応用情報技術者 2010年 春期 午後 問04
インターネットを介した情報提供システムに関する次の記述を読んで、設問1〜4に答えよ。
Z社は、利用者が希望する映画のタイトル、あらすじ、上映館、上映期間などの映画情報を表示する情報提供サービスを行っており、平均待ち時間の目標値を40ミリ秒以下としている。このサービスに使用する情報提供システムの現在のシステム構成を図1に示す。
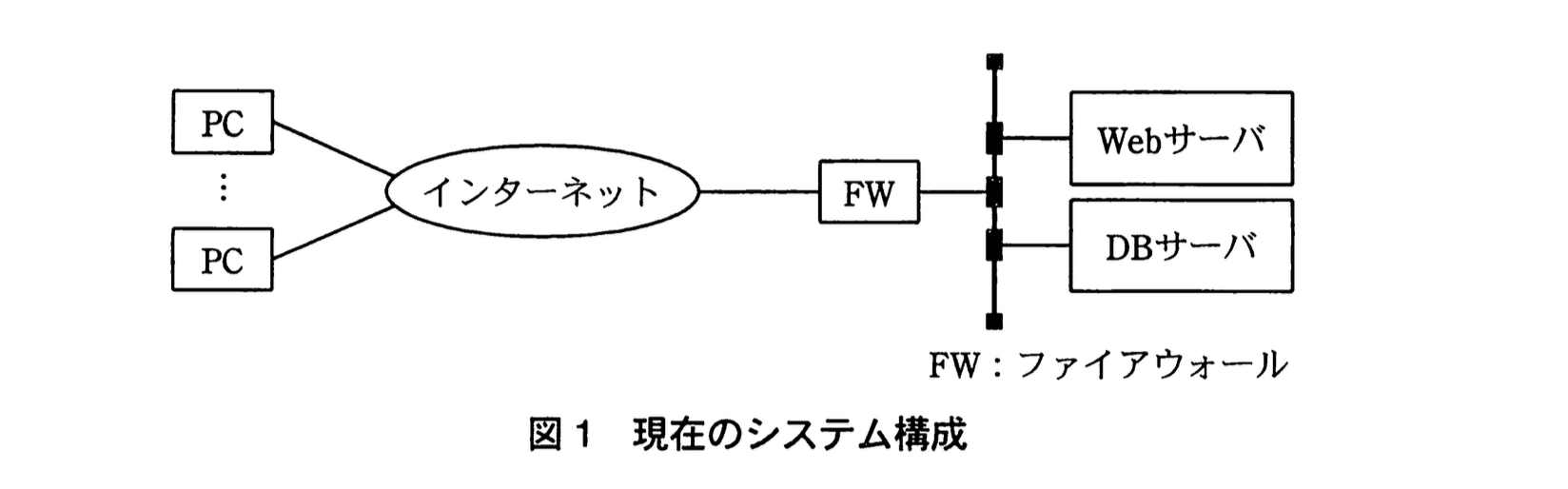
Webサーバとデータベースサーバ(以下、DBサーバという)を一体のシステムとして、現在のシステムの状況を調査したところ、1分当たりのアクセス数は平均600件、1アクセス当たりの平均処理時間Tpは40ミリ秒であった。また、アクセス頻度はおおむね a 分布に、処理時間はおおむね b 分布に従っていたので、M/M/1の待ち行列モデルによって評価することにした。
〔システム構成の見直し〕
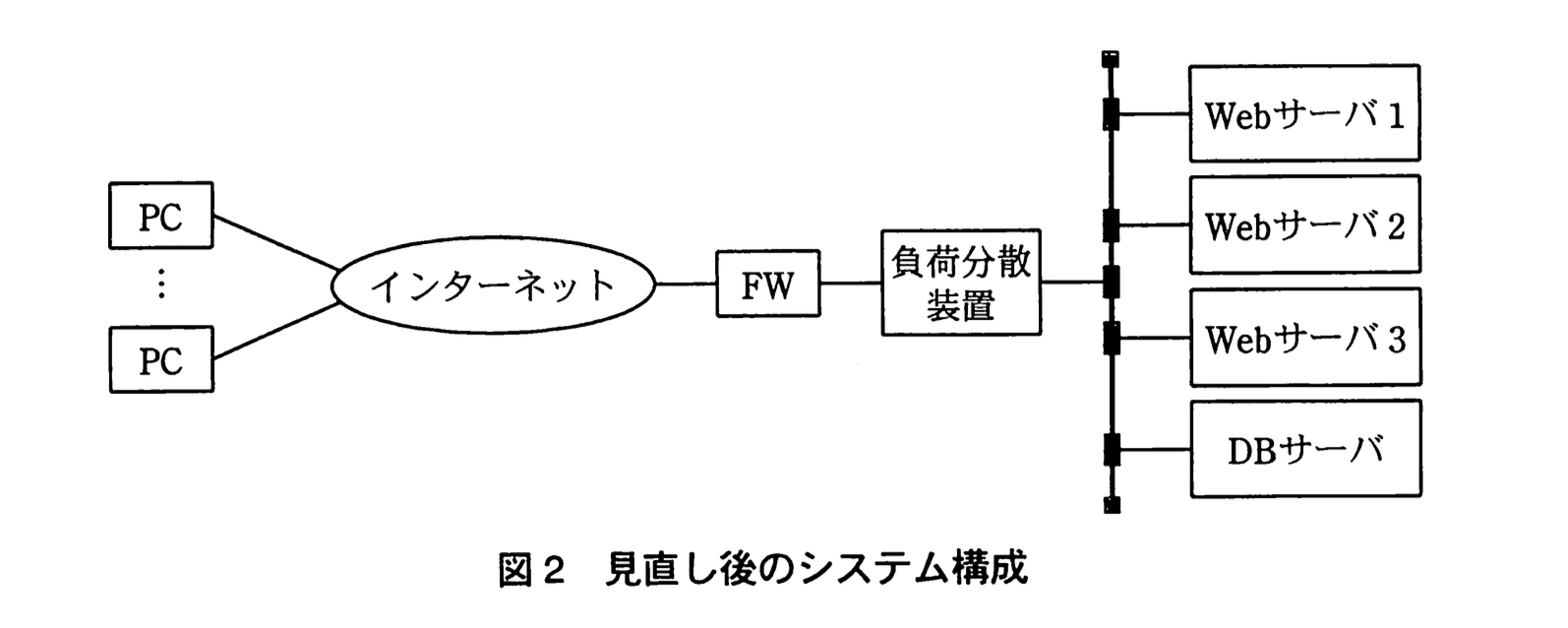
アクセス数が顕著に増加しているので、現在のシステム構成のままでは、将来、平均待ち時間がZ社の目標値を超えてしまう可能性のあることが分かった。そこで、この問題に対応するために、情報提供システムのシステム構成を見直して、図2に示すように、負荷分散装置を介して現行Webサーバと同等の処理能力を有するWebサーバ3台に負荷分散するシステム構成を検討することにした。
見直し後のシステムの負荷分散装置では、次の(ⅰ)〜(ⅴ)の負荷分散方式のいずれかを選択することができる。
(i) ラウンドロビン方式:あらかじめ決めた順序で各Webサーバにアクセスを振り分ける。
(ii) 加重ラウンドロビン方式:Webサーバの処理能力に応じて、アクセスを振り分ける。
(iii) 最少クライアント数方式:接続中のクライアント数が最も少ないWebサーバにアクセスを振り分ける。
(iv) 最少データ通信量方式:データ通信量が最も少ないWebサーバにアクセスを振り分ける。
(v) 最小負荷方式:CPU 使用率が最も低いWebサーバにアクセスを振り分ける。
Z 社では、負荷分散方式としては、設定の容易なラウンドロビン方式を採用することにした。
しかし、図2の見直し後のシステム構成においても、①アクセス数が一定数を超過すると、Webサーバが高負荷状態となり、待ち時間が長くなるなどの事象が発生することから、更なる対処が必要と考えた。
