応用情報技術者 2013年 秋期 午後 問02
リストによるメモリ管理に関する次の記述を読んで、設問1~3に答えよ。
与えられたメモリ空間(以下、ヒープ領域という)の中に、可変長のメモリブロックを動的に割り当てるためのデータ構造及びアルゴリズムを考える。
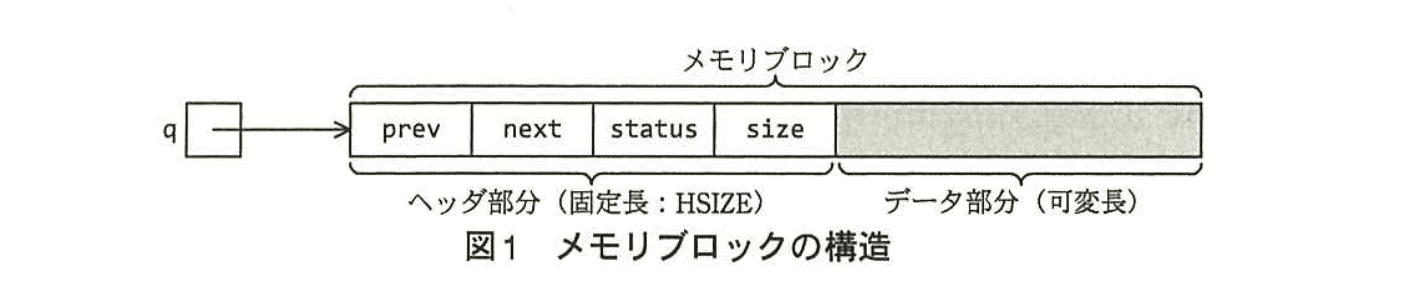
ヒープ領域は、一つ以上の連続したメモリブロックで構成する。メモリブロックは、固定長のヘッダ部分と可変長のデータ部分で構成される。ヘッダ部分は構造体で、prev, next, status 及び size のメンバによって構成される。メモリブロックの構造を図1に、ヘッダ部分のメンバの意味を表1にそれぞれ示す。メモリブロックを指すポインタ変数には、メモリブロックの先頭アドレスをセットする。あるメモリブロックを指すポインタ変数を q とするとき、そのメンバ prev の参照は、q->prev と表記する。また、ヘッダ部分のバイト数は、HSIZE とする。

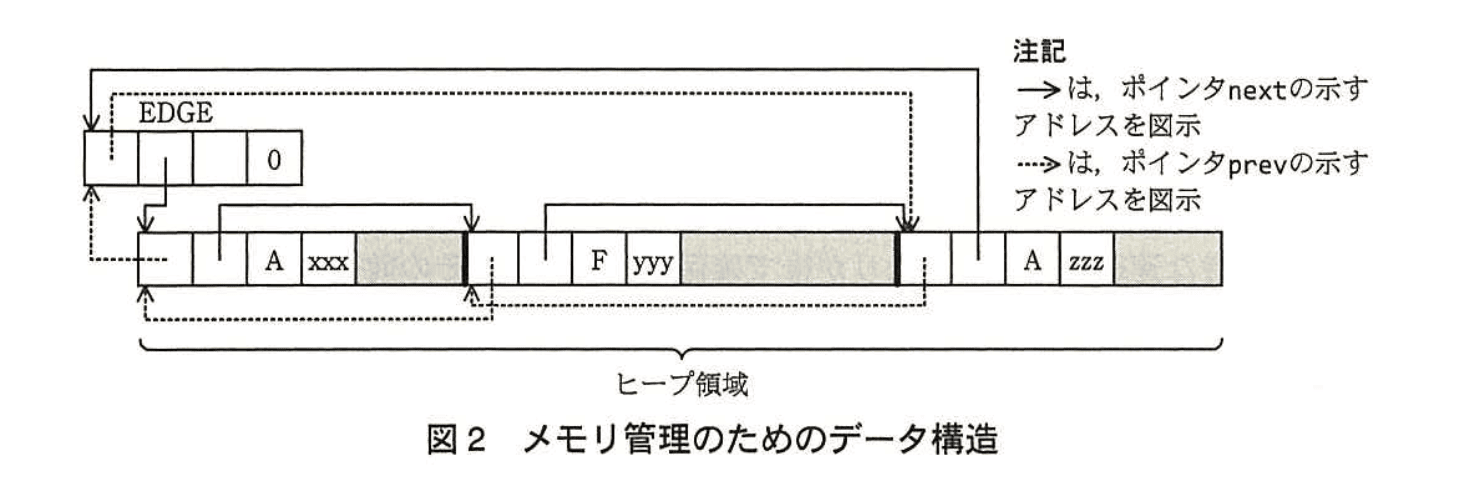
ヘッダ部分と同じ構造体の変数 EDGE をヒープ領域の外に定義する。そのメンバ prev 及び next には、それぞれヒープ領域の最後尾及び先頭のメモリブロックの先頭アドレスをセットする。ヒープ領域の先頭のメモリブロックのメンバ prev と最後尾のメモリブロックのメンバ next には、ともに EDGE の先頭アドレスをセットする。これによって、EDGE を含むメモリブロックが双方向の循環リストを構成する。EDGE にはデータ部分はなく、メンバ size には 0 が設定されている。データ構造の全体像を図2に示す。
〔メモリ割当ての関数〕
メモリ割当ての関数は、割り当てたいバイト数(msize)を引数とし、そのバイト数以上の大きさのデータ部分をもつメモリブロックを、ヒープ領域から探索する。このアルゴリズムを次のように考えた。
(1) ポインタ変数qを定義し、初期値として変数EDGEのnextの値をセットする。
(2) qがアと等しい場合は、ヒープ領域には十分な空きメモリをもったメモリブロックが無かったことを意味する。関数の戻り値にNULLをセットして終了する。それ以外の場合は、次の(3)~(5)を実行する。
(3) q->イが'A'の場合、又はq->sizeがmsize未満である場合は、qにq->ウをセットして(2)に戻る。
(4) q->sizeがHSIZE+msize以下の場合は、q->イに'A'をセットし、関数の戻り値にqの値をセットして終了する。
