応用情報技術者 2014年 秋期 午後 問10
販売管理システムの問題管理に関する次の記述を読んで、設問1~3に答えよ。
M社は、西日本の複数の地域で営業を展開している食品流通卸業者である。
M社は、基幹システムである販売管理システムを5年前に再構築した。取引量の多い食品スーパー数社との協業によるインターネット経由の共通EDIの導入をきっかけに、それまでの地域別の分散システムを、単一システムに統合した。その際にサーバや周辺機器も全面刷新し、食品スーパーからのPOSデータ連携を新たに始め、取扱いデータ量の大幅な増加に対応できるように、新規に多数のハードディスクドライブ(以下、ディスクという)を導入した。
再構築後の3年間は、目立った障害もなく安定して稼働したが、一昨年度と昨年度に1度ずつディスク障害が発生し、ディスクを交換した。今年度は、上半期に既に2度ディスクを交換している。
販売管理システムの運用及びサービスデスクは、情報システム部の運用課が担っている。先月から問題管理を担当することになったN君は、情報システム部長の指示を受けて、ディスク障害についての調査を開始した。
情報システム部長の今回の指示は、先日行われたシステム監査の報告会が契機となっている。システム監査において、販売管理システムのディスク障害の対応についてはインシデントの管理に終始しているので、予防処置について検討するようにとの指摘を受けていた。
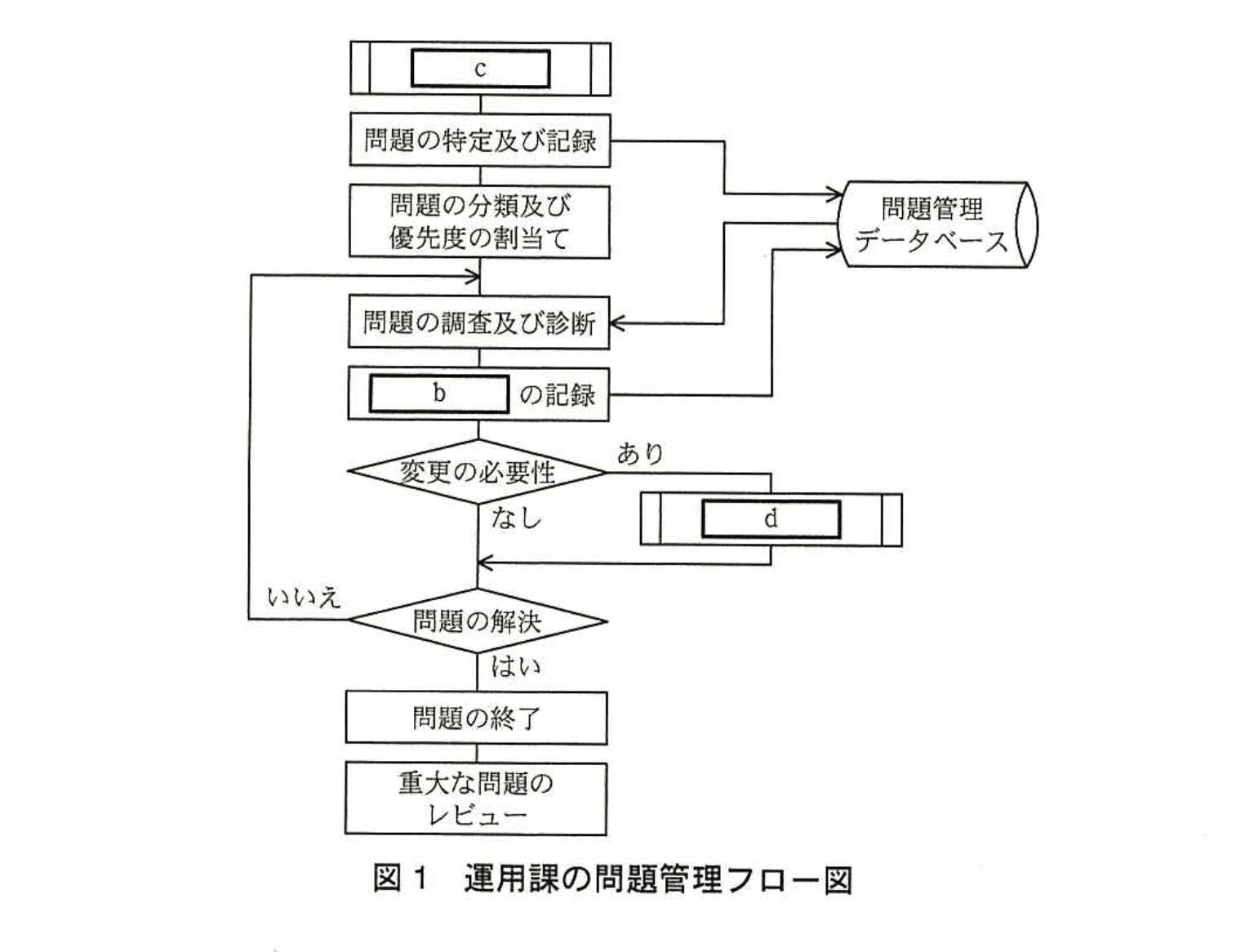
〔運用課の問題管理手順〕
運用課では、これまでに発生した問題に関して、事象の詳細、問題を調査・分析してaを特定した経緯と結果、暫定的な解決策(以下、暫定策という)、恒久的な解決策(以下、恒久策という)などの項目を問題管理データベースに記録して、新たに問題が発生した際の調査及び診断に使用している。
N君はまず、運用課での問題管理手順を確認した。
・問題の特定は、サービスデスクからの問題の通知によることが多いが、異常を示すシステムメッセージのメール通知など、サービスデスクを経由しない場合もある。特定した問題は、問題管理データベースに記録する。
・記録した問題を分類し、緊急度と影響度を評価して優先度を割り当てる。
・問題のaを特定するための調査及び診断を行う。初めに、問題管理データベースからbを参照して、過去に特定された問題でないか確認する。
・調査及び診断の結果、問題に対する暫定策又は恒久策は、問題管理データベースに、bとして記録する。
・問題の恒久策実施のために、何らかの変更が必要な場合、変更要求(RFC)を発行する。
