、条件判定のあとに次ノードへ参照を進める処理が要ります。
⇒ [イ] は node ← node.nextNode で、後続ノードへ着目を移す文になります。 -
探索失敗時の戻り値
見つからない場合は「null を返す」と明示されています。
⇒ [ウ] は null です。
以上から
[ア] node.keyがkeyと等しい
[イ] node←node.nextNode
[ウ] null
[ア] node.keyがkeyと等しい
[イ] node←node.nextNode
[ウ] null
が導かれます。
誤りやすいポイント
- 「node.data が key と等しい」と誤って data フィールドで比較してしまう。キー検索なので比較対象は key です。
- node = node.nextNode と代入演算子を = のみで書くミス。擬似言語中では代入を ← で表すため、演算子の違いで失点しやすいです。
- 探索失敗時に 0 や -1 を返すと勘違いするケース。問題文に「null を返す」と明示されています。
FAQ
Q: 探索関数で先頭から調べるのは効率が悪くありませんか?
A: チェイン法での線形リストは平均長が と短い想定です。ハッシュが適切ならば平均計算量は となるため先頭探索でも十分高速です。
A: チェイン法での線形リストは平均長が と短い想定です。ハッシュが適切ならば平均計算量は となるため先頭探索でも十分高速です。
Q: 追加関数でも [ア] と [イ] が同じになる理由は?
A: 追加時も「既にキーが存在するか」を確認するため、探索と同じ比較式と次ノードへの移動処理を再利用しています。
A: 追加時も「既にキーが存在するか」を確認するため、探索と同じ比較式と次ノードへの移動処理を再利用しています。
Q: null と 0 の違いは?
A: null は「何も参照していない」という参照型の特別な値、0 は整数リテラルです。ハッシュ表が「ノードへの参照」を格納しているので、存在しないことを示すのは null になります。
A: null は「何も参照していない」という参照型の特別な値、0 は整数リテラルです。ハッシュ表が「ノードへの参照」を格納しているので、存在しないことを示すのは null になります。
関連キーワード: ハッシュ関数, 衝突処理, チェイン法, 計算量, 線形リスト
設問3:
〔追加関数addNode〕のプログラム、図3中のエ、オに入れる適切な字句を答えよ。
模範解答
カ:key, data, table[hash]
キ:table[hash]
解説
解答の論理構成
-
生成するノードの形
【問題文】には
「構造体の実体を生成するには、次のように書き…
new Node(key, data, nextNode)」
とあります。Node コンストラクタの 3 つめの引数には “後続ノードへの参照” を渡す仕様です。 -
追加する位置
追加手順(3)では
「末尾まで探して見つからなければ、リストの先頭にノードを追加して true を返す。」
と指示されています。リストの先頭とはハッシュ表 table の該当要素 table[hash] です。したがって
• 生成時 nextNode には “現在の先頭ノード” である table[hash] を渡す
• 生成後は “新しい先頭ノード” として table[hash] に代入する
という 2 段階になります。 -
字句の決定
以上より
• エ には “key, data, table[hash]”
• オ には “table[hash]”
をそのまま記述するのが唯一妥当です。
誤りやすいポイント
- nextNode に null を渡してしまいリストが途中で途切れる
- tempNode 生成後に node.nextNode ← tempNode のように末尾へ追加してしまい、処理手順(3)と食い違う
- ハッシュ表の添字を書き間違え table[hash] を table[ key ] と記述してしまう
FAQ
Q: 末尾に追加では駄目なのですか?
A: 処理手順(3)で「リストの先頭にノードを追加」と明示されています。先頭追加はポインタ操作が一定で計算量も になる利点があります。
A: 処理手順(3)で「リストの先頭にノードを追加」と明示されています。先頭追加はポインタ操作が一定で計算量も になる利点があります。
Q: key, data, table[hash] の順序は固定ですか?
A: はい。【問題文】の new Node(key, data, nextNode) という定義順序を変えることはできません。
A: はい。【問題文】の new Node(key, data, nextNode) という定義順序を変えることはできません。
Q: 探索と同じ ア, イ を再利用する理由は?
A: addNode もリストを走査するため、条件判定(キー一致)と次ノードへの移動処理は search と同一になります。
A: addNode もリストを走査するため、条件判定(キー一致)と次ノードへの移動処理は search と同一になります。
関連キーワード: ハッシュ表, チェイン法, 線形リスト, 計算量
設問4:〔チェイン法の計算量〕について、(1)、(2)に答えよ。
(1)カに入れる適切な字句を25字以内で答えよ。
模範解答
カ:すべてのキーについてハッシュ値が同じになる
解説
解答の論理構成
- 問題文には「計算量が最悪になるのは、カの場合である。」とあり、チェイン法の計算量が劣化する具体的な状況を説明する空所が設けられています。
- チェイン法では、同一ハッシュ値を持つデータが同じ線形リストに連結される仕組みです。配列(ハッシュ表)要素ごとにリスト長の平均は ですが、ある要素にデータが極端に集中すると探索はリストの先頭から末尾まで線形にたどる必要があります。
- 最も極端な集中は「すべてのキーが同じハッシュ値を返す」状態です。配列 0~6 のいずれか 1 か所に全データが鎮座し、他の添字はすべて null となるため、探索・挿入・削除いずれも に落ち込みます。
- この状況を自然言語で 25 字以内にまとめると「すべてのキーについてハッシュ値が同じになる」となります。
誤りやすいポイント
- 「衝突が多発する場合」とだけ記述すると“どの程度の多発か”が曖昧で減点対象になりやすいです。空所は“最悪”を強調しているため、すべてのキーが同一ハッシュ値を取るケースまで踏み込む必要があります。
- 「ハッシュ関数が悪い場合」と誤って書く受験生がいますが、最悪ケースはハッシュ関数そのものの設計不良 だけ と限らず、入力データの偏りでも起こるため、主語をキー側に置く表現が安全です。
- 「配列長 が 1 のとき」と書いてしまうミスも散見されますが、問題文はハッシュ表の大きさを固定した上で“集中”を問うているので適切ではありません。
FAQ
Q: すべてのキーが異なるのにハッシュ値が同じになることは現実に起こりますか?
