応用情報技術者 2010年 春期 午後 問02
アプリケーションで使用するデータ構造とアルゴリズムに関する次の記述を読んで、設問1〜4に答えよ。
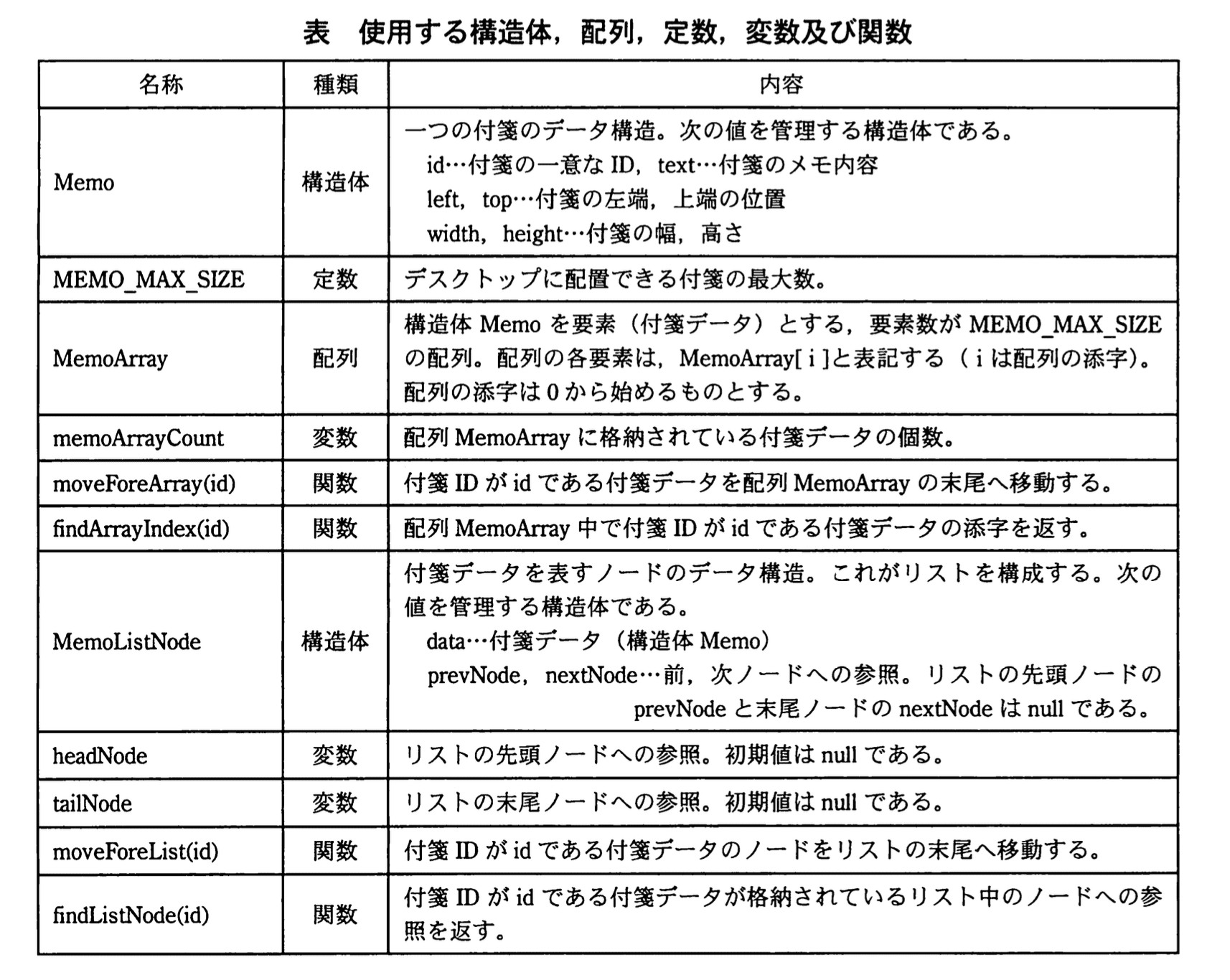
PCのデスクトップ上の好きな位置に付箋を配置できるアプリケーションの実行イメージを図1に、付箋1枚のデータイメージを図2に示す。
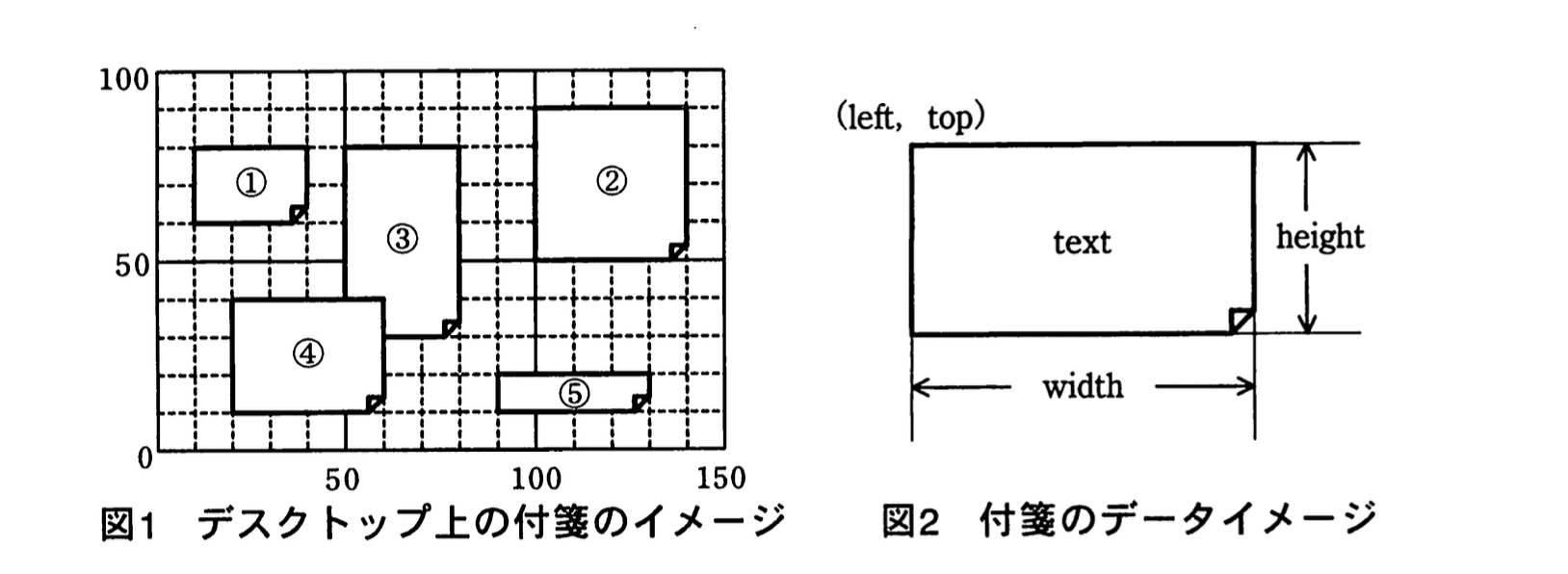
複数の付箋データを管理する方法として、配列と双方向リスト(以下、リストという)のいずれがよいかを検討することにした。そこで、図1の付箋③のようにほかの付箋の背後にある付箋を一番手前に移動するアルゴリズムを、配列とリストそれぞれで実装して比較検討する。使用する構造体、配列、定数、変数及び関数を表に示す。また、図1の付箋①〜⑤を順番に、配列及びリストにそれぞれ格納した際のイメージを図3、4に示す。
なお、配列及びリストの末尾に近い付箋データほど、デスクトップ上の手前に表示される。
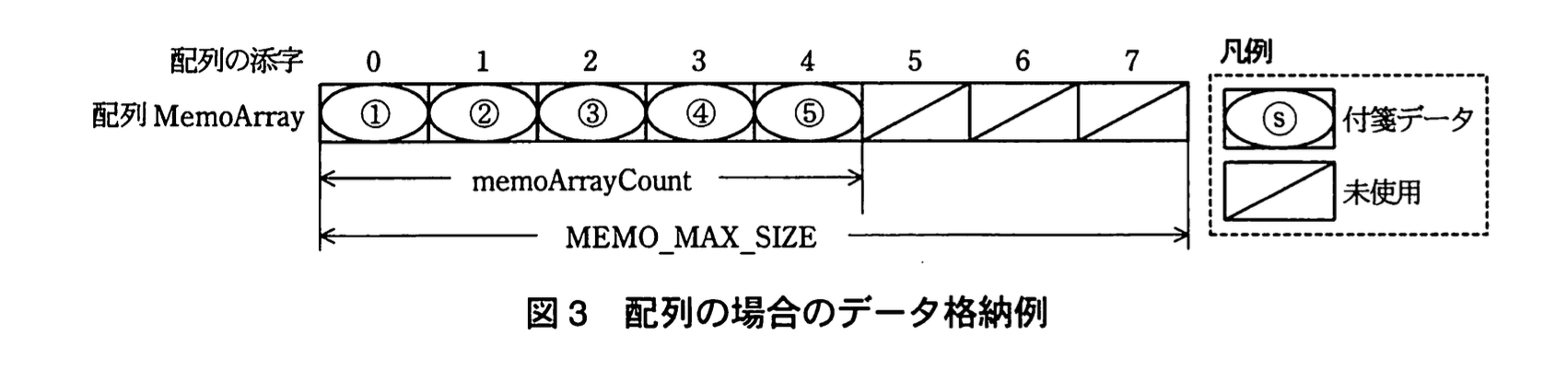
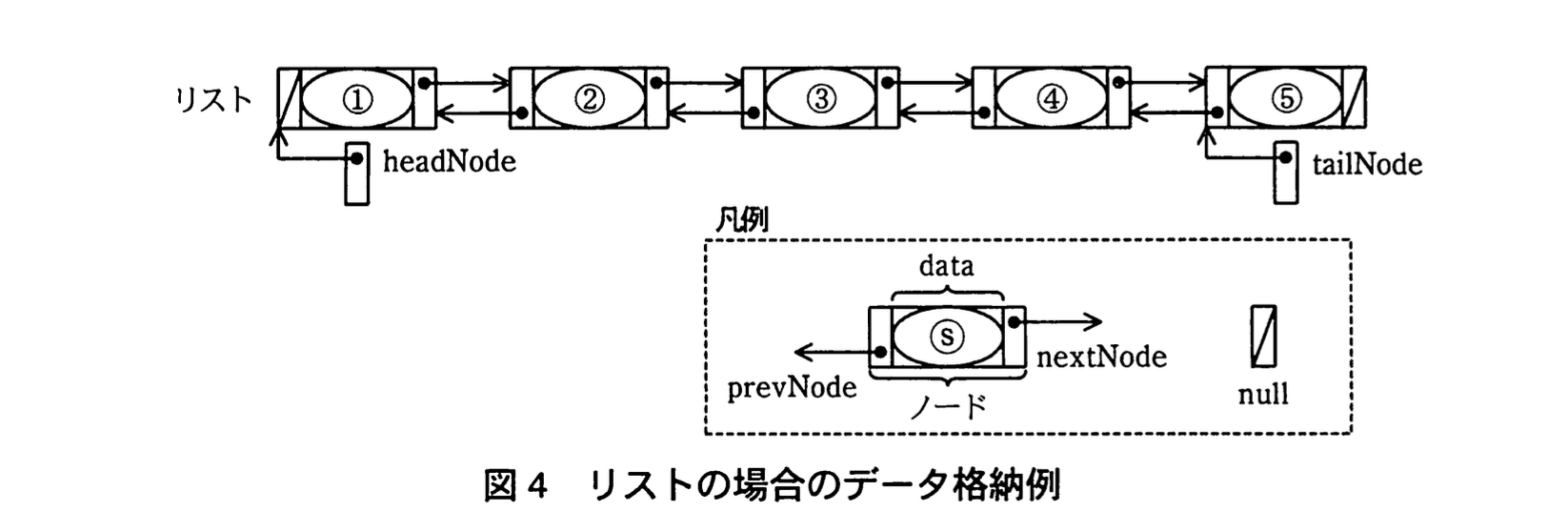
構造体の要素は“.” を使った表記で表す。“.”の左には、構造体を表す変数又は構造体を参照する変数を書く。“.”の右には、要素の名前を書く。配列の場合、図3の付箋⑤のメモ内容は MemoArray[4].text、また、リストの場合、図4の付箋②のIDは headNode.nextNode.data.id と表記できる。
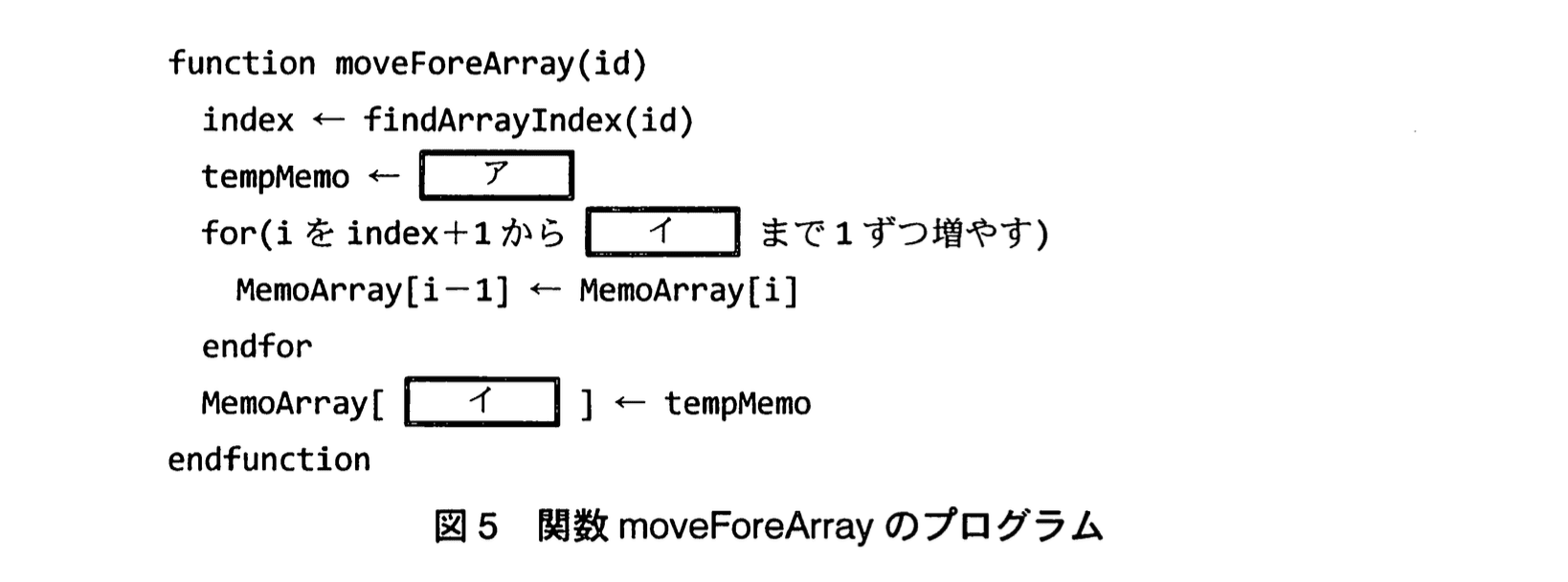
〔関数 moveForeArray〕
