応用情報技術者 2010年 秋期 午後 問02
構文解析に関する次の記述を読んで、設問1~4に答えよ。
宣言部と実行部からなる図1のような記述をするプログラム言語がある。その構文規則を、括弧記号で表記を拡張したBNFによって、図2のように定義した。
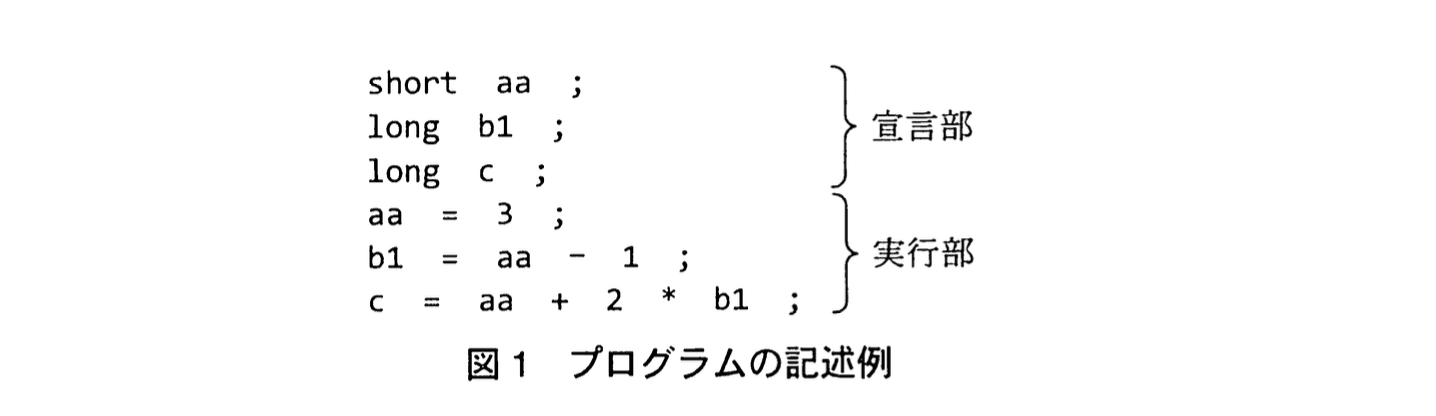
図2において、引用符「'」と「'」で囲まれた記号や文字列、<数>、及び<識別子>は終端記号を表す。そのほかの「<」と「>」で囲まれた名前は非終端記号を表す。<数>は1文字以上の数字の列を表し、<識別子>は英字で始まる1文字以上の英字又は数字からなる文字列を表す。
また、A|BはAとBのいずれかを選択することを表し、{A}はAを0回以上繰り返すことを表す。
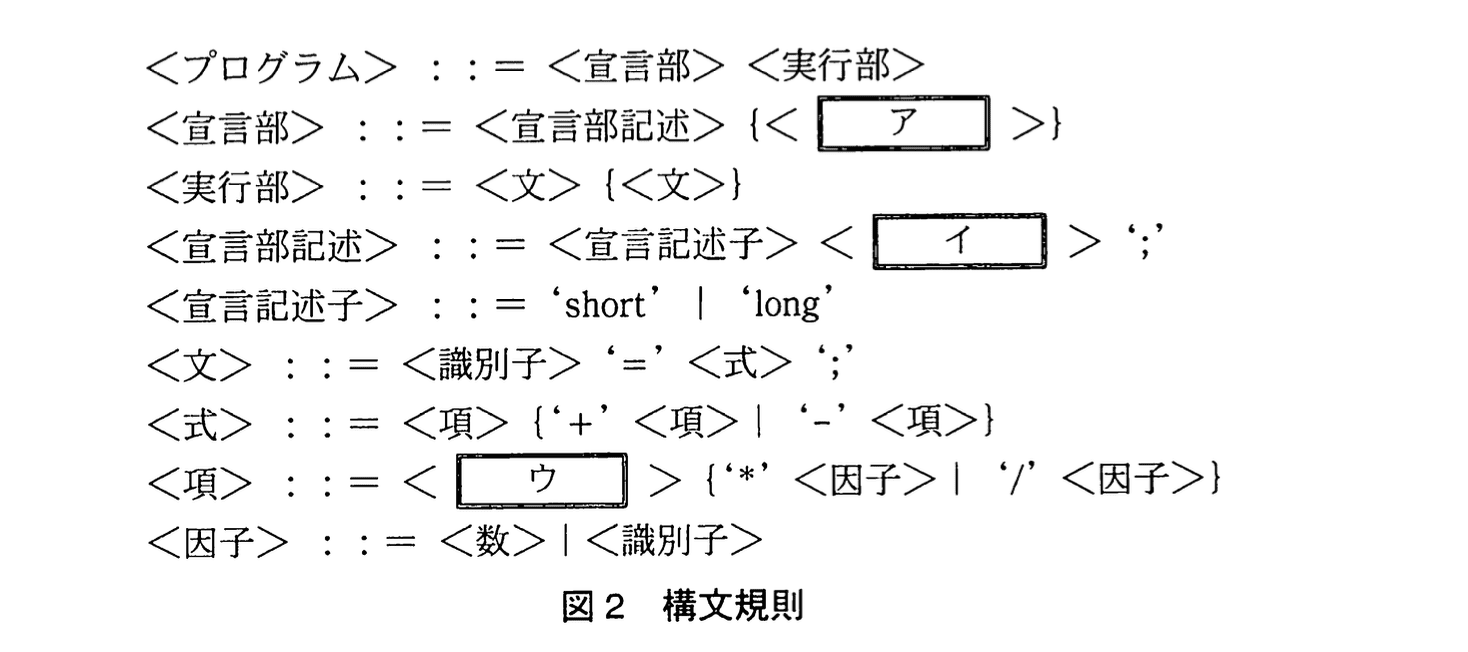
例えば、図1の最初の行 “short aa ;” は、図2の<宣言部記述>の定義に従っていて、<宣言記述子>と ‘short’、<イ>と ‘aa’、更に ‘;’ 同士がそれぞれ対応していることが分かる。
〔字句解析関数の定義〕
プログラム記述が図2の構文規則に従っているかどうかを検査するプログラムを作成するために、字句を先頭から順番に抽出し、その種類を判定する関数 gettoken() を定義する。ここでいう字句とは、構文規則における終端記号である。字句と字句は、空白や改行文字で区切られている。空白や改行文字は、字句そのものには含まれない。字句の種類と関数 gettoken() の戻り値の対応を表に示す。
なお、‘short’ と ‘long’ は<識別子>には含まれない。また、いずれの終端記号にも該当しない字句やプログラム記述の終わりを検出した場合の戻り値も定義する。

〔構文解析プログラム〕
図3は、図2の構文規則に従って、<文>及び<式>の構文を検査するプログラムである。プログラムの前提条件を次に示す。