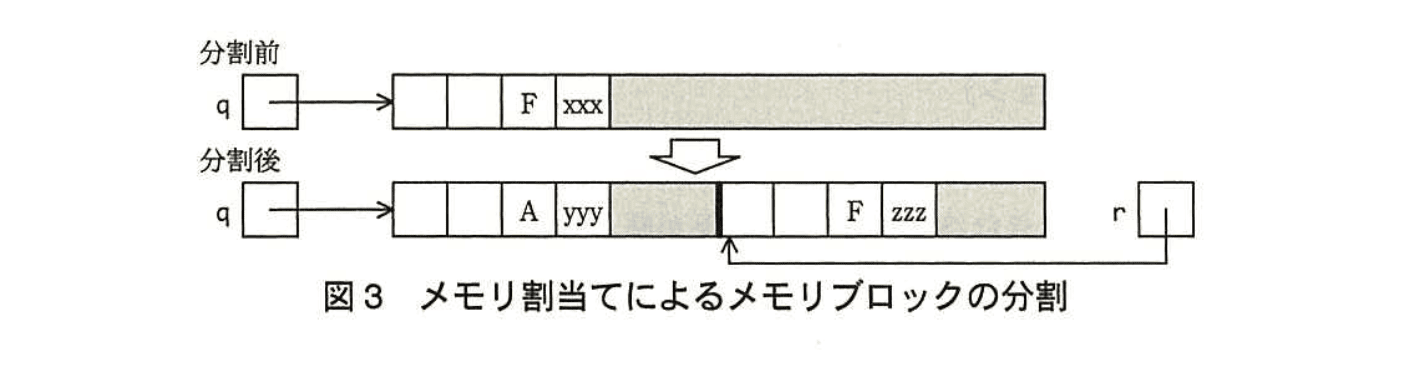
(5) q->sizeがHSIZE+msizeよりも大きい場合は、そのメモリブロックを割当て済みのメモリブロックと、残りの空きメモリブロックの二つに分割する(図3参照)。ポインタ変数rを定義し、初期値としてq+HSIZE+msizeをセットする。q->イに'A'をセットし、r->イに'F'をセットする。r->sizeにq->size-HSIZE-msizeをセットし、q->sizeにmsizeをセットする。r->prevにはエを、r->nextにはオを、q->next->prevにはrを、q->nextにはrを順にセットする。関数の戻り値にqの値をセットして終了する。
〔メモリ解放の関数〕
メモリ解放の関数 freemem は、解放したいメモリブロックの先頭アドレスを引数とし、そのメモリブロックを空きメモリブロックの状態に変更する。このとき、できるだけ大きな連続した空きメモリが後で確保できるよう、その前後のメモリブロックも空きメモリブロックかどうかを確認する。空きメモリブロックが連続する場合には、それらをまとめて一つの空きメモリブロックにする。
関数 freemem のプログラムを図4に示す。この関数を正しく動作させるためには、変数 EDGE のメンバ status の値はカである必要がある。

〔メモリコンパクション〕
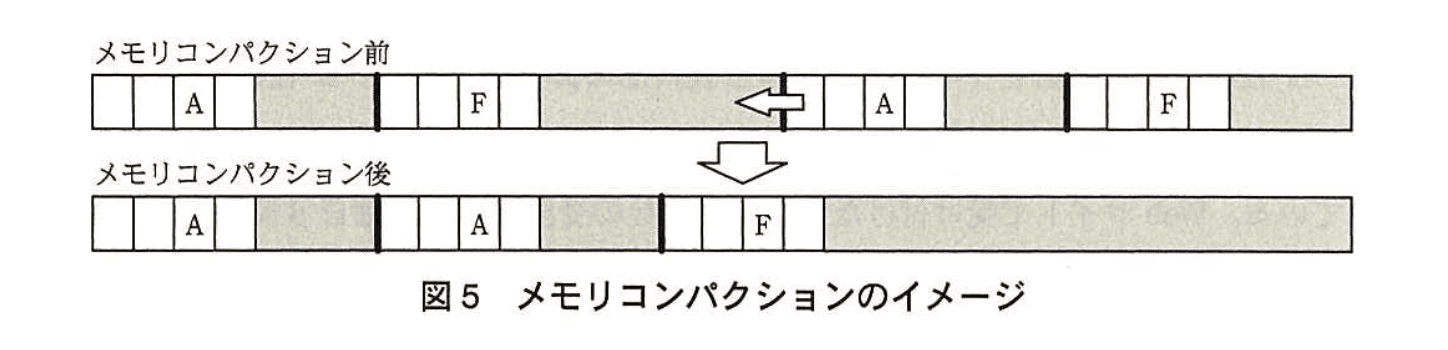
メモリの確保や解放の処理を繰り返すと、サイズの小さな空きメモリが分散してしまい、サイズの大きな空きメモリの確保が難しくなることがある。このような現象をコと呼ぶ。このとき、割当て済みのメモリブロックが連続するようにメモリブロックを移動し、移動したメモリブロックの後ろに大きな空きメモリを確保することをメモリコンパクションという(図5参照)。
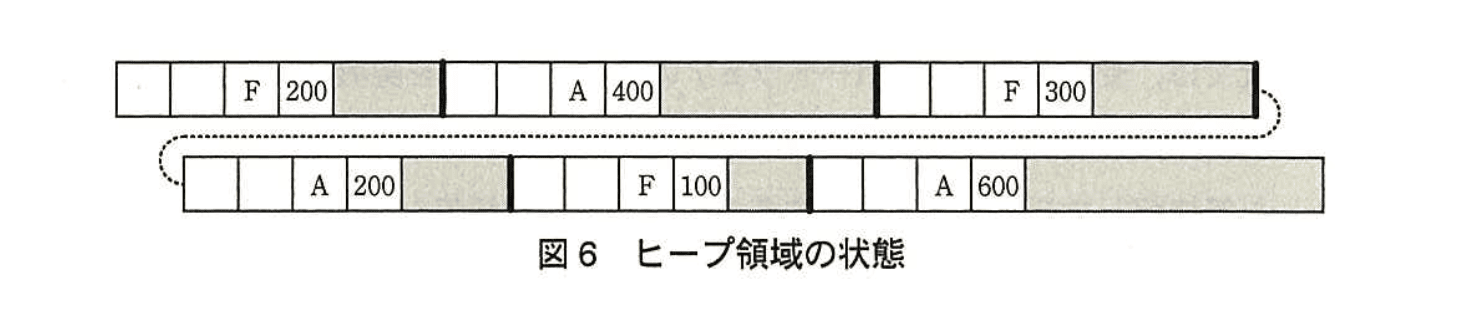
ヒープ領域が図6のように左上から右下にかけて連続する構成の場合、メモリコンパクションを実行すると、サバイトの空きメモリができる。
メモリコンパクションを実行すると、①メモリコンパクション前に実行したメモリ割当て関数の戻り値は、メモリ解放の関数の引数としては使えなくなる場合がある。Dさんが作成したコンテナイメージの一覧を表1に示す。
設問1:〔メモリ割当ての関数〕について、(1)、(2)に答えよ。
(1)本文中のア〜ウを用いて答えよ。
模範解答
ア:EDGEの先頭アドレス
イ:status
ウ:next
解説
解答の論理構成
-
循環リストの基準点