〔新サービスの追加〕
Z 社では、(システム構成の見直し)後に、利便性を向上するため、今までのサービスに加えて、Webサーバにかかる負荷が大きい新サービスを提供することになった。この新サービスの提供では、Webサーバが DBサーバから取得して PCへ送信する、1 アクセス当たりのデータ量が増加するので、Webサーバでの CPU 処理時間も増加する。そこで、見直し後のシステムで採用していたラウンドロビン方式について再評価したところ、②複数の利用者がほぼ同時にアクセスしているとき、同じサービスを要求した利用者同士で応答時間に大きなばらつきが生じ、平均待ち時間が目標値を超える場合があることが判明したので、③負荷分散方式の設定を変更することにした。
なお、DBサーバについては、性能的に十分な余裕があり、システム全体の性能に影響を与えることはないことが分かっている。
設問1:
現在のZ社の情報提供システムについて、本文中のa、bに入れる適切な字句を答えよ。
模範解答
a:ポアソン
b:指数
解説
解答の論理構成
-
問題文の確認
本文には次の記述があります。
「アクセス頻度はおおむね a 分布に、処理時間はおおむね b 分布に従っていたので、M/M/1の待ち行列モデルによって評価することにした。」 -
M/M/1モデルの前提
M/M/1は、
• 到着過程:ポアソン分布(Markovian:メモリレスな到着間隔)
• サービス時間:指数分布(Markovian:メモリレスな処理時間)
• サーバ数:1
を前提とする待ち行列モデルです。 -
a と b の決定
• 「到着過程がポアソン分布」→ a には「ポアソン」
• 「サービス時間が指数分布」→ b には「指数」 -
結論
a:ポアソン
b:指数
誤りやすいポイント
- 「到着間隔が指数分布だからサービス時間も指数分布」と混同し、a に「指数」と書いてしまう。
- 「M/M/1」の2つ目の M(サービス時間)が何を指すのか覚え違えている。
- ポアソン分布と指数分布の関係(ポアソン過程の到着間隔が指数分布)を逆に覚えている。
FAQ
Q: M/M/1 の3つ目の「1」は何を表しますか?
A: 並列に稼働するサーバ(サービス窓口)の数が「1」であることを示します。
A: 並列に稼働するサーバ(サービス窓口)の数が「1」であることを示します。
Q: ポアソン分布と指数分布はどうつながっていますか?