・問題の恒久策が有効で、再発防止を確認できたら、問題を終了する。
・問題のうち重大なものは、将来に向けた学習のためのレビューを行う。
上述の内容をフロー図にまとめると図1のとおりとなる。
〔ディスク障害の記録の確認〕
N君は、問題管理データベースを参照し、これまでのディスク障害の記録を調査した。記録の内容はいずれも類似しており、障害の事象は、RAIDコントローラがディスクの書込み時のエラーを検出したというもので、分析の結果は、ディスクの経年不良となっていた。恒久策として、障害を起こしたディスクを交換すると記載されていた。交換後、データ再構築処理の完了を確認して、問題は終了とされていた。N君は、①ディスク障害の問題に対して、障害を起こしたディスクの交換は恒久策にはならないと考えた。
〔ディスクの運用管理の確認〕
続いてN君は、販売管理システムを中心に、M社でのディスクの運用管理について、運用課メンバへのヒアリングなどの調査を行い、次の情報を得た。
・販売管理システムのディスク装置は、ホットスワップ対応機器によるRAID6構成を採っており、同一構成内で2台までのディスク障害であれば、システムを停止せずにディスクの交換が可能である。これまでに発生したディスク障害では、即時の対応を重視し、定期保守を待たず、日中、システムを停止せずにディスクを交換し、データ再構築処理を行っていた。なお、販売管理システムの定期保守は、週次に、システムを停止して実施している。
・販売管理システム再構築時に多数導入したディスクは、M社がそれまで使用してきた、メインフレームにも用いられる高信頼性モデルではなく、PCなどにも使用される汎用のモデルであった。機器単体では、高信頼性モデルの半分程度の寿命と言われている。
・N君は、これまでに確認した、機器メーカーや利用者からの報告などから、販売管理システムのディスクのように、同一の製造ロットで、同じように使用されているディスクは、障害も同時期に起こす確率が高いという情報を得ていた。また、これまで障害回復として実施していた、RAID6構成でシステムを停止せずにディスク交換した場合のデータ再構築処理は、高頻度のディスクアクセスを伴うので、機器に対する負荷が高く、二次的な障害の危険性が増すという情報も得ていた。
・N君が、販売管理システムのシステムメッセージを記録したログを調べると、ディスクの読取りエラーや書込みエラーの障害が発生したディスクに、障害の兆候を示す不良セクタの代替処理発生のメッセージが、障害発生の数日前から頻発していた。販売管理システムのメッセージ監視機能は、ディスクの読取りエラーと書込みエラーのエラーメッセージを検出すると問題管理担当者にメールで通知する設定になっているが、不良セクタの代替処理発生のメッセージを検出してもメールで通知する設定にはなっていなかった。