関数 moveForeArray の処理手順を次の (1)〜(4) に示す。
(1) 配列中の付箋IDが id である付箋データの添字を取得する。
(2) 配列中の (1) で取得した位置の付箋データを一時変数へ退避する。
(3) 配列中の (1) で取得した位置の次から配列の最後の付箋データがある位置までの付箋データを一つずつ前へずらす。
(4) 配列中の最後の付箋データがあった位置へ (2) で退避した付箋データを代入する。
〔関数 moveForeList〕
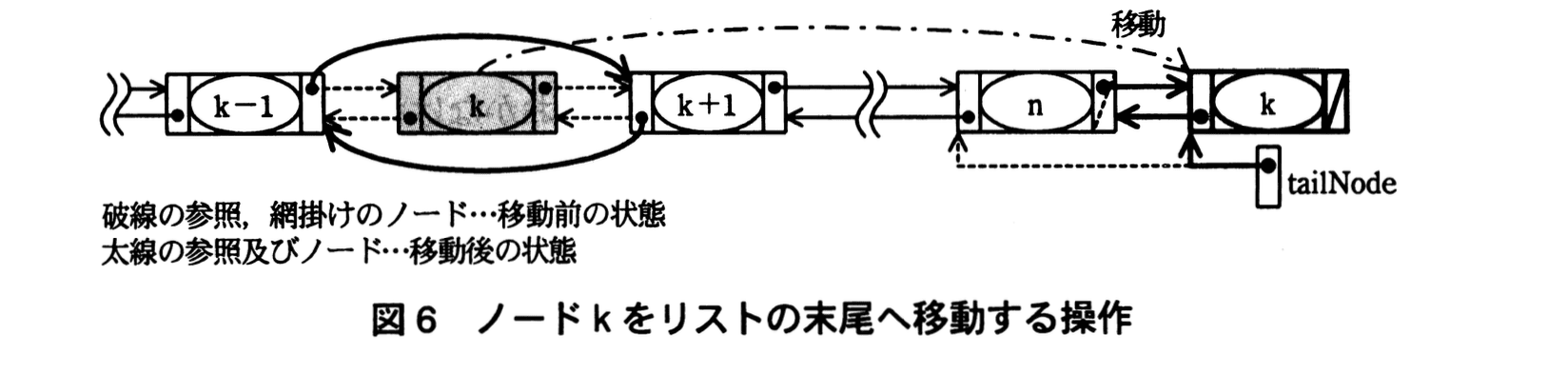
関数 moveForeList の処理手順を次の (1)〜(4) に示す。処理手順中の (3)(ii) 及び (4) の操作を図6に示す。また、関数 moveForeList のプログラムを図7に示す。
(1) リストから、付箋IDが id である付箋データをもつノードへの参照を取得する。
(2) (1) で取得したノード(ノード k)が末尾ノードの場合、処理を終了する。
(3) ノード k が先頭ノードの場合は (i) を、そうでない場合は (ii) を実行する。ここで、ノード k の次ノードをノード k+1、前ノードをノード k−1 と呼ぶ。
(i) リストの先頭ノードへの参照をノード k+1 への参照に変更し、ノード k+1 中の前ノードへの参照を null に変更する。
(ii) ノードk−1中の次ノードへの参照をノードk+1への参照に変更し、ノードk+1中の前ノードへの参照をノードk−1への参照に変更する。
(4) リストの末尾ノード(ノードn)中の次ノードへの参照をノードkへの参照に、ノードk中の前ノードへの参照をノードnへの参照に変更する。ノードk中の次ノードへの参照をnullに、リストの末尾ノードへの参照(tailNode)をノードkへの参照に変更する。