A: ポアソン過程では、単位時間当たりの到着数がポアソン分布に従い、その到着間隔(連続時間)は指数分布になります。
A: ポアソン過程では、単位時間当たりの到着数がポアソン分布に従い、その到着間隔(連続時間)は指数分布になります。
Q: 到着過程が規則的(定期的)なときでも M/M/1 を使えますか?
A: いいえ。M/M/1 は到着がランダム(ポアソン)であることを前提にしているため、定期到着ではモデルの仮定が成り立ちません。
A: いいえ。M/M/1 は到着がランダム(ポアソン)であることを前提にしているため、定期到着ではモデルの仮定が成り立ちません。
関連キーワード: 待ち行列理論, M/M/1モデル, ポアソン分布, 指数分布, 到着率, サービス率
設問2:現在のZ社の情報提供システムについて、(1)〜(4)に答えよ。ただし、(1)は、整数で答えよ。(2)〜(4)は、小数第2位を四捨五入して小数第1位まで求めよ。
(1)平均到着時間間隔Tr(ミリ秒)を求めよ。
模範解答
100
解説
解答の論理構成
-
平均到着率を求める
【問題文】に「1分当たりのアクセス数は平均600件」とあります。
したがって到着率 は
です。 -
平均到着時間間隔を算出
平均到着時間間隔 は の逆数なので
となります。 -
単位をミリ秒へ変換
-
回答
よって、平均到着時間間隔 は 100 ミリ秒です。
誤りやすいポイント
- 「1分当たり」をそのまま 600 ミリ秒と勘違いし、分→秒の変換を忘れる。
- 平均処理時間「Tp 40ミリ秒」を平均到着時間と混同する。
- 逆数計算後に秒からミリ秒へ再変換する工程を抜かして 0.1 とだけ書いてしまう。
FAQ
Q: 到着率 λ を直接ミリ秒単位で出す方法はありますか?
A: 600件/分 → 10件/秒 と求めてから逆数を取るのが最も確実です。ミリ秒にしたい場合は最後に 1000 を掛ければ済みます。
A: 600件/分 → 10件/秒 と求めてから逆数を取るのが最も確実です。ミリ秒にしたい場合は最後に 1000 を掛ければ済みます。
Q: 平均処理時間「Tp 40ミリ秒」はこの計算に影響しますか?
A: 到着時間間隔の算出には関係ありません。処理時間はサービス率を決めるときに使用します。
A: 到着時間間隔の算出には関係ありません。処理時間はサービス率を決めるときに使用します。
Q: M/M/1 モデルと の関係は?
