応用情報技術者 2022年 春期 午後 問08
システム間のデータ連携方式に関する次の記述を読んで、設問1~5に答えよ。
バスターミナルを運営するC社は、再開発に伴い、これまで散在していた小規模なバスターミナルを統合した、新たなバスターミナル(以下、新バスターミナルという)を運営することになった。
C社が運営する新バスターミナルには、複数のバス運行事業者(以下、運行事業者という)の高速バス、観光バス、路線バスが発着する。これら高速バスと観光バスは指定席制又は定員制であり、空席がない場合は乗車できない。乗車券の販売は、各運行事業者が用意する販売端末やホームページで行う。
新バスターミナルでは、新バスターミナルシステムとして、バスの発着を管理する運行管理システム、及びバスの発車時刻、発車番線、空席の有無などを利用者に案内する案内表示システムを導入することになり、C社の情報システム部に所属するD君が、運行事業者から空席の情報を取得するデータ連携方式の設計を行うことになった。
〔新バスターミナルシステムの概要〕
新バスターミナルシステムの概要を図1に示す。
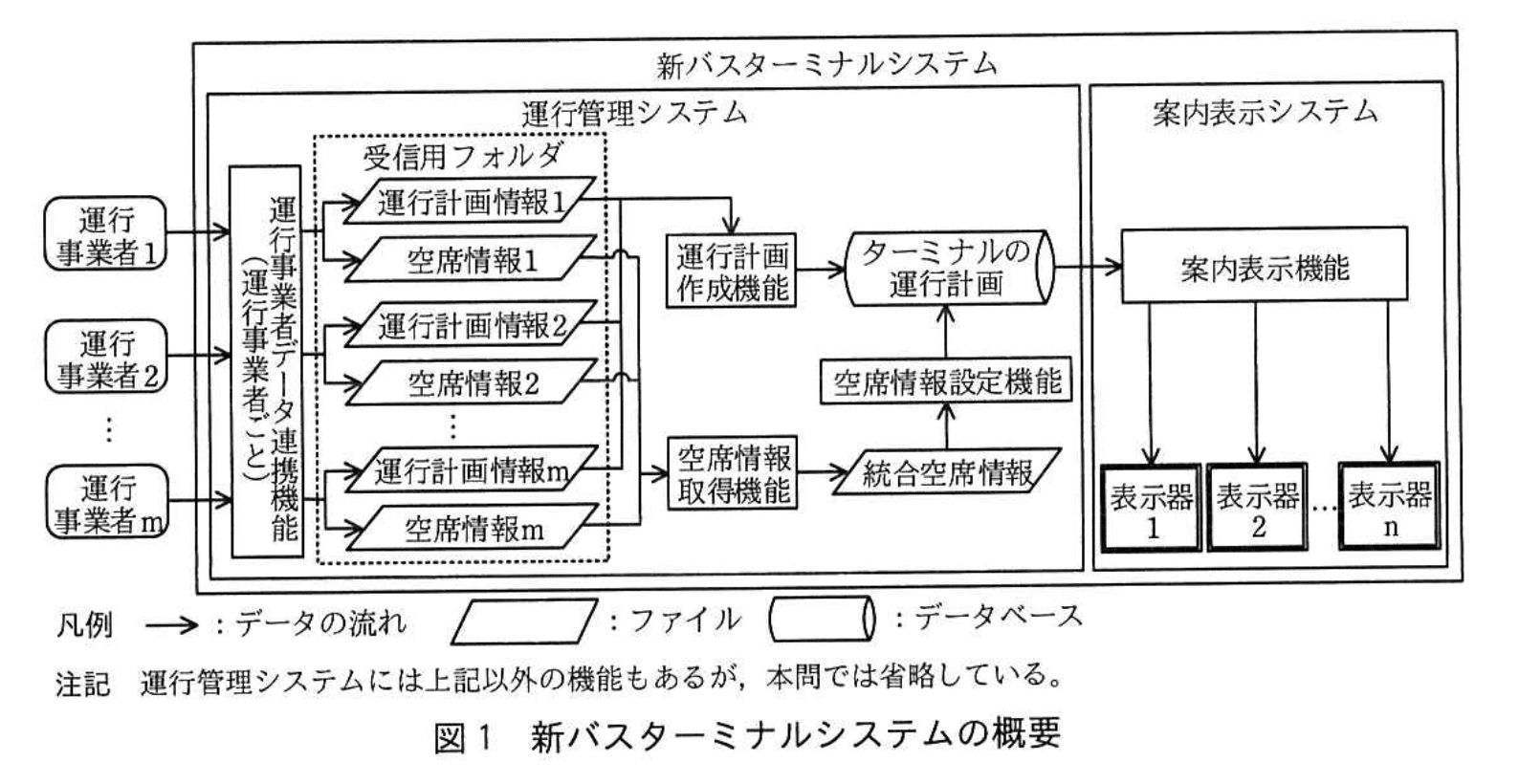
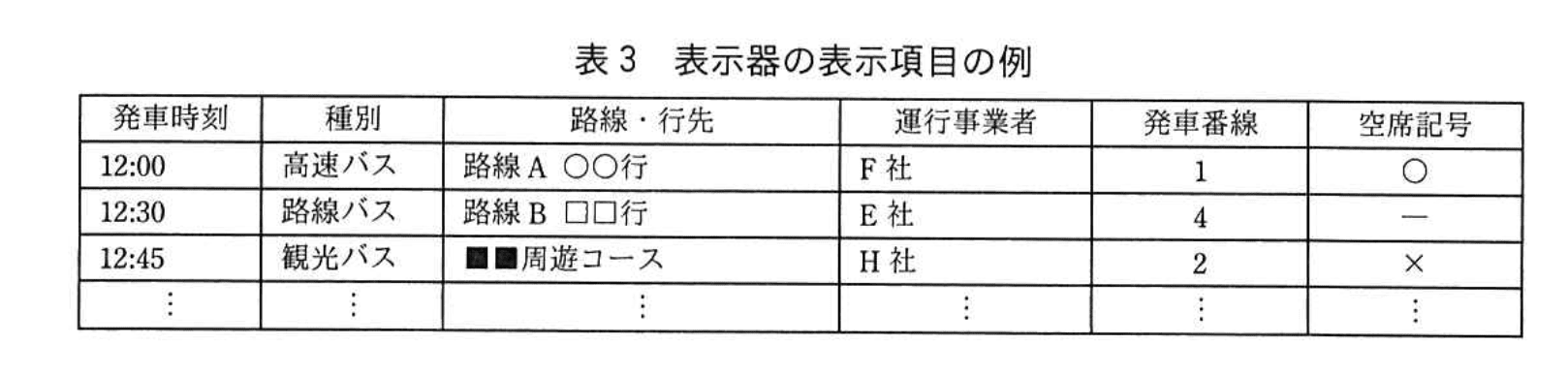
運行管理システムがもつ案内表示に関連する機能を表1に、案内表示システムがもつ機能を表2に、表示器の表示項目の例を表3に示す。


〔運行事業者の概要と連携機能の有無〕
運行事業者データ連携機能の空席情報を取得する処理について、運行事業者が空席情報を含むデータの連携機能をもつ場合には、それを活用する方針とした。そこで、D社は、高速バス、観光バスの運行事業者である E社、F社、G社、H社について、運行している全てのバスの種別と連携機能の有無を調査した。調査結果を表4に示す。
なお、高速バス、観光バスの運行事業者は上記の 4 社だけであるが、路線バスだけを運行する運行事業者である S 社、T社が存在する。