〔二つのアルゴリズムに関する考察〕
まず、時間計算量について考える。配列の場合、末尾へ移動する要素より後のすべての要素をずらす必要が生じる。この処理の計算量は オ である。リストの場合、末尾へ移動する付箋データの位置にかかわらず、少数の参照の変更だけでデータ同士の相対的な位置関係を簡単に変えられる。この処理の計算量は カ である。
次に、必要な領域の大きさについて考える。付箋データ1個当たりの領域の必要量は、配列の方が小さい。リストは参照を入れる場所を余分に必要とする。しかし、全体で必要とする領域は、配列の場合、キ としておかなければならない。リストの場合、配置されている付箋データの個数分だけ領域を確保すればよい。
設問1:図1の付箋①~⑤を格納した図3の配列及び図4のリストについて、(1)、(2)に答えよ。
(1)配列に格納されている、付箋①の高さ20を求める適切な式を答えよ。
模範解答
MemoArray[0].height
解説
解答の論理構成
- 付箋①が配列中のどの添字に入るかを確認します。問題文には
「図1の付箋①〜⑤を順番に、配列及びリストにそれぞれ格納した際のイメージを図3、4に示す。」
とあり、図3では左から順に①→②→③→④→⑤ が並んでいます。 - 配列の添字規則について、問題文は
「配列の添字は 0 から始めるものとする。」
と明示しています。したがって先頭の付箋①は添字「0」です。 - 構造体要素の表記規則は
「構造体の要素は“.” を使った表記で表す。」
と定義されており、具体例として
「図3の付箋⑤のメモ内容は MemoArray[4].text」
