応用情報技術者 2017年 春期 午後 問03
探索アルゴリズムに関する次の記述を読んで、設問1~5に答えよ。
1個ずつの重さが異なる商品を組み合わせ、合計の重さが指定された値になるようにしたい。
この問題を次のように簡略化し、解法を考える。
 例えば、指定された n 個の数が (10, 34, 55, 77)、目標 X が 100 とすると、選択した数の組合せは (10, 34, 55)、選択した数の合計(以下、合計という)は 99 となる。
この問題を解くためのアルゴリズムを考える。
指定された n 個の数の中から任意の個数を選択することから、各数に対して、選択する、選択しない、の二つのケースがある。数を一つずつ調べて、次の数がなくなるまで“選択する”、“選択しない”の分岐を繰り返すことで、任意の個数を選択する全ての組合せを網羅できる。この場合の分けを図1に示す。
例えば、指定された n 個の数が (10, 34, 55, 77)、目標 X が 100 とすると、選択した数の組合せは (10, 34, 55)、選択した数の合計(以下、合計という)は 99 となる。
この問題を解くためのアルゴリズムを考える。
指定された n 個の数の中から任意の個数を選択することから、各数に対して、選択する、選択しない、の二つのケースがある。数を一つずつ調べて、次の数がなくなるまで“選択する”、“選択しない”の分岐を繰り返すことで、任意の個数を選択する全ての組合せを網羅できる。この場合の分けを図1に示す。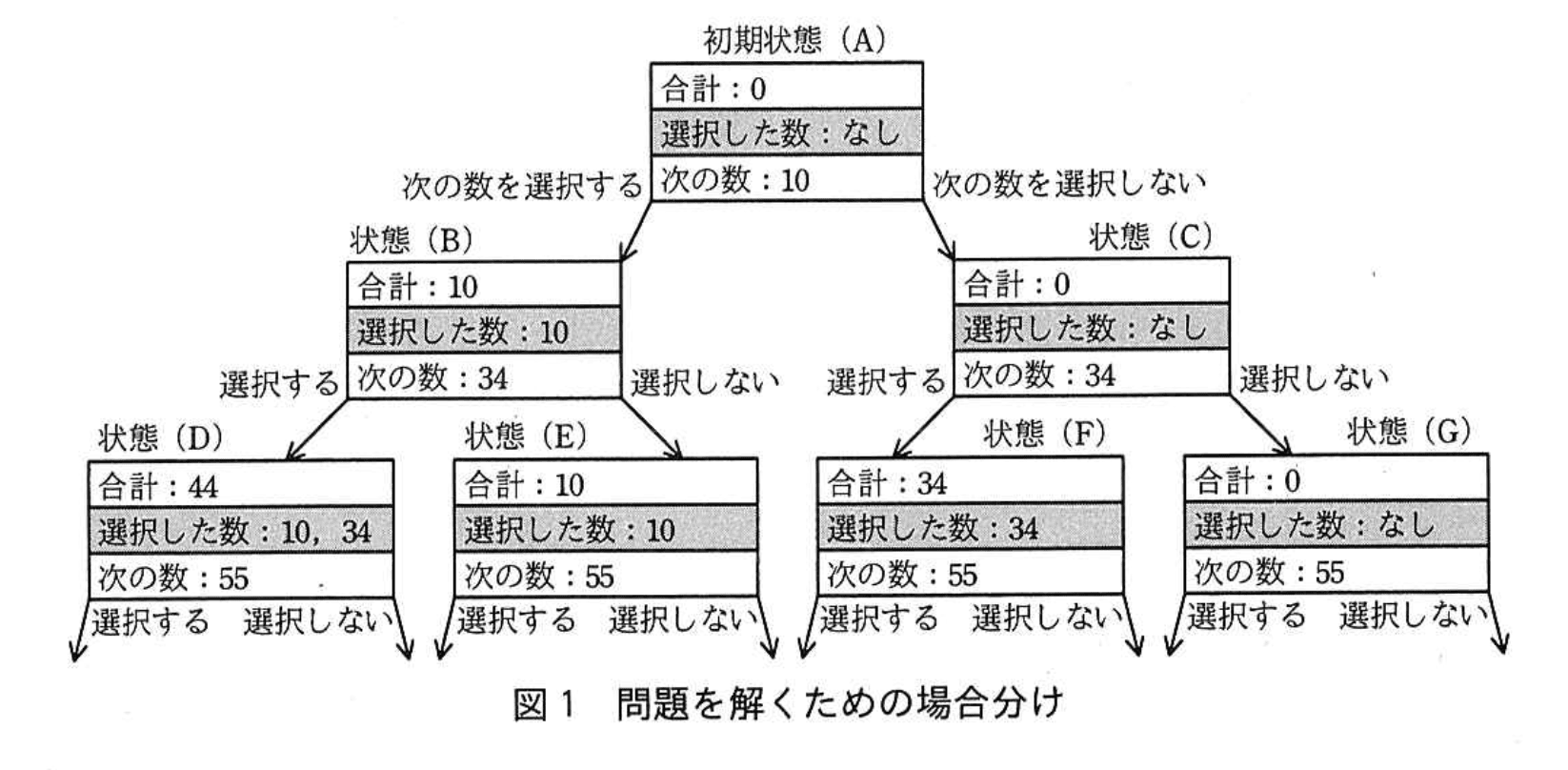
〔データ構造の検討〕
図1の場合分けをプログラムで実装するために、必要となるデータ構造を検討する。
まず、図1の場合分けを木構造とみなしたときの各ノード(状態)を構造体 Status で表す。構造体 Status は要素として “合計”、“選択した数”、“次の数” をもつ必要がある。