E社、F社、G社の空席情報の連携機能が提供しているデータ項目の書式と例を表5に示す。

〔データ項目の検討〕
君は、表5の情報を基に、運行管理システムが運行事業者から取得する空席情報ファイルのレコード構成、データ項目を検討した。
・空席情報ファイルは、ヘッダレコード1件と必要な数のデータレコードから成り、ヘッダレコードには、作成日、作成時刻に加え、データレコード件数を含めることにした。
・路線コード、便コードが運行事業者間で重複しないよう、二つのコードを結合し、運行事業者ごとのコードを付加した一つのコード(以下、統合便コードという)として取り扱うことにした。この統合便コードは、新バスターミナルシステム全体で使用する。この検討において、①表5の運行事業者以外の情報も調査し、問題がないことを確認した。
・②ファイル形式はCSV形式、文字コードはUTF-8とし、各項目の書式を統一した。
空席情報ファイルのデータレコードの内容を表6に示す。

〔連携方法の検討〕
D君は、連携方法について、それぞれの運行事業者を調整を行った。H社については運行する便数が少ないこともあり、開発費用が比較的安価である③Webページから情報を抽出する方法を用いることにした。連携方法に関する調整結果を表7に示す。

〔空席情報取得機能と空席情報設定機能の処理について〕
D君が検討した空席情報取得機能と空席情報設定機能を用いた空席情報ファイルの取得から設定の処理について、図2に示す。

表7及び図2で検討した処理について、情報システム部内でレビューを実施したところ、次のような指摘があった。
(i) 運行事業者とのデータ連携において FTP によるファイル転送を用いる場合は、ファイル全体が正しく転送されたことを確認する必要がある。
(ii) 特定の運行事業者から空席情報が取得できなかった場合、その運行事業者のバスについて表示票に古い空席記号が表示され続けてしまう。
