応用情報技術者 2013年 秋期 午後 問03
サーバ仮想化に関する次の記述を読んで、設問1~4に答えよ。
E社は、関東地区を中心に事業を営む食料品の卸業者である。E社の顧客はスーパーマーケットであり、E社のWebサイトで顧客からの注文を24時間365日受け付けている。Webサイトで受け付けた注文は、E社の受注担当者が毎日8時~18時の間に受注確認を行い、受注確認ができた注文の商品を翌日の7時に出荷している。
E社のシステムは、顧客からの注文を受け付ける受注システム、仕入先へ商品の発注を行う発注システム、従業員の給与計算を行う総務システムの三つの情報システムから成る。各情報システムは、アプリケーションサーバ(以下、APサーバという)とデータベースサーバ(以下、DBサーバという)から構成されている。三つの情報システムは、個別のハードウェアによって構成されており、サーバの保守費用が高くなっている。
E社では、受注システムのハードウェアの保守期間満了を契機に、サーバの保守費用の削減を目的として、仮想化技術によって三つの情報システムのハードウェアを統合した新情報システム基盤を構築することにした。新情報システム基盤の構築は、E社の情報システム部のF君が担当することになった。
〔現行情報システムの構成〕
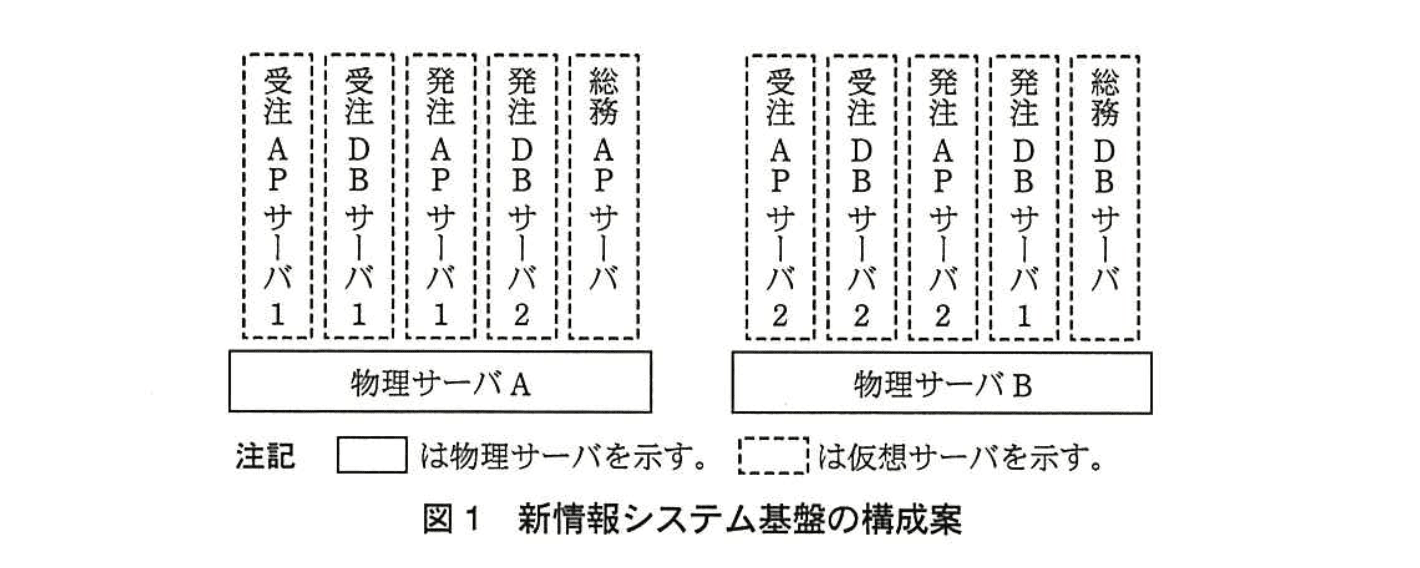
F君は、新情報システム基盤の構築に向けて、現行の三つの情報システムのハードウェア構成と、ピーク時におけるCPU利用率とメモリ利用率を調査した(表1)。
受注システムは、顧客が24時間365日注文できるように、冗長構成にしている。APサーバは、二つのAPサーバに負荷を分散して、一方のAPサーバにハードウェア障害が発生しても他方のAPサーバだけで縮退運転可能なa方式としている。また、DBサーバは、受注DBサーバ1を利用しており、受注DBサーバ1のハードウェア障害時には、あらかじめ起動してある受注DBサーバ2に自動的に切り替えるb方式としている。
発注システムは、APサーバについては受注システムと同様のa方式とし、DBサーバについては発注DBサーバ1のハードウェア障害時に手動で発注DBサーバ2を起動するc方式としている。
総務システムは、社外の顧客や仕入先に影響を与えないので、APサーバ、DBサーバそれぞれ1台の構成としている。
発注システムと総務システムについては、利用者がE社の社員であるので、ハードウェア点検やセキュリティパッチ適用のために、情報システムを停止させることが許容されている。
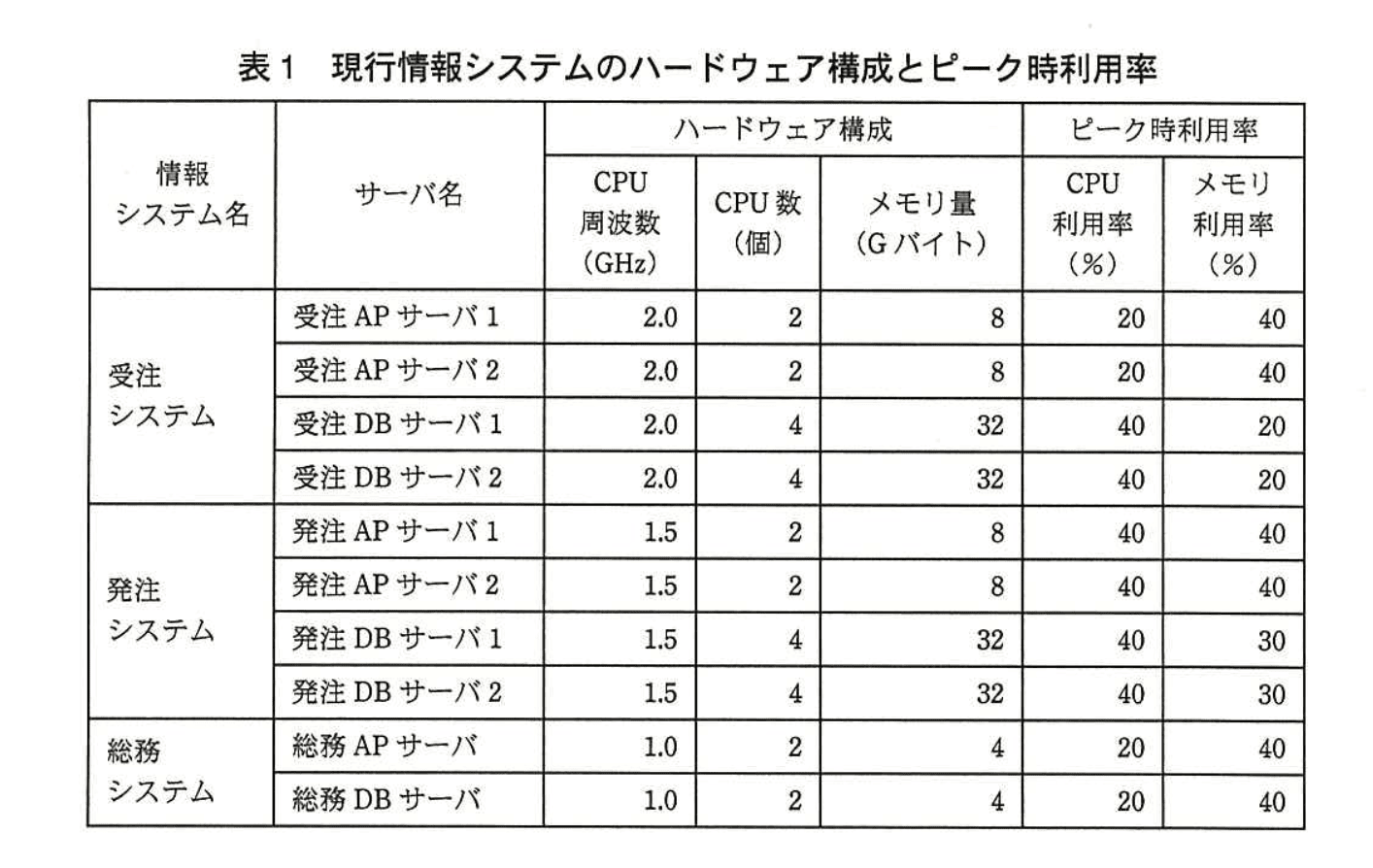
〔新情報システム基盤の構成案〕
F君は、現行情報システムのハードウェア構成とピーク時利用率を基に、サーバ仮想化による新情報システム基盤の構成案を作成した(図1)。