N君は、情報システム部長に、販売管理システムのディスクについては、これまでの、ディスク障害が発生してから交換するやり方を改め、②障害の兆候を出して、障害が発生する前に交換する方式を提案しようと考えた。また、同時に、③障害の兆候を検出したディスクの交換の実施時期についての改善も必要と考えた。
設問1:〔運用課の問題管理手順〕について(1)、(2)に答えよ。
(1)本文中のaに入れる適切な字句を、5字以内で答えよ。
模範解答
a:根本原因
解説
解答の論理構成
- 【問題文】には、
「問題を調査・分析してaを特定した経緯と結果」
「問題のaを特定するための調査及び診断を行う」
と二度繰り返し登場しています。ここで “特定” という動詞が使われていることから、a には「調査・分析の結果、究明する対象」が入ると読み取れます。 - ITIL などの問題管理プロセスでは、障害の再発防止を目的に「根本原因(Root Cause)」を突き止めることが必須とされています。
- 「調査・分析して○○を特定」「○○を特定するための調査及び診断」という流れは、まさに「根本原因」を探る一連の作業を指します。
- 以上より、a に入る適切な字句は「根本原因」と判断できます。
誤りやすいポイント
- 「主原因」「原因分析」など、似た語を選んでしまう。問題管理の正式用語は「根本原因」です。
- インシデント管理の観点で「障害原因」と答えてしまう。問題管理では “根本” にこだわる点が重要です。
- 図1を先に見て「変更要求」や「暫定策」など他のキーワードと混同する。
FAQ
Q: 「原因」と「根本原因」は同じではないのですか?
A: 障害が表面化した直接要因が「原因」、その背後にある真の要因が「根本原因」です。問題管理では後者を特定しなければ再発防止につながりません。
A: 障害が表面化した直接要因が「原因」、その背後にある真の要因が「根本原因」です。問題管理では後者を特定しなければ再発防止につながりません。
Q: ITILを知らなくても解けますか?
A: 本文中で “調査・分析して○○を特定” と繰り返しているため、用語を知らなくても文脈から「根本原因」を導けます。
A: 本文中で “調査・分析して○○を特定” と繰り返しているため、用語を知らなくても文脈から「根本原因」を導けます。
Q: 「真因」でも正解になりますか?