D 君は、(i) の指摘に対して運行事業者データ連携機能に空席情報ファイルの a と b が一致することを確認する処理を追加する対策案、及び (ii) の指摘に対して④図2の処理(3)の最初に新たな処理を追加する対策案の検討を行い、再度レビューを実施した。
D 君は対策案が承認された後、後続の開発作業に着手した。
設問1:〔データ項目の検討〕について、(1)、(2)に答えよ。
(1)本文中の下線①について、表5以外に調査した運行事業者を全て答えよ。
模範解答
H社、S社、T社
解説
解答の論理構成
- 下線部①の原文は「①表5の運行事業者以外の情報も調査し、問題がないことを確認した」です。この文が示すのは、表5に登場しない運行事業者を洗い出す必要があるということです。
- 表5に登場する運行事業者は【問題文】の「表5 空席情報の連携機能が提供しているデータ項目の書式と例」に列挙されている「E社」「F社」「G社」の3社だけです。
- 表5以外に運行事業者が登場する箇所を探すと、【問題文】の「表4 E社、F社、G社、H社の調査結果」と「高速バス、観光バスの運行事業者は上記の 4 社だけであるが、路線バスだけを運行する運行事業者である S 社、T 社が存在する。」という記述があります。
- ここで表5に含まれていない運行事業者は、「H社」「S社」「T社」の3社です。
- したがって、解答は「H社、S社、T社」になります。
誤りやすいポイント
- 表4に「E社、F社、G社、H社」が載っているため、うっかり「E社」「F社」「G社」まで含めてしまう。
- 路線バス専業の「S社」「T社」は高速・観光バスではないため見落としやすい。
- 「表5の運行事業者以外」という条件を読み飛ばし、単に“全社”を列挙してしまう。
FAQ
Q: 表4に「E社」があるのに、なぜ答えに含めないのですか?
A: 条件が「表5の運行事業者以外」です。表5に既に「E社」が含まれているため、除外します。
A: 条件が「表5の運行事業者以外」です。表5に既に「E社」が含まれているため、除外します。
Q: 「S社」「T社」は空席連携の対象外ですが、なぜ調査対象に入るのですか?