プログラムで使用する配列、変数及び構造体を表1に示す。

〔探索の手順〕
図1に示した場合分けの初期状態(A)からの探索手順を、次の(1)~(3)に示す。
① これから探索する状態を格納しておくためのデータ構造として、キューを使用する場合とスタックを使用する場合で、探索の順序が異なる。
また、②データ構造によってメモリの使用量も異なる。ここではキューを使用することにする。
(1) 初期状態(A)を作成し、キューに格納する。 キューが空になるまで(2)、(3)を繰り返す。
(2) キューに格納されている状態を一つ取り出す。 これを “取得した状態” と呼ぶ。
“取得した状態” の評価を行う(状態を評価する手順は次の “〔取得した状態〕の評価” に示す)。
(3) “取得した状態”に次の数がある場合、次の数を選択した状態と、次の数を選択しない状態をそれぞれ作成し、順にキューに格納する。
〔“取得した状態”の評価〕
“取得した状態”を評価し、“解答の候補”を設定する手順を、次の(1)、(2)に示す。
(1) “解答の候補”がnullの場合、“取得した状態”を“解答の候補”にする。
(2) “解答の候補”がnullでない場合、“解答の候補”の合計と“取得した状態”の合計をそれぞれ目標Xと比較して、後者の方が目標Xに近い場合、“取得した状態”を“解答の候補”にする。
探索の手順が終了した時点の“解答の候補”を解答とする。
探索を行うための関数を表2に示す。

〔探索処理関数 treeSearch〕
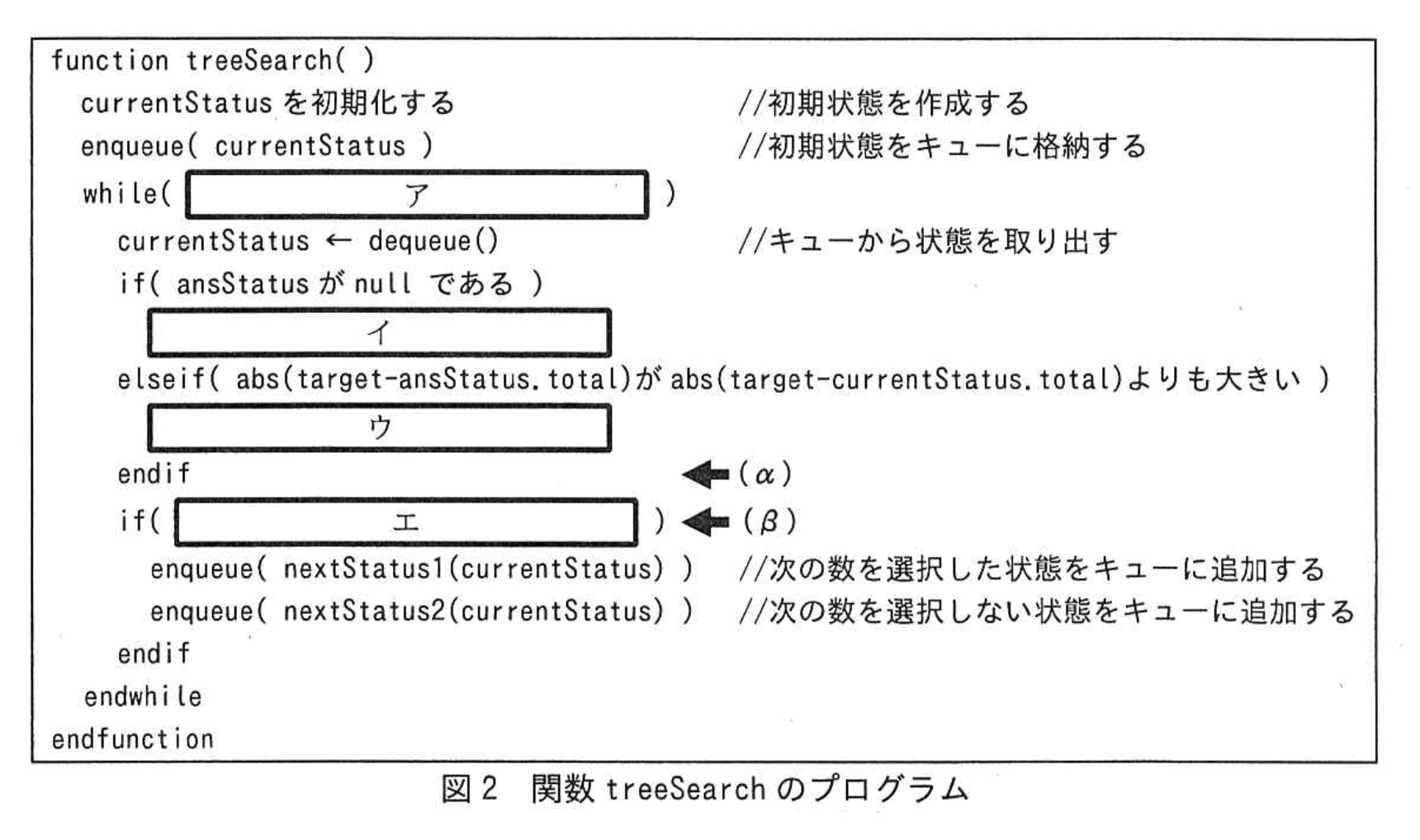
探索処理を実装した関数 treeSearch のプログラムを図2に示す。
ここで、表1で定義した配列及び変数は、グローバル変数とする。
〔探索回数の削減〕
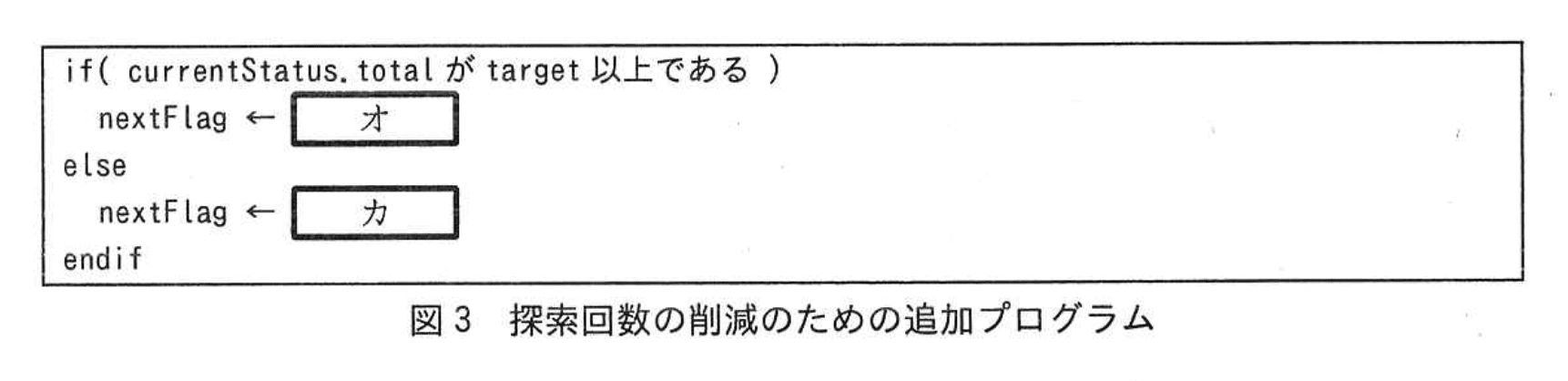