問題文には「EDGE を含むメモリブロックが双方向の循環リストを構成する。」とあり、さらに探索手順(1)で「変数 EDGE の next の値をセットする」と示されています。探索が一巡して元に戻ったことを検知するためには、q をセンチネルである「EDGE の先頭アドレス」と比較するしかありません。したがって
- ア=EDGEの先頭アドレス -
空き/使用中判定に使うメンバ
手順(3)では「q->イが'A'の場合、又は…」と記述されています。表1にはメンバ status の意味として「'A':データ部分は割当て済みメモリである。'F':データ部分は空きメモリである。」と明記されており、'A' を保持するフィールドは status です。したがって
- イ=status -
次のブロックへの移動
探索継続は「q に q->ウをセットして(2)に戻る」と説明されています。双方向リストで前へ進むときは next ポインタを参照しますから
- ウ=next
以上より、模範解答は
ア:EDGEの先頭アドレス イ:status ウ:next となります。
ア:EDGEの先頭アドレス イ:status ウ:next となります。
誤りやすいポイント
- prev と next の混同
循環リストで戻る方向も存在するため、先頭から順に走査する場合は next が正解です。 - センチネルに NULL を想定
本問題では「EDGE によって…双方向の循環リストを構成する」とあるため、終端は NULL ではなく「EDGE の先頭アドレス」です。 - 'A'/'F' を格納するフィールド名の誤記
表1に明示されているように 'A' と 'F' を保持するのは status であって size でも prev でもありません。
FAQ
Q: なぜ循環リスト(センチネル)を使うのですか?
A: 先頭や末尾のブロックでも同じロジックで走査・挿入・削除が行え、リストの終端判定が「EDGE に戻ったかどうか」だけで済むため、分枝が減り実装が簡潔になります。
A: 先頭や末尾のブロックでも同じロジックで走査・挿入・削除が行え、リストの終端判定が「EDGE に戻ったかどうか」だけで済むため、分枝が減り実装が簡潔になります。
Q: status が 'A' であってもサイズが足りないブロックは飛ばすのですか?
A: はい。手順(3)で「q->status が 'A' または q->size < msize の場合に次へ進む」と二重条件で判定しています。空きブロックでもサイズ不足なら候補になりません。
