応用情報技術者 2015年 春期 午後 問03
データ圧縮の前処理として用いられる Block-sorting に関する次の記述を読んで、設問1~4に答えよ.
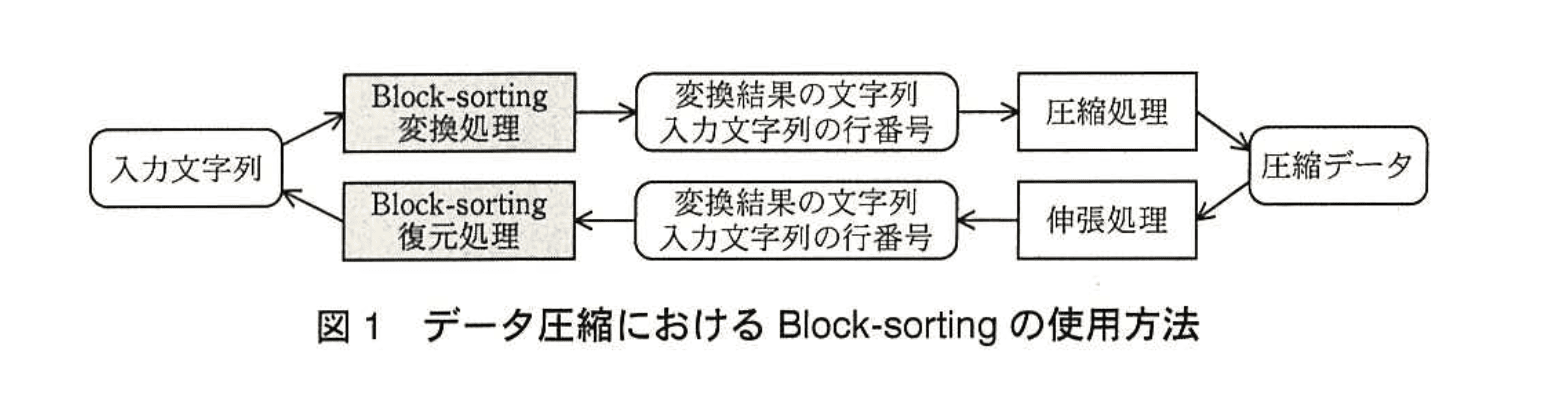
Block-sorting は、文字列に対する可逆変換の一種である。変換後の文字列は、変換前の文字列と比較して同じ文字が多く続く傾向があるので、その後に行う圧縮処理において圧縮率を向上させることができる。
Block-sorting は、変換処理と復元処理の二つの処理で構成される。変換処理は、入力文字列を受け取って、変換結果の文字列と、入力文字列がソート後のブロックで何行目にあるか (以下、入力文字列の行番号という) を出力する。一方、復元処理は、変換結果の文字列と入力文字列の行番号を受け取って入力文字列を出力する。
データ圧縮における Block-sorting の使用方法を図1に示す。
〔Block-sorting の変換処理〕
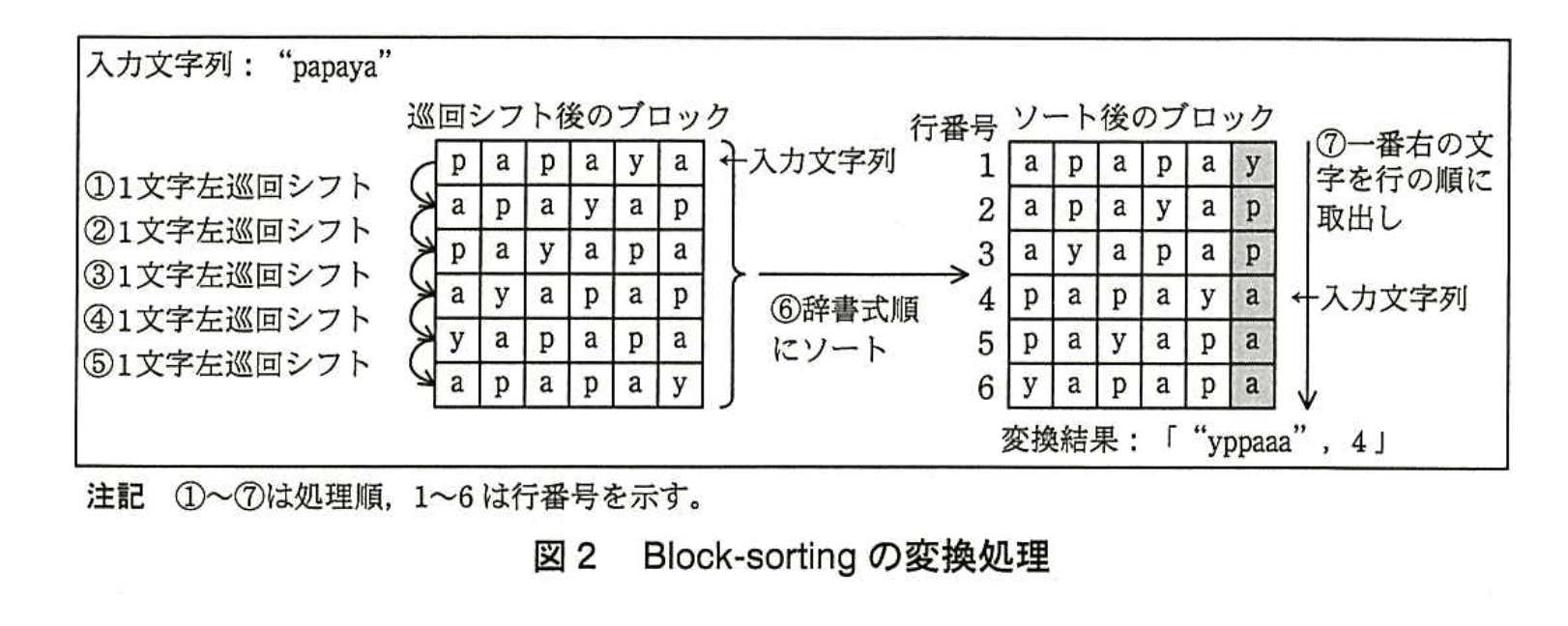
例として “papaya” を入力文字列としたときの変換処理を図2に示す。図2では、入力文字列を1文字左に巡回シフトすること(①)で文字列 “apayap” となる。さらに、もう1文字左に巡回シフトすること(②)で文字列 “payapa” となる。同様に1文字ずつ左に巡回シフトした(③〜⑤)結果の文字列を縦に並べて正方形のブロック (巡回シフト後のブロック) を作成する。