関数 treeSearch で実装した方法では、n が大きくなるにつれて“取得した状態”を評価する回数(以下、探索回数という)も増大するが、不要な探索処理を行わないようにすることによって、③探索回数を削減することができる。探索回数の削減のために、探索を継続するかどうかを示すフラグを新たに用意し、次の (1)〜(3) の処理を追加することにした。
(1) “取得した状態”の合計が目標 X 以上の場合、以降の状態で数を選択しても合計は目標 X から離れてしまい、“解答の候補”にはならない。以降の状態の探索を不要とするために、フラグを探索停止に設定する。
(2) (1) 以外の場合、フラグを探索継続に設定する。
(3) フラグが探索中止の場合、“取得した状態”からの分岐を探索しないようにする。
探索回数の削減のために追加する変数を表3に示す。

探索回数の削減を実装するために、図2中の(α)の行と(β)の行の間に図3のプログラムを追加し、(β)を“if エ かつ、nextFlag が“Y”である)”に修正した。
設問1:
図2中の ア〜エ に入れる適切な符号を答えよ。
模範解答
ア:isEmpty( )が0である
イ:ansStatus ← currentStatus
ウ:ansStatus ← currentStatus
エ:currentStatus.nextIndexが0ではない
解説
解答の論理構成
-
while( ア ) の判定
【問題文】には「キューが空になるまで(2)、(3)を繰り返す。」とあります。
さらに表2の isEmpty( ) は「キューが空ならば 1 を、そうでなければ 0 を返す。」と定義されています。
よってループ継続条件は「キューが空でない」=isEmpty( ) が 0 であるとなり、
ア=isEmpty( )が0である です。 -
if( ansStatus が null である ) 内の処理
“解答の候補”がまだ存在しない場合は現在取り出した状態を候補にします。