A: 一般的に同義ですが、設問は正式な専門用語を期待しているため「根本原因」と記述するのが安全です。
A: 一般的に同義ですが、設問は正式な専門用語を期待しているため「根本原因」と記述するのが安全です。
関連キーワード: 根本原因分析、インシデント管理、再発防止、ITIL, 変更要求
設問1:〔運用課の問題管理手順〕について(1)、(2)に答えよ。
(2)本文及び図1中のb〜dに入れる適切な字句を解答群の中から選び、記号で答えよ。
なお、c及び[ d ]には、サービスマネジメントのプロセス名称が入る。
解答群
ア:インシデント及びサービス要求管理
イ:既知の誤り
ウ:キャパシティ管理
エ:記録
オ:構成管理
カ:暫定策
キ:情報セキュリティ管理
ク:変更管理
ケ:リリース及び展開管理
模範解答
b:イ
c:ア
d:ク
解説
解答の論理構成
- 【問題文】には「初めに、問題管理データベースからbを参照して、過去に特定された問題でないか確認する。」とあります。ITIL の問題管理では、この参照対象は「既知の誤り(Known Error)」です。よって
b=「イ:既知の誤り」 - 「特定した問題は、問題管理データベースに記録する。」や「サービスデスクからの問題の通知」が冒頭に記載されており、これはインシデントが問題管理へエスカレーションされる典型形です。図1最上段のcは問題管理と密接に連携するプロセスであり、ITIL では「インシデント及びサービス要求管理」が該当します。よって
c=「ア:インシデント及びサービス要求管理」 - 【問題文】には「問題の恒久策実施のために、何らかの変更が必要な場合、変更要求(RFC)を発行する。」と明記されます。RFC を扱うプロセスは ITIL の「変更管理」です。図1でdは変更の有無を判断するひし形の右側に配置されており、変更プロセスを示しています。よって
d=「ク:変更管理」
誤りやすいポイント
- 「リリース及び展開管理」と混同しやすい
RFC を扱うのは変更管理であり、リリース管理は変更確定後の本番展開フェーズです。 - 「構成管理」との取り違え
構成管理は CI(構成アイテム)の属性や関係を維持しますが、インシデント起点の問題受付を示す c とは役割が異なります。 - 「暫定策」と「既知の誤り」の混同
既知の誤りは原因が判明している問題の登録名であり、暫定策(ワークアラウンド)はその場しのぎの対処方法です。語句を取り違えると b を誤答しやすくなります。
FAQ
Q: 「既知の誤り」は原因不明でも登録できますか?
A: いいえ。ITIL では「原因が判明し、再現手順または暫定策が明確になった問題」を既知の誤りとして登録します。
A: いいえ。ITIL では「原因が判明し、再現手順または暫定策が明確になった問題」を既知の誤りとして登録します。
Q: RFC を出した後のリリース作業は問題管理の範囲ですか?
A: いいえ。RFC 発行以降は変更管理が主導し、実際の本番反映はリリース及び展開管理が担当します。問題管理は恒久策が有効か確認して終了させるまでを担当します。
A: いいえ。RFC 発行以降は変更管理が主導し、実際の本番反映はリリース及び展開管理が担当します。問題管理は恒久策が有効か確認して終了させるまでを担当します。
Q: インシデントと問題はどこで区別されますか?
A: インシデント管理が「サービス中断や品質低下」を検知し、原因追究が必要と判断した時点で問題管理へエスカレーションされます。
A: インシデント管理が「サービス中断や品質低下」を検知し、原因追究が必要と判断した時点で問題管理へエスカレーションされます。
関連キーワード: 問題管理、既知の誤り、インシデント管理、変更管理、RFC
設問2:
本文中の下線①で、N君が、ディスク交換は恒久策にならないと考えたのはなぜか。40字以内で述べよ。
模範解答
故障したディスクを交換しても、他のディスクが故障する可能性があるから
解説
解答の論理構成
- まず、障害原因は「ディスクの経年不良」と【問題文】に明記されています。
分析の結果は、ディスクの経年不良となっていた。
- 恒久策として取られていた対処は「障害を起こしたディスクを交換」するだけでした。
恒久策として、障害を起こしたディスクを交換すると記載されていた。
- しかし同一ロットのディスクは同時期に故障しやすいという証拠が示されています。
同一の製造ロットで、同じように使用されているディスクは、障害も同時期に起こす確率が高い。
- さらに実際に「一昨年度」「昨年度」「今年度」に繰り返し交換が発生している事実からも、交換しても根本原因(ロット全体の経年劣化)は残ったままです。
- よってN君は「他のディスクも順次故障する可能性がある」と判断し、個別交換は恒久策にならないと結論づけました。
誤りやすいポイント
- 「RAID6 だから2台まで壊れても平気」と考え、恒久策=交換で十分と誤解する。
- 「経年不良」を個体の問題と捉え、ロット全体に広がるリスクを見落とす。
- 障害回数の増加を偶然とみなし、傾向分析を行わない。
- 恒久策と暫定策の区別をあいまいにし、交換手順を恒久策に分類してしまう。
FAQ
Q: RAID6 構成ならばディスクを順次交換しても運用に大きな影響はないのでは?