A: M/M/1 では到着率 λ が基礎パラメータです。今回の は λ の逆数で、待ち行列の解析に用います。
A: M/M/1 では到着率 λ が基礎パラメータです。今回の は λ の逆数で、待ち行列の解析に用います。
関連キーワード: 待ち行列理論, 到着率, サービス率, M/M/1, 単位変換
設問2:現在のZ社の情報提供システムについて、(1)〜(4)に答えよ。ただし、(1)は、整数で答えよ。(2)〜(4)は、小数第2位を四捨五入して小数第1位まで求めよ。
(2)利用率ρを求めよ。
模範解答
0.4
解説
解答の論理構成
-
取り出すべきデータを確認
- 到着率に相当する記述
→【問題文】「1分当たりのアクセス数は平均600件」 - サービス時間に相当する記述
→【問題文】「1アクセス当たりの平均処理時間Tpは40ミリ秒」
- 到着率に相当する記述
-
単位をそろえる
- 到着率 は 1 秒当たりに換算
- サービス時間 は 1 秒単位に換算
- サービス率 は の逆数
-
利用率 の算出
M/M/1モデルではよって -
結論
利用率 は 0.4 です。
誤りやすいポイント
- 「600件/分」をそのまま λ として に割り算し忘れる(60倍の誤差)。
- ミリ秒 → 秒への換算を忘れ、 を 40 秒と誤解する。
- M/M/1 の公式を と取り違える。
FAQ
Q: 到着率とサービス率は必ず同じ時間単位でそろえる必要がありますか?
A: はい。単位がそろっていないと利用率が正しく算出できません。
A: はい。単位がそろっていないと利用率が正しく算出できません。
Q: が 1 を超えると何が起こりますか?
A: 待ち行列が理論上無限に伸び、平均待ち時間も無限大に発散します。
A: 待ち行列が理論上無限に伸び、平均待ち時間も無限大に発散します。
Q: M/M/1 でなく M/M/c を使うのはどんな場合ですか?
A: サーバが複数台並列稼働し、それぞれが同一サービス率を持つときに M/M/c を適用します。
A: サーバが複数台並列稼働し、それぞれが同一サービス率を持つときに M/M/c を適用します。
関連キーワード: M/M/1, 待ち行列, 利用率, 到着率, サービス時間
設問2:現在のZ社の情報提供システムについて、(1)〜(4)に答えよ。ただし、(1)は、整数で答えよ。(2)〜(4)は、小数第2位を四捨五入して小数第1位まで求めよ。
(3)平均待ち時間Tw(ミリ秒)を求めよ。
模範解答
26.7
解説
解答の論理構成
-
前提条件の整理
- 到着率:問題文より「1分当たりのアクセス数は平均 600件」。よって 。
- サービス時間:問題文より「1アクセス当たりの平均処理時間 40ミリ秒」。。
- サービス率:。
- モデル:問題文に「M/M/1の待ち行列モデル」と明記されている。
-
平均待ち時間(待ち行列のみ)の公式
M/M/1 の平均待ち時間 はで求められる(単位は到着・サービス率に合わせる)。 -
値の代入
-
単位の変換
-
四捨五入(小数第2位を四捨五入し小数第1位まで)
誤りやすいポイント
- サービス率を秒で計算したまま分へ換算し忘れる。
- 公式を と取り違え、待ち時間ではなく系内時間を求めてしまう。
- の確認を怠り、安定条件を無視して計算を続行する。
- 小数第2位を四捨五入せず、26.6 ms や 26.67 ms のまま記載して減点される。
FAQ
Q: 到着率とサービス率の単位はそろえないといけませんか?
A: 必ずそろえてください。今回はどちらも「件/分」で統一し、最後にミリ秒へ変換しています。
A: 必ずそろえてください。今回はどちらも「件/分」で統一し、最後にミリ秒へ変換しています。
Q: M/M/1 以外のモデルを使ってはいけませんか?
A: 問題文に「M/M/1の待ち行列モデルによって評価することにした」と明記されているため、他モデルを用いると前提違反になります。
A: 問題文に「M/M/1の待ち行列モデルによって評価することにした」と明記されているため、他モデルを用いると前提違反になります。
Q: 系内平均時間 はどう求めるのですか?