A: はい。手順(3)で「q->status が 'A' または q->size < msize の場合に次へ進む」と二重条件で判定しています。空きブロックでもサイズ不足なら候補になりません。
Q: prev だけで前方向の走査はできますか?
A: 技術的には可能ですが、前方向(アドレスの増加方向)に進むには next が自然です。本問題のアルゴリズムも next を使用しており、prev は主に逆方向処理や統合時に利用します。
A: 技術的には可能ですが、前方向(アドレスの増加方向)に進むには next が自然です。本問題のアルゴリズムも next を使用しており、prev は主に逆方向処理や統合時に利用します。
関連キーワード: 循環リスト、センチネルノード、動的メモリ割当て、ダブルリンクリスト
設問1:〔メモリ割当ての関数〕について、(1)、(2)に答えよ。
(2)本文中のエ、オに入れる適切な字句を、ポインタ変数qを用いて答えよ。
模範解答
エ:q
オ:q → next
解説
解答の論理構成
-
分割の場面
本文(5)には「そのメモリブロックを割当て済みのメモリブロックと、残りの空きメモリブロックの二つに分割する」とあります。分割前にポインタ変数 q が指すブロックと q->next が指す後続ブロックが双方向リストで連結されています。 -
新ブロック r の位置関係
生成する r は「q+HSIZE+msize」を先頭アドレスとするので、物理的には q の直後、q->next の直前に挿入されます。したがって
• r の直前ブロック → q
• r の直後ブロック → q->next -
ヘッダの整合性
本文の指示は次の通りです。
「r->prevにはエを、r->nextにはオを、q->next->prevにはrを、q->nextにはrを順にセットする。」
双方向循環リストの整合性を保つには
• r->prev が q を指すことで、後方リンクが確立
• r->next が q->next を指すことで、前方リンクが確立
• その後 q->next->prev と q->next を更新し、リストが切れ目なくつながる -
以上より
エ= q
オ= q->next
誤りやすいポイント
- r->next に q を設定してしまう
→ これでは自分の後ろが自分になるループが発生します。 - q->next の更新順序を誤る
→ 先に q->next を書き換えると、元の後続ブロックのポインタが失われ復旧不能になります。 - prev と next の役割混同
→ 物理メモリ順とリンクリスト順が一致していると錯覚しやすいので要注意です。
FAQ
Q: 分割後に q->size を変更するのはなぜですか?