A: はい。ハッシュ関数が粗雑、または入力キーが特定の数列に偏ると同一ハッシュ値へ写像される可能性があります。これを避けるにはハッシュ関数の設計改善か、配列表サイズを素数にするなどの対策が有効です。
A: はい。ハッシュ関数が粗雑、または入力キーが特定の数列に偏ると同一ハッシュ値へ写像される可能性があります。これを避けるにはハッシュ関数の設計改善か、配列表サイズを素数にするなどの対策が有効です。
Q: ハッシュ衝突が発生しても平均計算量 と説明されるのはなぜですか?
A: 入力がランダムと仮定し、ハッシュ値が一様に分布すると期待される場合、各バケットの平均リスト長が で一定に抑えられるため、探索・挿入・削除の期待計算量は になります。
A: 入力がランダムと仮定し、ハッシュ値が一様に分布すると期待される場合、各バケットの平均リスト長が で一定に抑えられるため、探索・挿入・削除の期待計算量は になります。
Q: チェイン法以外で衝突を解決する代表的手法は?
A: オープンアドレス法(線形・二次・二重ハッシュ probing など)が代表例です。配列内で空きを探して格納し、リストを使わない点がチェイン法と異なります。
A: オープンアドレス法(線形・二次・二重ハッシュ probing など)が代表例です。配列内で空きを探して格納し、リストを使わない点がチェイン法と異なります。
関連キーワード: チェイン法, ハッシュ衝突, 計算量解析, バケット, 期待計算量
設問4:〔チェイン法の計算量〕について、(1)、(2)に答えよ。
(2)キに入れる計算量をO記法で答えよ。
模範解答
キ:O(1)
解説
解答の論理構成
- 問題文は「線形リスト上の探索の際にアクセスするノードの数は、線形リストの長さの平均 n/m に比例する」と述べています。ここで n はデータ件数、m はハッシュ表(配列)の長さです。
- さらに「m の選び方は任意なので、n に対して十分に大きくとっておけば、計算量が キ となる」と明示されています。
- n/m が 1 前後の定数になるよう m ≧ n を確保すれば、探索・追加・削除時に平均してアクセスするノード数は定数個に収まります。
- したがって、計算量はデータ件数 n に依存しない定数時間となり、キ には O(1) が入ります。
- 問題文も「この場合の計算量は 2 分探索木による O(log n) より小さい」と比較しており、定数時間であることを強調しています。
誤りやすいポイント
- n/m を「ハッシュ値の計算コスト」と誤解し、計算量を O(n/m) と直接書いてしまう。実際には m ≧ n とすれば O(1) です。
- 「最悪計算量」を聞かれていると思い込み、衝突が全件に発生するケース(O(n))を答えるミス。設問は平均計算量について説明した直後の空欄です。
- 「2 分探索木より小さい」から「O(log n − 1)」などと誤った減算を行う。Big-O は上界を示すため差し引きの概念はありません。
FAQ
Q: 配列サイズ m をどの程度に設定すれば平均 O(1) が保証できますか?
A: 一般にはデータ件数 n と同程度、あるいはもう少し大きい素数を採用する設計が多いです。負荷が高まったらリハッシュで m を拡張します。
A: 一般にはデータ件数 n と同程度、あるいはもう少し大きい素数を採用する設計が多いです。負荷が高まったらリハッシュで m を拡張します。
Q: 最悪計算量が O(n) になるのはどんなときですか?
A: ハッシュ関数が不適切で「すべてのキーが同じハッシュ値になる」場合です。問題文ではこれを「確率は小さく、実際上は無視できる」と述べています。
A: ハッシュ関数が不適切で「すべてのキーが同じハッシュ値になる」場合です。問題文ではこれを「確率は小さく、実際上は無視できる」と述べています。
Q: 2 分探索木の O(log n) と比べてメモリ使用量はどうなりますか?
A: チェイン法は配列(ハッシュ表)+リンクリストを持つため、キー密度が低い場合はメモリ効率が下がることがあります。バランス木はノード数とデータ件数が一致するためメモリ使用量が安定しています。
A: チェイン法は配列(ハッシュ表)+リンクリストを持つため、キー密度が低い場合はメモリ効率が下がることがあります。バランス木はノード数とデータ件数が一致するためメモリ使用量が安定しています。
関連キーワード: ハッシュ法, チェイン法, 衝突解消, 計算量解析, Big-O記法