次に、このブロックを行単位で辞書式順にソートし(⑥)、ソート後のブロックを得る。ソート後のブロックの各行の文字列から一番右の文字を行の順に取り出して並べた文字列と、ソート後のブロックにおいて入力文字列に一致する行の行番号を変換結果とする(⑦)。
〔Block-sortingの復元処理〕
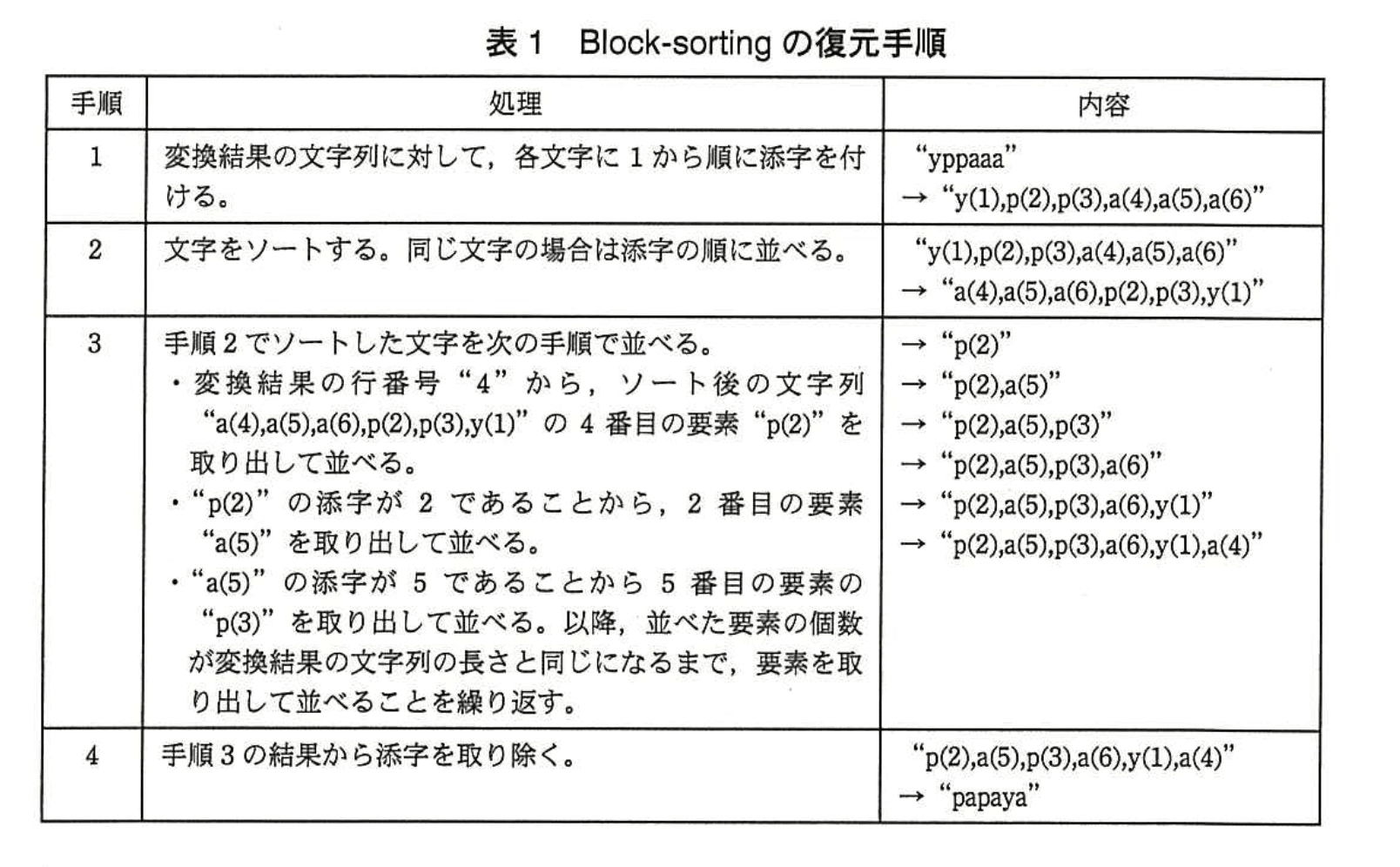
図2の変換結果「“yppaaa”、4」を復元する手順を表1に示す。
〔Block-sorting の実装〕
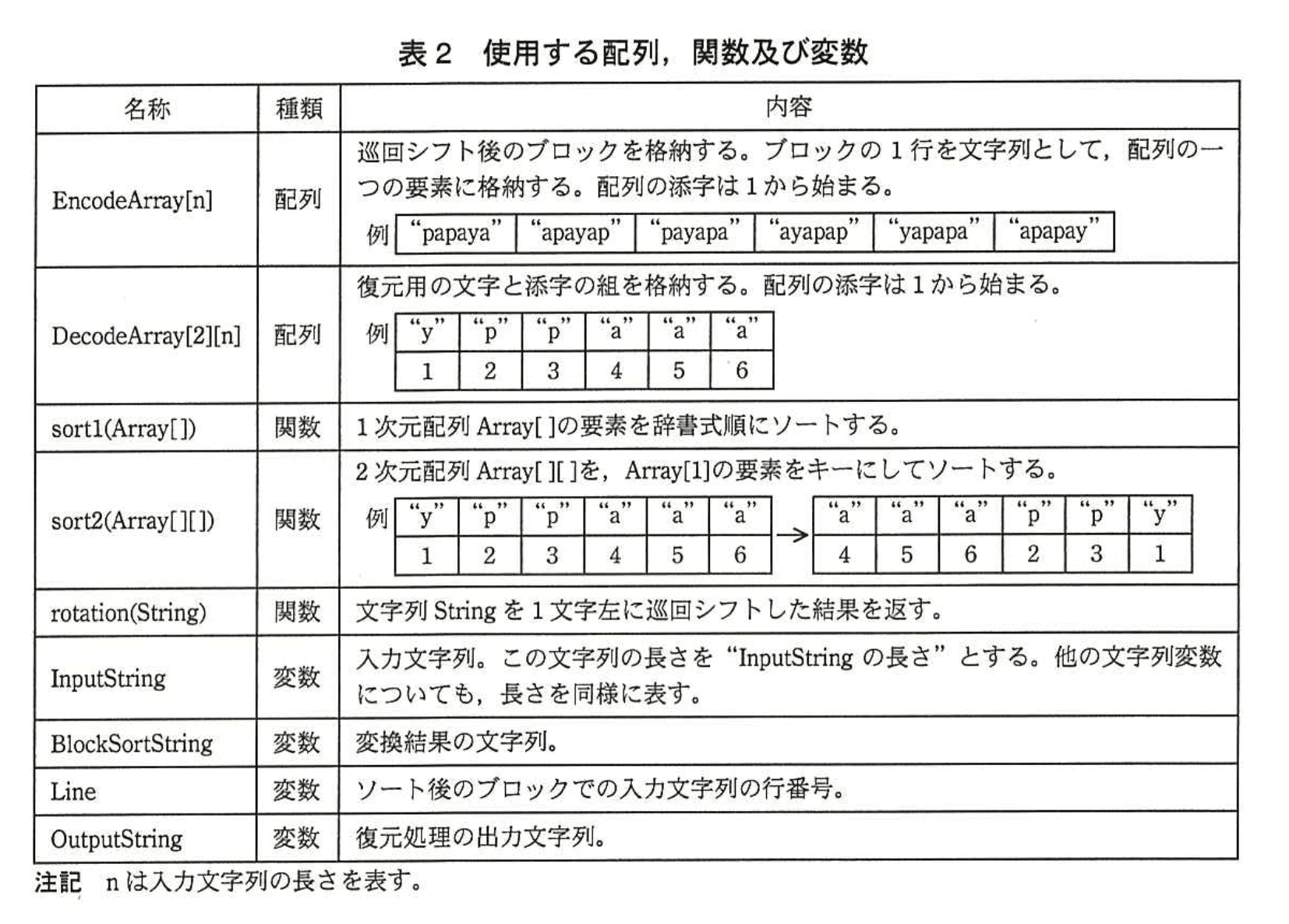
Block-sortingのプログラムを作成するために使用する配列、関数及び変数を、表2に示す。
〔変換処理関数 encode〕
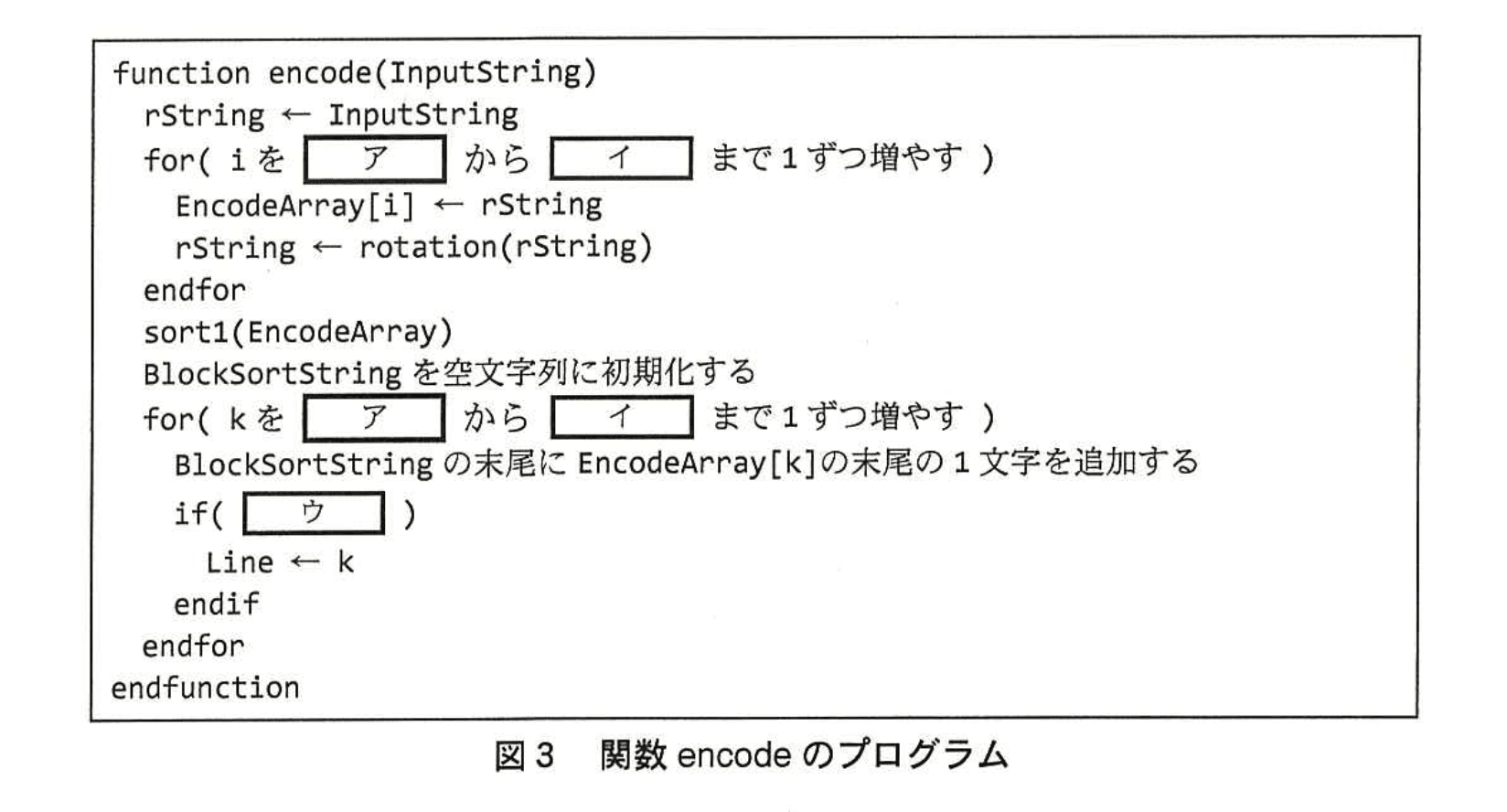
変換処理を実装した関数 encode のプログラムを図3に示す。
〔復元処理関数 decode〕
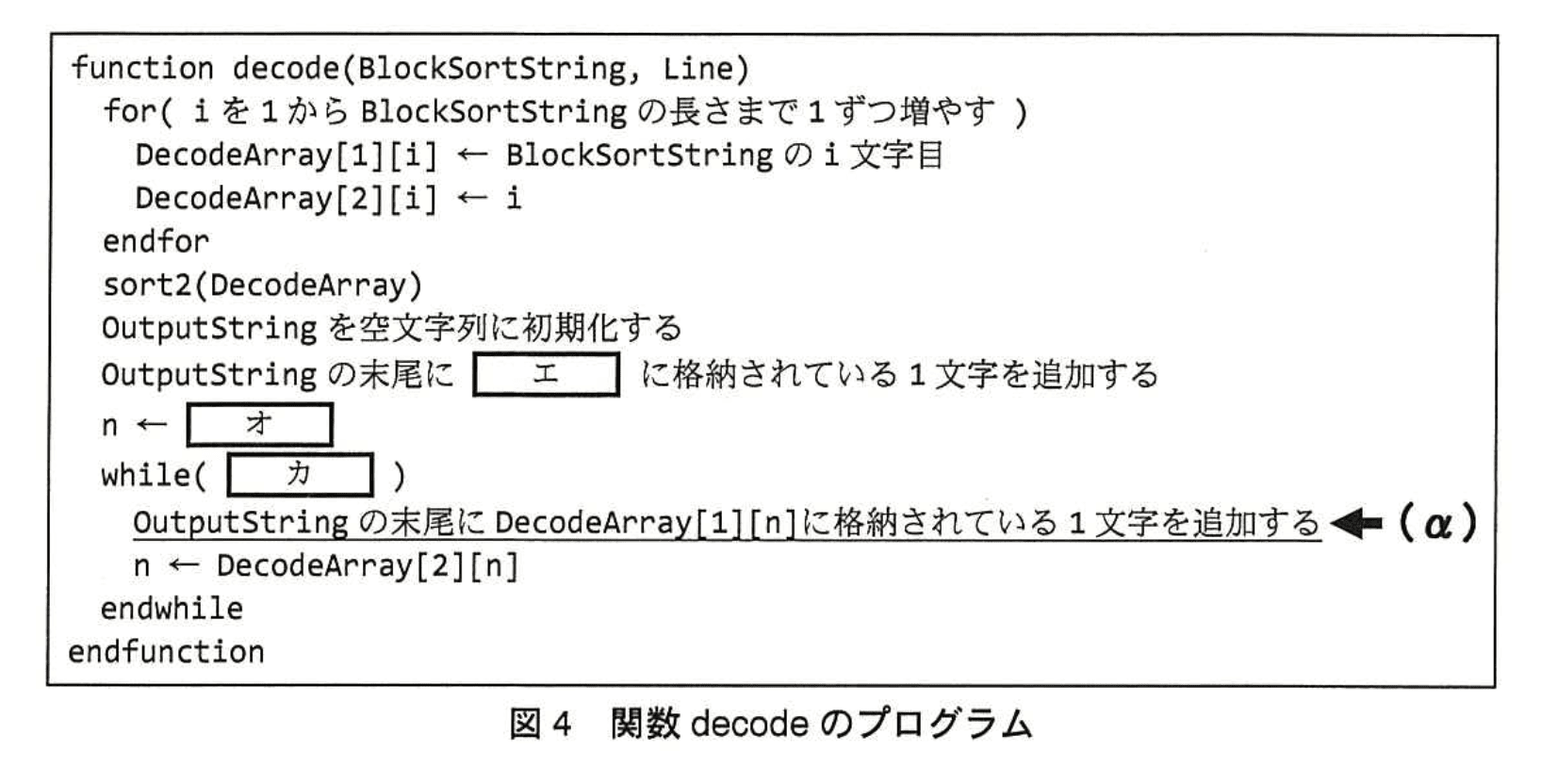
復元処理を実装した関数 decode のプログラムを図4に示す。
〔関数 sort2(Array[][]の実装〕
関数 decode の処理時間は、使用する関数 sort2(Array[][])の計算量に大きく依存する。処理時間を短くするためには、sort2(Array[][])の内部で計算量が少ないソートのアルゴリズムを使用して実装する必要がある。