【問題文】「(1) “解答の候補”がnullの場合、“取得した状態”を“解答の候補”にする。」
したがって イ=ansStatus ← currentStatus です。 -
elseif( … ) 内で距離を比較した後の処理
【問題文】「後者の方が目標Xに近い場合、“取得した状態”を“解答の候補”にする。」
比較結果が真なら同じく代入を行うので、ウ=ansStatus ← currentStatus です。 -
子ノード生成を行うかどうかの判定
【問題文】「“取得した状態”に次の数がある場合…キューに格納する。」
次の数の有無は nextIndex が 0 かどうかで判別できるよう表1に定義されています。
よって エ=currentStatus.nextIndexが0ではない となります。
以上により模範解答と一致します。
誤りやすいポイント
- isEmpty( ) の返り値を逆に解釈し、isEmpty()が1であると書いてしまう。
- ansStatus の更新条件を「小さい方」「大きい方」とあいまいに覚え、目標値との差の絶対値比較を忘れる。
- nextIndex の終了判定を n と比較してしまうなど、0 になる仕様を見落とす。
- キューとスタックを混同し、幅優先探索と深さ優先探索の制御を取り違える。
FAQ
Q: スタック(深さ優先探索)に置き換えると ア~エ は変わるのですか?
A: while の継続条件と “解答の候補”更新処理は同じですが、enqueue/dequeue 部分をスタック用の push/pop に替える必要があります。判定式自体は変わりません。
A: while の継続条件と “解答の候補”更新処理は同じですが、enqueue/dequeue 部分をスタック用の push/pop に替える必要があります。判定式自体は変わりません。
Q: nextFlag による枝刈りは必須ですか?