この構成案を採用した場合、ピーク時に物理サーバAとBに最低限必要なCPU数は同数になり、それぞれd個となる。メモリ量についても同じになり、それぞれ24Gバイトとなる。ここで、物理サーバAとBには、3.0 GHzのCPUを用いることにする。
〔冗長構成の検討〕
E社が導入を予定している仮想化システムには、情報システムが利用可能な状態のまま仮想サーバを他の物理サーバに移動させる機能と、障害が発生した物理サーバで動作していた仮想サーバを他の物理サーバで自動的に再起動させる機能がある。ただし、他の物理サーバで自動的に再起動させる場合は、情報システムが再び利用可能になるまでに一定の時間を要する。なお、複数の仮想サーバを並行して再起動させる場合の再起動時間は、単一の仮想サーバの再起動時間と同等であるとする。
F君は、物理サーバのハードウェア障害時にも、片方の物理サーバで全仮想サーバが動作可能なように、物理サーバのCPU数とメモリ量を、ピーク時に必要な数量の2倍にする構成案をまとめた。
〔新情報システム基盤の構成案のレビュー〕
F君がまとめた新情報システム基盤の構成案をF君の上司にレビューしてもらったところ、次の2点の指摘を受けた。
指摘1 新情報システム基盤の導入によって、発注DBサーバ2は不要になる。
指摘2 総務システムが利用する仮想サーバの配置を見直すだけで、総務システムが利用できなくなる頻度を、F君がまとめた構成案よりも低下させることができる。
F君は、レビューの指摘を反映させ、新情報システム基盤の構成案を確定させた。
〔新情報システム基盤の保守〕
E社の情報システム運用規程では、年1回のハードウェア点検と、必要に応じて実施するセキュリティパッチの適用が義務付けられている。ハードウェア点検では、点検対象のハードウェアを停止させ、ハードウェアを構成する部品に異常が無いことを確認する。また、セキュリティパッチについては、情報システムを構成するOSやミドルウェアにセキュリティパッチを適用する。セキュリティパッチの種類によっては、サーバの再起動が必要になる。
F君は、〔新情報システム基盤の構成案のレビュー〕で構成を確定した新情報システム基盤について、ハードウェア点検とセキュリティパッチの適用方法について検討を行った。この結果、①ハードウェア点検については、新情報システム基盤の導入によって、情報システムの停止や縮退運転をすることなく実施できることが分かった。しかし、②セキュリティパッチの適用については、現行情報システムと同様に、セキュリティパッチの種類によっては、情報システムの停止や縮退運転が必要であることが分かった。
設問1:
本文中のa〜cに入れる適切な字句を解答群の中から選び、記号で答えよ。
解答群
ア:コールドスタンバイ
イ:シェアードエブリシング
ウ:シェアードナッシング
オ:ホットスタンバイ
エ:フェールセーフ
カ:ロードシェア
模範解答
a:カ
b:オ
c:ア
解説
解答の論理構成
-