が示されています。 - 付箋①の高さを取得したいので要素名は height を使います。
- 以上より、配列 MemoArray の先頭要素(添字 0)の高さは
MemoArray[0].height
となります。
誤りやすいポイント
- 添字を「1」から始まると勘違いして MemoArray[1].height としてしまう。
- 構造体要素の区切りを -> やドットを忘れて MemoArray[0]height と書く記述ミス。
- リストと混同し、headNode.data.height としてしまう。
FAQ
Q: 添字がずれるのが不安です。図で素早く確認する方法はありますか?
A: 例として示された「図3の付箋⑤のメモ内容は MemoArray[4].text」を利用してください。⑤が「4」なら①が「0」になることがすぐ分かります。
A: 例として示された「図3の付箋⑤のメモ内容は MemoArray[4].text」を利用してください。⑤が「4」なら①が「0」になることがすぐ分かります。
Q: height ではなく top や width と書くと減点になりますか?
A: 要求は「付箋①の高さ」ですので要素名 height が必須です。別の要素名を書くと誤答になります。
A: 要求は「付箋①の高さ」ですので要素名 height が必須です。別の要素名を書くと誤答になります。
Q: リストの場合の書き方も覚える必要がありますか?
A: 別設問で問われる可能性があるため、「headNode.data.height」のようなドットチェーン表記も併せて整理しておくと安全です。
A: 別設問で問われる可能性があるため、「headNode.data.height」のようなドットチェーン表記も併せて整理しておくと安全です。