A: 路線バスのみでも運行管理システム全体で統合便コードを重複なく扱う必要があるため、全運行事業者のコード仕様を確認する必要があります。
A: 路線バスのみでも運行管理システム全体で統合便コードを重複なく扱う必要があるため、全運行事業者のコード仕様を確認する必要があります。
Q: 「H社」は空席連携機能を持たないのに、なぜ調査対象になるのですか?
A: 連携機能の有無に関係なく、統合便コードの衝突を防ぐ観点から全運行事業者を調査する方針だからです。
A: 連携機能の有無に関係なく、統合便コードの衝突を防ぐ観点から全運行事業者を調査する方針だからです。
関連キーワード: データ連携, CSV形式, コード体系, 空席情報, ファイル転送
設問1:〔データ項目の検討〕について、(1)、(2)に答えよ。
(2)表5のG社の例について、発車日、発車時刻、統合便コード、空席数を表6に合わせて変換した場合の変換後の値を答えよ。
模範解答
発車日:20220510
発車時刻:1800
統合便コード:G0030110
空席数:8
解説
解答の論理構成
-
発車日の変換
表5のG社の例では発車日が「2022-05-10」とハイフン区切りです。表6の書式は「YYYYMMDD」ですから、ハイフンを除去して「20220510」とします。
引用:「表5 G社 例 発車日 2022-05-10」
引用:「表6 発車日 YYYYMMDD」 -
発車時刻の変換
表5の発車時刻は「18:00」でコロン付き、表6は「hhmm」です。コロンを除去して「1800」とします。
引用:「表5 G社 例 発車時刻 18:00」
引用:「表6 発車時刻 hhmm」 -
統合便コードの生成
手順は表6の説明のとおりです。
引用:「路線コードと便コードとを結合した文字列の先頭に、運行事業者ごとのコード文字…を付加して、8桁のコードにする。桁数が8桁に満たない場合は、運行事業者コードの後にゼロパディングを行う。」
• 路線コード「301」と便コード「10」を結合し「30110」(5桁)。
• 先頭に運行事業者コード「G」を付与し「G30110」(6桁)。
• 8桁に満たないので、運行事業者コードの直後に2桁分ゼロパディングし「G0030110」。 -
空席数の取込み
空席数はそのまま可変長でよいので「8」を使用します。
引用:「表5 G社 例 空席数 8」
引用:「表6 空席数 可変長」
以上より、変換後の値は
発車日:20220510
発車時刻:1800
統合便コード:G0030110
空席数:8
発車日:20220510
発車時刻:1800
統合便コード:G0030110
空席数:8
誤りやすいポイント
- ゼロパディングの位置を末尾に入れてしまい「G3011000」とするミス。規定は「運行事業者コードの後」に入れる点に注意。
- 発車時刻を 4 桁化する際に「18:00」を「01800」としてしまう誤り。24 時制 2 桁+ 2 桁で十分なので先頭ゼロは不要。
- 路線コード「301」と便コード「10」の結合順序を逆にしてしまうケース。問題文は“路線コードと便コードとを結合”と明示。
FAQ
Q: 便コードが 3 桁以上の場合でもゼロパディングは必要ですか?
A: 結合後の桁数が運行事業者コードを含めて 8 桁に満たない場合のみ必要です。8 桁以上ならパディングしません。
A: 結合後の桁数が運行事業者コードを含めて 8 桁に満たない場合のみ必要です。8 桁以上ならパディングしません。
Q: 路線バスのみの運行事業者でも統合便コードの作り方は同じですか?
A: はい、表6に示す「新バスターミナルシステム全体で使用する」規則ですから種別によらず同じ方式で統一します。
A: はい、表6に示す「新バスターミナルシステム全体で使用する」規則ですから種別によらず同じ方式で統一します。
Q: 空席数が 0 の場合、空席記号はどう表示されますか?