A: 正解を得るだけなら必須ではありません。ただし探索木が指数的に広がるため、枝刈り(分枝限定)を入れると大幅に高速化できます。
A: 正解を得るだけなら必須ではありません。ただし探索木が指数的に広がるため、枝刈り(分枝限定)を入れると大幅に高速化できます。
Q: 同じ重さが複数ある場合はどう修正しますか?
A: 問題条件が「同じ数は1回しか選択できない」から外れます。重複を許す場合は、配列の各要素に“残り個数”を追加し、nextStatus1 作成時に個数をデクリメントするなどの拡張が必要です。
A: 問題条件が「同じ数は1回しか選択できない」から外れます。重複を許す場合は、配列の各要素に“残り個数”を追加し、nextStatus1 作成時に個数をデクリメントするなどの拡張が必要です。
関連キーワード: 幅優先探索, キュー, 状態空間, 枝刈り
設問2:
図3中の オ 、カ に入れる適切な符号を答えよ。
模範解答
オ:“N”
カ:“Y”
解説
解答の論理構成
-
問題文は探索回数削減のためにフラグ nextFlag を導入し、
“(1) “取得した状態”の合計が目標 X 以上の場合、以降の状態で数を選択しても合計は目標 X から離れてしまい、“解答の候補”にはならない。以降の状態の探索を不要とするために、フラグを探索停止に設定する。”
と明示しています。
── ここで「探索停止」を表す符号は “N” です。 -
また、
“(2) (1) 以外の場合、フラグを探索継続に設定する。”
とあり、「探索継続」を表す符号は “Y” です。 -
図3は if 文でこの方針をコード化しており、if( currentStatus.total が target 以上である ) nextFlag ← オ else nextFlag ← カ endifとなっています。
-
よって、
・currentStatus.total ≥ target のとき オ は “N”
・それ以外のとき カ は “Y”
が正解になります。
誤りやすいポイント
- “目標 X 以上になったらゴールに近づいた”と誤解し、継続フラグ “Y” を選んでしまう。問題文では「目標 X から離れてしまい…探索を不要」としており逆です。
-
と >= の境界を勘違いするケース。問題文は “目標 X 以上” と明記しているので等号を含めます。
- フラグ名を「継続=N」「中止=Y」と逆に暗記してしまうミス。
FAQ
Q: 合計がちょうど target と一致した場合もフラグは “N” ですか?
A: はい。“目標 X 以上” に一致も含まれるため探索停止 “N” になります。
A: はい。“目標 X 以上” に一致も含まれるため探索停止 “N” になります。
Q: 今回キューを使っていますが、スタックを用いた深さ優先探索でも同じフラグ設定は有効ですか?
A: 有効です。探索の順序は変わりますが、「合計が目標 X 以上なら枝刈り」という判定基準はデータ構造に依存しません。
A: 有効です。探索の順序は変わりますが、「合計が目標 X 以上なら枝刈り」という判定基準はデータ構造に依存しません。
Q: nextFlag を導入しても最適解を逃す危険はありませんか?
A: ありません。目標 X を超えた時点で、その枝からは合計がさらに大きくなるか変わらないため、“目標 X に最も近い” という評価基準では候補になり得ないからです。
A: ありません。目標 X を超えた時点で、その枝からは合計がさらに大きくなるか変わらないため、“目標 X に最も近い” という評価基準では候補になり得ないからです。
関連キーワード: 幅優先探索, 枝刈り, キュー, 状態空間探索, フラグ制御
設問3:本文中の下線①について、次の (1)、(2) の場合の評価の順序を、図1中の状態の記号 (A)~(G) を用いてそれぞれ答えよ。ここで、分岐の際は左側のノードから先にデータ構造に格納することとする。本問では (D)、(E)、(F)、(G) の後の状態は考慮しなくてよい。
(1)〔探索の手順〕での記述どおり、データ構造にキューを使用した場合
模範解答
(A)→(B)→(C)→(D)→(E)→(F)→(G)
解説
解答の論理構成
-
キュー利用時の探索順序を問題文は次のように規定しています。
- 【問題文】「① これから探索する状態を格納しておくためのデータ構造として、キューを使用する場合とスタックを使用する場合で、探索の順序が異なる」
- 【問題文】「(1) 初期状態(A)を作成し、キューに格納する。 キューが空になるまで(2)、(3)を繰り返す。」
- 【問題文】「(3) “取得した状態”に次の数がある場合、次の数を選択した状態と、次の数を選択しない状態をそれぞれ作成し、順にキューに格納する。」
-
キュー(FIFO)に格納する際は「左側のノードから先にデータ構造に格納する」と明示されています。このため
- 初期状態(A)を enqueue
- dequeue で (A) を取得し、(B) → (C) の順に enqueue