(1) <文>、<式>及び<項>の構文解析を行う関数をそれぞれ bun()、shiki()及び kou()とする。これらの関数の戻り値は、構文が正しい場合は0、エラーが検知された場合は-1である。
(2) 構文解析を行う各関数実行開始時の変数 token の値は、検査の対象となる文字列の最初の字句に対する関数 gettoken() の戻り値である。

設問1:
図2中のア〜ウに入れる適切な非終端記号又は終端記号の名前を答えよ。
模範解答
ア:宣言部記述
イ:識別子
ウ:因子
解説
解答の論理構成
- (1) 反復 { } が示すもの
プログラム中には宣言が複数並びます。宣言列を表す非終端記号は一つだけなので、 “複数回出現して良い要素=宣言そのもの” と判断できます。したがって { … } 内に来る ア は 〈宣言部記述〉 です。 - (2) 宣言行の中央に現れる字句の種類
例として問題文に示された “short aa ;” を見ると、'short'(宣言記述子)の直後に aa が入り、最後は ';' で閉じられます。この aa は “英字で始まる1文字以上の英字又は数字からなる文字列” であり、'short' と 'long' は<識別子>には含まれない” と明記されています。従って イ は 〈識別子〉 となります。 - (3) 〈項〉の先頭に置かれる要素
加減算より優先順位の高い乗除算を表す 〈項〉 は、乗除演算子で区切られた 〈因子〉 の列です。従って “最初に必ず解析する要素” である ウ は 〈因子〉 になります。
誤りやすいポイント
- { … } と [ … ] を混同し、ア に “〈宣言部〉” など再帰的に違う記号を入れてしまう。
- 例外扱いの 'short'・'long' を<識別子>に含めてしまい、イ を “〈数〉” との併記で迷う。
- 〈項〉と〈因子〉の階層を取り違え、“掛け算・割り算をまとめているのは 〈項〉” であることを忘れ、ウ に “〈項〉” を入れるミス。
FAQ
Q: “short 3 ;” のように数値を宣言できるのでは?