処理時間の違いを確認するために複数のソートアルゴリズムを使用して関数 sort2(Array[][])を実装したところ、Array[10]の要素をキーにしてクイックソート(不安定なソート)を使用した場合には復元処理の結果が入力文字列と一致しなかった。
この場合、sort2(Array[][])が表1の手順2を正しく実装できていないので、(β)ソートアルゴリズム、ソートキーのいずれかを見直す必要がある。
設問1:
文字列“kiseki”に対してBlock-sortingを適用して変換した結果を答えよ。変換結果は図2の記法に合わせて記述すること。
模範解答
“skkeii”, 5
解説
解答の論理構成
1.【問題文】には「入力文字列を1文字左に巡回シフトすること(①)…同様に1文字ずつ左に巡回シフトした(③〜⑤)結果の文字列を縦に並べて正方形のブロック (巡回シフト後のブロック) を作成する。」とあります。
文字列“kiseki”を 0〜5 回左に巡回シフトして 6 行のブロックを作ると
文字列“kiseki”を 0〜5 回左に巡回シフトして 6 行のブロックを作ると
-
kiseki
-
isekik
-
sekiki
-
ekikis
-
kikise
-
ikisek
-
次に「このブロックを行単位で辞書式順にソートし(⑥)」ます。6 行を昇順に並べ替えると
- ekikis
- ikisek
- isekik
- kikise
- kiseki ←入力文字列