- 次にキュー先頭の (B) を dequeue し、(D) → (E) を enqueue
- 次に (C) を dequeue し、(F) → (G) を enqueue
ここで (D)、(E)、(F)、(G) の後の状態は本問では考慮不要と指示されています。 -
以上より、dequeue で取り出される順番は
(A) → (B) → (C) → (D) → (E) → (F) → (G) -
よって模範解答は
【模範解答】「(A)→(B)→(C)→(D)→(E)→(F)→(G)」となります。
誤りやすいポイント
- 「スタック(LIFO)のときと同じだろう」と思い込み、(A)→(B)→(D)…の深さ優先順にしてしまう。
- enqueue の順番を誤り、(C)→(B) の順で入れてしまう。キューでは「先に格納したものが先に取り出される」ことを忘れがちです。
- 本問の指示「左側のノードから先」を見落として右→左で登録し、(A)→(C)→(B)…と逆順になる。
- (D) 以降のノードを無意識に追い掛け、余計なノードまで列挙してしまう。設問文に「(D)、(E)、(F)、(G) の後の状態は考慮しなくてよい」とあります。
FAQ
Q: キューとスタックを選んだ場合の最大の違いは何ですか?
A: キューは FIFO なので幅優先探索、スタックは LIFO なので深さ優先探索になります。取り出し順が変わるため評価順序も大きく変わります。
A: キューは FIFO なので幅優先探索、スタックは LIFO なので深さ優先探索になります。取り出し順が変わるため評価順序も大きく変わります。
Q: enqueue する際の左右の順序は常に重要ですか?
A: はい。左右どちらを先に格納するかで同階層内の評価順序が変わります。問題が指定していない場合でも、実装方針を決めて一貫させる必要があります。
A: はい。左右どちらを先に格納するかで同階層内の評価順序が変わります。問題が指定していない場合でも、実装方針を決めて一貫させる必要があります。
Q: 本問で (D) 以降を無視できる理由は?
A: 設問が「(D)、(E)、(F)、(G) の後の状態は考慮しなくてよい」と限定しているためです。評価対象ノードが決まっていれば、その後の展開を列挙する必要はありません。
A: 設問が「(D)、(E)、(F)、(G) の後の状態は考慮しなくてよい」と限定しているためです。評価対象ノードが決まっていれば、その後の展開を列挙する必要はありません。
関連キーワード: 幅優先探索, FIFOキュー, 探索木, ノード展開
設問3:本文中の下線①について、次の (1)、(2) の場合の評価の順序を、図1中の状態の記号 (A)~(G) を用いてそれぞれ答えよ。ここで、分岐の際は左側のノードから先にデータ構造に格納することとする。本問では (D)、(E)、(F)、(G) の後の状態は考慮しなくてよい。
(2)本文中のキューを全てスタックに置き換えた場合
模範解答
(A)→(C)→(G)→(F)→(B)→(E)→(D)
解説
解答の論理構成
-
本文の下線①は
「探索する状態を格納しておくためのデータ構造として、キューを使用する場合とスタックを使用する場合で、探索の順序が異なる」
と述べています。キュー(FIFO)をスタック(LIFO)に置き換えると取り出し順が逆転する点がカギです。 -
さらに問題文では
「分岐の際は左側のノードから先にデータ構造に格納することとする」
と指定されています。
つまり、ある状態を取り出した直後に
① 左側の子ノード
② 右側の子ノード
の順で push します。 -
スタックは LIFO ですから、push された「②右側」が上に積まれ、先に pop されます。
この“後入れ先出し”の性質が、探索順序を次のように決定します。① 初期状態 (A) を pop → 子ノードを左(B)・右(C) の順に push
→ スタック上部は (C)。② (C) を pop → 子ノードを左(F)・右(G) の順に push
→ スタック上部は (G)。③ (G) を pop(本問では (G) の後の状態は考慮不要)
→ 次にスタック最上位に残るのは (F)。④ (F) を pop(同上)
→ スタック最上位は (B)。⑤ (B) を pop → 子ノードを左(D)・右(E) の順に push
→ スタック上部は (E)。⑥ (E) を pop(同上)
→ スタック上部は (D)。⑦ (D) を pop して終了。 -
以上より、スタック版の評価順序は
(A)→(C)→(G)→(F)→(B)→(E)→(D)
となり、模範解答と一致します。
誤りやすいポイント
- 「左側を先に push したのだから左側を先に評価する」と思い込み、FIFO と LIFO の違いを取り違える。
- push するときの順番を逆にしてしまい (A)→(B)… と BFS と同じ並びにしてしまう。
- (D)、(E)、(F)、(G) の後の状態は「考慮しなくてよい」という条件を読み落とし、深く追って計算を崩す。
FAQ
Q: キューとスタックの違いを覚えるコツはありますか?