A: いいえ。宣言行は “宣言記述子+〈識別子〉+;” が原則です。〈数〉は宣言行の構文に含まれません。
A: いいえ。宣言行は “宣言記述子+〈識別子〉+;” が原則です。〈数〉は宣言行の構文に含まれません。
Q: 〈因子〉の定義に括弧 () がないのは誤り?
A: 本問の文法仕様に括弧は存在しません。従って再帰下降解析でも括弧処理は不要です。
A: 本問の文法仕様に括弧は存在しません。従って再帰下降解析でも括弧処理は不要です。
Q: もし ウ が誤って “〈項〉” だった場合、構文解析はどこで失敗する?
A: kou() が 〈項〉を再帰的に呼び出す形となり、乗除演算子を消費できず無限再帰またはトークン不一致を起こします。
A: kou() が 〈項〉を再帰的に呼び出す形となり、乗除演算子を消費できず無限再帰またはトークン不一致を起こします。
関連キーワード: BNF, 非終端記号、再帰下降解析、字句解析、乗除演算子
設問2:
次のプログラム記述には、図2で示した構文規則に反するエラーが幾つか含まれている。構文規則に反するエラーを含む行の番号をすべて答えよ。
short abc ; ・・・ ①
short def ghi ; ・・・ ②
long mno ; ・・・ ③
abc == def + 34 ; ・・・ ④
ghi = - 2 * mno ; ・・・ ⑤
mno = abc / 0 ; ・・・ ⑥
xyz = def - 7 ; ・・・ ⑦
模範解答
②、⑤
解説
解答の論理構成
ゆえに、構文規則に反する行は
②、⑤ です。
②、⑤ です。
誤りやすいポイント
- 〈宣言部記述〉は “型” と 〈識別子〉 1 個 だけ。カンマ区切りや連続記述は許されません。
- 〈式〉や 〈項〉 に 単項演算子(+、-)が存在しない ことを見落とすと、⑤のような記述を正しいと勘違いしがちです。
- “意味エラー(未宣言変数・0除算)” と “構文エラー” を混同しやすいので、設問で何を聞いているかを必ず確認しましょう。
FAQ
Q: - 2 * mno がダメなら 2 * - mno はどうですか?
A: いずれも 〈因子〉 の先頭に演算子が来る形になります。単項演算子の定義が無い以上、どちらも構文エラーです。
A: いずれも 〈因子〉 の先頭に演算子が来る形になります。単項演算子の定義が無い以上、どちらも構文エラーです。
Q: 行④の == は比較演算子と解釈されないのですか?
A: 本問題の字句分類に “==” はありません。字句解析では連続する “=” を 1 文字ずつ取り出す実装を前提としているため、最初の “=” が代入記号、次の gettoken() で取得した “=” は shiki() に入る前に処理済みとなり、結果として構文を乱しません。
A: 本問題の字句分類に “==” はありません。字句解析では連続する “=” を 1 文字ずつ取り出す実装を前提としているため、最初の “=” が代入記号、次の gettoken() で取得した “=” は shiki() に入る前に処理済みとなり、結果として構文を乱しません。
Q: 宣言していない xyz を使う行⑦は無視してよい?