A: RAID6 自体は冗長性を高めますが、再構築時の高負荷で「二次的な障害の危険性が増す」【問題文】ため、連続故障リスクを放置するのは不適切です。
A: RAID6 自体は冗長性を高めますが、再構築時の高負荷で「二次的な障害の危険性が増す」【問題文】ため、連続故障リスクを放置するのは不適切です。
Q: 交換を恒久策にしない場合、どのような改善が考えられますか?
A: 予防保守としてロット単位で計画的に新品へ更換し、さらに「障害の兆候を出して、障害が発生する前に交換する方式」を導入することが提案されています。
A: 予防保守としてロット単位で計画的に新品へ更換し、さらに「障害の兆候を出して、障害が発生する前に交換する方式」を導入することが提案されています。
Q: 経年不良の判断材料には何を使えばよいですか?
A: ログに出力されていた「不良セクタの代替処理発生」の頻発メッセージなど、障害の兆候を示すシステムメッセージが有効です。
A: ログに出力されていた「不良セクタの代替処理発生」の頻発メッセージなど、障害の兆候を示すシステムメッセージが有効です。
関連キーワード: 予防保守、RAID6, 問題管理、不良セクタ、経年劣化
設問3:〔ディスクの運用管理の確認〕について、(1)、(2)に答えよ。
(1)本文中の下線②を実現するために必要となる、販売管理システムのメッセージ監視機能の設定に関する変更点を40字以内で述べよ。
模範解答
不良セクタの代替処理発生のメッセージの検出をメールで通知する。
解説
解答の論理構成
-
目的の再確認
本問は、本文中の下線②「障害の兆候を出して、障害が発生する前に交換する方式」を実現するために、メッセージ監視機能の設定をどう変更すべきかを問うています。 -
障害の兆候が分かるメッセージの特定
【問題文】には、 「ディスクの読取りエラーと書込みエラーのエラーメッセージを検出すると問題管理担当者にメールで通知する設定になっているが、不良セクタの代替処理発生のメッセージを検出してもメールで通知する設定にはなっていなかった。」
とあります。
ここで “不良セクタの代替処理発生” メッセージこそが障害発生前に現れる兆候です。 -
要求される設定変更
したがって、既にメール通知されている「読取りエラー・書込みエラー」に加え、「不良セクタの代替処理発生」の検出時にもメール通知を行うよう設定を拡張すれば、障害の兆候を早期把握できます。 -
40字以内でのまとめ
上記を簡潔にまとめたものが模範解答
「不良セクタの代替処理発生のメッセージの検出をメールで通知する。」
となります。
誤りやすいポイント
- 読取りエラー・書込みエラーの通知は既に設定済みであることを見落とし、同じ内容を解答に書いてしまう。
- 「SMART情報を監視する」など本文にない追加機能を答えてしまい、設問条件を逸脱する。
- “不良セクタ” だけをキーワードにし、代替処理発生という「障害の兆候」を明示しないことで意図が伝わらなくなる。
FAQ
Q: 代替処理発生メッセージはなぜ重要なのですか?
A: 【問題文】によると「障害発生の数日前から頻発していた」とあり、ディスク障害の前兆であるためです。早期に把握すれば計画的な交換が可能になります。
A: 【問題文】によると「障害発生の数日前から頻発していた」とあり、ディスク障害の前兆であるためです。早期に把握すれば計画的な交換が可能になります。
Q: RAID6なので2台同時障害まで耐えられるのでは?