- sekiki
-
「ソート後のブロックの各行の文字列から一番右の文字を行の順に取り出して並べた文字列」として(⑦)
・ekikis → s
・ikisek → k
・isekik → k
・kikise → e
・kiseki → i
・sekiki → i
を連結すると “skkeii” になります。 -
「ソート後のブロックにおいて入力文字列に一致する行の行番号」を求めると、入力文字列“kiseki”は 5 行目なので行番号は 5 です。
以上より変換結果は
“skkeii”, 5
“skkeii”, 5
誤りやすいポイント
- 巡回シフト方向を逆にしてしまい、行列自体が間違う。
- ソート後の行番号ではなく、シフト生成時の行番号を答えてしまう。
- 同じ文字が続く場合、辞書式順で「添字の順(安定ソート)」になることを忘れ、不安定ソートの結果を用いてしまう。
- 末尾文字列を作る際に行順を崩してしまい、“skkeii” の文字順を取り違える。
FAQ
Q: 行数と文字列長が一致しないケースでも手順は同じですか?
A: はい。Block-sorting は「入力文字列の長さ=ブロックの行数=列数」という前提で動作します。長さが変わっても手順①〜⑦は不変です。
A: はい。Block-sorting は「入力文字列の長さ=ブロックの行数=列数」という前提で動作します。長さが変わっても手順①〜⑦は不変です。
Q: 辞書式順とは具体的にどの順序を指しますか?