APサーバの冗長方式
問題文では、APサーバについて「二つのAPサーバに負荷を分散して、一方のAPサーバにハードウェア障害が発生しても他方のAPサーバだけで縮退運転可能」とあります。
“負荷を分散して” 且つ “両系とも稼働中(障害時は片系運転)” の構成は、複数台で同時稼働し処理を分担する方式=「ロードシェア」です。
よって a = カ:ロードシェア。 -
受注DBサーバの冗長方式
「受注DBサーバ1のハードウェア障害時には、あらかじめ起動してある受注DBサーバ2に自動的に切り替える」と記述されています。
“あらかじめ起動してある”=待機系がオンライン、“自動的に切り替える”=フェイルオーバーが自動、という条件はホットスタンバイを満たします。
よって b = オ:ホットスタンバイ。 -
発注DBサーバの冗長方式
「発注DBサーバ1のハードウェア障害時に手動で発注DBサーバ2を起動する」とあります。
“手動で起動”=待機系は普段停止、“切り替えも手動” なのでコールドスタンバイです。
よって c = ア:コールドスタンバイ。
以上より、解答は
a:カ b:オ c:ア となります。
a:カ b:オ c:ア となります。
誤りやすいポイント
- ロードシェアとホットスタンバイを混同しやすいです。ロードシェアは“平常時から複数系が処理を分散”している点が決定的に異なります。
- ホットスタンバイとコールドスタンバイは待機系が「起動済みか否か」で判別します。切り替え方法(自動/手動)のみで判断すると誤答になります。
- フェールセーフ(エ)は“安全側に倒す”概念であり冗長構成の実装方式ではありません。名称のイメージで選ばないよう注意が必要です。
FAQ
Q: ロードシェアとロードバランサ配下のアクティブ–アクティブ構成は同じですか?
A: 本質的に同じです。問題では「二つのAPサーバに負荷を分散」と明記されているためロードシェアに該当します。
A: 本質的に同じです。問題では「二つのAPサーバに負荷を分散」と明記されているためロードシェアに該当します。
Q: ホットスタンバイとウォームスタンバイの違いは?
A: ホットスタンバイは待機系が本番系と同等に起動済みで即時切替可能、ウォームスタンバイはOS やミドルウェアは起動済みだがアプリや同期が遅延している等、完全即時ではない中間形態です。本問にはウォームスタンバイの選択肢がないため迷う必要はありません。
A: ホットスタンバイは待機系が本番系と同等に起動済みで即時切替可能、ウォームスタンバイはOS やミドルウェアは起動済みだがアプリや同期が遅延している等、完全即時ではない中間形態です。本問にはウォームスタンバイの選択肢がないため迷う必要はありません。
Q: コールドスタンバイ時の“手動起動”は必ず人手が必要ですか?