A: はい。本問は “構文” の正しさだけを問うています。名前解決や型検査といった意味解析は評価範囲外です。
A: はい。本問は “構文” の正しさだけを問うています。名前解決や型検査といった意味解析は評価範囲外です。
関連キーワード: BNF, 構文解析、字句解析、終端記号、再帰下降パーサ
設問3:
図3中のエ、オに入れる適切な字句を答えよ。
模範解答
エ:tokenと'='が等しい
オ:kou()と-1が等しい
解説
解答の論理構成
-
〈文〉の構文を確認
【問題文】の構文規則に「〈文〉 ::= 〈識別子〉 ‘=’ 〈式〉 ‘;’」とあります。つまり- 先頭に〈識別子〉
- 次に ‘=’
- 続いて〈式〉
- 最後に ‘;’
の順で現れることが必須です。
-
bun() の処理フローと エ
図3の bun() は〈文〉を検査する関数です。最初に token が 'I'(〈識別子〉)であることを確認してから gettoken() で次の字句を読み込みます。次に文法どおり ‘=’ が現れるかを調べる必要がありますから、 「if ( token と '=' が等しい ) then」
が正しい判定条件になります。したがって エ は「token と '=' が等しい」です。 -
〈式〉の構文と オ
〈式〉の定義は「〈式〉 ::= 〈項〉 { ‘+’ 〈項〉 | ‘-’ 〈項〉 }」。必ず先頭に〈項〉が来るため、shiki() は開始直後に kou() を呼んで〈項〉の妥当性をチェックしなければなりません。エラー検出ルール(正常なら 0、異常なら -1)より、 「if ( kou() と -1 が等しい ) then return -1 endif」
が必要条件です。よって オ は「kou() と -1 が等しい」です。 -
結論
エ:token と '=' が等しい
オ:kou() と -1 が等しい
誤りやすいポイント
- ‘=’ と ‘==’ を混同して比較演算子を誤記する
- 〈式〉を shiki() でなく kou() だけで終わらせてしまい、加減算ループに対応できなくなる
- gettoken() を呼ぶ位置を間違え、token が次字句を指していない状態で比較を行う
FAQ
Q: bun() で ‘;’ を確認する前に shiki() を呼ぶのはなぜですか?
A: 文法「〈識別子〉 ‘=’ 〈式〉 ‘;’」で ‘;’ は〈式〉の後ろにあるため、〈式〉の解析が完了してから ‘;’ をチェックする必要があります。
A: 文法「〈識別子〉 ‘=’ 〈式〉 ‘;’」で ‘;’ は〈式〉の後ろにあるため、〈式〉の解析が完了してから ‘;’ をチェックする必要があります。
Q: shiki() が while ループで ‘+’ と ‘-’ を処理しているのに kou() をさらに呼ぶ理由は?
A: 〈式〉は複数の 〈項〉 の加減算で構成されるため、先頭の 〈項〉 を kou() で解析し、その後の繰り返しでも毎回 kou() で新しい 〈項〉 を解析します。
A: 〈式〉は複数の 〈項〉 の加減算で構成されるため、先頭の 〈項〉 を kou() で解析し、その後の繰り返しでも毎回 kou() で新しい 〈項〉 を解析します。
Q: gettoken() はいつ呼べば良いですか?
A: 「今参照している token を消費し、次の字句を先読みしたい」タイミングで呼びます。図3では字句を受理した直後に gettoken() が呼び出されています。
A: 「今参照している token を消費し、次の字句を先読みしたい」タイミングで呼びます。図3では字句を受理した直後に gettoken() が呼び出されています。
関連キーワード: BNF, 字句解析、構文解析、再帰下降パーサ、トークン
設問4:“d = a * ( 3 + b ) ;”のように、式の演算子の評価順序を明示的に記述するため、「(」及び「)」を使えるように構文規則を拡張したい。これについて、(1)、(2)に答えよ。
(1)図2の構文規則の中の<因子>の行を、次のように書き換えた。
カに入れる適切な字句を答えよ。
<因子>::=<数>|<識別子>| '('カ')'
模範解答
カ:<式>
解説
解答の論理構成
- 問題文は「“d = a * ( 3 + b ) ;”のように、式の演算子の評価順序を明示的に記述するため、『(』及び『)』を使えるように構文規則を拡張したい」と述べています。
- 追加するトークンは括弧で囲まれた部分であり、その内部に来るのは“+”や“-”も現れる完全な式です。
- 図2の既存規則では演算子“+”“-”を含めた構文を表す非終端記号は<式>しか存在しません。
- したがって、書き換え後の
<因子> ::= <数>|<識別子>|'('カ')'
の カ には<式>を入れるのが唯一整合する選択肢です。 - よって解答は「<式>」となります。
誤りやすいポイント
- 括弧内に<項>や<因子>を入れてしまう誤答が多いですが、これでは“3 + b”の“+”を含む表現を解析できません。
- 「(」と「)」を終端記号として追加するだけで済むと考え、非終端記号を指定し忘れるケース。
- 全角『(』『)』と半角“(” “)”の表記ゆれを混同し、原文の終端記号を正確に引用しないミス。
FAQ
Q: どうして<項>ではなく<式>なのですか?