A: 文字コード(例:ASCII)の昇順で比較し、先頭文字が同じ場合は 2 文字目以降を順に比較します。【問題文】にあるとおり、同じ文字列が複数現れる場合は「添字の順」を維持します。
A: 文字コード(例:ASCII)の昇順で比較し、先頭文字が同じ場合は 2 文字目以降を順に比較します。【問題文】にあるとおり、同じ文字列が複数現れる場合は「添字の順」を維持します。
Q: 行番号は 0 から数えてはいけませんか?
A: いけません。本問題では「配列の添字は1から始まる」と明示されているため、行番号も 1 始まりで数えます。
A: いけません。本問題では「配列の添字は1から始まる」と明示されているため、行番号も 1 始まりで数えます。
関連キーワード: Block-sorting, 巡回シフト, 辞書式ソート, 安定ソート, バローズホイラー変換
設問2:
図3中のア〜ウに入れる適切な字句を答えよ。
模範解答
ア:1
イ:InputStringの長さ
ウ:EncodeArray[k]がInputStringと同一
解説
解答の論理構成
-
ループの開始値
【問題文】では「EncodeArray[n]…配列の添字は1から始まる」と規定されています。
したがって、最初に格納する行は添字「1」であり、[ア]=1 となります。 -
ループの終了値
Block-sorting で作るブロックは入力文字列を1文字ずつ左に巡回シフトした“全通り”を並べます。
【問題文】「注記 n は入力文字列の長さを表す」