A: 物理解釈としては“停止状態からの起動が必要”という意味で、スクリプトや自動化ツールを用いてリモートで起動することもありますが、起動プロセス自体が即時に行われない点がホットスタンバイと異なります。
A: 物理解釈としては“停止状態からの起動が必要”という意味で、スクリプトや自動化ツールを用いてリモートで起動することもありますが、起動プロセス自体が即時に行われない点がホットスタンバイと異なります。
関連キーワード: 冗長構成、ロードシェア、ホットスタンバイ、コールドスタンバイ、フェイルオーバー
設問2:
本文中のdに入れる適切な数値を整数で答えよ。ここで、物理サーバのCPUの1GHz当たりの処理能力は、現行情報システムのCPUの1GHz当たりの処理能力と同等とする。CPUの処理能力は、CPU周波数に比例するものとする。また、物理サーバで仮想サーバを動作させるための仮想化システムに必要なCPU数、メモリ量は考慮しないものとする。
模範解答
d:3
解説
解答の論理構成
-
現行サーバごとのピーク時 CPU 負荷を計算
【問題文】の表1より、各サーバのピーク時負荷 (GHz) は
・受注 AP サーバ:2 個 × 2.0 GHz × 20 % = 0.8 GHz
・受注 DB サーバ:4 個 × 2.0 GHz × 40 % = 3.2 GHz
・発注 AP サーバ:2 個 × 1.5 GHz × 40 % = 1.2 GHz
・発注 DB サーバ:4 個 × 1.5 GHz × 40 % = 2.4 GHz
・総務 AP / DB サーバ:2 個 × 1.0 GHz × 20 % = 0.4 GHz -
全仮想サーバのピーク時合計負荷を求める
受注 AP ×2 = 1.6、受注 DB ×2 = 6.4、発注 AP ×2 = 2.4、発注 DB ×2 = 4.8、総務 AP+DB = 0.8
合計 1.6 + 6.4 + 2.4 + 4.8 + 0.8 = 16.0 GHz -
図1の構成案では物理サーバA・Bに同数の仮想サーバが分散され、 【問題文】に「ピーク時に物理サーバAとBに最低限必要なCPU数は同数」とある。
よって片方の負荷は
16.0 GHz ÷ 2 = 8.0 GHz -
物理サーバは 3.0 GHz の CPU を使用
【問題文】「ここで、物理サーバAとBには、3.0 GHz の CPU を用いることにする。」
必要 CPU 個数 はとなり整数へ切り上げて 3 個。 -
よって d に入る値は 3 である。
誤りやすいポイント
- CPU 個数ではなく クロック周波数ベースで負荷を合算する点を見落としやすい。
- 「CPU 利用率 (%)」はキャパシティではなく実負荷を示す。計算時に 100% を掛け忘れたり、逆に 1.0 を掛けて二重計算するミスが多い。
- 物理サーバを 2 台に分散するため、合計負荷の半分が片側に載る事実を読み飛ばし、全負荷で割ってしまうケース。
FAQ
Q: CPU の 1 GHz 当たり性能が変わる場合はどう計算すれば良いですか?