A: 表2の案内表示機能に記載の「別途定義するしきい値」に従い、“×” などの空席記号が表示されます。空席数 0 のままでもファイルには 0 を記録します。
A: 表2の案内表示機能に記載の「別途定義するしきい値」に従い、“×” などの空席記号が表示されます。空席数 0 のままでもファイルには 0 を記録します。
関連キーワード: CSV形式, UTF-8, コード体系, ゼロパディング, データ連携
設問2:
本文中の下線②について、CSVファイルの特徴として適切なものを解答群の中から全て選び、記号で答えよ。
解答群
ア:XMLファイルと比較して、1レコード当たりのデータサイズが小さい。
イ:XMLファイルと比較して、処理速度が遅い。
ウ:固定長ファイルと比較して、項目の桁数や文字数に関する自由度が低い。
エ:固定長ファイルと比較して、処理速度が遅い。
模範解答
ア、エ
解説
解答の論理構成
- 【問題文】では、空席情報ファイルについて「②ファイル形式はCSV形式」と方針を定めています。設問はこの“CSV形式”の特徴を他形式(XML、固定長)と比較して選ぶ問題です。
- CSVはカンマ区切りでタグを持たないため、
- XMLのような開始・終了タグを含まずメタ情報も少ないことから、同じデータを格納した場合に「1レコード当たりのデータサイズ」が小さくなります。よって解答群「ア:XMLファイルと比較して、1レコード当たりのデータサイズが小さい。」が該当します。
- 固定長ファイルは各項目の開始位置を計算で直参照できるので、I/O とパースの両面で高い性能を発揮します。CSVは区切り文字を読み取りながら可変長項目を解釈する必要があるため、「処理速度」が固定長より遅くなりやすいです。よって「エ:固定長ファイルと比較して、処理速度が遅い。」が該当します。
- 残りの選択肢を検証します。
• 「イ:XMLファイルと比較して、処理速度が遅い。」
→ XMLはツリー構造を解析する必要がありオーバーヘッドが大きいので、一般にCSVの方が速い。誤り。
• 「ウ:固定長ファイルと比較して、項目の桁数や文字数に関する自由度が低い。」
→ 固定長は桁数が固定であるのに対し、CSVは可変長で自由度が高い。誤り。 - よって正しい組合せは「ア、エ」となります。
誤りやすいポイント
- 「XMLはテキストだから軽い」と思い込み、データ量に対してタグが増える事実を見落とす。
- 固定長=古い形式=遅いと短絡的に判断する。実際には位置計算だけでアクセスできるため高速。
- CSVの“自由度”を“低い”と誤読しやすい。可変長ゆえに自由度は高い点を押さえる。
- 処理速度をファイルサイズの大小だけで判断し、解析コスト(パース処理)を考慮しない。
FAQ
Q: XMLでも軽量なパーサを使えばCSVと同程度の速度になりますか?
A: 構造上、タグの解釈や階層管理が必要なため、同程度にするには専用設計やバイナリXMLなど別手段が必要です。一般的な SAX / DOM パーサでは CSV の方が速いケースが多いです。
A: 構造上、タグの解釈や階層管理が必要なため、同程度にするには専用設計やバイナリXMLなど別手段が必要です。一般的な SAX / DOM パーサでは CSV の方が速いケースが多いです。
Q: CSVと固定長の速度差はどこで決まりますか?
A: 主に「位置計算と I/O」。固定長はオフセット=(レコード長×行番号)で直接アクセスできる一方、CSVは区切り文字を読み取って位置を確定するため、その分オーバーヘッドが生じます。
A: 主に「位置計算と I/O」。固定長はオフセット=(レコード長×行番号)で直接アクセスできる一方、CSVは区切り文字を読み取って位置を確定するため、その分オーバーヘッドが生じます。
Q: 可変長のCSVでもインデックスを作れば高速化できますか?