A: です。今回の設問は のみを問うているので計算不要です。
A: です。今回の設問は のみを問うているので計算不要です。
関連キーワード: M/M/1, 到着率, サービス率, 待ち行列理論, 平均待ち時間
設問2:現在のZ社の情報提供システムについて、(1)〜(4)に答えよ。ただし、(1)は、整数で答えよ。(2)〜(4)は、小数第2位を四捨五入して小数第1位まで求めよ。
(4)平均応答時間Ts(ミリ秒)を求めよ。
模範解答
66.7
解説
解答の論理構成
-
入力情報の整理
- 【問題文】には「1分当たりのアクセス数は平均600件」とあります。
- 同じく「1アクセス当たりの平均処理時間Tpは40ミリ秒」とあります。
- 「M/M/1の待ち行列モデルによって評価する」と明示されています。
-
到着率 の算出
- 1分=60秒なので
- 1分=60秒なので
-
サービス率 の算出
- 平均処理時間
- よって
-
ρ(利用率)の計算
- なので定常状態が成立し、M/M/1 公式が利用できます。
-
平均応答時間 (待ち時間+サービス時間)の算出
- M/M/1 の平均応答時間は
- 数値を代入すると
- 秒をミリ秒に変換
- 指示のとおり「小数第2位を四捨五入して小数第1位」へ
- M/M/1 の平均応答時間は
-
結論
- 平均応答時間 は 66.7ミリ秒 になります。
誤りやすいポイント
- 「600件」をそのまま に使い、1分と60秒の換算を忘れる。
- 「40ミリ秒」を 0.04 秒に直さず計算し、サービス率 を誤る。
- M/M/1 の応答時間公式を ではなく と勘違いする。
- 最後の単位変換(秒→ミリ秒)や四捨五入の桁を誤って解答値がずれる。
FAQ
Q: “平均待ち時間”と“平均応答時間”は同じですか?
A: M/M/1 で“平均応答時間”は「待ち時間+サービス時間」の合計です。本問は公式 を用いるため、すでにサービス時間を含む値として算出できます。
A: M/M/1 で“平均応答時間”は「待ち時間+サービス時間」の合計です。本問は公式 を用いるため、すでにサービス時間を含む値として算出できます。
Q: 利用率 が 1 に近いとどうなりますか?
A: の分母が小さくなるため、応答時間が急激に増大します。 は 0.7 前後を超えると性能劣化が顕著になることが多いです。
A: の分母が小さくなるため、応答時間が急激に増大します。 は 0.7 前後を超えると性能劣化が顕著になることが多いです。
Q: なぜ M/M/1 を選んでよいのですか?
A: 【問題文】で「アクセス頻度はおおむね a 分布に、処理時間はおおむね b 分布に従っていた」とあり、これがポアソン到着・指数分布サービスであると読み取れるためです。
A: 【問題文】で「アクセス頻度はおおむね a 分布に、処理時間はおおむね b 分布に従っていた」とあり、これがポアソン到着・指数分布サービスであると読み取れるためです。
関連キーワード: M/M/1待ち行列, 到着率, サービス率, 利用率
設問3:〔システム構成の見直し〕の下線①の対処として、次の(1)、(2)のそれぞれに該当する具体的方策を解答群の中からすべて選び、記号で答えよ。
(1)情報提供システムへのアクセスをすべて受け付ける対処
模範解答
ウ、エ
解説
解答の論理構成
- 現状把握
- 【問題文】には「1分当たりのアクセス数は平均600件、1アクセス当たりの平均処理時間Tpは40ミリ秒」とあります。
- M/M/1 モデルでは到着率 とサービス率 の比 が 1 に近づくと待ち時間が急増します。
- ボトルネックの発生箇所
- 下線①には「アクセス数が一定数を超過すると、Webサーバが高負荷状態となり、待ち時間が長くなる」と記載されています。
- つまりアクセスを拒否せずに“すべて受け付ける”ためには、Web サーバの処理能力か同時処理数を増やす施策が必要です。
- 選択肢の整理
- 解答群のうち、アクセスを減らしたり間引いたりする方法は下線①の要件と逆方向です。
- 残った「ウ」「エ」はいずれも“サービス率 を向上させる”か“並列化して を分散させる”施策となります。
- 結論
- よって「情報提供システムへのアクセスをすべて受け付ける対処」に該当するのは【模範解答】どおり「ウ、エ」です。
誤りやすいポイント
- “待ち時間を短くする”=“到着数を制限する”と早合点してしまう
→ 下線①は「アクセスを拒否しない」前提なので制限系の選択肢は不適切です。 - DBサーバを強化すれば良いと考える
→ 【問題文】で「DBサーバについては、性能的に十分な余裕があり」と明言されており、効果はありません。 - ラウンドロビン方式の変更を①に絡めてしまう
→ 負荷分散方式の再検討は下線②・③の話であり、①の問いとは別です。
FAQ
Q: アクセス制御(接続数上限など)を入れればサーバは守れませんか?