A: 本問では【問題文】に「1 GHz 当たりの処理能力は…同等」と明記されているため単純比例で良いですが、性能差がある場合はベンチマーク値などで補正する必要があります。
A: 本問では【問題文】に「1 GHz 当たりの処理能力は…同等」と明記されているため単純比例で良いですが、性能差がある場合はベンチマーク値などで補正する必要があります。
Q: 小数点以下の CPU 個数になったときはどう扱いますか?
A: 実際には CPU やコアは整数単位でしか搭載できません。したがって計算結果を切り上げて、余裕を持たせるのが原則です。
A: 実際には CPU やコアは整数単位でしか搭載できません。したがって計算結果を切り上げて、余裕を持たせるのが原則です。
Q: 仮想化によるオーバーヘッドは考えなくて良いのですか?
A: 本問では【問題文】に「仮想化システムに必要なCPU数、メモリ量は考慮しない」と条件が与えられており、オーバーヘッド分は計算対象外です。
A: 本問では【問題文】に「仮想化システムに必要なCPU数、メモリ量は考慮しない」と条件が与えられており、オーバーヘッド分は計算対象外です。
関連キーワード: 仮想化、CPUリソース計算、冗長構成、負荷分散
設問3:〔新情報システム基盤の構成案のレビュー〕について、(1)、(2)に答えよ。
(1)指摘1について、発注DBサーバ2が不要な理由を40字以内で述べよ。
模範解答
物理サーバBの障害発生時には、物理サーバAで発注DBサーバ1が起動するから
解説
解答の論理構成
-
現行の発注システムでは、DB を 2 台に分けている理由が次の一文に示されています。
― 「発注DBサーバ1のハードウェア障害時に手動で発注DBサーバ2を起動するc方式としている。」
つまり、物理マシン障害=DB ソフトが動く場を失う、という前提で専用の待機機を用意しています。 -
新基盤では仮想化製品により、 ― 「障害が発生した物理サーバで動作していた仮想サーバを他の物理サーバで自動的に再起動させる機能」が提供されます。
この機能がある限り、DB 用の“待機機”は物理ではなく仮想移行・再起動で代替できます。 -
したがって物理サーバBが故障しても、そこに載っていた「発注DBサーバ1」を物理サーバAで自動再起動すれば済みます。
-
よって「発注DBサーバ2」を別途用意する必要がなくなり、指摘1が導かれます。
誤りやすいポイント
- “自動再起動”と“ライブマイグレーション”を混同し、停止時間ゼロと考えてしまう。問題文は“再起動”であり瞬時復旧ではない点に注意。
- 既存の c 方式=手動切替えをそのまま仮想化後も残すと勘違いする。
- 「冗長化=必ず二重化」と思い込み、仮想基盤上でのリソース共有型冗長をイメージできない。
FAQ
Q: 再起動に時間が掛かるなら発注DBサーバ2を残した方が安全では?