巡回シフトの回数も行数も“長さ”と同数になるので、ループの上限は「InputStringの長さ」、[イ]=InputStringの長さ です。 -
入力文字列と一致する行の特定
【問題文】「ソート後のブロックにおいて入力文字列に一致する行の行番号を変換結果とする」と明示されています。
よって if 文では「EncodeArray[k]がInputStringと同一」かを判定し、一致したときに Line に行番号 k を格納します。
これが [ウ]=EncodeArray[k]がInputStringと同一 となる理由です。
誤りやすいポイント
- 配列添字の開始を 0 と思い込み、[ア]に 0 を入れてしまう。問題文は「1から始まる」と明記。
- ループの終了条件を InputStringの長さ−1 にして行数が1行不足するミス。
- if 条件を EncodeArray[k] == rString など直前の巡回シフト文字列と比較する誤解。求めたいのは“元の入力文字列”との一致です。
FAQ
Q: 行番号はソート前とソート後のどちらでカウントしますか?
A: 【問題文】で「ソート後のブロックにおいて入力文字列に一致する行の行番号」と定義されています。必ずソート後の並び順で数えます。
A: 【問題文】で「ソート後のブロックにおいて入力文字列に一致する行の行番号」と定義されています。必ずソート後の並び順で数えます。
Q: InputString が重複行を持つ場合、Line はどれを指しますか?