A: 可能ですが、インデックス作成自体に別途時間・ストレージが必要で、結局はデータベースを導入するのと同様の管理負荷が生じます。ファイル転送だけで済む要件では固定長の方がシンプルに高速です。
A: 可能ですが、インデックス作成自体に別途時間・ストレージが必要で、結局はデータベースを導入するのと同様の管理負荷が生じます。ファイル転送だけで済む要件では固定長の方がシンプルに高速です。
関連キーワード: CSV, XML, 固定長ファイル, パース速度, デリミタ
設問3:
本文中の下線③の名称として適切な字句を解答群の中から選び、記号で答えよ。
解答群
ア:WAI
イ:Web API
ウ:Webコンテンツ
エ:Webスクレイピング
模範解答
エ
解説
解答の論理構成
- 問題文には、H社と連携する際の方法として
“H社については運行する便数が少ないこともあり、開発費用が比較的安価である③Webページから情報を抽出する方法を用いることにした。”
と記載されています。 - “Webページから情報を抽出する”行為は、公開された HTML などの画面を機械的に取得し、タグを解析して必要データを取り出す技術を指します。
- この技術を一般に呼ぶ名称は “Webスクレイピング” です。
- 解答群を照合すると、 “エ:Webスクレイピング” が該当します。
- 以上より、下線③に入る適切な字句は “エ” です。
誤りやすいポイント
- 「API も Web を経由するから ‘Web API’ では?」と早合点するケース
→ API はサービス提供側が正式に用意するインタフェースであり、画面解析とは異なる。 - “Webコンテンツ” はページそのものを指す一般語で、データ取得方法の名称ではない。
- “WAI” は “Web Accessibility Initiative” などを連想させるが、本設問の文脈と無関係。
FAQ
Q: Webスクレイピングを選ぶ根拠は何ですか?
A: 問題文にある “Webページから情報を抽出する” という行為そのものがスクレイピングを意味するためです。
A: 問題文にある “Webページから情報を抽出する” という行為そのものがスクレイピングを意味するためです。
Q: Web API とスクレイピングの主な違いは?
A: Web API は提供側が公式に公開するデータ取得用インタフェース、スクレイピングは画面表示用 HTML を解析して非公式にデータを取得する方法です。
A: Web API は提供側が公式に公開するデータ取得用インタフェース、スクレイピングは画面表示用 HTML を解析して非公式にデータを取得する方法です。
Q: スクレイピングを導入する際の注意点は?
A: 取得元ページの構造変更で動かなくなるリスク、著作権・利用規約の確認、アクセス負荷を掛けすぎない配慮などが必要です。
A: 取得元ページの構造変更で動かなくなるリスク、著作権・利用規約の確認、アクセス負荷を掛けすぎない配慮などが必要です。
関連キーワード: データ連携, FTP, CSV, 文字コード, スクレイピング
設問4:
本文中のa、bに入れる適切な字句を、20字以内で答えよ(aとbは順不同)。
模範解答
a:ヘッダレコードのデータレコード件数
b:処理したデータレコードの件数
解説
解答の論理構成
-
確認すべき項目の導出
- 指摘 (i) で、FTP 転送後に「ファイル全体が正しく転送されたことを確認」する必要が示されています。
- 対策案では「空席情報ファイルのa と b が一致することを確認」とあります。
-
“どの値を突合するか” の手掛かり
- データ設計段階で「空席情報ファイルは、ヘッダレコード1件と必要な数のデータレコードから成り、ヘッダレコードには、作成日、作成時刻に加え、データレコード件数を含める」と明記されています。
- したがってヘッダには“送信側が想定するデータレコード件数”が入る。
-
受信側で算出できる対応値
- 受信後、プログラムはファイルを読み込み「処理したデータレコードの件数」をカウントできます。
- ヘッダに記載された件数と、実際に読み取った件数が一致すれば「全件受信できた」と判断できます。
-
解答
- a に入るのは「ヘッダレコードのデータレコード件数」
- b に入るのは「処理したデータレコードの件数」
誤りやすいポイント
- ヘッダにあるのは “ファイル全体のバイト数” と誤解しがち。本文で指定されているのは「データレコード件数」です。
- b を “空席数の合計” と読み違えるケース。確認対象はレコード件数であり数値合計ではありません。
- 文字コードや CSV 形式など他の仕様と混同して、突合項目を複数設定してしまうミス。設問は件数一致のみを問います。
FAQ
Q: バイト数チェックではなく件数チェックで良いのですか?