関連キーワード: 配列, 添字, 構造体, 要素アクセス, データ構造
設問1:図1の付箋①~⑤を格納した図3の配列及び図4のリストについて、(1)、(2)に答えよ。
(2)tailNode.prevNode.data.heightの値を答えよ。
模範解答
30
解説
解答の論理構成
- 「図1の付箋①〜⑤を順番に、配列及びリストにそれぞれ格納した際のイメージを図3、4に示す。」とあるので、図4(リスト)の順序は①→②→③→④→⑤です。
- 図4では最後尾(末尾)ノードが付箋⑤であり、リストの末尾を指す変数は tailNode です。したがって
• tailNode … ⑤のノード
• tailNode.prevNode … ⑤の直前、すなわち付箋④のノード - ノードが保持する付箋データは構造体 Memo であり、その要素の一つが height です(表「Memo : width, height」より)。よって求める値は「付箋④の高さ」。
- 図1には等間隔のグリッドが描かれ、1目盛=10 の縮尺になっています。付箋④は縦方向に3目盛分に相当する大きさで描かれているため
したがって tailNode.prevNode.data.height は 30 になります。
誤りやすいポイント
- tailNode を「先頭ノード」と取り違え、付箋①や②の高さを答えてしまう。
- prevNode と nextNode を混同し、tailNode.nextNode を参照しようとして null になるケース。
- 図1の縮尺(1目盛がいくつか)を読み違え、5目盛=50 などと誤計算してしまう。
FAQ
Q: 図4の順序は固定ですか、それとも実際の ID 順に並んでいるのですか?