A: InputString と完全一致する行は必ず一意なので重複しません。巡回シフトは元文字列をただ回転させただけで、同じ並びが2回現れることはないためです。
A: InputString と完全一致する行は必ず一意なので重複しません。巡回シフトは元文字列をただ回転させただけで、同じ並びが2回現れることはないためです。
Q: 添字付きソートを安定ソートで行う理由は?
A: 復元処理では同一文字の並び順が失われると対応表が狂います。不安定ソートを使うと「“a(4),a(5),a(6)”」の順序が崩れ、手順3で正しいリンクが張れなくなるためです。
A: 復元処理では同一文字の並び順が失われると対応表が狂います。不安定ソートを使うと「“a(4),a(5),a(6)”」の順序が崩れ、手順3で正しいリンクが張れなくなるためです。
関連キーワード: 巡回シフト, 辞書式順ソート, 安定ソート, 可逆変換
設問3:〔復元処理関数decode〕について、(1)、(2)に答えよ。
(1)図4中のエ〜カに入れる適切な字句を答えよ。
模範解答
エ:DecodeArray[1][Line]
オ:DecodeArray[2][Line]
カ:OutputStringの長さがBlockSortStringの長さより小さい
解説
解答の論理構成
-
表1の手順3は、まず行番号で指示された位置から 1 文字を取り出し、次にその添字をたどる操作を繰り返します。原文は
「変換結果の行番号 “4” から、ソート後の文字列 “a(4),a(5),a(6),p(2),p(3),y(1)” の 4 番目の要素 “p(2)” を取り出して並べる。」
と記述しており、この “4 番目の要素” が DecodeArray の行 Line に相当します。したがって、最初に追加する 1 文字は
DecodeArray[1][Line] です。 -
同じく手順3には
「“p(2)” の添字が 2 であることから、2 番目の要素 … を取り出して並べる。」
とあるため、次に参照すべき行番号は行 Line に格納されている添字、すなわち DecodeArray[2][Line] となります。 -
ループをいつ止めるかについて表1は
「並べた要素の個数が変換結果の文字列の長さと同じになるまで … を繰り返す。」
と述べています。プログラムでは “個数” を OutputString の長さで、 “変換結果の文字列の長さ” を BlockSortString の長さで表現するため、条件は
OutputString の長さが BlockSortString の長さより小さい です。
以上より、図4中の空所は
エ:DecodeArray[1][Line]
オ:DecodeArray[2][Line]
カ:OutputStringの長さがBlockSortStringの長さより小さい
エ:DecodeArray[1][Line]
オ:DecodeArray[2][Line]
カ:OutputStringの長さがBlockSortStringの長さより小さい
誤りやすいポイント
- 行番号 Line を “添字” と取り違え、DecodeArray[2][Line] ではなく DecodeArray[2][n] を初期値に入れてしまう。
- ループ終了条件を “以下” と書いてしまい、1 文字足りない/多い出力になる off-by-one エラー。
- sort2 を不安定ソートで実装し、同じ文字の順序が崩れて復元不能になる。設問本文の「(β)ソートアルゴリズム、ソートキーのいずれかを見直す必要がある」はこの典型例。
FAQ
Q: Line は 0 始まりですか 1 始まりですか?
A: 問題文の「配列の添字は1から始まる。」という注記に従い、Line も 1 始まりです。
A: 問題文の「配列の添字は1から始まる。」という注記に従い、Line も 1 始まりです。
Q: sort2 が安定ソートでなければならない理由は?
A: 表1手順2の「同じ文字の場合は添字の順に並べる。」を守るには安定ソートが必要です。不安定ソートでは添字順が保存されず、復元が破綻します。
A: 表1手順2の「同じ文字の場合は添字の順に並べる。」を守るには安定ソートが必要です。不安定ソートでは添字順が保存されず、復元が破綻します。
Q: OutputString と BlockSortString の長さが等しい時にループを抜けるのはなぜ?
A: 表1手順3にある「並べた要素の個数が変換結果の文字列の長さと同じになるまで」処理を続けるためです。
A: 表1手順3にある「並べた要素の個数が変換結果の文字列の長さと同じになるまで」処理を続けるためです。
関連キーワード: Block-sorting, Burrows–Wheeler変換, 安定ソート, 復元アルゴリズム, 巡回シフト
設問3:〔復元処理関数decode〕について、(1)、(2)に答えよ。
(2)BlockSortStringの長さがpのとき、図4中の下線(α)の処理の実行回数を答えよ。
模範解答
p−1
解説
解答の論理構成
- 復元処理 decode は、まず OutputString に1文字だけ追加します。
引用:「OutputString の末尾に エ に格納されている 1 文字を追加する」 - その後、while ループ内の下線部 (α) で1回の繰返しにつき1文字ずつ追加します。
引用:「OutputString の末尾に DecodeArray[1][n] に格納されている 1 文字を追加する ← (α)」 - ループの継続条件は カ で示されており、表1の手順3に対応します。
引用:「並べた要素の個数が変換結果の文字列の長さと同じになるまで…繰り返す。」 - 問題文で「BlockSortString の長さが p」と与えられていますから、最終的に OutputString には p 文字が入るまで繰返します。
- すでに1文字はループ外で追加済みなので、残りは p-1 文字。
- 従って、下線部 (α) が実行される回数は p-1 回となります。
誤りやすいポイント
- ループ外で1文字追加していることを見落とし、p 回と答えてしまう。
- 表1の手順3は「要素を取り出して並べる」処理全体を指すと誤解し、(α) の部分的なカウントを間違える。
- カ の条件を「DecodeArray が空になるまで」などと曲解し、実際の停止タイミングを読み違える。
FAQ
Q: カ の具体的な条件は何ですか?