A: 守れますが“アクセスをすべて受け付ける”という①の条件に反します。今回の設問では処理能力拡大が優先です。
A: 守れますが“アクセスをすべて受け付ける”という①の条件に反します。今回の設問では処理能力拡大が優先です。
Q: DBサーバのキャッシュ導入は効果がありますか?
A: 【問題文】で「性能的に十分な余裕があり」とあるため、DB 側を改善してもボトルネックは解消しません。
A: 【問題文】で「性能的に十分な余裕があり」とあるため、DB 側を改善してもボトルネックは解消しません。
Q: 既に Webサーバを「3台」に増設したのになぜさらに対処が必要なのですか?
A: アクセス増加は継続し、将来到着率 が 3 台の合計サービス率を再び上回る恐れがあるためです。
A: アクセス増加は継続し、将来到着率 が 3 台の合計サービス率を再び上回る恐れがあるためです。
関連キーワード: スケールアウト, サービス率, ラウンドロビン, ボトルネック
設問3:〔システム構成の見直し〕の下線①の対処として、次の(1)、(2)のそれぞれに該当する具体的方策を解答群の中からすべて選び、記号で答えよ。
(2)情報提供システムへのアクセスのうち同時に受け付ける数を制限する対処
解答群
ア:Webサーバの故障を検出し、故障していないWebサーバへ振り分ける。
イ:Webサーバへの通信用バッファを大きくする。
ウ:現行Webサーバと同等の処理能力をもつWebサーバを増設する。
エ:現行Webサーバより高い処理能力をもつWebサーバに取り替える。
オ:“混雑しているので後ほどアクセスしてください”と表示する装置を設置する。
模範解答
オ
解説
解答の論理構成
-
課題の把握
【問題文】には「①アクセス数が一定数を超過すると、Webサーバが高負荷状態となり、待ち時間が長くなる」とあります。したがって“同時に受け付ける数”を意図的に制限し、これ以上負荷が上がらないようにする仕組みが必要です。 -
求められる対処の特徴
- 受付可能な上限を超えたアクセスには速やかに“制限中”であることを伝える
- これによりWebサーバへのキュー長を抑え、待ち時間の悪化を防止
-
解答群との照合
• ア:故障時のフェイルオーバーであり、同時受付数の制限とは無関係
• イ:バッファ拡大は逆に同時接続を増やす方向で、制限にならない
• ウ:サーバ増設は同時受付数を“増やす”対策
• エ:高性能化も“増やす”対策
• オ:「“混雑しているので後ほどアクセスしてください”と表示する装置を設置する」──受付上限を超えた利用者にエラーメッセージを返し、負荷をコントロールする典型的な“入口制御(Admission Control)”です -
結論
「同時に受け付ける数を制限する対処」に該当するのは解答群「オ」のみです。
誤りやすいポイント
- 「Webサーバを増やせば同時受付数の問題は解決する」と短絡的に考えてしまう
- バッファ拡大=性能向上と誤認し、待ち行列が長くなってレスポンスが悪化するリスクを見落とす
- フェイルオーバと入口制御を混同し、“故障対応”と“過負荷対応”を区別できない
FAQ
Q: バッファを大きくするのはなぜ逆効果になる場合があるのですか?
A: 受付済みのリクエストがバッファに溜まるだけで、Webサーバの処理能力は向上しません。結果として待ち行列が長くなり、ユーザの待ち時間が延びます。
A: 受付済みのリクエストがバッファに溜まるだけで、Webサーバの処理能力は向上しません。結果として待ち行列が長くなり、ユーザの待ち時間が延びます。
Q: サーバ増設や高性能化ではだめなのでしょうか?
A: もちろん有効な場合もありますが、本設問は「同時に受け付ける数を制限」する具体策を問うています。サーバを増やすのは制限ではなく拡張です。
A: もちろん有効な場合もありますが、本設問は「同時に受け付ける数を制限」する具体策を問うています。サーバを増やすのは制限ではなく拡張です。
Q: 入口制御を行う装置は具体的に何ですか?