A: 問題文の「図1の付箋①〜⑤を順番に…図4に示す。」に従い、図4の並びは①→②→③→④→⑤です。ID 順であるかどうかは本問の求解には影響しません。
A: 問題文の「図1の付箋①〜⑤を順番に…図4に示す。」に従い、図4の並びは①→②→③→④→⑤です。ID 順であるかどうかは本問の求解には影響しません。
Q: height を求める際、必ずグリッド目盛の大きさで計算しなければなりませんか?
A: はい。図1ではグリッドが尺度を示しており、付箋の幅・高さは目盛数 × 1目盛長で定義されます。よって高さは目盛数を数えることで一意に決まります。
A: はい。図1ではグリッドが尺度を示しており、付箋の幅・高さは目盛数 × 1目盛長で定義されます。よって高さは目盛数を数えることで一意に決まります。
Q: moveForeList のアルゴリズムと今回の height 値取得は関係がありますか?
A: 直接的な関係はありません。本設問はリスト上の位置関係(tailNode, prevNode)を理解していれば答えられるもので、ポインタ操作そのものや moveForeList の処理は問われていません。
A: 直接的な関係はありません。本設問はリスト上の位置関係(tailNode, prevNode)を理解していれば答えられるもので、ポインタ操作そのものや moveForeList の処理は問われていません。
関連キーワード: 連結リスト, 配列, ポインタ操作, データ構造
設問2:
図5中のア、イに入れる適切な字句を答えよ。
模範解答
ア:MemoArray[index]
イ:memoArrayCount−1
解説
解答の論理構成
-
退避すべき付箋データ
手順 (2) では「配列中の (1) で取得した位置の付箋データを一時変数へ退避する。」とあります。プログラムではその“位置”を変数 index に格納しているので、退避対象は MemoArray[index] です。したがって ア は 「MemoArray[index]」 となります。 -
for ループの終端値
手順 (3) では「配列中の (1) で取得した位置の次から配列の最後の付箋データがある位置まで」を前へずらします。“最後の付箋データがある位置”は、現在格納されている要素数 memoArrayCount の直前の添字、すなわち memoArrayCount−1 です。プログラムの for ループで i をその添字まで増やす必要があるので、 イ は 「memoArrayCount−1」 になります。 -
末尾への再配置
手順 (4) では「配列中の最後の付箋データがあった位置へ (2) で退避した付箋データを代入する。」とあるため、ループ終了後の添字も memoArrayCount−1 で一致し、全体の整合性が取れます。
以上より
・ア MemoArray[index]
・イ memoArrayCount−1
・ア MemoArray[index]
・イ memoArrayCount−1
誤りやすいポイント
- 「最後の付箋データ」を固定長配列の末尾(MEMO_MAX_SIZE−1)と混同しやすい。実際には現在の要素数 memoArrayCount を基準にする点に注意。
- index の要素を退避せずに上書きしてしまい、データが失われるケース。
- ループ条件を i < memoArrayCount−1 と書き、最終要素をずらし損ねるミス。
FAQ
Q: MEMO_MAX_SIZE と memoArrayCount の違いは何ですか?
A: MEMO_MAX_SIZE は配列の物理的な最大長、memoArrayCount は現在使っている要素数です。今回の移動では論理的末尾である memoArrayCount−1 が重要です。
A: MEMO_MAX_SIZE は配列の物理的な最大長、memoArrayCount は現在使っている要素数です。今回の移動では論理的末尾である memoArrayCount−1 が重要です。
Q: 退避にポインタ(参照)だけを使えば高速化できますか?
A: 構造体の大きさによってはポインタ退避の方がコピー量を削減できますが、本問はアルゴリズム比較が目的なので深くは問われていません。
A: 構造体の大きさによってはポインタ退避の方がコピー量を削減できますが、本問はアルゴリズム比較が目的なので深くは問われていません。
Q: 配列とリスト、領域効率はどちらが良いのですか?