A: “Queue は列(Line)、Stack は皿の積み重ね”とイメージすると直感的です。Queue は先頭から出る、Stack は上から出ると視覚化すると混同しにくくなります。
A: “Queue は列(Line)、Stack は皿の積み重ね”とイメージすると直感的です。Queue は先頭から出る、Stack は上から出ると視覚化すると混同しにくくなります。
Q: push する順序は常に「左→右」で良いのですか?
A: 本問では「左側のノードから先にデータ構造に格納する」と明記されています。実装によっては逆順で push し、LIFO/FIFO の性質と組み合わせて目的の順序を作る場合もあります。
A: 本問では「左側のノードから先にデータ構造に格納する」と明記されています。実装によっては逆順で push し、LIFO/FIFO の性質と組み合わせて目的の順序を作る場合もあります。
Q: 深さ優先探索と幅優先探索でメモリ使用量が異なる理由は?
A: 深さ優先(スタック)は現在の経路分だけを保持すればよいのに対し、幅優先(キュー)は同一レベルの全ノードを保持します。そのためレベル幅が大きい木ではキューの方がメモリ消費が大きくなります。
A: 深さ優先(スタック)は現在の経路分だけを保持すればよいのに対し、幅優先(キュー)は同一レベルの全ノードを保持します。そのためレベル幅が大きい木ではキューの方がメモリ消費が大きくなります。
関連キーワード: 深さ優先探索, 幅優先探索, スタック, キュー, 木構造
設問4:
本文中の下線②について、データ構造にキューを使用した場合に、キューが必要とするメモリ使用量の最小値として適切な符号を解答群の中から選び、記号で答えよ。
ここで、問題における数の個数を n、キューに状態を一つ格納するために必要なメモリ使用量を m とする。
解答群
ア:
イ:
ウ:
エ:
オ:
模範解答
ア
解説
解答の論理構成
-
木構造の幅優先探索では、同じ深さのノードを キュー に保持しながら次の深さを生成します。
【問題文】には「① これから探索する状態を格納しておくためのデータ構造として、キューを使用する場合とスタックを使用する場合で、探索の順序が異なる。また、②データ構造によってメモリの使用量も異なる。」とあります。 -
深さを 0〜n とすると、
・深さ 0(初期状態)は 個
・深さ 1 は 個
・…
・深さ n は 個
――各数に対して「選択する/選択しない」の2分岐であるためです。 -
幅優先探索の 最大同時格納数 は「ある深さのすべてのノードをキューに入れ終えた瞬間」です。
最もノード数が多いのは最下層(深さ n)なので、その数は 個になります。 -
キューに状態を一つ格納するためのメモリを m とすると、必要メモリの最小(=保証するための上限)値は
-
解答群より「ア:」が該当します。
誤りやすいポイント
- 「最小値」を“平均的な”メモリ量と誤解し、 や を選びやすいです。「常に正しく動作させるのに最低限必要」=「ピーク時の確保量」と読み替えることが肝要です。
- 深さ n−1 で止めてしまい「 個」と数え損ねるケース。すべての深さ n−1 ノードを処理し終えると 深さ n の全葉ノード がキューに溜まる点を見落とさないようにしましょう。
- DFS と混同してスタックのメモリ量を考えてしまうミス。設問は明示的に「キューを使用した場合」です。
FAQ
Q: スタック(深さ優先探索)ならメモリ量はどうなりますか?