A: システム要件上、発注システムは社内利用で「情報システムを停止させることが許容されている」と明記されています。よって自動再起動による短時間停止を許容できます。
A: システム要件上、発注システムは社内利用で「情報システムを停止させることが許容されている」と明記されています。よって自動再起動による短時間停止を許容できます。
Q: 仮想サーバが同時に多数落ちても並行再起動できるの?
A: 問題文に「複数の仮想サーバを並行して再起動させる場合の再起動時間は、単一の仮想サーバの再起動時間と同等」とあるので、一括での復旧が可能とされています。
A: 問題文に「複数の仮想サーバを並行して再起動させる場合の再起動時間は、単一の仮想サーバの再起動時間と同等」とあるので、一括での復旧が可能とされています。
Q: ライセンス面で DB を 1 台にするとコストが下がる?
A: 設問では保守費用削減が主目的です。不要なサーバを削除すればハード・ライセンス双方の保守費が下がるのは自然な効果です。
A: 設問では保守費用削減が主目的です。不要なサーバを削除すればハード・ライセンス双方の保守費が下がるのは自然な効果です。
関連キーワード: 仮想サーバ移動、自動再起動、フェイルオーバー、冗長構成、物理サーバ障害
設問3:〔新情報システム基盤の構成案のレビュー〕について、(1)、(2)に答えよ。
(2)指摘2について、総務システムが利用できなくなる頻度を低下させるためには、仮想サーバの配置をどのように変更すればよいか。35字以内で述べよ。
模範解答
総務APサーバと総務DBサーバを同一物理サーバに配置する。
解説
解答の論理構成
- 現状把握
- 問題文には「総務システムは、APサーバ、DBサーバそれぞれ1台の構成としている。」とあります。つまり冗長化されていない単一構成です。
- レビューでの指摘
- 「指摘2 総務システムが利用する仮想サーバの配置を見直すだけで、総務システムが利用できなくなる頻度を、F君がまとめた構成案よりも低下させることができる。」と記載されています。
- 可用性の考察
- 総務システムは「APサーバ」と「DBサーバ」の両方が同時に稼働して初めて業務が成立します。
- 仮に二つの仮想サーバを異なる物理サーバへ分散配置すると、どちらか一方の物理サーバが故障しただけでシステム全体が停止します。
- 一方、両方を同一物理サーバに集約すれば、その物理サーバが故障しない限りシステムは継続利用できます。故障確率は片方のサーバだけが壊れる場合よりも低く、“利用できなくなる頻度” を下げられます。
- 結論
- したがって、総務システムの二つの仮想サーバを同じ物理サーバへ移動させる構成が最適であり、模範解答「総務APサーバと総務DBサーバを同一物理サーバに配置する。」が導かれます。
誤りやすいポイント
- 「分散すれば可用性が上がる」と思い込む
冗長構成が無い単一サーバの場合は逆効果です。両方同時に必要なシステムでは“同居”が合理的です。 - フェイルオーバー機能を過信する
問題文には「他の物理サーバで自動的に再起動させる場合は、…一定の時間を要する」とあるため、再起動完了まで業務は停止します。総務システムは無停止要件ではないにせよ、停止頻度は低い方が望ましいです。 - 「発注DBサーバ2が不要」の指摘と混同する
指摘1と指摘2は別論点です。総務システムの可用性改善は発注システムとは無関係なので切り分けましょう。
FAQ
Q: 受注システムも同一物理サーバにまとめた方が良いですか?
A: 受注システムは「24時間365日注文受付」とあり、冗長構成(負荷分散・自動切替)が必須です。したがって物理サーバ分散が前提になります。
A: 受注システムは「24時間365日注文受付」とあり、冗長構成(負荷分散・自動切替)が必須です。したがって物理サーバ分散が前提になります。
Q: 物理サーバが故障したとき、全仮想サーバをもう一台に移動すれば良いのでは?