A: リバースプロキシやロードバランサの機能として実装するケースが一般的です。HTTP 503など適切なステータスコードで“混雑”を通知します。
A: リバースプロキシやロードバランサの機能として実装するケースが一般的です。HTTP 503など適切なステータスコードで“混雑”を通知します。
関連キーワード: 入口制御, 待ち行列理論, Admission Control, 過負荷防止
設問4:〔新サービスの追加〕について、(1)、(2)に答えよ。
(1)本文中の下線②について、なぜそのような問題が発生するのか。その原因について、50字以内で述べよ。
模範解答
特定のWebサーバに新サービスの処理が集中した場合に、待ち時間が長くなることがある。
解説
解答の論理構成
- 新サービス導入で処理負荷増
【問題文】では「Webサーバが DBサーバから取得して PCへ送信する、1 アクセス当たりのデータ量が増加するので、Webサーバでの CPU 処理時間も増加する」とあり、従来より 1 リクエスト当たりの処理時間が長くなります。 - 依然として「ラウンドロビン方式」を使用
「Z 社では、負荷分散方式としては、設定の容易なラウンドロビン方式を採用する」と記載されています。ラウンドロビンはアクセスを順番に振り分けるだけで、各 Web サーバの瞬間的な負荷を考慮しません。 - 同時アクセス時の集中発生
下線②には「複数の利用者がほぼ同時にアクセスしているとき、同じサービスを要求した利用者同士で応答時間に大きなばらつきが生じ」とあります。同時に届いた複数の“重い”リクエストが、順序上たまたま同じ Web サーバへ偏る可能性があります。 - 待ち時間増大のメカニズム
偏ったサーバではキューが伸び、M/M/1 モデルの待ち行列理論より平均待ち時間 が急増します。他サーバは空いていても、集中した 1 台で処理遅延が発生し、トランザクション全体の平均待ち時間が目標値「40ミリ秒」を超えることになります。 - したがって原因は「ラウンドロビンが瞬間的な負荷を無視するため、重い新サービスが特定サーバに集中し、そのサーバだけ待ち時間が長くなる」ことです。
誤りやすいポイント
- 「ラウンドロビン=均等負荷」と早合点し、瞬間的な偏りが起きうることを見落とす。
- ボトルネックを DB サーバと決めつける。本文に「性能的に十分な余裕があり」とあり、原因は Web サーバ側です。
- 「平均待ち時間が目標値を超える」のはアクセス総量の増加だけと思い込む。実際はリクエストの“重さ”と偏りが主因です。
FAQ
Q: ラウンドロビン方式は常に公平に負荷を分散できるのでは?
A: 順序は公平でも、リクエストの処理時間が異なると“仕事量”は均等化されません。同時到着した重いリクエストが同じサーバに割り当てられると待ち行列が伸びます。
A: 順序は公平でも、リクエストの処理時間が異なると“仕事量”は均等化されません。同時到着した重いリクエストが同じサーバに割り当てられると待ち行列が伸びます。
Q: 加重ラウンドロビン方式に切り替えれば解決しますか?
A: 重いリクエストの発生頻度や重さが一定であれば効果があります。しかし瞬間的な負荷を見ながら振り分ける「最小負荷方式」などの方が待ち時間ばらつきを抑えやすいです。
A: 重いリクエストの発生頻度や重さが一定であれば効果があります。しかし瞬間的な負荷を見ながら振り分ける「最小負荷方式」などの方が待ち時間ばらつきを抑えやすいです。
Q: DB サーバが余裕なら Web サーバを増やせば良いのでは?