A: ノードごとに参照を持つリストは1要素当たりの領域が大きいですが、配列は「MEMO_MAX_SIZE としておかなければならない」ように上限分を確保するため、要素数が少ない場合はリストの方が総領域は小さくなります。
A: ノードごとに参照を持つリストは1要素当たりの領域が大きいですが、配列は「MEMO_MAX_SIZE としておかなければならない」ように上限分を確保するため、要素数が少ない場合はリストの方が総領域は小さくなります。
関連キーワード: 配列シフト, 双方向リスト, 時間計算量, 論理添字, 退避コピー
設問3:
図7中のウ、エに入れる適切な字句を答えよ。
模範解答
ウ:node.nextNode.prevNode ← node.prevNode
エ:node.prevNode ← tailNode
解説
解答の論理構成
-
前提
問題文には、末尾以外にあるノードをリストの末尾へ移動する処理として、
“(4) リストの末尾ノード(ノードn)中の次ノードへの参照をノードkへの参照に、ノードk中の前ノードへの参照をノードnへの参照に変更する。ノードk中の次ノードへの参照をnullに、リストの末尾ノードへの参照(tailNode)をノードkへの参照に変更する。”
と記載されています。これをコード化したものが図7です。 -
先頭ノード以外の場合の分岐
先に “node.prevNode.nextNode ← node.nextNode” で k−1 が k+1 を指すようにし、さらに k+1 が k−1 を指す必要があります。
したがって ウ には
node.nextNode.prevNode ← node.prevNode
が入ります。 -
末尾側へ連結する処理
既存の末尾ノード(tailNode)から新たに移動するノード k への参照は、図7中に既に “tailNode.nextNode ← node” と書かれています。
続いてノード k の prevNode を tailNode に向け替える必要があります。
よって エ には
node.prevNode ← tailNode
が入ります。 -
これにより、
・リストからノード k を一度切り離す
・旧 tailNode とノード k を相互接続する
・node.nextNode を null、tailNode を node に更新する
という“(4)”で要求された操作がすべて満たされ、整合性が保たれます。
誤りやすいポイント
- prev と next を取り違えて循環参照や断絶を起こす
- “node.nextNode ← null” を忘れ、末尾ノードが次ノードを保持してしまう
- headNode や tailNode の更新順序を誤り、一時的にリスト構造が壊れる
- 先頭ノードだった場合とそれ以外の場合の分岐を混同する
FAQ
Q: 先に tailNode.nextNode ← node を行うのと node.prevNode ← tailNode を行う順序は逆でも良いですか?
A: どちらが先でも最終結果は同じですが、実装を統一しやすいよう図7では tailNode 側から先に更新しています。
A: どちらが先でも最終結果は同じですが、実装を統一しやすいよう図7では tailNode 側から先に更新しています。
Q: 先頭ノードの場合、headNode ← node.nextNode の後に headNode が null になる可能性は?
A: 末尾ノードでないことを (2) で排除しているため、先頭=末尾というケースはありません。このため headNode は必ず非 null です。
A: 末尾ノードでないことを (2) で排除しているため、先頭=末尾というケースはありません。このため headNode は必ず非 null です。
Q: 時間計算量は配列よりリストが有利とありますが、不変ですか?
A: ノード参照が既知であれば O(1) です。ただし findListNode(id) がリニア検索なら全体では O(n) になります。
A: ノード参照が既知であれば O(1) です。ただし findListNode(id) がリニア検索なら全体では O(n) になります。
関連キーワード: 連結リスト, ポインタ操作, ノード削除, 末尾挿入, 参照更新
設問4:〔二つのアルゴリズムに関する考察〕について、(1)、(2)に答えよ。
(1)本文中のオ、カに入れる適切な字句をO記法で答えよ。
なお、配列及びリストの付箋データの個数をnとし、関数findArrayIndex及び関数findListNodeの計算量は無視する。
模範解答
オ:O(n)
カ:O(1)
解説
解答の論理構成
- 問題文は、配列の場合について「末尾へ移動する要素より後のすべての要素をずらす必要が生じる」と述べています。これは要素数を とすると最悪で 回のコピーが必要であり、時間計算量はサイズに比例します。
⇒ - リストの場合については「少数の参照の変更だけでデータ同士の相対的な位置関係を簡単に変えられる」とあります。双方向リストではノードの切り離しと末尾への再接続は固定回数のポインタ書き換えで済み、要素数に依存しません。
⇒ - 設問中で「関数findArrayIndex及び関数findListNodeの計算量は無視する」と明示されているため、探索コストを考慮する必要はありません。したがって上記がそのまま最終答となります。
誤りやすいポイント
- findArrayIndex や findListNode の線形探索を含めてしまい、リスト側まで と誤答する。
- 配列のシフトで平均ケース(約 要素移動)を考え、 と書く。定数倍は O 記法では無視される点を失念。
- リストで「末尾ポインタ更新」を忘れ、操作回数が増えると誤解して としてしまう。
FAQ
Q: 先頭ノードを移動する場合でもリストは本当に ですか?