A: 本文(5)にある通り「q->sizeにmsizeをセットする」ことで、q が要求サイズだけを保持し、余った領域を新ブロック r に譲るためです。
A: 本文(5)にある通り「q->sizeにmsizeをセットする」ことで、q が要求サイズだけを保持し、余った領域を新ブロック r に譲るためです。
Q: 循環リストである利点は何ですか?
A: 先頭・末尾判定が不要になり、EDGE から一周すれば全ブロックを走査できます。
A: 先頭・末尾判定が不要になり、EDGE から一周すれば全ブロックを走査できます。
Q: EDGE の size が必ず 0 である理由は?
A: データ部分を持たない番兵ノードなので、誤ってユーザに割り当てられないように固定値 0 にしています。
A: データ部分を持たない番兵ノードなので、誤ってユーザに割り当てられないように固定値 0 にしています。
関連キーワード: 双方向循環リスト、ヒープ領域、メモリブロック、ポインタ操作、分割アルゴリズム
設問2:〔メモリ解放の関数〕について、(1)、(2)に答えよ。
(1)本文中のカに入れる適切な字句を答えよ。
模範解答
カ:'A'
解説
解答の論理構成
-
図2の説明より
「ヒープ領域の先頭のメモリブロックのメンバ prev と最後尾のメモリブロックのメンバ next には、ともに EDGE の先頭アドレスをセットする。これによって、EDGE を含むメモリブロックが双方向の循環リストを構成する。」
つまり EDGE はヒープ外にあるダミーノードであり、リストの番兵(sentinel)として機能します。 -
図4の freemem では、解放対象 q の前後ブロックの状態を
if (p->status が 'F' と等しい)
if (r->status が 'F' と等しい)
で判定し、空き ('F') なら連結・サイズ加算を行います。 -
解放対象がヒープの先頭ブロックの場合、p は EDGE を指します。
もし EDGE->status が 'F' なら、freemem は EDGE を通常の空きブロックとみなし、p->next ← r->next p->size ← ... p->next->prev ← pの処理で EDGE をヒープ内ブロックと誤認してしまいます。
これはダミーノードを破壊し、リストが壊れる原因になります。 -
一方 EDGE->status を 'A' にしておけば、上記の if 文は成立せず、else // 前が割当て済み ... q->status ← 'F'が選択され、EDGE は併合対象になりません。
従って「この関数を正しく動作させるためには、変数 EDGE のメンバ status の値はカである必要がある。」の カ には 'A' が入ります。
誤りやすいポイント
- EDGE もヒープ領域と誤解し、'F' を入れてしまう
→ 先頭ブロック解放時に番兵が結合され、循環リストが崩壊します。 - 「ダミーノードにデータ部がない=空き」と短絡的に判断してしまう
→ ヘッダの役割(リストの境界識別)を見落とす典型例です。 - freemem の if‐else ネストを追い切れず、番兵の扱いを確認せずに答えを決める
→ ポインタ更新先を紙に書き出して追跡するクセを付けましょう。
FAQ
Q: EDGE->status を 'A' にしてもデータ部分が無いのは矛盾しませんか?
A: 本アルゴリズムでは 'A'/'F' は「結合対象か否か」を示すフラグです。EDGE は結合対象外にしたいだけなのでサイズ 0 のまま 'A' で問題ありません。
A: 本アルゴリズムでは 'A'/'F' は「結合対象か否か」を示すフラグです。EDGE は結合対象外にしたいだけなのでサイズ 0 のまま 'A' で問題ありません。
Q: 'A' 以外に特別なマーク(例:'E')を設けても良いですか?