A: 本文でヘッダに「データレコード件数」を載せると規定されているため、最小変更で実装できる件数突合が選ばれています。
A: 本文でヘッダに「データレコード件数」を載せると規定されているため、最小変更で実装できる件数突合が選ばれています。
Q: 受信側で読み取った件数が多い場合はどう扱いますか?
A: 件数不一致としてエラー扱いにし、ファイルを再取得する運用が一般的です。
A: 件数不一致としてエラー扱いにし、ファイルを再取得する運用が一般的です。
Q: CRC などのハッシュ値を使う方法と比較して劣りますか?
A: ハッシュ値の方が厳密ですが、現行仕様でヘッダ件数が既に定義されていること、ファイルが CSV で比較的小容量であることから件数チェックが採用されています。
A: ハッシュ値の方が厳密ですが、現行仕様でヘッダ件数が既に定義されていること、ファイルが CSV で比較的小容量であることから件数チェックが採用されています。
関連キーワード: FTP, CSV, ヘッダレコード, レコード件数, ファイル検証
設問5:
本文中の下線④で追加した処理の内容を35字以内で述べよ。
模範解答
ターミナルの運行計画に設定された空席数をnullにする。
解説
解答の論理構成
-
指摘事項の把握
レビューでは、
― “特定の運行事業者から空席情報が取得できなかった場合、その運行事業者のバスについて表示器に古い空席記号が表示され続けてしまう。”
と指摘されています。古い空席数が残れば誤表示になります。 -
対策の方針
指摘に対し、D君は “④図2の処理(3)の最初に新たな処理を追加する対策案” を検討しました。
処理(3)は “ターミナルの運行計画と照合し空席数を設定する” ため、その直前で対策を行えば古い値を無効化できます。 -
追加すべき具体的処理
誤表示を防ぐ最も確実な方法は、更新対象となる便の空席数をいったん未設定状態に戻すことです。ターミナルの運行計画で未設定を表す値は “null” と規定されています。
― “ターミナルの運行計画の空席数には初期値として null を設定する。”
― “ターミナルの運行計画の空席数が null の場合は、“—” を表示する。” -
結論
したがって、新たに追加する処理は “ターミナルの運行計画に設定された空席数を null にする” となります。
誤りやすいポイント
- ファイル未取得時の表示を “×” と誤解し、空席数を0に初期化してしまう。
- “null” を単に空文字列や0と置き換えてしまう。
- 処理(1)や(2)に追加すると考え、更新前に上書きされ旧データが残る問題を解決できない。
FAQ
Q: 取得失敗した運行事業者だけを null にすべきでは?
A: 処理は統合空席情報ファイルを照合する前に全便の空席数を null に戻すため、取得できた便は直後の上書きで新値が入ります。結果として取得できなかった便だけが null のまま残ります。
A: 処理は統合空席情報ファイルを照合する前に全便の空席数を null に戻すため、取得できた便は直後の上書きで新値が入ります。結果として取得できなかった便だけが null のまま残ります。
Q: “null” にしたあと表示器はどう映るのですか?
A: 表示器は “ターミナルの運行計画の空席数が null の場合は、“—” を表示する。” ため、古い記号が消えて “—” になります。
A: 表示器は “ターミナルの運行計画の空席数が null の場合は、“—” を表示する。” ため、古い記号が消えて “—” になります。
Q: 更新間隔が5分でも問題ありませんか?
A: 5分ごとに処理(1)~(3)を行うため、最長でも5分で表示が最新状態(または “—”)に保たれます。
A: 5分ごとに処理(1)~(3)を行うため、最長でも5分で表示が最新状態(または “—”)に保たれます。
関連キーワード: CSV, 文字コード, FTP, API, null