A: 耐えられますが、再構築時の高負荷で「二次的な障害の危険性が増す」と本文に記されており、兆候時点で交換する方が安全です。
A: 耐えられますが、再構築時の高負荷で「二次的な障害の危険性が増す」と本文に記されており、兆候時点で交換する方が安全です。
Q: 監視設定を変えるだけで十分ですか?
A: 監視強化は前提条件です。実際には検出後の交換手順やタイミング(週次の定期保守に合わせるなど)も合わせて見直す必要がありますが、本設問は監視設定に限定して問われています。
A: 監視強化は前提条件です。実際には検出後の交換手順やタイミング(週次の定期保守に合わせるなど)も合わせて見直す必要がありますが、本設問は監視設定に限定して問われています。
関連キーワード: RAID6, 不良セクタ、障害予兆、ホットスワップ、メール通知
設問3:〔ディスクの運用管理の確認〕について、(1)、(2)に答えよ。
(2)本文中の下線③について、N君が考えた改善とはどのようなことか。30字以内で述べよ。
模範解答
ディスク交換を定期保守時のシステム停止中に実施する。
解説
解答の論理構成
-
事実確認
・「これまでに発生したディスク障害では、即時の対応を重視し、定期保守を待たず、日中、システムを停止せずにディスクを交換」していた。
・一方で「販売管理システムの定期保守は、週次に、システムを停止して実施している」。
・さらに「RAID6構成でシステムを停止せずにディスク交換した場合のデータ再構築処理は、高頻度のディスクアクセスを伴うので、機器に対する負荷が高く、二次的な障害の危険性が増す」というリスク情報も得ている。 -
問題点の抽出
システム稼働中の再構築はディスク全体に負荷を掛けてしまい、「同一の製造ロットで…障害も同時期に起こす確率が高い」状況では二次被害を誘発しやすい。 -
解決方針の導出
・週次の定期保守ではシステムを計画停止するため、大量アクセスを回避できる。
・停止中なら再構築処理の I/O 影響が抑えられ、業務への影響も限定的。
したがって、障害予兆を検知したディスクは「定期保守時のシステム停止中に交換」するのが最適となる。 -
結論
上記を踏まえ、本設問③の改善内容は「ディスク交換を定期保守時のシステム停止中に実施する。」である。
誤りやすいポイント
- RAID6 の冗長性を過信し、「稼働中交換が安全」と思い込む。再構築負荷による二次障害リスクが見落とされやすいです。
- 予兆検知後に“すぐ交換”と即断し、業務時間帯の I/O 影響を軽視してしまう。定期保守という計画停止の好機があることを忘れがちです。
- 「障害が発生する前に交換」のみで回答を終え、実施“時期”への言及を欠いて減点されるケースが目立ちます。
FAQ
Q: 週次保守より早く障害が顕在化しそうな場合はどうしますか?
A: 業務への影響度と予兆レベルを評価し、高リスクなら臨時停止を計画し交換します。基本方針は「可能な限り停止中に交換」で、例外はリスク管理で判断します。
A: 業務への影響度と予兆レベルを評価し、高リスクなら臨時停止を計画し交換します。基本方針は「可能な限り停止中に交換」で、例外はリスク管理で判断します。
Q: RAID6 なら 2 台同時障害まで耐えられるのに、なぜ急いで交換しないのですか?
A: 再構築中は残存ディスクに高負荷が掛かり、同一ロット故障が重なると 3 台目が落ちる恐れがあります。計画停止下での交換・再構築が安全策です。
A: 再構築中は残存ディスクに高負荷が掛かり、同一ロット故障が重なると 3 台目が落ちる恐れがあります。計画停止下での交換・再構築が安全策です。
Q: 不良セクタ代替処理メッセージもメール通知すべきですか?
A: はい。予兆検知を自動化し早期に交換計画へ移行できるため、障害発生前の是正処置に繋がります。
A: はい。予兆検知を自動化し早期に交換計画へ移行できるため、障害発生前の是正処置に繋がります。
関連キーワード: RAID6, 予兆監視、再構築負荷、計画停止、二次障害