A: 可能ですが、ソース全体に新しい状態を認識させる修正が必要です。既存の 'A'/'F' だけで済むなら設計・実装コストを抑えられます。
A: 可能ですが、ソース全体に新しい状態を認識させる修正が必要です。既存の 'A'/'F' だけで済むなら設計・実装コストを抑えられます。
Q: 末尾ブロックを解放するときも EDGE は安全ですか?
A: はい。末尾ブロックでは r が EDGE を指しますが、EDGE->status が 'A' のため併合は発生せず、番兵は保持されます。
A: はい。末尾ブロックでは r が EDGE を指しますが、EDGE->status が 'A' のため併合は発生せず、番兵は保持されます。
関連キーワード: ダミーノード、循環リンクリスト、空きブロック結合、旗ビット、境界条件
設問2:〔メモリ解放の関数〕について、(1)、(2)に答えよ。
(2)図4中のキ〜ケに入れる適切な字句を答えよ。
模範解答
キ:p → size + q → size + r → size + 2*HSIZE
ク:p
ケ:q → size + r → size + HSIZE
解説
解答の論理構成
- 図4先頭で
p ← q->prev、r ← q->next とポインタを取得し、 if (p->status が 'F' と等しい) で前ブロック p が空き ('F') か判定しています。 - p と r の両方が空きの場合には
p->next ← r->next で 3 つのブロックをまとめ、続けて
p->size ← キ と書き換えてサイズを再計算します。
3 ブロックのデータ部分サイズは
p->size + q->size + r->size、 さらに削除される 2 個のヘッダ(q と r)の分 2HSIZE を加えるので
キ は
**「p → size + q → size + r → size + 2HSIZE」**
となります。 - つなぎ替え後は “次ブロックの prev も更新” というコメントに対応して
p->next->prev ← ク が実行されます。
ここで p->next は r->next(p が先頭)なので、 prev に入れるのは新しい先頭ブロック p です。
よって ク は 「p」 です。 - else 節では前が割当て済み (p は 'A') で、後ろ r が空きの場合に
q->next ← r->next で 2 ブロックを連結し、 q->size ← ケ でサイズを更新します。
データ部分は q->size + r->size、 削除されるヘッダは r 1 個なので +HSIZE、 よって ケ は
「q → size + r → size + HSIZE」 です。
誤りやすいポイント
- ヘッダのサイズ HSIZE を「残すヘッダ」ではなく「消えるヘッダ」の数で数える点を忘れやすいです。
- p->next->prev の更新先を q と早合点しがちですが、両隣が空きのときはリスト先頭が p へ変わるため p をセットします。
- 片側だけ空きの場合と両側空きの場合で、加算する HSIZE の係数が異なることに注意が必要です。
FAQ
Q: 2 つの空きブロックをまとめるときに +HSIZE が 1 個になるのはなぜですか?
A: 結合時に不要になるのは “境界にある一方のヘッダ” だけだからです。結合後は先頭側のヘッダが残り、間にあったヘッダ 1 個分 HSIZE が不要になります。
A: 結合時に不要になるのは “境界にある一方のヘッダ” だけだからです。結合後は先頭側のヘッダが残り、間にあったヘッダ 1 個分 HSIZE が不要になります。
Q: p->size の更新式に元の p->size を含める理由は?
A: p のデータ部分はそのまま残るため、結合後の総サイズに元の p->size も加算しなければ実際より小さく計上してしまうからです。
A: p のデータ部分はそのまま残るため、結合後の総サイズに元の p->size も加算しなければ実際より小さく計上してしまうからです。
Q: EDGE の status を 'F' にしておく必要性は?