A: 一般的には「OutputString の長さ < BlockSortString の長さ」のように、復元対象の長さに達するまでループする条件になります。
A: 一般的には「OutputString の長さ < BlockSortString の長さ」のように、復元対象の長さに達するまでループする条件になります。
Q: もし BlockSortString が長さ1のときでも同じ式で良いのですか?
A: はい。長さ1の場合、最初に1文字追加した時点で OutputString は長さ1となり、while 条件が偽になるため (α) は0回実行されます。式 p-1 は 1-1=0 となり整合します。
A: はい。長さ1の場合、最初に1文字追加した時点で OutputString は長さ1となり、while 条件が偽になるため (α) は0回実行されます。式 p-1 は 1-1=0 となり整合します。
Q: (α) の中で n ← DecodeArray[2][n] と更新していますが、これは回数に影響しますか?
A: 回数自体には影響しません。n の更新は取り出す次の文字位置を決めるだけで、ループの終了判定はあくまで カ で行われます。
A: 回数自体には影響しません。n の更新は取り出す次の文字位置を決めるだけで、ループの終了判定はあくまで カ で行われます。
関連キーワード: Block-sorting, 巡回シフト, 辞書式順ソート, 可逆変換, 安定ソート
設問4:
本文中の下線(β)について、ソートアルゴリズムを見直す場合とソートキーを見直す場合のそれぞれについて、どのように見直せばよいかを30字以内で述べよ。
模範解答
ソートアルゴリズム:同じ文字の場合に元の順序を保持するソートを使用する。
ソートキー:2番目のソートキーにArray[2]の要素を加える。
解説
解答の論理構成
- 表1 手順2 には「“同じ文字の場合は添字の順に並べる。”」と明記されています。
これはソートの結果が安定(元の並びを保持)していることを要求しています。 - ところが問題文は「Array[ ][1]の要素をキーにしてクイックソート(不安定なソート)を使用した場合には復元処理の結果が入力文字列と一致しなかった。」と述べています。
不安定ソートでは同じ文字の相対順が崩れ、添字に従うという手順2の条件を満たせず、復元が失敗します。 - よって(β)の見直し案①
「同じ文字の場合に元の順序を保持するソートを使用する」=安定ソートに切替える、が正解となります。 - 見直し案②はソートキーの追加です。手順2の条件をキーで強制的に保証するため、一次キーに文字、二次キーに添字を設定すれば、不安定ソートでも結果は正しくなります。
そこで「2番目のソートキーにArray[2]の要素を加える」と記述します。
誤りやすいポイント
- クイックソートが常に誤りになると決めつける。安定ソートに改良したクイックソート(例えば安定版実装)なら問題ありません。
- 「添字で並べる」処理をループで別途行えばよいと考え、ソート自体の安定性を無視する。
- ソートキー追加案で一次キーを添字、二次キーを文字と誤って設定し、辞書式順を壊してしまう。
FAQ
Q: なぜ添字を二次キーにするだけで復元が成功するのですか?
A: 文字が同じ場合に「添字の順」となる条件をソートキーで直接表現できるためです。二次キーが添字なら、不安定ソートでも結果は安定ソートと同じ並びになります。
A: 文字が同じ場合に「添字の順」となる条件をソートキーで直接表現できるためです。二次キーが添字なら、不安定ソートでも結果は安定ソートと同じ並びになります。
Q: 安定ソートならどのアルゴリズムがお勧めですか?
A: 配列サイズが比較的小さければ挿入ソート、一般にはマージソートやTimsortが高速で安定です。
A: 配列サイズが比較的小さければ挿入ソート、一般にはマージソートやTimsortが高速で安定です。
Q: 不安定ソートを使い続けたい場合の注意点は?
A: 必ず「文字+添字」の複合キーにし、添字を数値として比較してください。文字列連結キーにすると桁数の違いで誤動作します。
A: 必ず「文字+添字」の複合キーにし、添字を数値として比較してください。文字列連結キーにすると桁数の違いで誤動作します。
関連キーワード: 安定ソート, 二次キー, クイックソート, 辞書式順, 復元処理