A: 最深でも再帰(またはスタック)に同時に積まれるのは 深さ n+1 件程度なので、必要メモリはおおよそ になります。
A: 最深でも再帰(またはスタック)に同時に積まれるのは 深さ n+1 件程度なので、必要メモリはおおよそ になります。
Q: 途中で “探索回数の削減” を入れてもメモリ上限は変わりますか?
A: 枝刈りにより実際の使用量は減少しますが、「最悪の場合」の葉がすべて残る可能性は残るため、理論上の上限 は変わりません。
A: 枝刈りにより実際の使用量は減少しますが、「最悪の場合」の葉がすべて残る可能性は残るため、理論上の上限 は変わりません。
Q: n が大きいとメモリが現実的でなくなります。実務ではどう対処しますか?
A: 分割統治(meet-in-the-middle)、動的計画法、ビット DP など、メモリと計算量を抑える別アルゴリズムを選択します。
A: 分割統治(meet-in-the-middle)、動的計画法、ビット DP など、メモリと計算量を抑える別アルゴリズムを選択します。
関連キーワード: 幅優先探索, 二分木, 計算量, メモリ上限, 枝刈り
設問5:
本文中の下線③における探索回数の削減を更に効率的に行うために、“指定されたn個の数”に実施しておくことが有効な事前処理の内容を 20 字以内で、その理由を 25 字以内でそれぞれ述べよ。
模範解答
内容:数を降順にソートしておく。
理由:早い段階で探索を打ち切ることができる。
解説
解答の論理構成
- 問題では「“取得した状態”の合計が目標 X 以上の場合、以降の状態で数を選択しても合計は目標 X から離れてしまい、“解答の候補”にはならない」と明言し、下線③として探索打切り条件を導入しています。
- この条件は “合計が大きくなりやすい” 分岐ほど早く判定されるほど効果的です。
- そこで「指定された n 個の数」を大きい順、すなわち降順に並べ替えておけば、最初に加算候補になるのは最大値です。
- 最大値を含めた時点で合計が目標 X を超える可能性が高まるため、上記の打切り条件が「早い段階」で発動しやすくなります。
- よって事前処理として「数を降順にソートしておく」ことで、「探索回数を削減することができる」という結論になります。
誤りやすいポイント
- 「昇順に並べれば小刻みに合計を調整できるから有利」と誤解しがちですが、本問題の打切り判定は “超えたら即終了” なので逆効果です。
- 配列 numbers[] を並べ替えると添字が変わるため、nextIndex の更新ロジックを忘れると整合が取れなくなります。
- キュー探索(BFS)なので「大きい数から処理しても順番は変わらない」と思い込むミス。実際にはノード生成順が変わり、打切り回数に大きく影響します。
FAQ
Q: なぜ「降順」でなく「ランダム」では駄目なのですか?
A: ランダムでは大きい数が後半に回る恐れがあり、打切り条件が働くタイミングが遅くなるからです。
A: ランダムでは大きい数が後半に回る恐れがあり、打切り条件が働くタイミングが遅くなるからです。
Q: numbers[] を変更すると元の順序が失われますが支障は?
A: 探索は組合せを網羅する目的なので順序は不要です。numbers[] に対する操作は添字だけで管理されているため、降順でも問題ありません。
A: 探索は組合せを網羅する目的なので順序は不要です。numbers[] に対する操作は添字だけで管理されているため、降順でも問題ありません。
Q: 打切り条件を「合計 > X+α」に変えた方が良いですか?
A: 本問題は「目標 X に最も近い合計」を探すため、単純に「目標 X 以上」で止めても十分に効果があります。α を設けると逆に最適解を見逃す恐れがあります。
A: 本問題は「目標 X に最も近い合計」を探すため、単純に「目標 X 以上」で止めても十分に効果があります。α を設けると逆に最適解を見逃す恐れがあります。
関連キーワード: 降順ソート, 枝刈り, 幅優先探索, 組合せ最適化