A: freemem が隣接ブロックの status を参照する際、番兵として機能させるためです。'F' なら誤って EDGE を割当て済みと判定せず、境界条件処理が簡潔になります。
A: freemem が隣接ブロックの status を参照する際、番兵として機能させるためです。'F' なら誤って EDGE を割当て済みと判定せず、境界条件処理が簡潔になります。
関連キーワード: ダブルリンクリスト、動的メモリ確保、ガベージコレクション、メモリフラグメンテーション、ブロック統合
設問3:〔メモリコンパクション〕について、(1)〜(3)に答えよ。
(1)本文中のコに入れる適切な字句をカタカナで答えよ。
模範解答
コ:フラグメンテーション
解説
解答の論理構成
-
問題文では次のように状況と用語を提示しています。「メモリの確保や解放の処理を繰り返すと、サイズの小さな空きメモリが分散してしまい、サイズの大きな空きメモリの確保が難しくなることがある。このような現象をコと呼ぶ。」
-
キーワードは「サイズの小さな空きメモリが分散」「サイズの大きな空きメモリの確保が難しくなる」。
これはヒープ領域に細切れの空き領域が点在し、連続領域が不足する典型的な問題の説明です。 -
動的メモリ管理分野で、細切れの空き領域が散在してしまう現象は一般に「フラグメンテーション(fragmentation)」と呼びます。
内部・外部に大別されますが、問題文が述べる「空きメモリが分散」は外部フラグメンテーションの典型です。 -
以上より、コ に入る語は 「フラグメンテーション」 が妥当です。
誤りやすいポイント
- 「メモリコンパクション」と混同
コンパクションはフラグメンテーションを解消する手段であって現象名ではありません。 - 「デフラグメンテーション」と誤記
デフラグはフラグメンテーションを直す操作を指す用語であり、空き領域が散在する状態そのものを示しません。 - 内部/外部の区別が頭に浮かび、設問がどちらかを問うと誤解
設問は現象の総称を聞いているため、どちらにも共通する「フラグメンテーション」で解答します。
FAQ
Q: 「フラグメンテーション」と「メモリコンパクション」の違いは何ですか?
A: 「フラグメンテーション」は空き領域がバラバラになる“現象”で、「メモリコンパクション」はその現象を解消するために割当て済みブロックを詰め、大きな連続空き領域を作る“操作”です。
A: 「フラグメンテーション」は空き領域がバラバラになる“現象”で、「メモリコンパクション」はその現象を解消するために割当て済みブロックを詰め、大きな連続空き領域を作る“操作”です。
Q: 内部フラグメンテーションと外部フラグメンテーションを区別する必要はありますか?
A: 本設問では分散した空きメモリが問題になっているため外部フラグメンテーションの説明に近いですが、解答としては総称の「フラグメンテーション」で十分です。
A: 本設問では分散した空きメモリが問題になっているため外部フラグメンテーションの説明に近いですが、解答としては総称の「フラグメンテーション」で十分です。
Q: フラグメンテーションを完全に防ぐ方法はありますか?
A: 完全に防ぐことは難しく、ガーベジコレクションやメモリプール、メモリコンパクションなどの対策を組み合わせて影響を抑えます。
A: 完全に防ぐことは難しく、ガーベジコレクションやメモリプール、メモリコンパクションなどの対策を組み合わせて影響を抑えます。
関連キーワード: フラグメンテーション、メモリコンパクション、ヒープ領域、動的メモリ割り当て
設問3:〔メモリコンパクション〕について、(1)〜(3)に答えよ。
(2)本文中のサに入れる適切な式を答えよ。
模範解答
サ:2 × HSIZE + 600
解説
解答の論理構成
-
空きブロックの把握
図6に示されたヒープ領域には
・先頭の "F" 200
・中央の "F" 300
・末尾の "F" 100
の 3 つの空きメモリブロックが点在しています。
ここで 表1 にあるとおり size は「データ部分のバイト数」であり、ヘッダは含みません。 -
ヘッダの性質
問題文冒頭で
「メモリブロックは、固定長のヘッダ部分と可変長のデータ部分で構成される。…ヘッダ部分のバイト数は、HSIZE とする。」
と述べられています。したがって各ブロックごとに HSIZE バイトのヘッダが存在します。 -
メモリコンパクション後の状態
メモリコンパクションでは「割当て済みのメモリブロックが連続するようにメモリブロックを移動し、移動したメモリブロックの後ろに大きな空きメモリを確保」します。- 3 個の空きブロックは 1 か所にまとめられ、データ部分は 200 + 300 + 100 = 600 バイト。
- ヘッダは 3 個 → 1 個 に減るため、不要になるヘッダは 2 × HSIZE バイト。
-
まとめ
以上より、コンパクション後に連続して確保できる空き容量は
600(データ部分合計) + 2 × HSIZE(余剰ヘッダ分) バイトとなります。よって サ に入る式は
2 × HSIZE + 600 です。
誤りやすいポイント
- ヘッダサイズを加味せずに 600 だけを書いてしまう。
- 「まとめ後のブロックにもヘッダが 1 個残る」ことを忘れ、3 × HSIZE を足してしまう。
- 図6が 2 段に描かれているため「上下で別領域」と誤解し、空きブロックを 2 個と数えてしまう。
- size フィールドにヘッダ分が既に含まれていると勘違いする。
FAQ
Q: HSIZE の具体的な値が問題文にないのに式で答えるのはなぜですか?