A: はい。先頭ノードの場合でも、prevNode が null なことを確認し、数本の参照を付け替えるだけなので要素数に依存しません。
A: はい。先頭ノードの場合でも、prevNode が null なことを確認し、数本の参照を付け替えるだけなので要素数に依存しません。
Q: 配列のシフトを memcpy などの高速コピーに置き換えれば計算量は変わりますか?
A: コピー方法を工夫しても、影響する要素数が最大 である事実は変わらず、ビッグオーでは のままです。
A: コピー方法を工夫しても、影響する要素数が最大 である事実は変わらず、ビッグオーでは のままです。
Q: 配列でも空き領域を作っておけばシフト不要になりませんか?
A: 今回は「末尾に近い付箋ほど手前に表示」と指定されているため、表示順を保存する配列を密に保つ必要があり、空きを許す設計は前提外です。
A: 今回は「末尾に近い付箋ほど手前に表示」と指定されているため、表示順を保存する配列を密に保つ必要があり、空きを許す設計は前提外です。
関連キーワード: 配列, 双方向リスト, 時間計算量, ,
設問4:〔二つのアルゴリズムに関する考察〕について、(1)、(2)に答えよ。
(2)リストの場合、配置されている付箋データの個数分だけ領域を確保すればよいのに対し、配列の場合はどうしなければならないのか。キに入れる適切な字句を30字以内で答えよ。
模範解答
キ:デスクトップに配置できる付箋の最大数分の領域を確保
解説
解答の論理構成
-
問題文はメモリ使用量の比較を次のように示しています。「全体で必要とする領域は、配列の場合、キ としておかなければならない。リストの場合、配置されている付箋データの個数分だけ領域を確保すればよい。」
この一文から、配列では“現在の個数”ではなく“最大個数”を見込んだ領域確保が必要であることが読み取れます。 -
そもそも配列は宣言時に連続領域を確保する静的データ構造です。途中でサイズを伸縮できないため、最初に「最悪の場合」を想定した長さを確保しておく必要があります。
-
本問で配列のサイズを決める指標は、定数「MEMO_MAX_SIZE」に対応する次の記述です。「MEMO_MAX_SIZE: デスクトップに配置できる付箋の最大数。」
-
したがって [キ] には、配列が確保しなければならない領域量=「デスクトップに配置できる付箋の最大数分の領域を確保」という趣旨の語句が入ります。
-
この結論をまとめると、[キ] は
「デスクトップに配置できる付箋の最大数分の領域を確保」
となります。
誤りやすいポイント
- 「配列=メモリ効率が良い」と短絡的に考え、最大数ではなく「現在数+α」で十分だと誤解する。配列は伸縮しないため将来追加できなくなるリスクを見落としがちです。
- 「MEMO_MAX_SIZE」を単なる上限チェック用定数と捉え、メモリ確保量にまで関係すると気付かない。
- リストなら動的確保=常に最小メモリ、配列は固定確保=最大メモリという本質的な違いを混同し、両者の長所短所を取り違える。
FAQ
Q: MEMO_MAX_SIZE を少なめに設定しておけばメモリ節約になりますか?
A: 最大数を小さくすると確かに配列の使用メモリは減りますが、付箋をそれ以上置けなくなる制限が厳しくなります。ユーザビリティとのトレードオフです。
A: 最大数を小さくすると確かに配列の使用メモリは減りますが、付箋をそれ以上置けなくなる制限が厳しくなります。ユーザビリティとのトレードオフです。
Q: 配列でも realloc などでサイズ変更すればよいのでは?
A: 一般的な C 言語の可変長配列やベクタ型を採用すれば伸縮可能ですが、本問では「要素数が MEMO_MAX_SIZE の配列」と明示されており、固定長配列として扱う前提です。
A: 一般的な C 言語の可変長配列やベクタ型を採用すれば伸縮可能ですが、本問では「要素数が MEMO_MAX_SIZE の配列」と明示されており、固定長配列として扱う前提です。
Q: リストのほうが常に優れているのですか?
A: リストは追加削除が高速・柔軟ですが、各ノードに prevNode と nextNode の参照分だけメモリを多く消費します。データ件数が少なく追加削除が頻繁でない場合は配列のほうがシンプルかつメモリ効率が良いケースもあります。
A: リストは追加削除が高速・柔軟ですが、各ノードに prevNode と nextNode の参照分だけメモリを多く消費します。データ件数が少なく追加削除が頻繁でない場合は配列のほうがシンプルかつメモリ効率が良いケースもあります。
関連キーワード: 配列, リンクドリスト, メモリ確保, 固定長データ構造, 最悪ケース