A: 移動(ライブマイグレーション)は物理サーバが稼働中でないと実行できません。故障時は「自動的に再起動させる」機能に頼ることになり、再起動完了まで停止が発生します。
A: 移動(ライブマイグレーション)は物理サーバが稼働中でないと実行できません。故障時は「自動的に再起動させる」機能に頼ることになり、再起動完了まで停止が発生します。
Q: セキュリティパッチ適用時も同居の方が有利ですか?
A: パッチ適用で仮想サーバを再起動する場合、同居でも分散でも停止対象は同じ2台です。適用頻度は変わらないため、停止“頻度”の観点では同居だけが有利になります。
A: パッチ適用で仮想サーバを再起動する場合、同居でも分散でも停止対象は同じ2台です。適用頻度は変わらないため、停止“頻度”の観点では同居だけが有利になります。
関連キーワード: 仮想サーバ、可用性、フェイルオーバー、冗長化、単一障害点
設問4:〔新情報システム基盤の保守〕について(1)、(2)に答えよ。
(1)本文中の下線①について、情報システムの停止も縮退運転もなく、ハードウェア点検ができるのはなぜか。物理サーバのCPU数とメモリ量をピーク時の2倍にする構成としたこと以外の理由を、35字以内で述べよ。
模範解答
仮想サーバを起動した状態で他の物理サーバに移動できるから
解説
解答の論理構成
- まず本文は、仮想化基盤が備える二つの機能を説明しています。
引用︓「E社が導入を予定している仮想化システムには、情報システムが利用可能な状態のまま仮想サーバを他の物理サーバに移動させる機能…」
この一文が “サービス稼働中でも仮想サーバを別ホストへ移す” ことを明示しています。 - ハードウェア点検は「点検対象のハードウェアを停止させ」るため、通常は同一サーバ上の仮想サーバも停止が必要になります。
- しかし①では「情報システムの停止や縮退運転をすることなく実施できる」と述べています。
- これは、点検対象サーバ上の全仮想サーバを“利用可能な状態のまま”別サーバへ 事前にライブマイグレーション すれば、点検中もアプリケーションは動き続けるためです。
- よって「仮想サーバを起動した状態で他の物理サーバに移動できるから」という解答になります。
誤りやすいポイント
- 「障害が発生した物理サーバで動作していた仮想サーバを他の物理サーバで自動的に再起動させる機能」と混同し、再起動=停止時間ありと判断してしまう。点検は計画作業であり、停止を伴わない“移動”機能を使う場面です。
- CPU数・メモリ量をピーク時の2倍にした “リソース冗長” を理由に挙げてしまう。本問は「それ以外の理由」と明示されているため誤答になります。
- 「点検対象サーバに残っても縮退運転できる」と考えるケース。①は“縮退運転もなく”が条件なので、縮退前提の回答は不適切です。
FAQ
Q: ライブマイグレーションに要する時間が長い場合でも停止しないのですか?
A: 移動中も仮想マシンのメモリ内容を同期し続ける方式なので、ユーザ側からは数百ミリ秒程度の瞬断か、ほぼ無停止で切り替わります。
A: 移動中も仮想マシンのメモリ内容を同期し続ける方式なので、ユーザ側からは数百ミリ秒程度の瞬断か、ほぼ無停止で切り替わります。
Q: 点検対象サーバの全VMを移動後、空いたサーバは完全停止しても問題ない?
A: はい。移動完了後にサーバをシャットダウンして点検できます。リソースは残りの物理サーバでまかなわれます。
A: はい。移動完了後にサーバをシャットダウンして点検できます。リソースは残りの物理サーバでまかなわれます。
Q: 移動先サーバのリソースが不足しているとどうなりますか?