A: 本問は「式」を求める設問です。ヘッダ長は実装依存のため定数 HSIZE のまま示すことが正解になります。
A: 本問は「式」を求める設問です。ヘッダ長は実装依存のため定数 HSIZE のまま示すことが正解になります。
Q: メモリコンパクションでヘッダが減る仕組みを一言で言うと?
A: 離散していた空きブロックを一つに統合する過程で、先頭 1 個だけヘッダを残し、残りのヘッダ領域をデータ領域に取り込むからです。
A: 離散していた空きブロックを一つに統合する過程で、先頭 1 個だけヘッダを残し、残りのヘッダ領域をデータ領域に取り込むからです。
Q: 割当て済みブロックの移動でポインタはどう更新されますか?
A: コンパクション時には各ブロックの prev・next だけでなく、そのブロックを指していたアプリ側ポインタも再設定する必要があります(本文の①が示す注意点)。
A: コンパクション時には各ブロックの prev・next だけでなく、そのブロックを指していたアプリ側ポインタも再設定する必要があります(本文の①が示す注意点)。
関連キーワード: メモリコンパクション、外部フラグメンテーション、可変長メモリ管理、ヒープ、ヘッダオーバヘッド
設問3:〔メモリコンパクション〕について、(1)〜(3)に答えよ。
(3)本文中の下線①の理由を25字以内で述べよ。
模範解答
メモリブロックの先頭アドレスが変わるから
解説
解答の論理構成
- 問題文には「①メモリコンパクション前に実行したメモリ割当て関数の戻り値は、メモリ解放の関数の引数としては使えなくなる場合がある」とあります。
- メモリコンパクションとは「割当て済みのメモリブロックが連続するようにメモリブロックを移動し、移動したメモリブロックの後ろに大きな空きメモリを確保する」操作です。
- 移動とは物理アドレス(実アドレス)を詰め直す処理を指し、ブロックの「先頭アドレス」が書き換わることを意味します。
- メモリ割当て関数の戻り値は割当て直後のブロック先頭アドレスです。コンパクションでそのアドレスが変化すると、以前取得したポインタはヒープ内の正しいブロックを指さなくなります。
- その結果、ポインタをそのまま freemem に渡すと誤動作や破壊的書込みを招くため、「使えなくなる場合がある」という警告が成立します。
- 以上より、理由は「メモリブロックの先頭アドレスが変わるから」となります。
誤りやすいポイント
- メモリコンパクション=ガーベジコレクションと早合点し、先頭アドレスの変更を意識しない。
- 仮想アドレス採用 OS ではアドレス固定と思い込み、本問題のような物理アドレス前提の実装を忘れる。
- 「戻り値が無効」=必ず NULL になると誤解し、ポインタ値自体は残ることを見落とす。
- コンパクション対象が空き領域だけだと勘違いし、割当て済みブロックが移動する事実を見落とす。
FAQ
Q: メモリコンパクション後にポインタを有効に保つ方法はありますか?
A: 移動前後でテーブルを更新するハンドル方式や、全ポインタを書き換える追跡ガーベジコレクション方式があります。
A: 移動前後でテーブルを更新するハンドル方式や、全ポインタを書き換える追跡ガーベジコレクション方式があります。
Q: コンパクションを行わない設計もありますか?
A: あります。固定サイズブロック方式やスラブアロケータなどは断片化を抑えつつコンパクションを不要にする設計です。
A: あります。固定サイズブロック方式やスラブアロケータなどは断片化を抑えつつコンパクションを不要にする設計です。
Q: 断片化とヒープ枯渇の関係は?
A: 断片化が進むと「空き容量は十分だが連続していない」状態となり、大きい要求を満たせずヒープ枯渇と同様のエラーを返すことがあります。
A: 断片化が進むと「空き容量は十分だが連続していない」状態となり、大きい要求を満たせずヒープ枯渇と同様のエラーを返すことがあります。
関連キーワード: メモリコンパクション、断片化、ポインタ、動的メモリ確保、ヒープ