A: 台数増加は効果がありますが、ラウンドロビンのままでは偏り問題が残ります。負荷の“監視機能”を持つ方式と組み合わせるのが合理的です。
A: 台数増加は効果がありますが、ラウンドロビンのままでは偏り問題が残ります。負荷の“監視機能”を持つ方式と組み合わせるのが合理的です。
関連キーワード: 待ち行列, ラウンドロビン, 負荷分散, CPU使用率, リクエスト集中
設問4:〔新サービスの追加〕について、(1)、(2)に答えよ。
(2)本文中の下線③について、どの負荷分散方式を設定することが適切か。本文中の負荷分散方式から二つ選び、(i)〜(v)の番号で答えよ。
模範解答
(iv)、(v)
解説
解答の論理構成
-
問題の前提確認
本文では、見直し後に「②複数の利用者がほぼ同時にアクセスしているとき、同じサービスを要求した利用者同士で応答時間に大きなばらつきが生じ、平均待ち時間が目標値を超える場合がある」とあります。ばらつきの主因は、Webサーバごとに CPU 使用率・データ送出量が偏ることです。
さらに「Webサーバが DBサーバから取得して PCへ送信する、1 アクセス当たりのデータ量が増加するので、Webサーバでの CPU 処理時間も増加する」とされ、ボトルネックは Webサーバ側に集中すると分かります。 -
ラウンドロビン方式が不適切な理由
ラウンドロビンは「あらかじめ決めた順序で各 Webサーバにアクセスを振り分ける」だけで、リアルタイムの負荷状況を考慮しません。そのため一時的に負荷が偏り、応答時間の「大きなばらつき」が発生します。 -
適切な負荷分散方式の選定
新サービスでは
・CPU 処理が重い
・送出データ量が多い
という二つの負荷要因が同時に増えています。よって動的に “今軽いサーバ” を選ぶアルゴリズムが必要です。本文が示す選択肢から該当するのは次の二つです。
• 「(ⅳ) 最少データ通信量方式:データ通信量が最も少ない Webサーバにアクセスを振り分ける。」
• 「(ⅴ) 最小負荷方式:CPU 使用率が最も低い Webサーバにアクセスを振り分ける。」
これらは実負荷メトリクス(通信量・CPU 使用率)を監視しながら振り分けるため、偏りの早期検知と是正が可能です。データ量が増しても、CPU が上がっても、いずれかの指標で“軽い”サーバに新規アクセスを送ることで待ち時間の均等化と平均待ち時間の低減が見込めます。 -
他方式が不適切な理由
• 「(ⅰ) ラウンドロビン方式」…負荷を見ないので同じ問題が再発。
• 「(ⅱ) 加重ラウンドロビン方式」…サーバ性能が同等と明記されているため重みは全て同じ、結果は(ⅰ)と同じ。
• 「(ⅲ) 最少クライアント数方式」…同時接続数が少なくても通信量や CPU 使用率が高い場合があり、今回の負荷特性を直接反映しない。 -
結論
以上より本文の下線③で採用すべき負荷分散方式は「(ⅳ) 最少データ通信量方式」と「(ⅴ) 最小負荷方式」です。模範解答「(iv)、(v)」と一致します。
誤りやすいポイント
- 「加重ラウンドロビン=動的」と早合点する
実際は静的重み付けのため同性能サーバでは効果なし。 - 「最少クライアント数=最少通信量」と誤認する
ストリーミングや大容量送信では“1クライアント=大負荷”のケースがある。 - DBサーバが余裕とあるのに DB 側の負荷分散を考え始める
問題文に「性能的に十分な余裕があり、システム全体の性能に影響を与えることはない」と明記されている。
FAQ
Q: 加重ラウンドロビンに重みを動的に変えれば良いのでは?
A: 問題文の選択肢「(ii) 加重ラウンドロビン方式」は“処理能力に応じて”静的に決める方式として提示されています。処理能力が同等の3台では重みは同じになり、動的負荷平準化は行われません。
A: 問題文の選択肢「(ii) 加重ラウンドロビン方式」は“処理能力に応じて”静的に決める方式として提示されています。処理能力が同等の3台では重みは同じになり、動的負荷平準化は行われません。
Q: 最少クライアント数方式が負荷を見ているように感じますが?
A: “接続中のクライアント数”のみを見るため、大容量データを送信中の1クライアントとアイドル状態の1クライアントを区別できません。通信量や CPU 使用率が直接のボトルネックとなる今回の状況に対しては十分ではありません。
A: “接続中のクライアント数”のみを見るため、大容量データを送信中の1クライアントとアイドル状態の1クライアントを区別できません。通信量や CPU 使用率が直接のボトルネックとなる今回の状況に対しては十分ではありません。
Q: 2種類を同時に採用するのですか?
A: 現実の製品では複数指標を組み合わせることも可能ですが、設問は「本文中の負荷分散方式から二つ選び」と指定しています。したがって、通信量に基づく「(ⅳ)」と CPU 使用率に基づく「(ⅴ)」の2方式を選択するのが適切です。
A: 現実の製品では複数指標を組み合わせることも可能ですが、設問は「本文中の負荷分散方式から二つ選び」と指定しています。したがって、通信量に基づく「(ⅳ)」と CPU 使用率に基づく「(ⅴ)」の2方式を選択するのが適切です。
関連キーワード: 負荷分散, 待ち行列モデル, CPU使用率, トラフィック分散