A: 必要なCPU・メモリに余裕が無いとライブマイグレーションは失敗または性能低下を招くため、本文で「ピーク時の2倍」に拡張して余裕を確保しています。
A: 必要なCPU・メモリに余裕が無いとライブマイグレーションは失敗または性能低下を招くため、本文で「ピーク時の2倍」に拡張して余裕を確保しています。
関連キーワード: ライブマイグレーション、仮想サーバ、可用性、ハードウェア点検、冗長構成
設問4:〔新情報システム基盤の保守〕について(1)、(2)に答えよ。
(2)本文中の下線②のうち、サーバの再起動が必要なセキュリティパッチを適用する場合、情報システムを停止してサーバを再起動しなければならないのはどのサーバか。該当するサーバを全て、表1のサーバ名で答えよ。
模範解答
発注DBサーバ1、総務APサーバ、総務DBサーバ
解説
解答の論理構成
-
現行構成の冗長性
-
受注システム
- AP サーバは「一方のAPサーバにハードウェア障害が発生しても他方のAPサーバだけで縮退運転可能なa方式」とある。
- DB サーバは「受注DBサーバ1のハードウェア障害時には…受注DBサーバ2に自動的に切り替えるb方式」とある。
⇒ 受注システムの各サーバは二重化されており、片方を停止・再起動してもサービスは継続できる。
-
発注システム
- AP サーバは受注と同じa方式で二重化。
- DB サーバは「発注DBサーバ1のハードウェア障害時に手動で発注DBサーバ2を起動するc方式」とある。
⇒ DB は「起動待機系」で二台構成。
-
総務システム
- 「APサーバ、DBサーバそれぞれ1台の構成」とある。
-
-
レビューによる構成変更
- 指摘1:「発注DBサーバ2は不要になる。」
⇒ 新基盤では DB の二台目を撤去し、「発注DBサーバ1」のみとなる。
- 指摘1:「発注DBサーバ2は不要になる。」
-
セキュリティパッチ適用時の可用性要件
- 下線②より「セキュリティパッチの種類によっては、情報システムの停止や縮退運転が必要である」。
- 再起動型パッチを当てると、対象サーバの OS がシャットダウンされ、当該サーバのアプリケーションは必ず停止する。
- 冗長構成をとっていれば、他系に処理を任せられるため“停止”扱いにならない。
-
停止しなければならないサーバの抽出
- 受注系:AP2台・DB2台→片系再起動中もサービス継続可。停止不要。
- 発注系:
- AP2台 → 片系ずつ適用可。
- DB は「発注DBサーバ1」1台のみ。再起動=システム停止。
- 総務系:AP 1台「総務APサーバ」、DB 1台「総務DBサーバ」。いずれも再起動=システム停止。
-
結論
停止と再起動が必要なのは
「発注DBサーバ1、総務APサーバ、総務DBサーバ」。
誤りやすいポイント
- 「発注DBサーバ2」が図1に描かれているため残っていると誤認しやすいが、指摘1で削除されている。
- 再起動が必要なのは“物理サーバ”ではなく“パッチを当てる仮想サーバ”であることを見落としやすい。
- 二重化=停止不要と短絡的に判断し、「起動待機系」であっても片系停止でサービス継続できると勘違いするケース。
FAQ
Q: 受注DBサーバを再起動するときは本当に停止しなくてよいのですか?
A: はい。「受注DBサーバ1」「受注DBサーバ2」がb方式で自動切替できるため、片方を再起動してもサービスはもう一方で提供し続けられます。
A: はい。「受注DBサーバ1」「受注DBサーバ2」がb方式で自動切替できるため、片方を再起動してもサービスはもう一方で提供し続けられます。
Q: 発注システムも手動切替すれば停止しないのでは?
A: 発注系は「発注DBサーバ2」が取り外されたため切替先がありません。したがって「発注DBサーバ1」を再起動する間は発注システム全体を停止せざるを得ません。
A: 発注系は「発注DBサーバ2」が取り外されたため切替先がありません。したがって「発注DBサーバ1」を再起動する間は発注システム全体を停止せざるを得ません。
Q: 物理サーバをライブマイグレーションすれば全停止を避けられますか?
A: ライブマイグレーションは“ハードウェア点検”時に有効です。OS 再起動が必要なパッチ適用では、仮想サーバ自体を落とす必要があるため回避できません。
A: ライブマイグレーションは“ハードウェア点検”時に有効です。OS 再起動が必要なパッチ適用では、仮想サーバ自体を落とす必要があるため回避できません。
関連キーワード: 冗長構成、ライブマイグレーション、フェイルオーバー、セキュリティパッチ、可用性