A: <項>は“*” “/”しか扱わず、“+”“-”を含む表現は<式>でしか認められていないからです。
A: <項>は“*” “/”しか扱わず、“+”“-”を含む表現は<式>でしか認められていないからです。
Q: 括弧は再帰呼び出しになるのですか?
A: はい。<因子>の中で<式>を許可することで、<式>→<項>→<因子>→<式>…という再帰的な解析が可能になります。
A: はい。<因子>の中で<式>を許可することで、<式>→<項>→<因子>→<式>…という再帰的な解析が可能になります。
Q: gettoken() への対応は変更が必要ですか?
A: 新たに'('と')'を終端記号として識別し、対応する戻り値を追加する実装変更が必要です。
A: 新たに'('と')'を終端記号として識別し、対応する戻り値を追加する実装変更が必要です。
関連キーワード: BNF, 再帰下降構文解析、非終端記号、終端記号、演算子優先度
設問4:“d = a * ( 3 + b ) ;”のように、式の演算子の評価順序を明示的に記述するため、「(」及び「)」を使えるように構文規則を拡張したい。これについて、(1)、(2)に答えよ。
(2)この構文規則の拡張によって、関数gettoken()も修正する必要がある。どのような修正が必要か、35字以内で述べよ。
模範解答
「(」と「)」に対してはほかの字句とはそれぞれ別の戻り値を戻す。
または
「'('と')'の字句に対してそれぞれ'('と')'を戻す。」
解説
解答の論理構成
- 図2の構文規則に新しく '(' と ')' を終端記号として追加するため、字句解析段階で両者を区別して取り出せるようにする必要があります。
- 表「字句の種類と関数 gettoken() の戻り値の対応」では
'='、'+'、'-'、'*'、'/' 及び ';'
が「左の各字句に同じ」戻り値を返すと示されています。既存の記号トークンは “その文字自身” を戻しています。 - 同じ方針を踏襲すると、'(' と ')' についても 個別の戻り値 を定義すれば構文解析側は簡単に識別できます。
- よって解答は「『(』と『)』に対してはほかの字句とはそれぞれ別の戻り値を戻す。」となります。
誤りやすいポイント
- 既存記号と同じ戻り値を使って良いと勘違いし、両括弧を同一トークンにまとめてしまう。
- 'S'、'L'、'N'、'I'、'?'、'$' など予約済みコードと衝突する戻り値を割り当てる。
- 構文規則を変更しただけで満足し、gettoken() の修正を失念する。
- 括弧を「<識別子>」や「<数>」と同様に空白で区切られる字句だと思い込み、字句境界の判定を誤る。
FAQ
Q: 既存の戻り値に空きがない場合はどうすればよいですか?
A: '(' と ')' も既存の記号と同様に “その文字自身” を戻せば追加コードは不要です。文字が被らなければ問題ありません。
A: '(' と ')' も既存の記号と同様に “その文字自身” を戻せば追加コードは不要です。文字が被らなければ問題ありません。
Q: 括弧は式の中だけで使うので、bun() の修正は不要ですか?
A: はい。括弧は<式>内部(shiki()、kou())で解釈されるため、bun() への直接変更は不要です。
A: はい。括弧は<式>内部(shiki()、kou())で解釈されるため、bun() への直接変更は不要です。
Q: 空白を挟まない “a*(3+b)” のような書き方でも認識できますか?
A: gettoken() が記号を単独トークンとして切り出す実装になっていれば空白なしでも正しく分割できます。
A: gettoken() が記号を単独トークンとして切り出す実装になっていれば空白なしでも正しく分割できます。
関連キーワード: 字句解析、トークン、BNF, 構文解析、再帰下降パーサ
